



Yong Zheng-Xin (Yong)
@yongzx.bsky.social
ml research at Brown University // collab at Meta AI and Cohere For AI
🔗 yongzx.github.io
🔗 yongzx.github.io
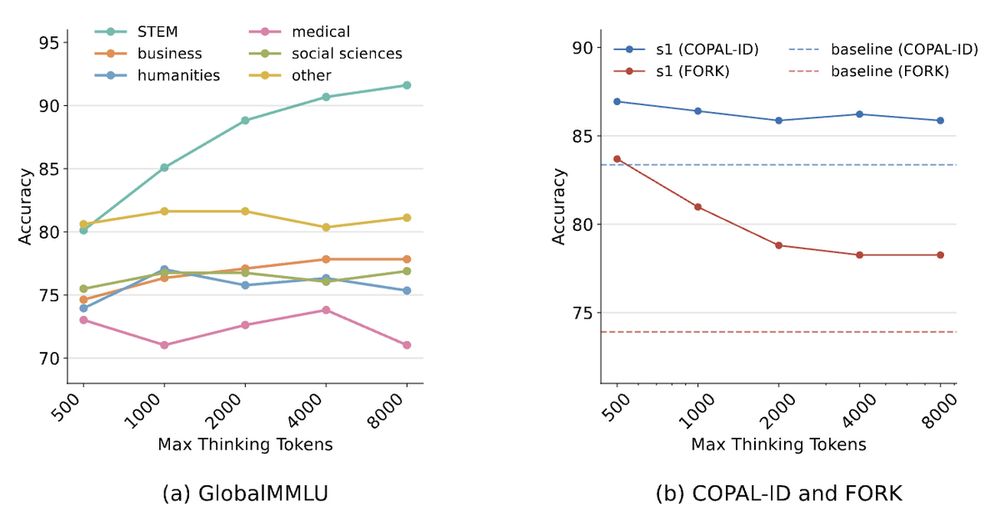
Scaling test-time compute not only yields minimal benefits, but can even lead to worse performance, especially for cultural benchmarks such as FORK.
This suggests future work is also needed for cross-domain generalization of test-time scaling.
[11/N]
This suggests future work is also needed for cross-domain generalization of test-time scaling.
[11/N]
May 9, 2025 at 7:53 PM
Scaling test-time compute not only yields minimal benefits, but can even lead to worse performance, especially for cultural benchmarks such as FORK.
This suggests future work is also needed for cross-domain generalization of test-time scaling.
[11/N]
This suggests future work is also needed for cross-domain generalization of test-time scaling.
[11/N]
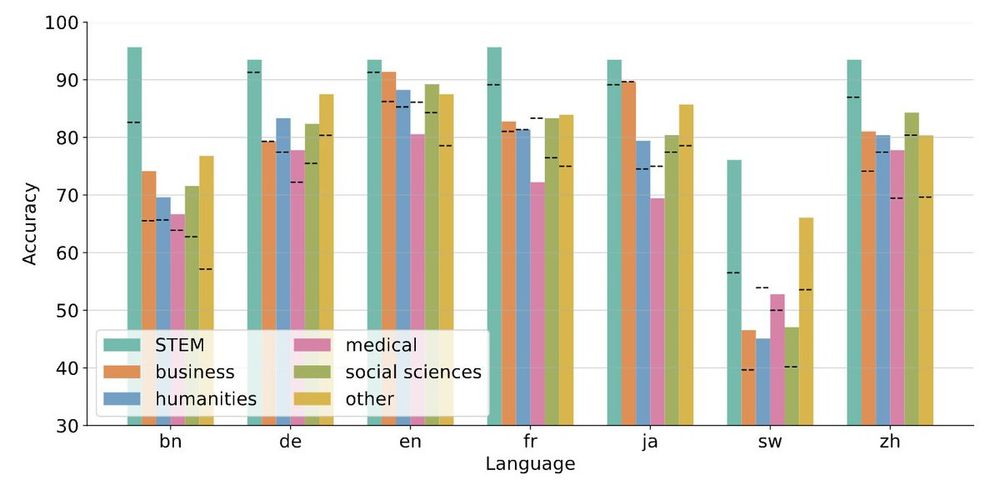
4️⃣ Cross-Domain Generalization
We evaluate multilingual cross-domain generalization on three benchmarks.
We observe poor transfer of math reasoning finetuning to other domain subjects like humanities and medical domains for the GlobalMMLU benchmark.
[10/N]
We evaluate multilingual cross-domain generalization on three benchmarks.
We observe poor transfer of math reasoning finetuning to other domain subjects like humanities and medical domains for the GlobalMMLU benchmark.
[10/N]
May 9, 2025 at 7:53 PM
4️⃣ Cross-Domain Generalization
We evaluate multilingual cross-domain generalization on three benchmarks.
