



Please check out our work!
📄 Preprint: arxiv.org/abs/2506.08641
💻 Code: github.com/ExplainableM...
#TimeSeries #VisionTransformer #FoundationModel
📄 Preprint: arxiv.org/abs/2506.08641
💻 Code: github.com/ExplainableM...
#TimeSeries #VisionTransformer #FoundationModel

GitHub - ExplainableML/TiViT: Time Vision Transformer
Time Vision Transformer. Contribute to ExplainableML/TiViT development by creating an account on GitHub.
github.com
July 3, 2025 at 7:59 AM
Please check out our work!
📄 Preprint: arxiv.org/abs/2506.08641
💻 Code: github.com/ExplainableM...
#TimeSeries #VisionTransformer #FoundationModel
📄 Preprint: arxiv.org/abs/2506.08641
💻 Code: github.com/ExplainableM...
#TimeSeries #VisionTransformer #FoundationModel

#3 GlaViTU
This paper presents a novel world-wide dataset and a novel convolutional-transformer, named Glacier-VisionTransformer-U-Net (GlaViTU), for multitemporal and global glacier mapping.
⬆️ relevant task and nice results
⬇️ weak zero-shot transferability?
www.nature.com/articles/s41...
This paper presents a novel world-wide dataset and a novel convolutional-transformer, named Glacier-VisionTransformer-U-Net (GlaViTU), for multitemporal and global glacier mapping.
⬆️ relevant task and nice results
⬇️ weak zero-shot transferability?
www.nature.com/articles/s41...

Globally scalable glacier mapping by deep learning matches expert delineation accuracy - Nature Communications
A deep learning model using open satellite data for scalable, global glacier mapping is developed. This model matches expert-level accuracy, facilitating more reliable glacier monitoring to support cl...
www.nature.com
February 5, 2025 at 1:24 PM
#3 GlaViTU
This paper presents a novel world-wide dataset and a novel convolutional-transformer, named Glacier-VisionTransformer-U-Net (GlaViTU), for multitemporal and global glacier mapping.
⬆️ relevant task and nice results
⬇️ weak zero-shot transferability?
www.nature.com/articles/s41...
This paper presents a novel world-wide dataset and a novel convolutional-transformer, named Glacier-VisionTransformer-U-Net (GlaViTU), for multitemporal and global glacier mapping.
⬆️ relevant task and nice results
⬇️ weak zero-shot transferability?
www.nature.com/articles/s41...

MR-Transformer: A Vision Transformer-based Deep Learning Model for Total Knee Replacement Prediction Using MRI https://doi.org/10.1148/ryai.240373 @cem.bsky.social @cai2r.net #MSKRad #DJD #VisionTransformer

September 6, 2025 at 7:15 PM
MR-Transformer: A Vision Transformer-based Deep Learning Model for Total Knee Replacement Prediction Using MRI https://doi.org/10.1148/ryai.240373 @cem.bsky.social @cai2r.net #MSKRad #DJD #VisionTransformer

Orthogonal Residual Updates add only the component orthogonal to the activation stream; a ViT‑B model gained +4.3% top‑1 accuracy on ImageNet‑1k benchmark tests. Read more: https://getnews.me/orthogonal-residual-updates-improve-stability-and-accuracy-in-deep-networks/ #neurips2025 #visiontransformer

September 27, 2025 at 1:56 AM
Orthogonal Residual Updates add only the component orthogonal to the activation stream; a ViT‑B model gained +4.3% top‑1 accuracy on ImageNet‑1k benchmark tests. Read more: https://getnews.me/orthogonal-residual-updates-improve-stability-and-accuracy-in-deep-networks/ #neurips2025 #visiontransformer
A new progressive adaptation for Swin Transformers improves accuracy on PASCAL and NYUD‑v2 while using only about 20% of the trainable parameters of a fully fine‑tuned model. https://getnews.me/parameter-efficient-multi-task-learning-reduces-model-size-by-fivefold/ #multitask #visiontransformer

September 26, 2025 at 3:10 PM
A new progressive adaptation for Swin Transformers improves accuracy on PASCAL and NYUD‑v2 while using only about 20% of the trainable parameters of a fully fine‑tuned model. https://getnews.me/parameter-efficient-multi-task-learning-reduces-model-size-by-fivefold/ #multitask #visiontransformer
Researchers reproduced the Vision Transformer study and found Diffusion Denoised Smoothing boosts explanation‑map robustness, though it adds extra overhead. Read more: https://getnews.me/reproducing-vision-transformers-with-diffusion-denoised-smoothing/ #visiontransformer #diffusiondenoisedsmoothing

September 19, 2025 at 11:30 PM
Researchers reproduced the Vision Transformer study and found Diffusion Denoised Smoothing boosts explanation‑map robustness, though it adds extra overhead. Read more: https://getnews.me/reproducing-vision-transformers-with-diffusion-denoised-smoothing/ #visiontransformer #diffusiondenoisedsmoothing
EfficienT‑HDR cuts FLOPS by ~67% and boosts CPU inference speed over fivefold, with about 2.5× speedup on edge processors, delivering HDR quality without ghosting. Read more: https://getnews.me/efficient-hdr-lightweight-transformer-improves-edge-hdr-imaging/ #efficienthdr #visiontransformer #edgeai

