




Adina Yakup
@adinayakup.bsky.social
AI Research @Hugging Face 🤗
Contributing to the Chinese ML community.
Contributing to the Chinese ML community.
Baidu just released a reasoning model 🔥 ERNIE-4.5-21B-A3B-Thinking
huggingface.co/baidu/ERNIE-...
✨ Small MoE - Apache 2.0
✨ 128K context length for deep reasoning
✨ Efficient tool usage capabilities
huggingface.co/baidu/ERNIE-...
✨ Small MoE - Apache 2.0
✨ 128K context length for deep reasoning
✨ Efficient tool usage capabilities

baidu/ERNIE-4.5-21B-A3B-Thinking · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
September 9, 2025 at 6:25 AM
Baidu just released a reasoning model 🔥 ERNIE-4.5-21B-A3B-Thinking
huggingface.co/baidu/ERNIE-...
✨ Small MoE - Apache 2.0
✨ 128K context length for deep reasoning
✨ Efficient tool usage capabilities
huggingface.co/baidu/ERNIE-...
✨ Small MoE - Apache 2.0
✨ 128K context length for deep reasoning
✨ Efficient tool usage capabilities
Baidu just released a thinking model 🔥 ERNIE-4.5-21B-A3B-Thinking
huggingface.co/baidu/ERNIE-...
✨ Small MoE - Apache 2.0
✨ 128K context length for deep reasoning
✨ Efficient tool usage capabilities
huggingface.co/baidu/ERNIE-...
✨ Small MoE - Apache 2.0
✨ 128K context length for deep reasoning
✨ Efficient tool usage capabilities
baidu/ERNIE-4.5-21B-A3B-Thinking · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
September 9, 2025 at 6:21 AM
Baidu just released a thinking model 🔥 ERNIE-4.5-21B-A3B-Thinking
huggingface.co/baidu/ERNIE-...
✨ Small MoE - Apache 2.0
✨ 128K context length for deep reasoning
✨ Efficient tool usage capabilities
huggingface.co/baidu/ERNIE-...
✨ Small MoE - Apache 2.0
✨ 128K context length for deep reasoning
✨ Efficient tool usage capabilities
MiniCPM4.1🔥New edge-side LLM built for efficiency + reasoning from OpenBMB
huggingface.co/openbmb/Mini...
✨ 8B - Apache 2.0
✨ Hybrid reasoning model: deep reasoning +fast inference.
✨5x faster on edge chips, 90% smaller (BitCPM)
✨Trained on UltraClean + UltraChat v2 data
huggingface.co/openbmb/Mini...
✨ 8B - Apache 2.0
✨ Hybrid reasoning model: deep reasoning +fast inference.
✨5x faster on edge chips, 90% smaller (BitCPM)
✨Trained on UltraClean + UltraChat v2 data

openbmb/MiniCPM4.1-8B · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
September 6, 2025 at 1:57 PM
MiniCPM4.1🔥New edge-side LLM built for efficiency + reasoning from OpenBMB
huggingface.co/openbmb/Mini...
✨ 8B - Apache 2.0
✨ Hybrid reasoning model: deep reasoning +fast inference.
✨5x faster on edge chips, 90% smaller (BitCPM)
✨Trained on UltraClean + UltraChat v2 data
huggingface.co/openbmb/Mini...
✨ 8B - Apache 2.0
✨ Hybrid reasoning model: deep reasoning +fast inference.
✨5x faster on edge chips, 90% smaller (BitCPM)
✨Trained on UltraClean + UltraChat v2 data
Inverse IFEval 🔥New benchmark from Bytedance & MAP
huggingface.co/datasets/m-a...
huggingface.co/papers/2509....
Testing LLMs on their ability to override biases & follow adversarial instructions.
✨ 8 challenge types
✨ 1,012 CN/EN Qs across 23 domains
✨ Human-in-the-loop + LLM-as-a-Judge
huggingface.co/datasets/m-a...
huggingface.co/papers/2509....
Testing LLMs on their ability to override biases & follow adversarial instructions.
✨ 8 challenge types
✨ 1,012 CN/EN Qs across 23 domains
✨ Human-in-the-loop + LLM-as-a-Judge

