




AJ Stuyvenberg
@ajs.bsky.social
AWS Hero
Staff Eng @ Datadog
Streaming at: twitch.tv/aj_stuyvenberg
Videos at: youtube.com/@astuyve
I write about serverless minutia at aaronstuyvenberg.com/
Staff Eng @ Datadog
Streaming at: twitch.tv/aj_stuyvenberg
Videos at: youtube.com/@astuyve
I write about serverless minutia at aaronstuyvenberg.com/
I use AWS a ton but Lambda still astounds me. Throw some code in a function, send 1m requests as fast as you can.
It ate up all available file descriptors on my little t3 box and still ran 18k RPS with a p99 of 0.3479s. Not many services can go from 0 to 18k RPS instantaneously with this p99.
It ate up all available file descriptors on my little t3 box and still ran 18k RPS with a p99 of 0.3479s. Not many services can go from 0 to 18k RPS instantaneously with this p99.


September 18, 2025 at 1:03 PM
I use AWS a ton but Lambda still astounds me. Throw some code in a function, send 1m requests as fast as you can.
It ate up all available file descriptors on my little t3 box and still ran 18k RPS with a p99 of 0.3479s. Not many services can go from 0 to 18k RPS instantaneously with this p99.
It ate up all available file descriptors on my little t3 box and still ran 18k RPS with a p99 of 0.3479s. Not many services can go from 0 to 18k RPS instantaneously with this p99.
Lambda now charges for init time, so it's useful to count sandboxes which are proactively initialized but never receive a request.
Here's what happens after a 10k request burst. Hundreds of sandbox shutdowns, along with 22 sandboxes which were spun up but never received a request.
Here's what happens after a 10k request burst. Hundreds of sandbox shutdowns, along with 22 sandboxes which were spun up but never received a request.
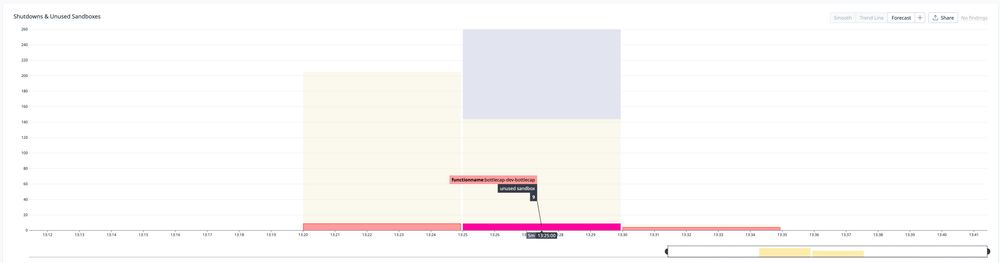
August 5, 2025 at 5:51 PM
Lambda now charges for init time, so it's useful to count sandboxes which are proactively initialized but never receive a request.
Here's what happens after a 10k request burst. Hundreds of sandbox shutdowns, along with 22 sandboxes which were spun up but never received a request.
Here's what happens after a 10k request burst. Hundreds of sandbox shutdowns, along with 22 sandboxes which were spun up but never received a request.
Happy Lambda Init Billing day to those who celebrate. Fix your cold starts!

August 1, 2025 at 3:04 PM
Happy Lambda Init Billing day to those who celebrate. Fix your cold starts!
NEW: Lambda can now send up to 200mb payloads using response streaming! I assume this is mostly directed at LLM inference workloads, where chatbots can stream large amounts of data over the wire as it becomes available.