We observe poor transfer of math reasoning finetuning to other domain subjects like humanities and medical domains for the GlobalMMLU benchmark.
[10/N]
We evaluate multilingual cross-domain generalization on three benchmarks.
We observe poor transfer of math reasoning finetuning to other domain subjects like humanities and medical domains for the GlobalMMLU benchmark.
[10/N]
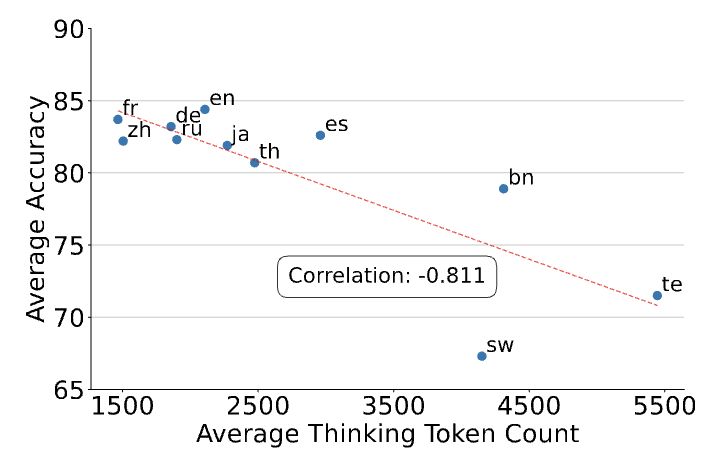
Thinking in low-resource languages like Telugu (te) and Swahili (sw) not only suffers from poor reasoning performance, but it also costs more inference compute.
This double disadvantage suggests future work is needed for efficient reasoning in low-resource languages.
[9/N]
This double disadvantage suggests future work is needed for efficient reasoning in low-resource languages.
[9/N]
May 9, 2025 at 7:53 PM
Thinking in low-resource languages like Telugu (te) and Swahili (sw) not only suffers from poor reasoning performance, but it also costs more inference compute.
This double disadvantage suggests future work is needed for efficient reasoning in low-resource languages.
[9/N]
This double disadvantage suggests future work is needed for efficient reasoning in low-resource languages.
[9/N]
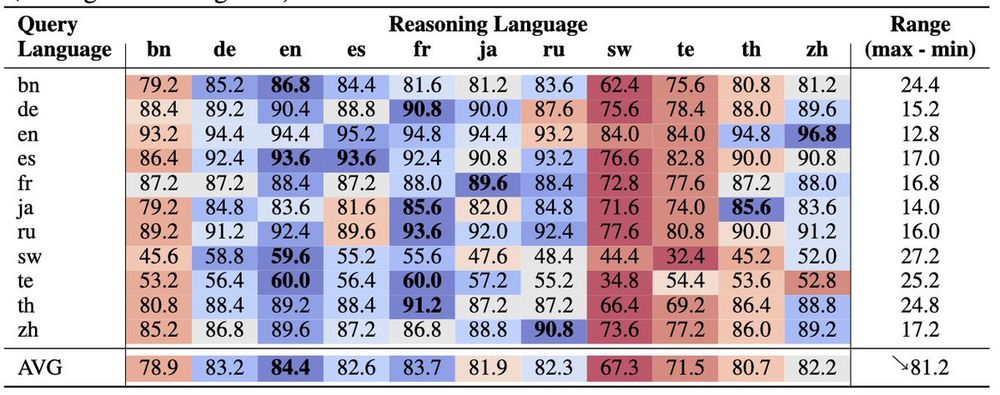
We perform an NxN exhaustive analysis and find that models can think well in high-resource languages such as English (en) and French (fr), but not in low-resource languages such as Telugu (te) and Swahili (sw).
[8/N]
[8/N]
May 9, 2025 at 7:53 PM
We perform an NxN exhaustive analysis and find that models can think well in high-resource languages such as English (en) and French (fr), but not in low-resource languages such as Telugu (te) and Swahili (sw).