m-a-p/Inverse_IFEval · Datasets at Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
September 5, 2025 at 2:28 PM
Inverse IFEval 🔥New benchmark from Bytedance & MAP
huggingface.co/datasets/m-a...
huggingface.co/papers/2509....
Testing LLMs on their ability to override biases & follow adversarial instructions.
✨ 8 challenge types
✨ 1,012 CN/EN Qs across 23 domains
✨ Human-in-the-loop + LLM-as-a-Judge
huggingface.co/datasets/m-a...
huggingface.co/papers/2509....
Testing LLMs on their ability to override biases & follow adversarial instructions.
✨ 8 challenge types
✨ 1,012 CN/EN Qs across 23 domains
✨ Human-in-the-loop + LLM-as-a-Judge
Klear-46B-A2.5🔥 a sparse MoE LLM developed by the Kwai-Klear Team at Kuaishou
huggingface.co/collections/...
✨ 46B total / 2.5B active - Apache2.0
✨ Dense-level performance at lower cost
✨ Trained on 22T tokens with progressive curriculum
✨ 64K context length
huggingface.co/collections/...
✨ 46B total / 2.5B active - Apache2.0
✨ Dense-level performance at lower cost
✨ Trained on 22T tokens with progressive curriculum
✨ 64K context length

Klear1.0 - a Kwai-Klear Collection
Klear1.0
huggingface.co
September 5, 2025 at 1:42 PM
Klear-46B-A2.5🔥 a sparse MoE LLM developed by the Kwai-Klear Team at Kuaishou
huggingface.co/collections/...
✨ 46B total / 2.5B active - Apache2.0
✨ Dense-level performance at lower cost
✨ Trained on 22T tokens with progressive curriculum
✨ 64K context length
huggingface.co/collections/...
✨ 46B total / 2.5B active - Apache2.0
✨ Dense-level performance at lower cost
✨ Trained on 22T tokens with progressive curriculum
✨ 64K context length
Latest update from Moonshot AI
Kimi K2 >>> Kimi K2-Instruct-0905🔥
huggingface.co/moonshotai/K...
✨ 32B activated / 1T total parameters
✨ Enhanced agentic coding intelligence
✨ Better frontend coding experience
✨ 256K context window for long horizon tasks
Kimi K2 >>> Kimi K2-Instruct-0905🔥
huggingface.co/moonshotai/K...
✨ 32B activated / 1T total parameters
✨ Enhanced agentic coding intelligence
✨ Better frontend coding experience
✨ 256K context window for long horizon tasks

moonshotai/Kimi-K2-Instruct-0905 · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
September 5, 2025 at 7:09 AM
Latest update from Moonshot AI
Kimi K2 >>> Kimi K2-Instruct-0905🔥
huggingface.co/moonshotai/K...
✨ 32B activated / 1T total parameters
✨ Enhanced agentic coding intelligence
✨ Better frontend coding experience
✨ 256K context window for long horizon tasks
Kimi K2 >>> Kimi K2-Instruct-0905🔥
huggingface.co/moonshotai/K...
✨ 32B activated / 1T total parameters
✨ Enhanced agentic coding intelligence
✨ Better frontend coding experience
✨ 256K context window for long horizon tasks

From food delivery to frontier AI 🚀 Meituan, the leading lifestyle platform just dropped its first open SoTA LLM: LongCat-Flash 🔥
huggingface.co/meituan-long...
huggingface.co/meituan-long...

meituan-longcat/LongCat-Flash-Chat · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
September 1, 2025 at 8:26 AM
From food delivery to frontier AI 🚀 Meituan, the leading lifestyle platform just dropped its first open SoTA LLM: LongCat-Flash 🔥
huggingface.co/meituan-long...
huggingface.co/meituan-long...
USO 🎨 Unified customization model released by Bytedance research
Demo
huggingface.co/spaces/byted...
Model
huggingface.co/bytedance-re...
Paper
huggingface.co/papers/2508....
Demo
huggingface.co/spaces/byted...
Model
huggingface.co/bytedance-re...
Paper
huggingface.co/papers/2508....