August 1, 2025 at 1:10 AM
NEW: Lambda can now send up to 200mb payloads using response streaming! I assume this is mostly directed at LLM inference workloads, where chatbots can stream large amounts of data over the wire as it becomes available.
I've long been an advocate for the Lambda Web Adapter project which lets anyone pretty easily ship an app to Lambda without learning about the event model/API.
Honestly AWS should simply support this natively.
Honestly AWS should simply support this natively.
July 30, 2025 at 5:43 PM
I've long been an advocate for the Lambda Web Adapter project which lets anyone pretty easily ship an app to Lambda without learning about the event model/API.
Honestly AWS should simply support this natively.
Honestly AWS should simply support this natively.
"We run benchmarks continually across all of our competitors, not just queries - even connections, ensuring we don't add any latency at all." @isamlambert
Performance is such a competitive advantage which easily slips away if you're not constantly paying attention to it.
Performance is such a competitive advantage which easily slips away if you're not constantly paying attention to it.
July 28, 2025 at 2:59 PM
"We run benchmarks continually across all of our competitors, not just queries - even connections, ensuring we don't add any latency at all." @isamlambert
Performance is such a competitive advantage which easily slips away if you're not constantly paying attention to it.
Performance is such a competitive advantage which easily slips away if you're not constantly paying attention to it.
Reposted by AJ Stuyvenberg

Datadog rewrote its AWS Lambda Extension from #Golang to #Rustlang with no prior Rust experience. @ajs.bsky.social will share how they achieved an 80% Lambda cold start improvement along with a 50% memory footprint reduction at our free and virtual #P99CONF. www.p99conf.io?latest_sfdc_...
#ScyllaDB
#ScyllaDB

