



CIRCE is a Python package based on #AnnData and fully compatible with the #scverse environment.
You can extract DNA region modules & visualize CIRCE's interactions over gene locations.
CIRCE also facilitates #CellOracle or #HuMMuS usage, making it unnecessary to run Cicero (code in R) first.
4/5
You can extract DNA region modules & visualize CIRCE's interactions over gene locations.
CIRCE also facilitates #CellOracle or #HuMMuS usage, making it unnecessary to run Cicero (code in R) first.
4/5

September 30, 2025 at 12:23 PM
CIRCE is a Python package based on #AnnData and fully compatible with the #scverse environment.
You can extract DNA region modules & visualize CIRCE's interactions over gene locations.
CIRCE also facilitates #CellOracle or #HuMMuS usage, making it unnecessary to run Cicero (code in R) first.
4/5
You can extract DNA region modules & visualize CIRCE's interactions over gene locations.
CIRCE also facilitates #CellOracle or #HuMMuS usage, making it unnecessary to run Cicero (code in R) first.
4/5

6/
The new .h5sc format provides fast random access to single-cell images for ML training.
It follows #FAIR data principles (findable, accessible, interoperable, reusable) and integrates with @scverse.bsky.social tools via AnnData.
The new .h5sc format provides fast random access to single-cell images for ML training.
It follows #FAIR data principles (findable, accessible, interoperable, reusable) and integrates with @scverse.bsky.social tools via AnnData.

September 24, 2025 at 12:22 PM
6/
The new .h5sc format provides fast random access to single-cell images for ML training.
It follows #FAIR data principles (findable, accessible, interoperable, reusable) and integrates with @scverse.bsky.social tools via AnnData.
The new .h5sc format provides fast random access to single-cell images for ML training.
It follows #FAIR data principles (findable, accessible, interoperable, reusable) and integrates with @scverse.bsky.social tools via AnnData.

New preprint from the @saeyslab.bsky.social by @louisedck.bsky.social --- anndataR brings seamless interoperability between Python’s AnnData (H5AD) and R’s SingleCellExperiment/Seurat — finally bridging the gap between ecosystems. biorxiv.org/content/10.1101/2025.08.18.669052v1

September 17, 2025 at 6:49 AM
New preprint from the @saeyslab.bsky.social by @louisedck.bsky.social --- anndataR brings seamless interoperability between Python’s AnnData (H5AD) and R’s SingleCellExperiment/Seurat — finally bridging the gap between ecosystems. biorxiv.org/content/10.1101/2025.08.18.669052v1

anndataR makes it possible to:
- Read and write H5AD files natively in R
- Convert between AnnData, SingleCellExperiment & Seurat
- Work with AnnData objects in R
If you've struggled with reading H5AD files in R, or single cell format conversion, try out anndataR! anndatar.data-intuitive.com
- Read and write H5AD files natively in R
- Convert between AnnData, SingleCellExperiment & Seurat
- Work with AnnData objects in R
If you've struggled with reading H5AD files in R, or single cell format conversion, try out anndataR! anndatar.data-intuitive.com
www.biorxiv.org
August 25, 2025 at 3:24 PM
anndataR makes it possible to:
- Read and write H5AD files natively in R
- Convert between AnnData, SingleCellExperiment & Seurat
- Work with AnnData objects in R
If you've struggled with reading H5AD files in R, or single cell format conversion, try out anndataR! anndatar.data-intuitive.com
- Read and write H5AD files natively in R
- Convert between AnnData, SingleCellExperiment & Seurat
- Work with AnnData objects in R
If you've struggled with reading H5AD files in R, or single cell format conversion, try out anndataR! anndatar.data-intuitive.com
We're excited to share that our preprint on anndataR, a new package bringing Python's AnnData to R, is now available on bioRxiv 🎉
🔗 Read the paper: www.biorxiv.org/content/10.1...
💻 Check the package in action: anndatar.data-intuitive.com
🔗 Read the paper: www.biorxiv.org/content/10.1...
💻 Check the package in action: anndatar.data-intuitive.com

August 25, 2025 at 3:24 PM
We're excited to share that our preprint on anndataR, a new package bringing Python's AnnData to R, is now available on bioRxiv 🎉
🔗 Read the paper: www.biorxiv.org/content/10.1...
💻 Check the package in action: anndatar.data-intuitive.com
🔗 Read the paper: www.biorxiv.org/content/10.1...
💻 Check the package in action: anndatar.data-intuitive.com