USO - a Hugging Face Space by bytedance-research
Create custom images by combining different styles and subjects. Upload content and style images, or use text prompts to generate photorealistic portraits or styled images.
huggingface.co
August 29, 2025 at 9:18 AM
USO 🎨 Unified customization model released by Bytedance research
Demo
huggingface.co/spaces/byted...
Model
huggingface.co/bytedance-re...
Paper
huggingface.co/papers/2508....
Demo
huggingface.co/spaces/byted...
Model
huggingface.co/bytedance-re...
Paper
huggingface.co/papers/2508....
Step-Audio 2🔥 New end to end multimodal LLM for audio & speech, released by StepFun
huggingface.co/collections/...
huggingface.co/collections/...

Step-Audio 2 - a stepfun-ai Collection
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
August 29, 2025 at 8:45 AM
Step-Audio 2🔥 New end to end multimodal LLM for audio & speech, released by StepFun
huggingface.co/collections/...
huggingface.co/collections/...
🇨🇳 China’s State Council just released its “AI+” Action Plan (2025)
huggingface.co/spaces/zh-ai...
✨Goal: By 2035, AI will deeply empower all sectors, reshape productivity & society
✨Focus on 6 pillars:
>Science & Tech
>Industry
>Consumption
>Public welfare
>Governance
>Global cooperation
huggingface.co/spaces/zh-ai...
✨Goal: By 2035, AI will deeply empower all sectors, reshape productivity & society
✨Focus on 6 pillars:
>Science & Tech
>Industry
>Consumption
>Public welfare
>Governance
>Global cooperation

China AI policy research 🤗 - a Hugging Face Space by zh-ai-community
Browse and filter through key AI policy documents from China, covering various topics like domestic development, international cooperation, safety, data management, industry standards, and ethics. ...
huggingface.co
August 26, 2025 at 11:41 AM
🇨🇳 China’s State Council just released its “AI+” Action Plan (2025)
huggingface.co/spaces/zh-ai...
✨Goal: By 2035, AI will deeply empower all sectors, reshape productivity & society
✨Focus on 6 pillars:
>Science & Tech
>Industry
>Consumption
>Public welfare
>Governance
>Global cooperation
huggingface.co/spaces/zh-ai...
✨Goal: By 2035, AI will deeply empower all sectors, reshape productivity & society
✨Focus on 6 pillars:
>Science & Tech
>Industry
>Consumption
>Public welfare
>Governance
>Global cooperation
MiniCPM-V 4.5 🚀 New MLLM for image, multi-image & video understanding, running even on your phone, released by OpenBMB
huggingface.co/openbmb/Mini...
huggingface.co/openbmb/Mini...

openbmb/MiniCPM-V-4_5 · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
August 26, 2025 at 10:49 AM
MiniCPM-V 4.5 🚀 New MLLM for image, multi-image & video understanding, running even on your phone, released by OpenBMB
huggingface.co/openbmb/Mini...
huggingface.co/openbmb/Mini...
InternVL3.5 🔥 New family of multimodal model by Shanghai AI lab @opengvlab
huggingface.co/collections/...
✨ 1B · 2B · 4B · 8B · 14B · 38B | MoE → 20B-A4B · 30B-A3B · 241B-A28B 📄Apache 2.0
✨ +16% reasoning performance, 4.05× speedup vs InternVL3
huggingface.co/collections/...
✨ 1B · 2B · 4B · 8B · 14B · 38B | MoE → 20B-A4B · 30B-A3B · 241B-A28B 📄Apache 2.0
✨ +16% reasoning performance, 4.05× speedup vs InternVL3