July 23, 2025 at 2:17 PM
Datadog rewrote its AWS Lambda Extension from #Golang to #Rustlang with no prior Rust experience. @ajs.bsky.social will share how they achieved an 80% Lambda cold start improvement along with a 50% memory footprint reduction at our free and virtual #P99CONF. www.p99conf.io?latest_sfdc_...
#ScyllaDB
#ScyllaDB
Here's another 33% cold start reduction, which comes from deferring expensive decryption calls made to AWS Secrets Manager until the secret is actually needed.
Lazy loading is great!
Lazy loading is great!
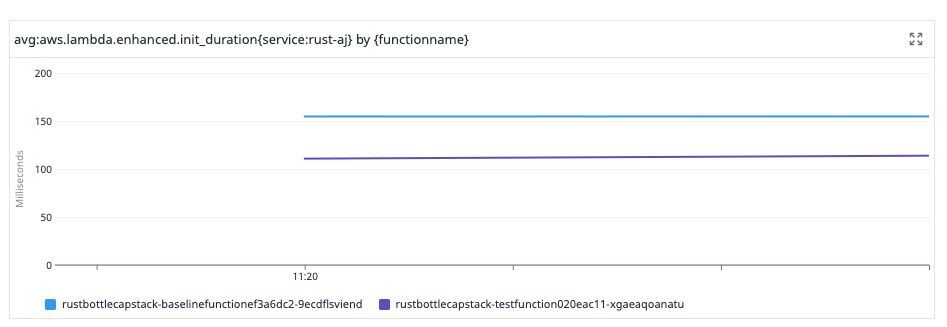
July 22, 2025 at 3:31 PM
Here's another 33% cold start reduction, which comes from deferring expensive decryption calls made to AWS Secrets Manager until the secret is actually needed.
Lazy loading is great!
Lazy loading is great!
Here's how to visualize a 100% memory allocation improvement!
A recent stress test revealed that malloc calls bottlenecked when sending > 100k spans through the API and aggregator pipelines in Lambda.
A recent stress test revealed that malloc calls bottlenecked when sending > 100k spans through the API and aggregator pipelines in Lambda.
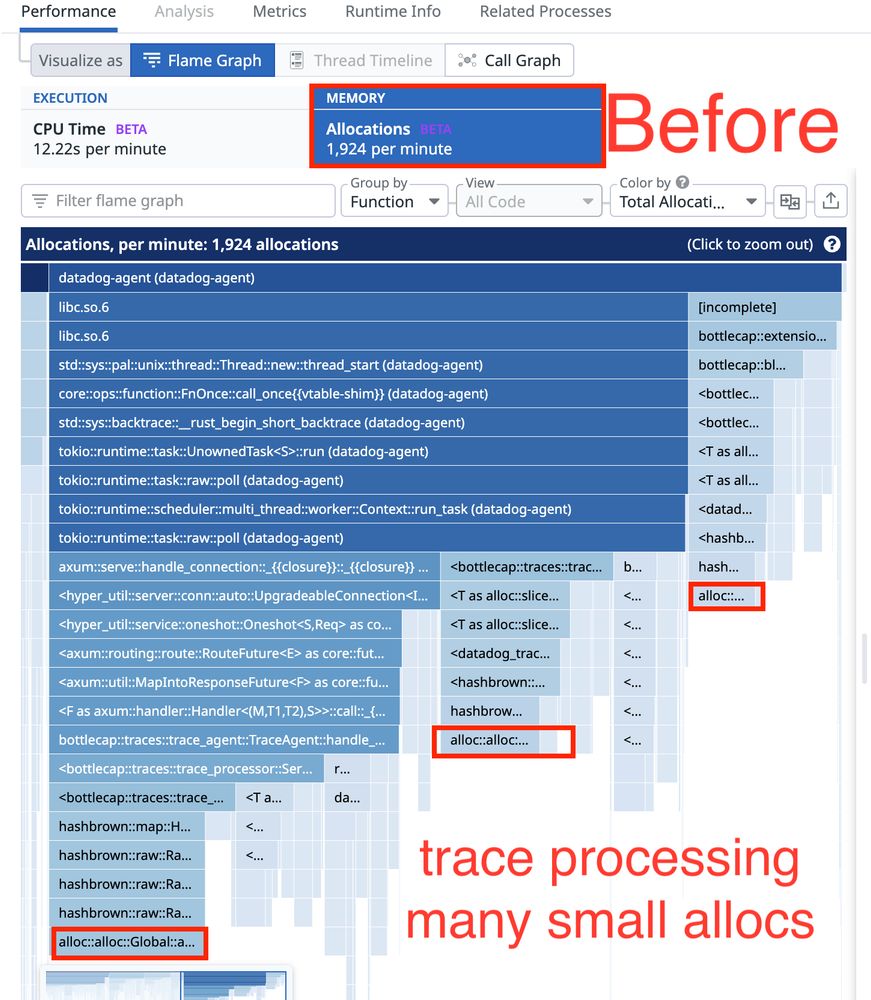
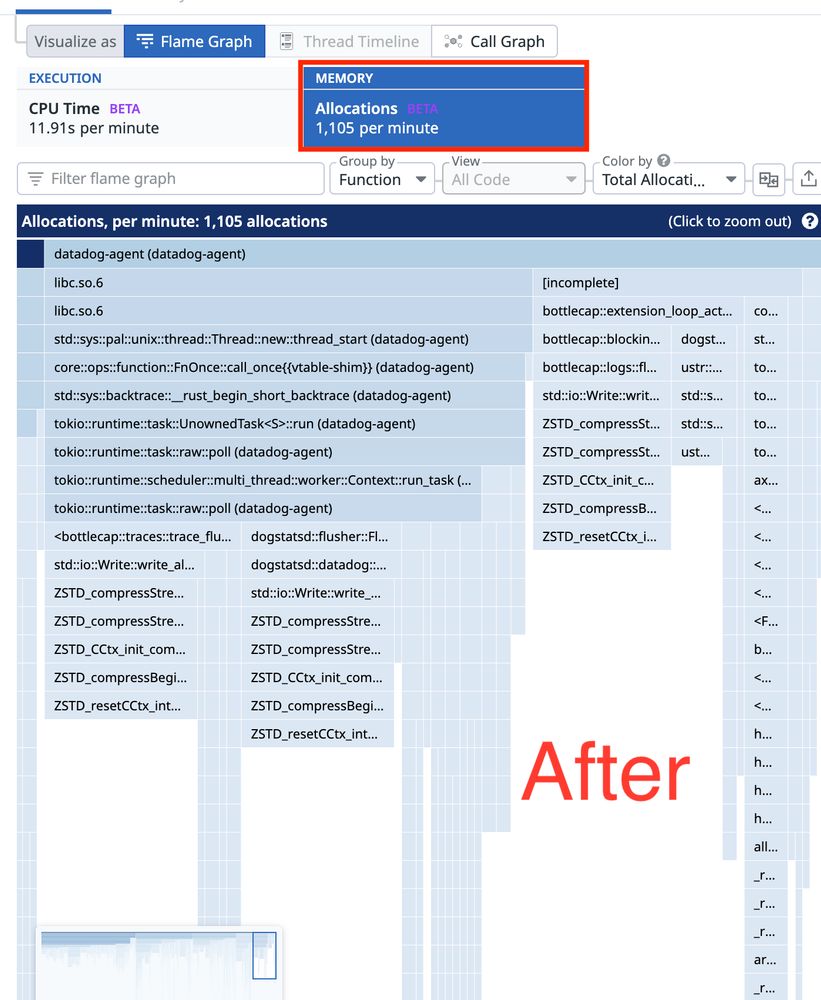
July 18, 2025 at 3:07 PM
Here's how to visualize a 100% memory allocation improvement!
A recent stress test revealed that malloc calls bottlenecked when sending > 100k spans through the API and aggregator pipelines in Lambda.
A recent stress test revealed that malloc calls bottlenecked when sending > 100k spans through the API and aggregator pipelines in Lambda.
NEW: A recent blog post went viral in the AWS ecosystem, about how there's a silent crash in AWS Lambda's NodeJS runtime.
Today I'll step you through the actual Lambda runtime code which causes this confusing issue, and walk you through how to safely perform async work in Lambda:
Today I'll step you through the actual Lambda runtime code which causes this confusing issue, and walk you through how to safely perform async work in Lambda:

July 17, 2025 at 3:29 PM
NEW: A recent blog post went viral in the AWS ecosystem, about how there's a silent crash in AWS Lambda's NodeJS runtime.
Today I'll step you through the actual Lambda runtime code which causes this confusing issue, and walk you through how to safely perform async work in Lambda:
Today I'll step you through the actual Lambda runtime code which causes this confusing issue, and walk you through how to safely perform async work in Lambda:
Lambda's fleet management shutdown algorithm is learning faster!
I'm calling this function every 8 or so minutes. At first the gap from invocation to shutdown is about 5-6 minutes, which was the fastest I've observed during previous experiments.
I'm calling this function every 8 or so minutes. At first the gap from invocation to shutdown is about 5-6 minutes, which was the fastest I've observed during previous experiments.
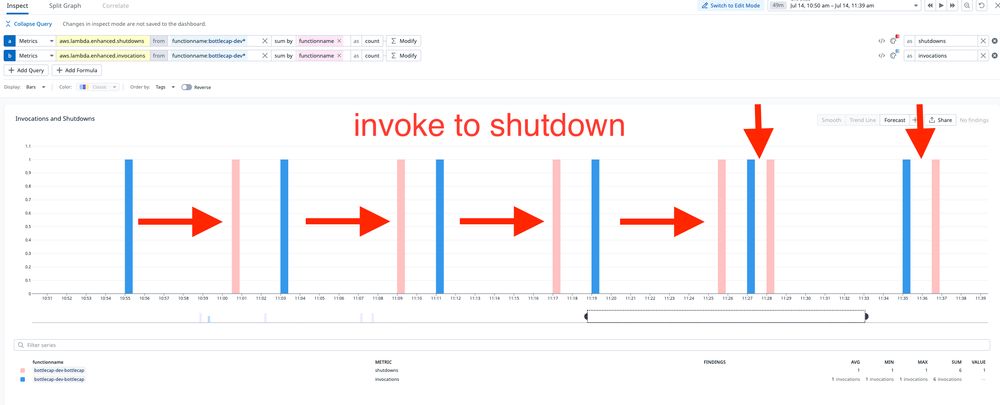
July 14, 2025 at 4:07 PM
Lambda's fleet management shutdown algorithm is learning faster!
I'm calling this function every 8 or so minutes. At first the gap from invocation to shutdown is about 5-6 minutes, which was the fastest I've observed during previous experiments.
I'm calling this function every 8 or so minutes. At first the gap from invocation to shutdown is about 5-6 minutes, which was the fastest I've observed during previous experiments.
NEW: AWS is rolling out a new free tier beginning July 15th!!
New accounts get $100 in credits to start and can earn $100 exploring AWS resources. You can now explore AWS without worrying about incurring a huge bill, this is great!
docs.aws.amazon.com/awsaccountbi...
New accounts get $100 in credits to start and can earn $100 exploring AWS resources. You can now explore AWS without worrying about incurring a huge bill, this is great!
docs.aws.amazon.com/awsaccountbi...