We also now have a new way of extending the anndata API, contributed by a community member, Sri Varra. Users can now extend the anndata API easily, great for building new features and methods directly into the AnnData object: anndata.readthedocs.io/en/stable/ge...
August 11, 2025 at 4:51 PM
We also now have a new way of extending the anndata API, contributed by a community member, Sri Varra. Users can now extend the anndata API easily, great for building new features and methods directly into the AnnData object: anndata.readthedocs.io/en/stable/ge...
Anndata now supports @zarr.dev v3, great for both performance and interoperability. Check out our guide for more info, especially sharding: anndata.readthedocs.io/en/stable/tu.... Don’t worry though, we remain fully v2 backwards compatible - upgrade fearlessly!

August 11, 2025 at 4:51 PM
Anndata now supports @zarr.dev v3, great for both performance and interoperability. Check out our guide for more info, especially sharding: anndata.readthedocs.io/en/stable/tu.... Don’t worry though, we remain fully v2 backwards compatible - upgrade fearlessly!
anndata 0.12 is out now! We have lots of great features that we hope address some persistent needs. Here are some of the highlights!
August 11, 2025 at 4:51 PM
anndata 0.12 is out now! We have lots of great features that we hope address some persistent needs. Here are some of the highlights!

At least you can access the h5 file and find a matrix, though. I agree that getting all AnnData functionality in R is hard (and changes based on which version of scanpy your file was created in), but it's a format you can manually inspect with something like rhdf5 rather than a binary file.
July 25, 2025 at 11:51 AM
At least you can access the h5 file and find a matrix, though. I agree that getting all AnnData functionality in R is hard (and changes based on which version of scanpy your file was created in), but it's a format you can manually inspect with something like rhdf5 rather than a binary file.

h5ad/AnnData have similar problems with how its implemented in Python. it's not really language agnostic.
July 25, 2025 at 11:45 AM
h5ad/AnnData have similar problems with how its implemented in Python. it's not really language agnostic.

Annotated matrices are much more valuable!
AnnData can easily be read into R/Bioc as well unlocking more stats tools.
AnnData can easily be read into R/Bioc as well unlocking more stats tools.

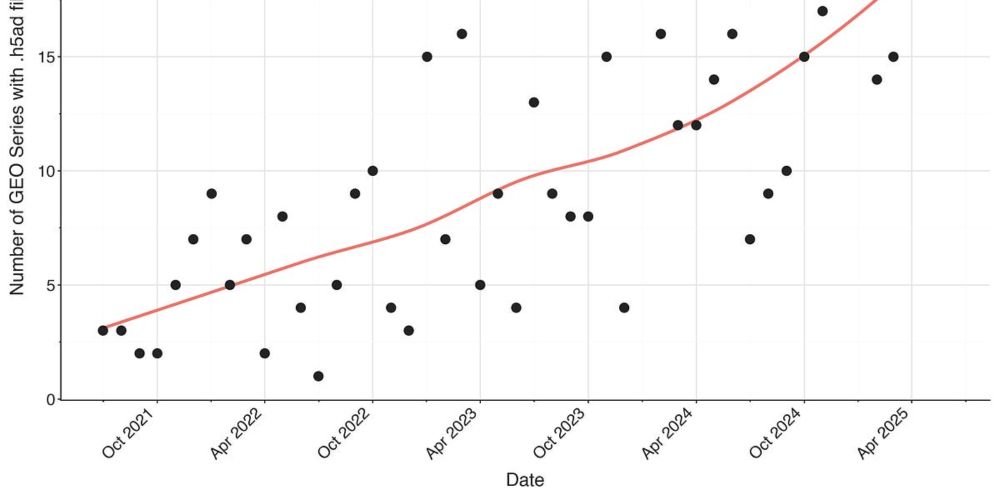
July 25, 2025 at 7:33 AM
Annotated matrices are much more valuable!
AnnData can easily be read into R/Bioc as well unlocking more stats tools.
AnnData can easily be read into R/Bioc as well unlocking more stats tools.