InternVL3.5 - a OpenGVLab Collection
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
August 26, 2025 at 10:33 AM
InternVL3.5 🔥 New family of multimodal model by Shanghai AI lab @opengvlab
huggingface.co/collections/...
✨ 1B · 2B · 4B · 8B · 14B · 38B | MoE → 20B-A4B · 30B-A3B · 241B-A28B 📄Apache 2.0
✨ +16% reasoning performance, 4.05× speedup vs InternVL3
huggingface.co/collections/...
✨ 1B · 2B · 4B · 8B · 14B · 38B | MoE → 20B-A4B · 30B-A3B · 241B-A28B 📄Apache 2.0
✨ +16% reasoning performance, 4.05× speedup vs InternVL3
Intern-S1-mini 🔥 lightweight open multimodal reasoning model by Shanghai AI Lab.
huggingface.co/internlm/Int...
✨ Efficient 8B LLM + 0.3B vision encoder
✨ Apache 2.0
✨ 5T multimodal pretraining, 50%+ in scientific domains
✨ Dynamic tokenizer for molecules & protein sequences
huggingface.co/internlm/Int...
✨ Efficient 8B LLM + 0.3B vision encoder
✨ Apache 2.0
✨ 5T multimodal pretraining, 50%+ in scientific domains
✨ Dynamic tokenizer for molecules & protein sequences

internlm/Intern-S1-mini · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
August 21, 2025 at 1:28 PM
Intern-S1-mini 🔥 lightweight open multimodal reasoning model by Shanghai AI Lab.
huggingface.co/internlm/Int...
✨ Efficient 8B LLM + 0.3B vision encoder
✨ Apache 2.0
✨ 5T multimodal pretraining, 50%+ in scientific domains
✨ Dynamic tokenizer for molecules & protein sequences
huggingface.co/internlm/Int...
✨ Efficient 8B LLM + 0.3B vision encoder
✨ Apache 2.0
✨ 5T multimodal pretraining, 50%+ in scientific domains
✨ Dynamic tokenizer for molecules & protein sequences
Seed-OSS 🔥 The latest open LLM from Bytedance Seed team
huggingface.co/collections/...
✨ 36B - Base & Instruct
✨ Apache 2.0
✨ Native 512K long context
✨ Strong reasoning & agentic intelligence
✨ 2 Base versions: with & without synthetic data
huggingface.co/collections/...
✨ 36B - Base & Instruct
✨ Apache 2.0
✨ Native 512K long context
✨ Strong reasoning & agentic intelligence
✨ 2 Base versions: with & without synthetic data

Seed-OSS - a ByteDance-Seed Collection
Seed-OSS Open-Source Models
huggingface.co
August 20, 2025 at 6:40 PM
Seed-OSS 🔥 The latest open LLM from Bytedance Seed team
huggingface.co/collections/...
✨ 36B - Base & Instruct
✨ Apache 2.0
✨ Native 512K long context
✨ Strong reasoning & agentic intelligence
✨ 2 Base versions: with & without synthetic data
huggingface.co/collections/...
✨ 36B - Base & Instruct
✨ Apache 2.0
✨ Native 512K long context
✨ Strong reasoning & agentic intelligence
✨ 2 Base versions: with & without synthetic data

Before my vacation: Qwen releasing.
When I came back: Qwen still releasing
Respect!!🫡
Qwen Image Edit 🔥 the image editing version of Qwen-Image by Alibaba Qwen
huggingface.co/Qwen/Qwen-Im...
When I came back: Qwen still releasing
Respect!!🫡
Qwen Image Edit 🔥 the image editing version of Qwen-Image by Alibaba Qwen
huggingface.co/Qwen/Qwen-Im...

Qwen/Qwen-Image-Edit · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
August 18, 2025 at 6:12 PM
Before my vacation: Qwen releasing.
When I came back: Qwen still releasing
Respect!!🫡
Qwen Image Edit 🔥 the image editing version of Qwen-Image by Alibaba Qwen
huggingface.co/Qwen/Qwen-Im...
When I came back: Qwen still releasing
Respect!!🫡
Qwen Image Edit 🔥 the image editing version of Qwen-Image by Alibaba Qwen
huggingface.co/Qwen/Qwen-Im...
🔥 July highlights from Chinese AI community
huggingface.co/collections/...
I’ve been tracking things closely, but July’s open-source wave still managed to surprise me.
Can’t wait to see what’s coming next! 🚀
huggingface.co/collections/...
I’ve been tracking things closely, but July’s open-source wave still managed to surprise me.
Can’t wait to see what’s coming next! 🚀