July 11, 2025 at 3:23 PM
NEW: AWS is rolling out a new free tier beginning July 15th!!
New accounts get $100 in credits to start and can earn $100 exploring AWS resources. You can now explore AWS without worrying about incurring a huge bill, this is great!
docs.aws.amazon.com/awsaccountbi...
New accounts get $100 in credits to start and can earn $100 exploring AWS resources. You can now explore AWS without worrying about incurring a huge bill, this is great!
docs.aws.amazon.com/awsaccountbi...
You should care about your p99! By improving the function cold start time, the service on the left performed:
2x faster in RPS and thus, duration.
p99 from 1.52s -> .949s
The code and functionality is identical, but improving the cold start from 816ms to 301ms made all the difference.
2x faster in RPS and thus, duration.
p99 from 1.52s -> .949s
The code and functionality is identical, but improving the cold start from 816ms to 301ms made all the difference.
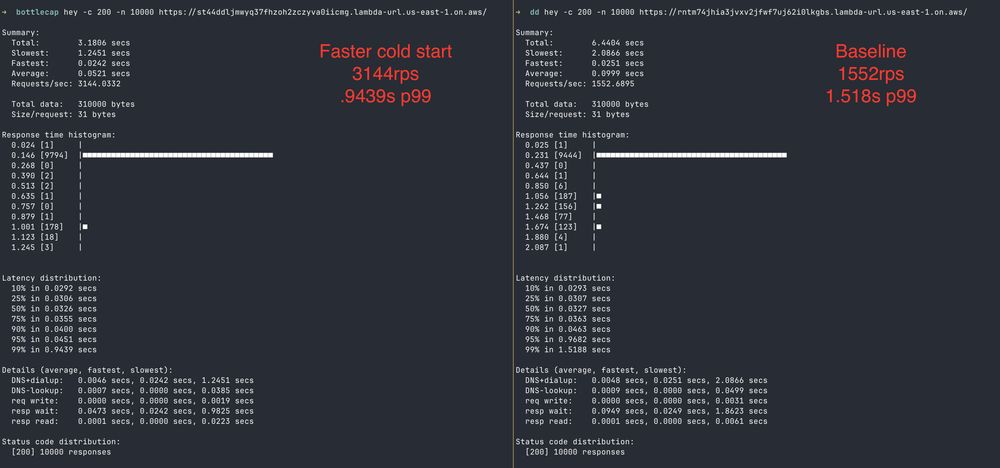