(2/2) ...omic data augmentation methods, interoperability with e.g., Anndata and PyTorch, cross-release benchmarks, roadmap of development practices, enriched tutorials for non-microbiome omics.
July 17, 2025 at 8:20 PM
(2/2) ...omic data augmentation methods, interoperability with e.g., Anndata and PyTorch, cross-release benchmarks, roadmap of development practices, enriched tutorials for non-microbiome omics.
We will have our next community meeting on Tuesday, 2025-07-08 at 18:00 CEST! Ilan will be speaking about the new upcoming anndata release.
(Zoom registration link and more information in thread!)
(Zoom registration link and more information in thread!)
July 7, 2025 at 7:01 AM
We will have our next community meeting on Tuesday, 2025-07-08 at 18:00 CEST! Ilan will be speaking about the new upcoming anndata release.
(Zoom registration link and more information in thread!)
(Zoom registration link and more information in thread!)
We will have our next community meeting on Tuesday, 2025-07-08 at 18:00 CEST! Ilan will be speaking about the new upcoming anndata release.
(Zoom registration link and more information in thread!)
(Zoom registration link and more information in thread!)
July 3, 2025 at 7:01 AM
We will have our next community meeting on Tuesday, 2025-07-08 at 18:00 CEST! Ilan will be speaking about the new upcoming anndata release.
(Zoom registration link and more information in thread!)
(Zoom registration link and more information in thread!)

and many are hampered by slow random disk access. We present scDataset, a PyTorch IterableDataset that operates directly on one or more AnnData files without the need for format conversion. The core innovation is a combination of block sampling and [3/5 of https://arxiv.org/abs/2506.01883v1]
June 3, 2025 at 6:54 AM
and many are hampered by slow random disk access. We present scDataset, a PyTorch IterableDataset that operates directly on one or more AnnData files without the need for format conversion. The core innovation is a combination of block sampling and [3/5 of https://arxiv.org/abs/2506.01883v1]
the AnnData format is the community standard for storing single-cell datasets, existing data loading solutions for AnnData are often inadequate: some require loading all data into memory, others convert to dense formats that increase storage demands, [2/5 of https://arxiv.org/abs/2506.01883v1]
June 3, 2025 at 6:54 AM
the AnnData format is the community standard for storing single-cell datasets, existing data loading solutions for AnnData are often inadequate: some require loading all data into memory, others convert to dense formats that increase storage demands, [2/5 of https://arxiv.org/abs/2506.01883v1]

We’ve designed it to be fast, flexible and easy to use:
- Works seamlessly with Scanpy, Squidpy and AnnData (@scverse_team compatible)
- Plug-and-play any ST dataset
- Outputs spatially informed scores
- Geostatistics-inspired metrics to evaluate gene sets
- Works seamlessly with Scanpy, Squidpy and AnnData (@scverse_team compatible)
- Plug-and-play any ST dataset
- Outputs spatially informed scores
- Geostatistics-inspired metrics to evaluate gene sets
June 2, 2025 at 11:23 AM
We’ve designed it to be fast, flexible and easy to use:
- Works seamlessly with Scanpy, Squidpy and AnnData (@scverse_team compatible)
- Plug-and-play any ST dataset
- Outputs spatially informed scores
- Geostatistics-inspired metrics to evaluate gene sets
- Works seamlessly with Scanpy, Squidpy and AnnData (@scverse_team compatible)
- Plug-and-play any ST dataset
- Outputs spatially informed scores
- Geostatistics-inspired metrics to evaluate gene sets

Updates on CRAN: anndata (0.8.0), effectsize (1.0.1), FlowerMate (1.1)
May 27, 2025 at 5:23 PM
Updates on CRAN: anndata (0.8.0), effectsize (1.0.1), FlowerMate (1.1)


Working with a large set of AnnData files on S3 is tough if you don't have the metadata indexed, so I created a tool to help.
github.com/honicky/annd...
It uses partial downloads to dramatically speed up extracting the metadata without downloading the whole file.
`pip install anndata-metadata`
github.com/honicky/annd...
It uses partial downloads to dramatically speed up extracting the metadata without downloading the whole file.
`pip install anndata-metadata`