🧩 July 2025 - Open works from the Chinese community - a zh-ai-community Collection
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
July 31, 2025 at 8:43 PM
🔥 July highlights from Chinese AI community
huggingface.co/collections/...
I’ve been tracking things closely, but July’s open-source wave still managed to surprise me.
Can’t wait to see what’s coming next! 🚀
huggingface.co/collections/...
I’ve been tracking things closely, but July’s open-source wave still managed to surprise me.
Can’t wait to see what’s coming next! 🚀
Qwen team did it again!🔥
They just released Qwen3-Coder-30B-A3B-Instruct on the hub
huggingface.co/Qwen/Qwen3-C...
✨ Apache 2.0
✨30B total / 3.3B active (128 experts, 8 top-k)
✨ Native 256K context, extendable to 1M via Yarn
✨ Built for Agentic Coding
They just released Qwen3-Coder-30B-A3B-Instruct on the hub
huggingface.co/Qwen/Qwen3-C...
✨ Apache 2.0
✨30B total / 3.3B active (128 experts, 8 top-k)
✨ Native 256K context, extendable to 1M via Yarn
✨ Built for Agentic Coding

Qwen/Qwen3-Coder-30B-A3B-Instruct · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
July 31, 2025 at 2:58 PM
Qwen team did it again!🔥
They just released Qwen3-Coder-30B-A3B-Instruct on the hub
huggingface.co/Qwen/Qwen3-C...
✨ Apache 2.0
✨30B total / 3.3B active (128 experts, 8 top-k)
✨ Native 256K context, extendable to 1M via Yarn
✨ Built for Agentic Coding
They just released Qwen3-Coder-30B-A3B-Instruct on the hub
huggingface.co/Qwen/Qwen3-C...
✨ Apache 2.0
✨30B total / 3.3B active (128 experts, 8 top-k)
✨ Native 256K context, extendable to 1M via Yarn
✨ Built for Agentic Coding
It’s here! After the WAIC announcement, StepFun has just dropped Step 3 🔥 their latest multimodal reasoning model on the hub.
Model: huggingface.co/stepfun-ai/s...
Paper: huggingface.co/papers/2507....
Model: huggingface.co/stepfun-ai/s...
Paper: huggingface.co/papers/2507....
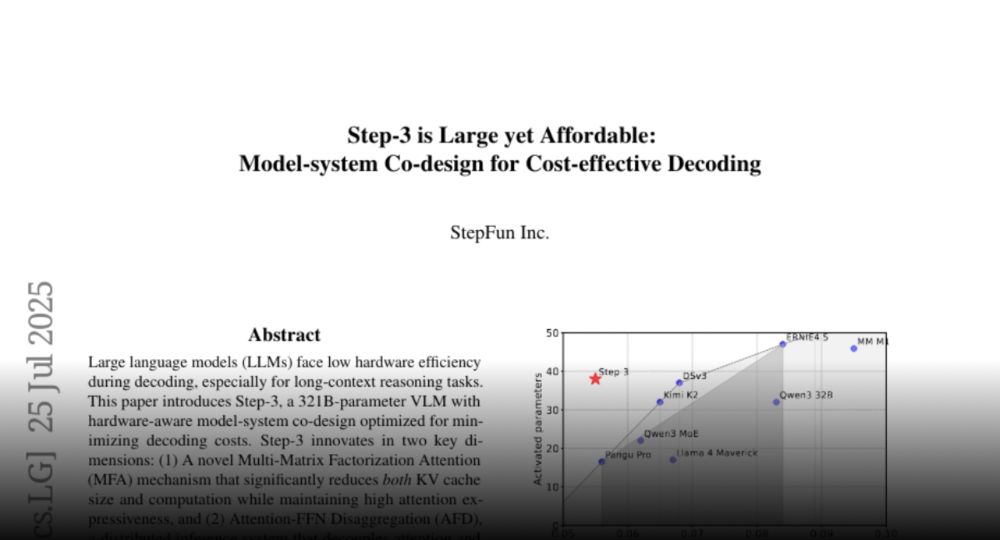
Paper page - Step-3 is Large yet Affordable: Model-system Co-design for
Cost-effective Decoding
Join the discussion on this paper page
huggingface.co
July 31, 2025 at 1:39 PM
It’s here! After the WAIC announcement, StepFun has just dropped Step 3 🔥 their latest multimodal reasoning model on the hub.
Model: huggingface.co/stepfun-ai/s...
Paper: huggingface.co/papers/2507....
Model: huggingface.co/stepfun-ai/s...
Paper: huggingface.co/papers/2507....
Qwen3-30B-A3B-Thinking-2507 🔥 latest step in scaling thinking capabilities from Alibaba_Qwen
huggingface.co/Qwen/Qwen3-3...
✨ 30B total / 3B active - Apache 2.0
✨ Native 256K context
✨ SOTA coding, alignment, agentic reasoning
huggingface.co/Qwen/Qwen3-3...
✨ 30B total / 3B active - Apache 2.0
✨ Native 256K context
✨ SOTA coding, alignment, agentic reasoning