[8/N]
[8/N]
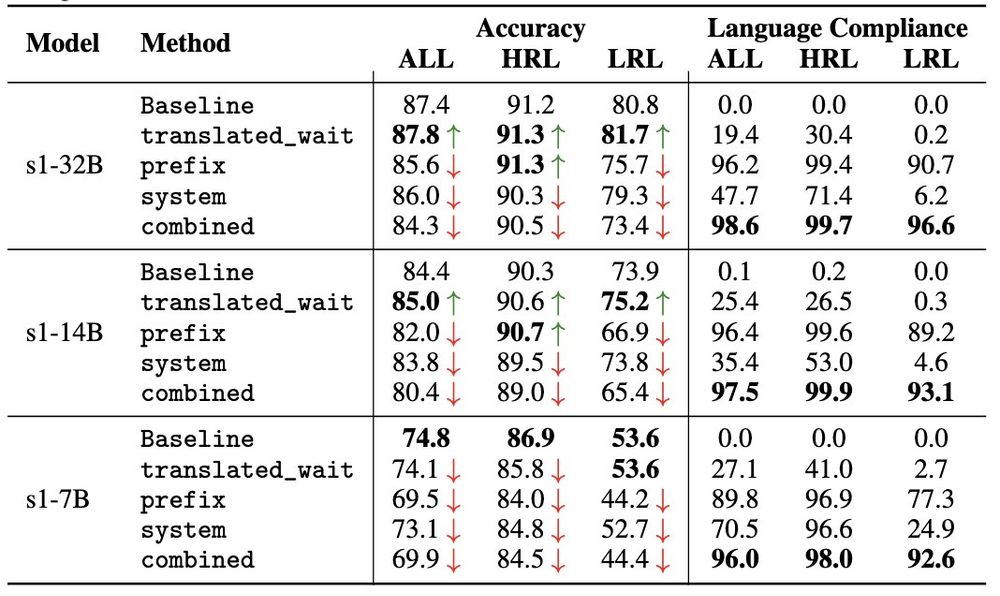
3️⃣ Language Forcing
We show that we can force English-centric reasoning models to think in non-English languages through a combination of translated wait tokens, prefix, and system prompt.
They yield nearly 100% success rate (measured by language compliance)!
[7/N]
We show that we can force English-centric reasoning models to think in non-English languages through a combination of translated wait tokens, prefix, and system prompt.
They yield nearly 100% success rate (measured by language compliance)!
[7/N]
May 9, 2025 at 7:53 PM
3️⃣ Language Forcing
We show that we can force English-centric reasoning models to think in non-English languages through a combination of translated wait tokens, prefix, and system prompt.
They yield nearly 100% success rate (measured by language compliance)!
[7/N]
We show that we can force English-centric reasoning models to think in non-English languages through a combination of translated wait tokens, prefix, and system prompt.
They yield nearly 100% success rate (measured by language compliance)!
[7/N]
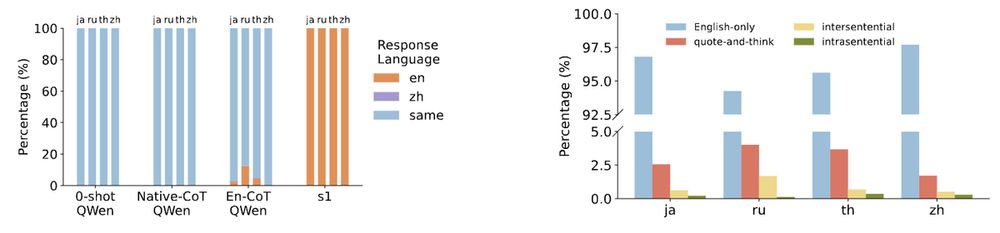
This quote-and-think pattern is the dominant language-mixing pattern for s1 models, and we observe that English-centric reasoning language models tend to think in English.
[6/N]
[6/N]
May 9, 2025 at 7:53 PM
This quote-and-think pattern is the dominant language-mixing pattern for s1 models, and we observe that English-centric reasoning language models tend to think in English.
[6/N]
[6/N]
2️⃣ Language-Mixing
We analyze how English-centric reasoning models think for non-English questions, and we observe they mix languages through the sophisticated quote-and-think pattern.
[4/N]
We analyze how English-centric reasoning models think for non-English questions, and we observe they mix languages through the sophisticated quote-and-think pattern.
[4/N]

May 9, 2025 at 7:53 PM
2️⃣ Language-Mixing
We analyze how English-centric reasoning models think for non-English questions, and we observe they mix languages through the sophisticated quote-and-think pattern.
[4/N]
We analyze how English-centric reasoning models think for non-English questions, and we observe they mix languages through the sophisticated quote-and-think pattern.
[4/N]
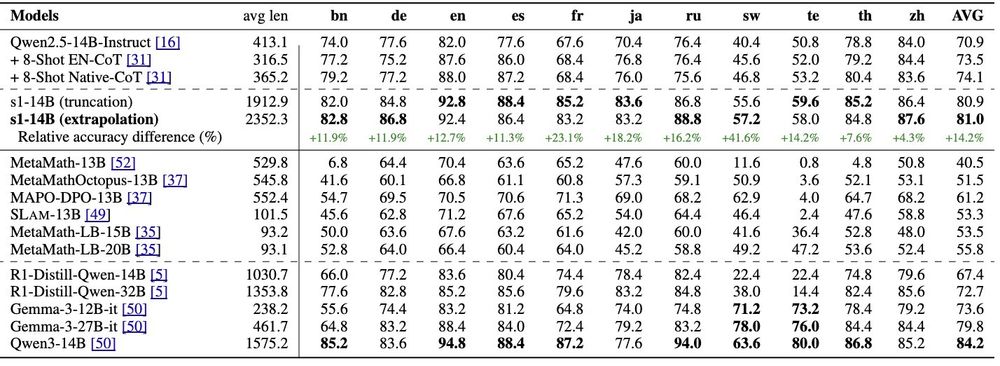
Through test-time scaling, the s1 model–––which is Qwen2.5 trained on just 1k English reasoning data–––can outperform
(1) models finetuned on multilingual math reasoning data and
(2) SOTA reasoning models (e.g., Gemma3 and r1-distilled models) twice its size.