September 26, 2025 at 5:13 PM
EfficienT‑HDR cuts FLOPS by ~67% and boosts CPU inference speed over fivefold, with about 2.5× speedup on edge processors, delivering HDR quality without ghosting. Read more: https://getnews.me/efficient-hdr-lightweight-transformer-improves-edge-hdr-imaging/ #efficienthdr #visiontransformer #edgeai
Activation‑space tuning (NoRA) updates only 0.4% of a vision transformer’s parameters (~0.02 M) and yields +0.17% accuracy on CIFAR‑10 and +0.27% on CIFAR‑100. Read more: https://getnews.me/activation-space-tuning-improves-parameter-efficient-fine-tuning/ #activationtuning #peft #visiontransformer

September 18, 2025 at 5:23 PM
Activation‑space tuning (NoRA) updates only 0.4% of a vision transformer’s parameters (~0.02 M) and yields +0.17% accuracy on CIFAR‑10 and +0.27% on CIFAR‑100. Read more: https://getnews.me/activation-space-tuning-improves-parameter-efficient-fine-tuning/ #activationtuning #peft #visiontransformer

I posted my blog about Genie🧙
skyfoliage.com/pubstore/cm0...
or copied version is written in medium
medium.com/@taks.skyfol...
#magic #genie #vision #game #creator #environment #transformer #VisionTransformer #ICML #google #DeepMind #skyfoliage.com
skyfoliage.com/pubstore/cm0...
or copied version is written in medium
medium.com/@taks.skyfol...
#magic #genie #vision #game #creator #environment #transformer #VisionTransformer #ICML #google #DeepMind #skyfoliage.com
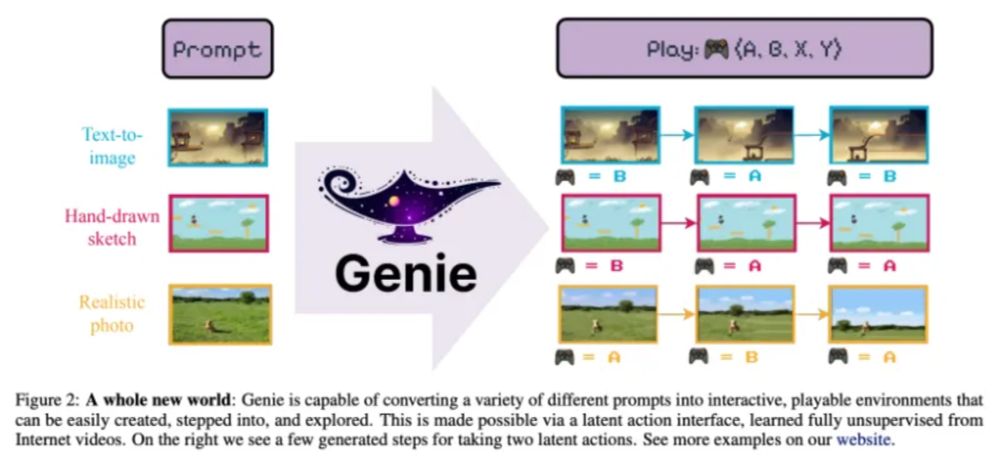
skyfoliage.com: Will Game Developers Lose Their Jobs to AI?
This article describe about a paper of Genie in ICML 2024.
skyfoliage.com
August 23, 2024 at 5:44 PM
I posted my blog about Genie🧙
skyfoliage.com/pubstore/cm0...
or copied version is written in medium
medium.com/@taks.skyfol...
#magic #genie #vision #game #creator #environment #transformer #VisionTransformer #ICML #google #DeepMind #skyfoliage.com
skyfoliage.com/pubstore/cm0...
or copied version is written in medium
medium.com/@taks.skyfol...
#magic #genie #vision #game #creator #environment #transformer #VisionTransformer #ICML #google #DeepMind #skyfoliage.com
PVTAdpNet combines U‑Net and a Pyramid Vision Transformer, achieving a Dice score of 0.8851 and mIoU 0.8167 for real‑time polyp segmentation on standard GPUs. https://getnews.me/pvtadpnet-boosts-real-time-polyp-segmentation-with-vision-transformers/ #polypsegmentation #visiontransformer

September 30, 2025 at 1:22 PM
PVTAdpNet combines U‑Net and a Pyramid Vision Transformer, achieving a Dice score of 0.8851 and mIoU 0.8167 for real‑time polyp segmentation on standard GPUs. https://getnews.me/pvtadpnet-boosts-real-time-polyp-segmentation-with-vision-transformers/ #polypsegmentation #visiontransformer
A new hyperspectral adapter linking vision transformers achieved segmentation accuracy on three autonomous‑driving benchmarks, training on small datasets. Read more: https://getnews.me/hyperspectral-adapter-improves-semantic-segmentation-via-vision-models/ #hyperspectral #visiontransformer