July 10, 2025 at 3:36 PM
You should care about your p99! By improving the function cold start time, the service on the left performed:
2x faster in RPS and thus, duration.
p99 from 1.52s -> .949s
The code and functionality is identical, but improving the cold start from 816ms to 301ms made all the difference.
2x faster in RPS and thus, duration.
p99 from 1.52s -> .949s
The code and functionality is identical, but improving the cold start from 816ms to 301ms made all the difference.
Quick PSA to make sure you're using a DLQ and setting a max receive count for SQS, otherwise you may find yourself looking at a flamegraph like this.
Hundreds of attempts, multiple messages in queue and not burning down and average age of message ticking up! Seems common knowledge, but...
Hundreds of attempts, multiple messages in queue and not burning down and average age of message ticking up! Seems common knowledge, but...
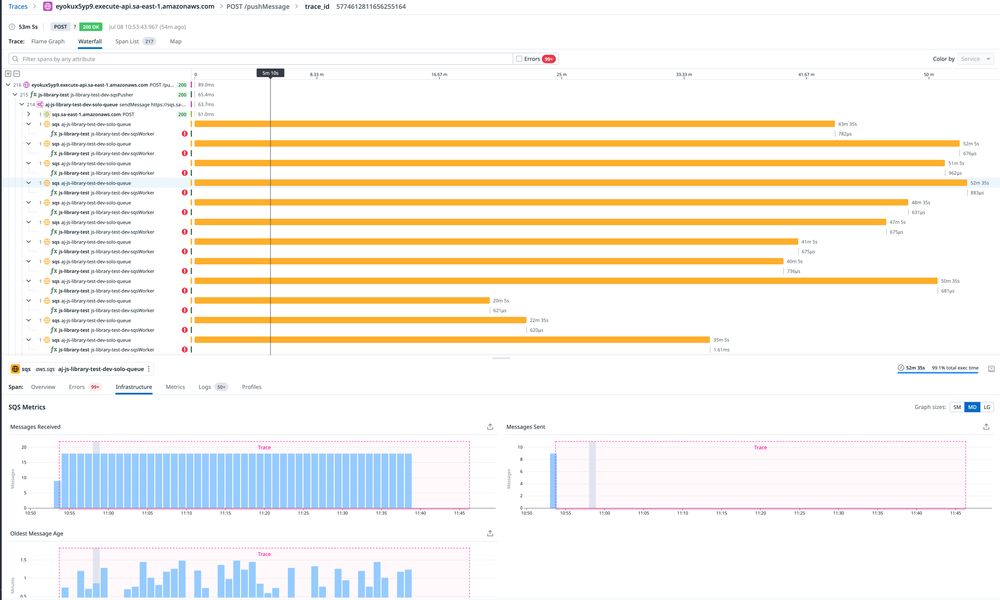
July 8, 2025 at 3:55 PM
Quick PSA to make sure you're using a DLQ and setting a max receive count for SQS, otherwise you may find yourself looking at a flamegraph like this.
Hundreds of attempts, multiple messages in queue and not burning down and average age of message ticking up! Seems common knowledge, but...
Hundreds of attempts, multiple messages in queue and not burning down and average age of message ticking up! Seems common knowledge, but...
Real-time audio processing is an extremely interesting corner of performance engineering. You've gotta process data faster than it streams in, otherwise the work is wasted.
The engineering team behind CoScreen just open sourced a new library, dtln-rs, suitable for removing noise from all kinds
The engineering team behind CoScreen just open sourced a new library, dtln-rs, suitable for removing noise from all kinds

How we built a real-time, client-side noise suppression library without server dependencies | Datadog
Learn how we implemented and open-sourced a noise filter for real-time audio chat without compromising performance. Better yet, try the demo and add it to your own project today.
www.datadoghq.com
July 3, 2025 at 3:16 PM
Real-time audio processing is an extremely interesting corner of performance engineering. You've gotta process data faster than it streams in, otherwise the work is wasted.
The engineering team behind CoScreen just open sourced a new library, dtln-rs, suitable for removing noise from all kinds
The engineering team behind CoScreen just open sourced a new library, dtln-rs, suitable for removing noise from all kinds
Monitoring Lambda sandbox shutdowns reveals an interesting scaling behavior
After a request spike, Lambda waits ~10m before reaping 2/3rds of sandboxes. 5m later it begins reaping the rest.
Presumably this helps smooth latency during retry storms, or if traffic returns!
After a request spike, Lambda waits ~10m before reaping 2/3rds of sandboxes. 5m later it begins reaping the rest.
Presumably this helps smooth latency during retry storms, or if traffic returns!

May 29, 2025 at 3:55 PM
Monitoring Lambda sandbox shutdowns reveals an interesting scaling behavior
After a request spike, Lambda waits ~10m before reaping 2/3rds of sandboxes. 5m later it begins reaping the rest.
Presumably this helps smooth latency during retry storms, or if traffic returns!
After a request spike, Lambda waits ~10m before reaping 2/3rds of sandboxes. 5m later it begins reaping the rest.
Presumably this helps smooth latency during retry storms, or if traffic returns!
Here's another huge p99 cliff!
One unreasonably effective way to lower the average latency of a service is to minimize the causes of p99 events.
Here, we've managed to absolutely crush the Max Post Runtime Duration from ~80ms to 500µs!
One unreasonably effective way to lower the average latency of a service is to minimize the causes of p99 events.
Here, we've managed to absolutely crush the Max Post Runtime Duration from ~80ms to 500µs!