[3/N]
(1) models finetuned on multilingual math reasoning data and
(2) SOTA reasoning models (e.g., Gemma3 and r1-distilled models) twice its size.
[3/N]
May 9, 2025 at 7:53 PM
Through test-time scaling, the s1 model–––which is Qwen2.5 trained on just 1k English reasoning data–––can outperform
(1) models finetuned on multilingual math reasoning data and
(2) SOTA reasoning models (e.g., Gemma3 and r1-distilled models) twice its size.
[3/N]
(1) models finetuned on multilingual math reasoning data and
(2) SOTA reasoning models (e.g., Gemma3 and r1-distilled models) twice its size.
[3/N]
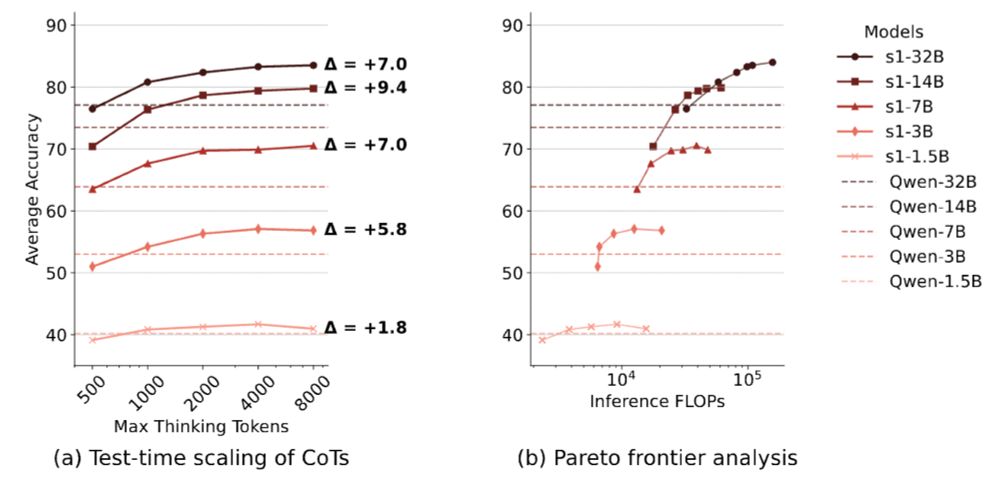
1️⃣ Crosslingual Test-Time Scaling
We observe crosslingual benefits of test-time scaling for English-centric reasoning models with ≥3B parameters.
Furthermore, with sufficient test-time compute, 14B models can even outperform 32B models on the MGSM benchmark!
[2/N]
We observe crosslingual benefits of test-time scaling for English-centric reasoning models with ≥3B parameters.
Furthermore, with sufficient test-time compute, 14B models can even outperform 32B models on the MGSM benchmark!
[2/N]
May 9, 2025 at 7:53 PM
1️⃣ Crosslingual Test-Time Scaling
We observe crosslingual benefits of test-time scaling for English-centric reasoning models with ≥3B parameters.
Furthermore, with sufficient test-time compute, 14B models can even outperform 32B models on the MGSM benchmark!
[2/N]
We observe crosslingual benefits of test-time scaling for English-centric reasoning models with ≥3B parameters.
Furthermore, with sufficient test-time compute, 14B models can even outperform 32B models on the MGSM benchmark!
[2/N]
📣 New paper!
We observe that reasoning language models finetuned only on English data are capable of zero-shot cross-lingual reasoning through a "quote-and-think" pattern.
However, this does not mean they reason the same way across all languages or in new domains.
[1/N]
We observe that reasoning language models finetuned only on English data are capable of zero-shot cross-lingual reasoning through a "quote-and-think" pattern.
However, this does not mean they reason the same way across all languages or in new domains.
[1/N]

May 9, 2025 at 7:53 PM
📣 New paper!
We observe that reasoning language models finetuned only on English data are capable of zero-shot cross-lingual reasoning through a "quote-and-think" pattern.
However, this does not mean they reason the same way across all languages or in new domains.
[1/N]
We observe that reasoning language models finetuned only on English data are capable of zero-shot cross-lingual reasoning through a "quote-and-think" pattern.
However, this does not mean they reason the same way across all languages or in new domains.
[1/N]