GitHub - honicky/anndata-metadata: A Python library and CLI tool for extracting metadata from AnnData .h5ad files, both locally and on S3
A Python library and CLI tool for extracting metadata from AnnData .h5ad files, both locally and on S3 - honicky/anndata-metadata
github.com
May 18, 2025 at 9:22 PM
Working with a large set of AnnData files on S3 is tough if you don't have the metadata indexed, so I created a tool to help.
github.com/honicky/annd...
It uses partial downloads to dramatically speed up extracting the metadata without downloading the whole file.
`pip install anndata-metadata`
github.com/honicky/annd...
It uses partial downloads to dramatically speed up extracting the metadata without downloading the whole file.
`pip install anndata-metadata`
scverse turns 3!
What started as a shared vision for interoperable single-cell analysis has become a vibrant, global community.
From AnnData to full multimodal pipelines, we’re building the future of everything single-cell and spatial omics, together.
Here’s to what’s next!
What started as a shared vision for interoperable single-cell analysis has become a vibrant, global community.
From AnnData to full multimodal pipelines, we’re building the future of everything single-cell and spatial omics, together.
Here’s to what’s next!
May 17, 2025 at 10:08 PM
scverse turns 3!
What started as a shared vision for interoperable single-cell analysis has become a vibrant, global community.
From AnnData to full multimodal pipelines, we’re building the future of everything single-cell and spatial omics, together.
Here’s to what’s next!
What started as a shared vision for interoperable single-cell analysis has become a vibrant, global community.
From AnnData to full multimodal pipelines, we’re building the future of everything single-cell and spatial omics, together.
Here’s to what’s next!

Happy to share my first publication! AnnSQL leverages DuckDB to create a relational database based on each AnnData layer, enabling fast queries on massive, atlas-sized single-cell datasets. 🧬🖥️
#Bioinformatics #SingleCell #DuckDb
#Bioinformatics #SingleCell #DuckDb
🔍 Recently published in Bioinformatics Advances: "AnnSQL: A Python SQL-based package for fast large-scale single-cell genomics analysis using minimal computational resources"
Read the full paper here: https://doi.org/10.1093/bioadv/vbaf105
Authors: @kennypavan.com and @your-arpy.bsky.social
Read the full paper here: https://doi.org/10.1093/bioadv/vbaf105
Authors: @kennypavan.com and @your-arpy.bsky.social

May 6, 2025 at 2:20 PM
Happy to share my first publication! AnnSQL leverages DuckDB to create a relational database based on each AnnData layer, enabling fast queries on massive, atlas-sized single-cell datasets. 🧬🖥️
#Bioinformatics #SingleCell #DuckDb
#Bioinformatics #SingleCell #DuckDb
AnnSQL bridges single-cell #genomics and relational databases by converting AnnData objects into SQL tables using the DuckDb engine. This enables fast, SQL-based analysis of datasets with millions of cells while preserving key functionality like normalization, PCA, and clustering.
May 6, 2025 at 9:10 AM
AnnSQL bridges single-cell #genomics and relational databases by converting AnnData objects into SQL tables using the DuckDb engine. This enables fast, SQL-based analysis of datasets with millions of cells while preserving key functionality like normalization, PCA, and clustering.

It integrates with spatialdata and anndata, helping extend scverse toward spatial proteomics and imaging workflows.
We hope it helps researchers build flexible, powerful analysis pipelines for analyzing highly multiplexed fluorescence images.
🔧 Package: github.com/sagar87/spat...
We hope it helps researchers build flexible, powerful analysis pipelines for analyzing highly multiplexed fluorescence images.
🔧 Package: github.com/sagar87/spat...

GitHub - sagar87/spatialproteomics: Spatialproteomics is a light weight wrapper around xarray with the intention to facilitate the data exploration and analysis of highly multiplexed immunohistochemistry data. Docs available here: https://sagar87.github.io/spatialproteomics/ .
Spatialproteomics is a light weight wrapper around xarray with the intention to facilitate the data exploration and analysis of highly multiplexed immunohistochemistry data. Docs available here: h...
github.com
May 5, 2025 at 11:30 AM
It integrates with spatialdata and anndata, helping extend scverse toward spatial proteomics and imaging workflows.
We hope it helps researchers build flexible, powerful analysis pipelines for analyzing highly multiplexed fluorescence images.
🔧 Package: github.com/sagar87/spat...
We hope it helps researchers build flexible, powerful analysis pipelines for analyzing highly multiplexed fluorescence images.
🔧 Package: github.com/sagar87/spat...

Hey Jeff! So nice to e-connect with u. I converted the seurat obj to anndata. Will use SEACells to summarize the whole dataset with ~9k metacells, happy to share once I finish! Think this ll make your beautiful data easier to query for any tasks that would be too intense using 500k cells. Thank you!
April 29, 2025 at 11:33 PM
Hey Jeff! So nice to e-connect with u. I converted the seurat obj to anndata. Will use SEACells to summarize the whole dataset with ~9k metacells, happy to share once I finish! Think this ll make your beautiful data easier to query for any tasks that would be too intense using 500k cells. Thank you!