September 26, 2025 at 8:00 PM
A new hyperspectral adapter linking vision transformers achieved segmentation accuracy on three autonomous‑driving benchmarks, training on small datasets. Read more: https://getnews.me/hyperspectral-adapter-improves-semantic-segmentation-via-vision-models/ #hyperspectral #visiontransformer

New AI model sets benchmark in digital pathology with superior cancer diagnostics 🤖🔬🧬 www.news-medical.net/news/2024052... #ProvGigaPath #Digital #Pathology #Cancer #Diagnostics #AI #Healthcare #VisionTransformer #MachineLearning #HealthTech @natureportfolio.bsky.social

New AI model sets benchmark in digital pathology with superior cancer diagnostics
Researchers developed Prov-GigaPath, a whole-slide pathology foundation model using a novel vision transformer architecture. The model demonstrates superior performance in mutation prediction, cancer ...
www.news-medical.net
May 24, 2024 at 1:09 AM
New AI model sets benchmark in digital pathology with superior cancer diagnostics 🤖🔬🧬 www.news-medical.net/news/2024052... #ProvGigaPath #Digital #Pathology #Cancer #Diagnostics #AI #Healthcare #VisionTransformer #MachineLearning #HealthTech @natureportfolio.bsky.social
VPNeXt, a simplified Vision Transformer model, beats the prior state‑of‑the‑art mIoU on the VOC2012 benchmark, with its version 3 released on September 27 2025. Read more: https://getnews.me/vpnext-rethinks-dense-decoding-for-vision-transformers/ #vpnext #visiontransformer #semanticsegmentation

October 1, 2025 at 11:34 AM
VPNeXt, a simplified Vision Transformer model, beats the prior state‑of‑the‑art mIoU on the VOC2012 benchmark, with its version 3 released on September 27 2025. Read more: https://getnews.me/vpnext-rethinks-dense-decoding-for-vision-transformers/ #vpnext #visiontransformer #semanticsegmentation
I‑Segmenter is the first fully integer‑only Vision Transformer for semantic segmentation, achieving only a 5.1 % accuracy gap to FP32 while shrinking model size up to 3.8×. Read more: https://getnews.me/i-segmenter-vision-transformer-for-efficient-segmentation/ #visiontransformer #segmentation

September 17, 2025 at 6:00 AM
I‑Segmenter is the first fully integer‑only Vision Transformer for semantic segmentation, achieving only a 5.1 % accuracy gap to FP32 while shrinking model size up to 3.8×. Read more: https://getnews.me/i-segmenter-vision-transformer-for-efficient-segmentation/ #visiontransformer #segmentation
MR-Transformer: A Vision Transformer-based Deep Learning Model for Total Knee Replacement Prediction Using MRI https://doi.org/10.1148/ryai.240373 @cem.bsky.social @cai2r.net #MSKRad #MachineLearning #VisionTransformer

October 22, 2025 at 7:15 PM
MR-Transformer: A Vision Transformer-based Deep Learning Model for Total Knee Replacement Prediction Using MRI https://doi.org/10.1148/ryai.240373 @cem.bsky.social @cai2r.net #MSKRad #MachineLearning #VisionTransformer
ViTP embeds a Vision Transformer in a Vision‑Language Model, was tested on 16 remote‑sensing & medical benchmarks and achieved scores. Code on GitHub. Read more: https://getnews.me/visual-instruction-pretraining-boosts-domain-specific-vision-models/ #visualinstructionpretraining #visiontransformer

September 24, 2025 at 11:48 PM
ViTP embeds a Vision Transformer in a Vision‑Language Model, was tested on 16 remote‑sensing & medical benchmarks and achieved scores. Code on GitHub. Read more: https://getnews.me/visual-instruction-pretraining-boosts-domain-specific-vision-models/ #visualinstructionpretraining #visiontransformer
MR-Transformer predicts knee osteoarthritis progression to joint replacement using MRI https://doi.org/10.1148/ryai.240373 @cem.bsky.social @cai2r.net #DJD #VisionTransformer #ML

September 3, 2025 at 7:15 PM
MR-Transformer predicts knee osteoarthritis progression to joint replacement using MRI https://doi.org/10.1148/ryai.240373 @cem.bsky.social @cai2r.net #DJD #VisionTransformer #ML
A framework merging an autoencoder with a Vision Transformer raised dental age‑estimation accuracy to 0.815 for second molars and 0.543 for third molars. https://getnews.me/autoencoder-vision-transformer-boosts-dental-age-estimation-accuracy/ #dentalage #visiontransformer

September 17, 2025 at 12:54 AM
A framework merging an autoencoder with a Vision Transformer raised dental age‑estimation accuracy to 0.815 for second molars and 0.543 for third molars. https://getnews.me/autoencoder-vision-transformer-boosts-dental-age-estimation-accuracy/ #dentalage #visiontransformer