Qwen/Qwen3-30B-A3B-Thinking-2507-FP8 · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
July 30, 2025 at 4:00 PM
Qwen3-30B-A3B-Thinking-2507 🔥 latest step in scaling thinking capabilities from Alibaba_Qwen
huggingface.co/Qwen/Qwen3-3...
✨ 30B total / 3B active - Apache 2.0
✨ Native 256K context
✨ SOTA coding, alignment, agentic reasoning
huggingface.co/Qwen/Qwen3-3...
✨ 30B total / 3B active - Apache 2.0
✨ Native 256K context
✨ SOTA coding, alignment, agentic reasoning
Skywork UniPic 🔥a unified autoregressive multimodal model for image understanding, generation, & editing, by Skywork
huggingface.co/collections/...
✨ 1.5 B - MIT License
✨ Runs on RTX 4090
✨ Truly unified architecture
huggingface.co/collections/...
✨ 1.5 B - MIT License
✨ Runs on RTX 4090
✨ Truly unified architecture

Skywork-UniPic - a Skywork Collection
Unified Autoregressive Modeling for Visual Understanding and Generation
huggingface.co
July 30, 2025 at 9:01 AM
Skywork UniPic 🔥a unified autoregressive multimodal model for image understanding, generation, & editing, by Skywork
huggingface.co/collections/...
✨ 1.5 B - MIT License
✨ Runs on RTX 4090
✨ Truly unified architecture
huggingface.co/collections/...
✨ 1.5 B - MIT License
✨ Runs on RTX 4090
✨ Truly unified architecture
Qwen just released Qwen3-30B-A3B-Instruct-2507 🔥 an upgrade to the non-thinking mode model
huggingface.co/Qwen/Qwen3-3...
✨ 30B MoE / 3.3B active - Apache 2.0
✨ Strong gains in reasoning, math, coding, & multilingual tasks
✨ Native support for 256K long-context inputs
huggingface.co/Qwen/Qwen3-3...
✨ 30B MoE / 3.3B active - Apache 2.0
✨ Strong gains in reasoning, math, coding, & multilingual tasks
✨ Native support for 256K long-context inputs

Qwen/Qwen3-30B-A3B-Instruct-2507 · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
July 29, 2025 at 5:18 PM
Qwen just released Qwen3-30B-A3B-Instruct-2507 🔥 an upgrade to the non-thinking mode model
huggingface.co/Qwen/Qwen3-3...
✨ 30B MoE / 3.3B active - Apache 2.0
✨ Strong gains in reasoning, math, coding, & multilingual tasks
✨ Native support for 256K long-context inputs
huggingface.co/Qwen/Qwen3-3...
✨ 30B MoE / 3.3B active - Apache 2.0
✨ Strong gains in reasoning, math, coding, & multilingual tasks
✨ Native support for 256K long-context inputs
Wan2.2 🔥A video diffusion model with MoE just released by Alibaba_Wan
huggingface.co/Wan-AI/Wan2....
huggingface.co/Wan-AI/Wan2....
huggingface.co/Wan-AI/Wan2....
huggingface.co/Wan-AI/Wan2....

July 28, 2025 at 1:46 PM
Wan2.2 🔥A video diffusion model with MoE just released by Alibaba_Wan
huggingface.co/Wan-AI/Wan2....
huggingface.co/Wan-AI/Wan2....
huggingface.co/Wan-AI/Wan2....
huggingface.co/Wan-AI/Wan2....
GLM-4.5 🔥 The largest open models yet from Zhipu AI.
Built for intelligent agents with unified capabilities: reasoning, coding, tool use.
huggingface.co/collections/...
✨ 355B total / 32B active - MIT license
✨ Hybrid modes: Thinking mode for complex tasks/ Non-thinking mode for instant replies
Built for intelligent agents with unified capabilities: reasoning, coding, tool use.
huggingface.co/collections/...
✨ 355B total / 32B active - MIT license
✨ Hybrid modes: Thinking mode for complex tasks/ Non-thinking mode for instant replies
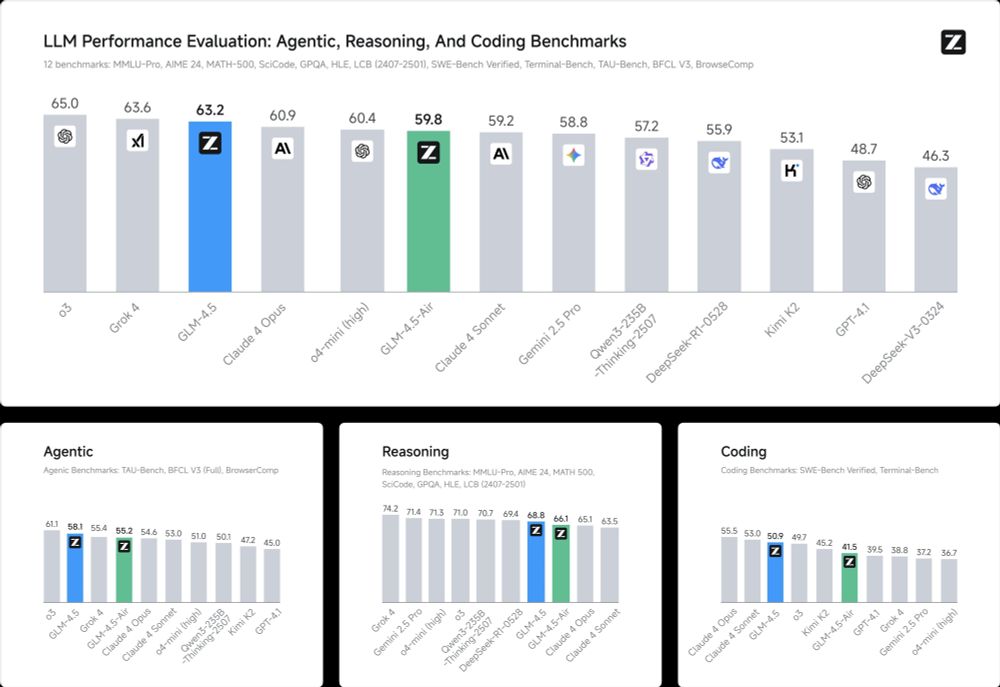
July 28, 2025 at 1:28 PM
GLM-4.5 🔥 The largest open models yet from Zhipu AI.
Built for intelligent agents with unified capabilities: reasoning, coding, tool use.
huggingface.co/collections/...
✨ 355B total / 32B active - MIT license
✨ Hybrid modes: Thinking mode for complex tasks/ Non-thinking mode for instant replies
Built for intelligent agents with unified capabilities: reasoning, coding, tool use.
huggingface.co/collections/...
✨ 355B total / 32B active - MIT license
✨ Hybrid modes: Thinking mode for complex tasks/ Non-thinking mode for instant replies