May 21, 2025 at 4:34 PM
Here's another huge p99 cliff!
One unreasonably effective way to lower the average latency of a service is to minimize the causes of p99 events.
Here, we've managed to absolutely crush the Max Post Runtime Duration from ~80ms to 500µs!
One unreasonably effective way to lower the average latency of a service is to minimize the causes of p99 events.
Here, we've managed to absolutely crush the Max Post Runtime Duration from ~80ms to 500µs!
Truly incredible to learn that Epic Games isn't self hosted on a VPS.

May 6, 2025 at 3:55 PM
Truly incredible to learn that Epic Games isn't self hosted on a VPS.
PRICE CUT: Lambda slashes the price of cloudwatch logs for high volume. From $.50/gb down to $0.05/gb after 50TB.
You've gotta be spending a decent chunk of $$$ on cloudwatch logs for this to help, but still – a price cut is a price cut!
You've gotta be spending a decent chunk of $$$ on cloudwatch logs for this to help, but still – a price cut is a price cut!

May 1, 2025 at 7:55 PM
PRICE CUT: Lambda slashes the price of cloudwatch logs for high volume. From $.50/gb down to $0.05/gb after 50TB.
You've gotta be spending a decent chunk of $$$ on cloudwatch logs for this to help, but still – a price cut is a price cut!
You've gotta be spending a decent chunk of $$$ on cloudwatch logs for this to help, but still – a price cut is a price cut!
Combining profiler data with claude code feels super powerful.
Just drop a pprof file into a project, explain the dimensions of the profile, then let the LLM make suggestions to solve the hot spots.
Instant performance boost
Just drop a pprof file into a project, explain the dimensions of the profile, then let the LLM make suggestions to solve the hot spots.
Instant performance boost

May 1, 2025 at 4:29 PM
Combining profiler data with claude code feels super powerful.
Just drop a pprof file into a project, explain the dimensions of the profile, then let the LLM make suggestions to solve the hot spots.
Instant performance boost
Just drop a pprof file into a project, explain the dimensions of the profile, then let the LLM make suggestions to solve the hot spots.
Instant performance boost
NEW: AWS Lambda will now begin billing for the INIT phase for all runtimes (not just custom/container runtimes). Your cold starts cost money now!
My hottest take is that AWS should have done this years ago.
My hottest take is that AWS should have done this years ago.

April 29, 2025 at 7:49 PM
NEW: AWS Lambda will now begin billing for the INIT phase for all runtimes (not just custom/container runtimes). Your cold starts cost money now!
My hottest take is that AWS should have done this years ago.
My hottest take is that AWS should have done this years ago.
The evolution of my program when each branch is benchmarked & profiled before merging

April 23, 2025 at 4:52 PM
The evolution of my program when each branch is benchmarked & profiled before merging
Reposted by AJ Stuyvenberg

The latest cover for Cold Start Aficionado magazine. w/ @ajs.bsky.social

April 22, 2025 at 6:00 PM
The latest cover for Cold Start Aficionado magazine. w/ @ajs.bsky.social
Check out that p99 cliff!
I spent 2024 shipping our next-generation Lambda Extension, which offers an 82% improvement in cold start time, better aggregation and flushing options, and lower overall overhead – all in a substantially smaller binary package.
More: www.datadoghq.com/blog/enginee...
I spent 2024 shipping our next-generation Lambda Extension, which offers an 82% improvement in cold start time, better aggregation and flushing options, and lower overall overhead – all in a substantially smaller binary package.
More: www.datadoghq.com/blog/enginee...


April 10, 2025 at 4:21 PM
Check out that p99 cliff!
I spent 2024 shipping our next-generation Lambda Extension, which offers an 82% improvement in cold start time, better aggregation and flushing options, and lower overall overhead – all in a substantially smaller binary package.
More: www.datadoghq.com/blog/enginee...
I spent 2024 shipping our next-generation Lambda Extension, which offers an 82% improvement in cold start time, better aggregation and flushing options, and lower overall overhead – all in a substantially smaller binary package.
More: www.datadoghq.com/blog/enginee...
Cloudflare isn't pulling any punches with this twitter outage. Absolutely brutal:

March 10, 2025 at 5:10 PM
Cloudflare isn't pulling any punches with this twitter outage. Absolutely brutal: