




Explainable AI
@xai-research.bsky.social
Explainable/Interpretable AI researchers and enthusiasts - DM to join the XAI Slack! Blue Sky and Slack maintained by Nick Kroeger
Pinned
Explainable AI
@xai-research.bsky.social
· Jan 24
Connect with XAI/IML researchers and enthusiasts from around the world. Discuss interpretability methods, get help on challenging problems, and meet experts in your field! DM to join 🥳
Reposted by Explainable AI

Had such a great time presenting our tutorial on Interpretability Techniques for Speech Models at #Interspeech2025! 🔍
For anyone looking for an introduction to the topic, we've now uploaded all materials to the website: interpretingdl.github.io/speech-inter...
For anyone looking for an introduction to the topic, we've now uploaded all materials to the website: interpretingdl.github.io/speech-inter...
August 19, 2025 at 9:23 PM
Had such a great time presenting our tutorial on Interpretability Techniques for Speech Models at #Interspeech2025! 🔍
For anyone looking for an introduction to the topic, we've now uploaded all materials to the website: interpretingdl.github.io/speech-inter...
For anyone looking for an introduction to the topic, we've now uploaded all materials to the website: interpretingdl.github.io/speech-inter...
Reposted by Explainable AI

🔥 I am super excited to be presenting a poster at #ACL2025 in Vienna next week! 🌏
This is my first big conference!
📅 Tuesday morning, 10:30–12:00, during Poster Session 2.
💬 If you're around, feel free to message me. I would be happy to connect, chat, or have a drink!
This is my first big conference!
📅 Tuesday morning, 10:30–12:00, during Poster Session 2.
💬 If you're around, feel free to message me. I would be happy to connect, chat, or have a drink!

July 25, 2025 at 3:37 PM
🔥 I am super excited to be presenting a poster at #ACL2025 in Vienna next week! 🌏
This is my first big conference!
📅 Tuesday morning, 10:30–12:00, during Poster Session 2.
💬 If you're around, feel free to message me. I would be happy to connect, chat, or have a drink!
This is my first big conference!
📅 Tuesday morning, 10:30–12:00, during Poster Session 2.
💬 If you're around, feel free to message me. I would be happy to connect, chat, or have a drink!
Reposted by Explainable AI

ACL paper alert! What structure is lost when using linearizing interp methods like Shapley? We show the nonlinear interactions between features reflect structures described by the sciences of syntax, semantics, and phonology.

June 12, 2025 at 6:56 PM
ACL paper alert! What structure is lost when using linearizing interp methods like Shapley? We show the nonlinear interactions between features reflect structures described by the sciences of syntax, semantics, and phonology.
Reposted by Explainable AI
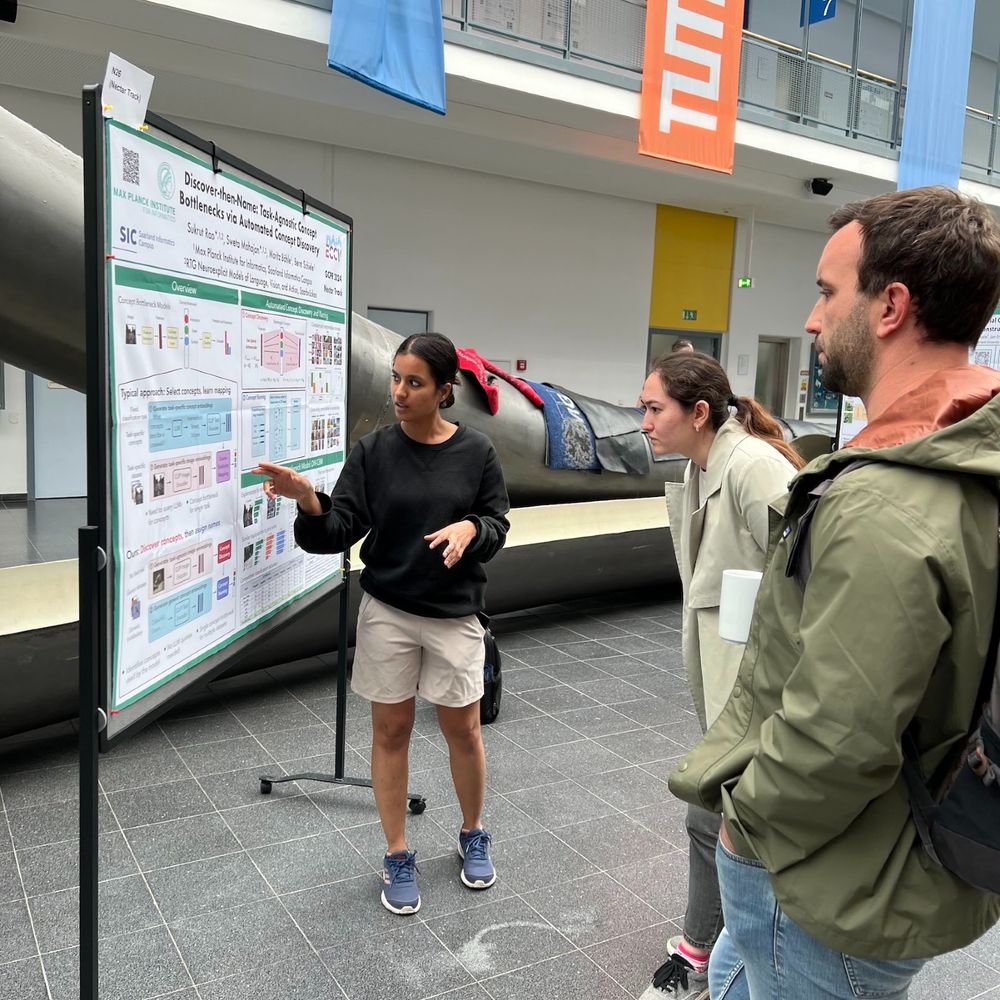
🚨Deadline Extension Alert!
Our Non-proceedings track is open till August 15th for the eXCV workshop at ICCV.
Our nectar track accepts published papers, as is.
More info at: excv-workshop.github.io
@iccv.bsky.social #ICCV2025
Our Non-proceedings track is open till August 15th for the eXCV workshop at ICCV.
Our nectar track accepts published papers, as is.
More info at: excv-workshop.github.io
@iccv.bsky.social #ICCV2025

July 18, 2025 at 9:31 AM
🚨Deadline Extension Alert!
Our Non-proceedings track is open till August 15th for the eXCV workshop at ICCV.
Our nectar track accepts published papers, as is.
More info at: excv-workshop.github.io
@iccv.bsky.social #ICCV2025
Our Non-proceedings track is open till August 15th for the eXCV workshop at ICCV.
Our nectar track accepts published papers, as is.
More info at: excv-workshop.github.io
@iccv.bsky.social #ICCV2025
Reposted by Explainable AI

10 days to go! Still time to run your method and submit!
Just 10 days to go until the results submission deadline for the MIB Shared Task at #BlackboxNLP!
If you're working on:
🧠 Circuit discovery
🔍 Feature attribution
🧪 Causal variable localization
now’s the time to polish and submit!
Join us on Discord: discord.gg/n5uwjQcxPR
If you're working on:
🧠 Circuit discovery
🔍 Feature attribution
🧪 Causal variable localization
now’s the time to polish and submit!
Join us on Discord: discord.gg/n5uwjQcxPR

July 23, 2025 at 8:21 AM
10 days to go! Still time to run your method and submit!
Reposted by Explainable AI

Excited to announce the first workshop on CogInterp: Interpreting Cognition in Deep Learning Models @ NeurIPS 2025! 📣
How can we interpret the algorithms and representations underlying complex behavior in deep learning models?
🌐 coginterp.github.io/neurips2025/
1/4
How can we interpret the algorithms and representations underlying complex behavior in deep learning models?
🌐 coginterp.github.io/neurips2025/
1/4
Home
First Workshop on Interpreting Cognition in Deep Learning Models (NeurIPS 2025)
coginterp.github.io
July 16, 2025 at 1:08 PM
Excited to announce the first workshop on CogInterp: Interpreting Cognition in Deep Learning Models @ NeurIPS 2025! 📣
How can we interpret the algorithms and representations underlying complex behavior in deep learning models?
🌐 coginterp.github.io/neurips2025/
1/4
How can we interpret the algorithms and representations underlying complex behavior in deep learning models?
🌐 coginterp.github.io/neurips2025/
1/4
Reposted by Explainable AI

If you're at #ICML2025, chat with me, @sarah-nlp.bsky.social, Atticus, and others at our poster 11am - 1:30pm at East #1205! We're establishing a 𝗠echanistic 𝗜nterpretability 𝗕enchmark.
We're planning to keep this a living benchmark; come by and share your ideas/hot takes!
We're planning to keep this a living benchmark; come by and share your ideas/hot takes!

July 17, 2025 at 5:45 PM
If you're at #ICML2025, chat with me, @sarah-nlp.bsky.social, Atticus, and others at our poster 11am - 1:30pm at East #1205! We're establishing a 𝗠echanistic 𝗜nterpretability 𝗕enchmark.
We're planning to keep this a living benchmark; come by and share your ideas/hot takes!
We're planning to keep this a living benchmark; come by and share your ideas/hot takes!
Reposted by Explainable AI

Poster is up and we are looking forward to the #ICML2025 poster session. Come join @patrickknab.bsky.social and me at Poster #W-214 presenting our work with @smarton.bsky.social, Christian Bartelt, and @margretkeuper.bsky.social @margretkeuper.bsky.social #UniMa

July 17, 2025 at 6:00 PM
Poster is up and we are looking forward to the #ICML2025 poster session. Come join @patrickknab.bsky.social and me at Poster #W-214 presenting our work with @smarton.bsky.social, Christian Bartelt, and @margretkeuper.bsky.social @margretkeuper.bsky.social #UniMa
Reposted by Explainable AI

I am at #ICML2025! 🇨🇦🏞️
Catch me:
1️⃣ Presenting this paper👇 tomorrow 11am-1:30pm at East #1205
2️⃣ At the Actionable Interpretability @actinterp.bsky.social workshop on Saturday in East Ballroom A (I’m an organizer!)
Catch me:
1️⃣ Presenting this paper👇 tomorrow 11am-1:30pm at East #1205
2️⃣ At the Actionable Interpretability @actinterp.bsky.social workshop on Saturday in East Ballroom A (I’m an organizer!)
Lots of progress in mech interp (MI) lately! But how can we measure when new mech interp methods yield real improvements over prior work?
We propose 😎 𝗠𝗜𝗕: a 𝗠echanistic 𝗜nterpretability 𝗕enchmark!
We propose 😎 𝗠𝗜𝗕: a 𝗠echanistic 𝗜nterpretability 𝗕enchmark!

July 16, 2025 at 11:09 PM
I am at #ICML2025! 🇨🇦🏞️
Catch me:
1️⃣ Presenting this paper👇 tomorrow 11am-1:30pm at East #1205
2️⃣ At the Actionable Interpretability @actinterp.bsky.social workshop on Saturday in East Ballroom A (I’m an organizer!)
Catch me:
1️⃣ Presenting this paper👇 tomorrow 11am-1:30pm at East #1205
2️⃣ At the Actionable Interpretability @actinterp.bsky.social workshop on Saturday in East Ballroom A (I’m an organizer!)
Reposted by Explainable AI

Causal Abstraction, the theory behind DAS, tests if a network realizes a given algorithm. We show (w/ @denissutter.bsky.social, T. Hofmann, @tpimentel.bsky.social ) that the theory collapses without the linear representation hypothesis—a problem we call the non-linear representation dilemma.

July 17, 2025 at 10:57 AM
Causal Abstraction, the theory behind DAS, tests if a network realizes a given algorithm. We show (w/ @denissutter.bsky.social, T. Hofmann, @tpimentel.bsky.social ) that the theory collapses without the linear representation hypothesis—a problem we call the non-linear representation dilemma.
Reposted by Explainable AI
Join us on Thursday 11-13 in poster hall West #214 to discuss image segments as concepts. #ICML2025 @patrickknab.bsky.social @smarton.bsky.social Christian bartelt @margretkeuper.bsky.social @keuper-labs.bsky.social
Attending #ICML2025? Watch out for our paper "DCBM: Data-Efficient Visual Concept Bottleneck Models" presented by @katharinaprasse.bsky.social -> github.com/KathPra/DCBM

July 15, 2025 at 10:01 PM
Join us on Thursday 11-13 in poster hall West #214 to discuss image segments as concepts. #ICML2025 @patrickknab.bsky.social @smarton.bsky.social Christian bartelt @margretkeuper.bsky.social @keuper-labs.bsky.social
Reposted by Explainable AI

🌌🛰️🔭Want to explore universal visual features? Check out our interactive demo of concepts learned from our #ICML2025 paper "Universal Sparse Autoencoders: Interpretable Cross-Model Concept Alignment".
Come see our poster at 4pm on Tuesday in East Exhibition hall A-B, E-1208!
Come see our poster at 4pm on Tuesday in East Exhibition hall A-B, E-1208!
July 15, 2025 at 2:36 AM
🌌🛰️🔭Want to explore universal visual features? Check out our interactive demo of concepts learned from our #ICML2025 paper "Universal Sparse Autoencoders: Interpretable Cross-Model Concept Alignment".
Come see our poster at 4pm on Tuesday in East Exhibition hall A-B, E-1208!
Come see our poster at 4pm on Tuesday in East Exhibition hall A-B, E-1208!
Reposted by Explainable AI

Papers being presented from our group at #ICML2025!
Congratulations to all the authors! To know more, visit us in the poster sessions!
A 🧵with more details:
@icmlconf.bsky.social @mpi-inf.mpg.de
Congratulations to all the authors! To know more, visit us in the poster sessions!
A 🧵with more details:
@icmlconf.bsky.social @mpi-inf.mpg.de

July 13, 2025 at 8:00 AM
Papers being presented from our group at #ICML2025!
Congratulations to all the authors! To know more, visit us in the poster sessions!
A 🧵with more details:
@icmlconf.bsky.social @mpi-inf.mpg.de
Congratulations to all the authors! To know more, visit us in the poster sessions!
A 🧵with more details:
@icmlconf.bsky.social @mpi-inf.mpg.de
Reposted by Explainable AI

Our #ICML position paper: #XAI is similar to applied statistics: it uses summary statistics in an attempt to answer real world questions. But authors need to state how concretely (!) their XAI statistics contributes to answer which concrete (!) question!
arxiv.org/abs/2402.02870
arxiv.org/abs/2402.02870

During the last couple of years, we have read a lot of papers on explainability and often felt that something was fundamentally missing🤔
This led us to write a position paper (accepted at #ICML2025) that attempts to identify the problem and to propose a solution.
arxiv.org/abs/2402.02870
👇🧵
This led us to write a position paper (accepted at #ICML2025) that attempts to identify the problem and to propose a solution.
arxiv.org/abs/2402.02870
👇🧵

July 11, 2025 at 7:35 AM
Our #ICML position paper: #XAI is similar to applied statistics: it uses summary statistics in an attempt to answer real world questions. But authors need to state how concretely (!) their XAI statistics contributes to answer which concrete (!) question!
arxiv.org/abs/2402.02870
arxiv.org/abs/2402.02870
Reposted by Explainable AI
🚨 New preprint! 🚨
Everyone loves causal interp. It’s coherently defined! It makes testable predictions about mechanistic interventions! But what if we had a different objective: predicting model behavior not under mechanistic interventions, but on unseen input data?
Everyone loves causal interp. It’s coherently defined! It makes testable predictions about mechanistic interventions! But what if we had a different objective: predicting model behavior not under mechanistic interventions, but on unseen input data?

July 10, 2025 at 2:31 PM
🚨 New preprint! 🚨
Everyone loves causal interp. It’s coherently defined! It makes testable predictions about mechanistic interventions! But what if we had a different objective: predicting model behavior not under mechanistic interventions, but on unseen input data?
Everyone loves causal interp. It’s coherently defined! It makes testable predictions about mechanistic interventions! But what if we had a different objective: predicting model behavior not under mechanistic interventions, but on unseen input data?
Reposted by Explainable AI
Introducing the speakers for the eXCV workshop at ICCV, Hawaii. Get ready for many stimulating and insightful talks and discussions.
Our Non-proceedings track is still open!
Paper submission deadline: July 18, 2025
More info at: excv-workshop.github.io
@iccv.bsky.social #ICCV2025
Our Non-proceedings track is still open!
Paper submission deadline: July 18, 2025
More info at: excv-workshop.github.io
@iccv.bsky.social #ICCV2025

July 10, 2025 at 12:49 PM
Introducing the speakers for the eXCV workshop at ICCV, Hawaii. Get ready for many stimulating and insightful talks and discussions.
Our Non-proceedings track is still open!
Paper submission deadline: July 18, 2025
More info at: excv-workshop.github.io
@iccv.bsky.social #ICCV2025
Our Non-proceedings track is still open!
Paper submission deadline: July 18, 2025
More info at: excv-workshop.github.io
@iccv.bsky.social #ICCV2025
Reposted by Explainable AI

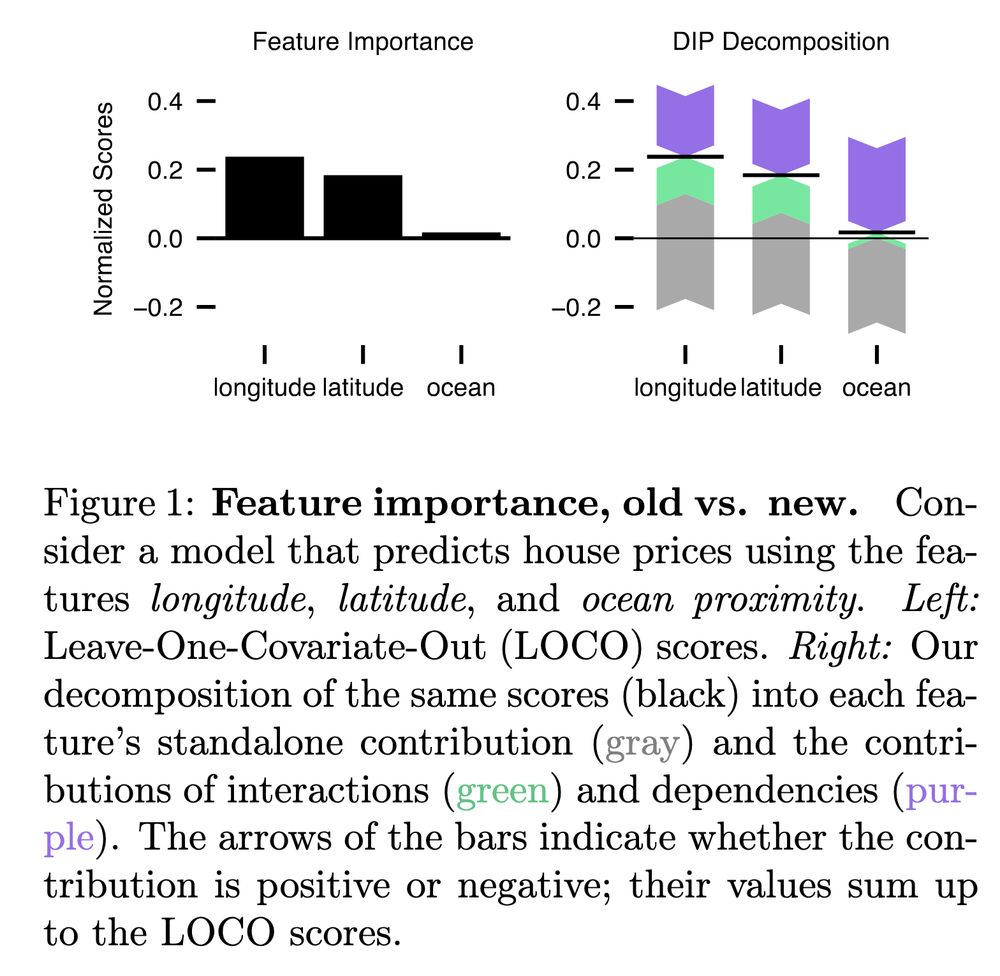
In many XAI applications, it is crucial to determine whether features contribute individually or only when combined. However, existing methods fail to reveal cooperations since they entangle individual contributions with those made via interactions and dependencies. We show how to disentangle them!
July 7, 2025 at 3:37 PM
In many XAI applications, it is crucial to determine whether features contribute individually or only when combined. However, existing methods fail to reveal cooperations since they entangle individual contributions with those made via interactions and dependencies. We show how to disentangle them!
Reposted by Explainable AI
Tried steering with SAEs and found that not all features behave as expected?
Check out our new preprint - "SAEs Are Good for Steering - If You Select the Right Features" 🧵
Check out our new preprint - "SAEs Are Good for Steering - If You Select the Right Features" 🧵

May 27, 2025 at 4:06 PM
Tried steering with SAEs and found that not all features behave as expected?
Check out our new preprint - "SAEs Are Good for Steering - If You Select the Right Features" 🧵
Check out our new preprint - "SAEs Are Good for Steering - If You Select the Right Features" 🧵
Reposted by Explainable AI

How do language models track mental states of each character in a story, often referred to as Theory of Mind?
We reverse-engineered how LLaMA-3-70B-Instruct handles a belief-tracking task and found something surprising: it uses mechanisms strikingly similar to pointer variables in C programming!
We reverse-engineered how LLaMA-3-70B-Instruct handles a belief-tracking task and found something surprising: it uses mechanisms strikingly similar to pointer variables in C programming!

June 24, 2025 at 5:13 PM
How do language models track mental states of each character in a story, often referred to as Theory of Mind?
We reverse-engineered how LLaMA-3-70B-Instruct handles a belief-tracking task and found something surprising: it uses mechanisms strikingly similar to pointer variables in C programming!
We reverse-engineered how LLaMA-3-70B-Instruct handles a belief-tracking task and found something surprising: it uses mechanisms strikingly similar to pointer variables in C programming!
Reposted by Explainable AI
VLMs perform better on questions about text than when answering the same questions about images - but why? and how can we fix it?
In a new project led by Yaniv (@YNikankin on the other app), we investigate this gap from an mechanistic perspective, and use our findings to close a third of it! 🧵
In a new project led by Yaniv (@YNikankin on the other app), we investigate this gap from an mechanistic perspective, and use our findings to close a third of it! 🧵

June 26, 2025 at 10:41 AM
VLMs perform better on questions about text than when answering the same questions about images - but why? and how can we fix it?
In a new project led by Yaniv (@YNikankin on the other app), we investigate this gap from an mechanistic perspective, and use our findings to close a third of it! 🧵
In a new project led by Yaniv (@YNikankin on the other app), we investigate this gap from an mechanistic perspective, and use our findings to close a third of it! 🧵
Reposted by Explainable AI

Have you heard about this year's shared task? 📢
Mechanistic Interpretability (MI) is quickly advancing, but comparing methods remains a challenge. This year at #BlackboxNLP, we're introducing a shared task to rigorously evaluate MI methods in language models 🧵
Mechanistic Interpretability (MI) is quickly advancing, but comparing methods remains a challenge. This year at #BlackboxNLP, we're introducing a shared task to rigorously evaluate MI methods in language models 🧵

June 23, 2025 at 2:46 PM
Have you heard about this year's shared task? 📢
Mechanistic Interpretability (MI) is quickly advancing, but comparing methods remains a challenge. This year at #BlackboxNLP, we're introducing a shared task to rigorously evaluate MI methods in language models 🧵
Mechanistic Interpretability (MI) is quickly advancing, but comparing methods remains a challenge. This year at #BlackboxNLP, we're introducing a shared task to rigorously evaluate MI methods in language models 🧵
Reposted by Explainable AI

Our position paper on algorithmic explanations is out—excited to share it! 🙌
Proud of this collaborative effort toward a scientifically grounded understanding of generative AI.
@tuberlin.bsky.social @bifold.berlin @msftresearch.bsky.social @UCSD & @UCLA
Proud of this collaborative effort toward a scientifically grounded understanding of generative AI.
@tuberlin.bsky.social @bifold.berlin @msftresearch.bsky.social @UCSD & @UCLA

June 20, 2025 at 5:12 PM
Our position paper on algorithmic explanations is out—excited to share it! 🙌
Proud of this collaborative effort toward a scientifically grounded understanding of generative AI.
@tuberlin.bsky.social @bifold.berlin @msftresearch.bsky.social @UCSD & @UCLA
Proud of this collaborative effort toward a scientifically grounded understanding of generative AI.
@tuberlin.bsky.social @bifold.berlin @msftresearch.bsky.social @UCSD & @UCLA
Reposted by Explainable AI

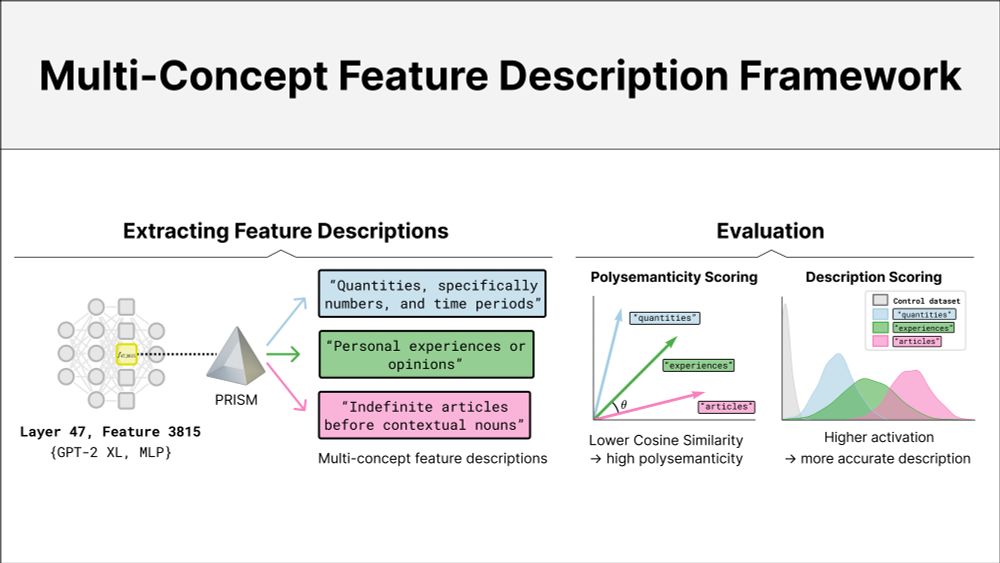
🔍 When do neurons encode multiple concepts?
We introduce PRISM, a framework for extracting multi-concept feature descriptions to better understand polysemanticity.
📄 Capturing Polysemanticity with PRISM: A Multi-Concept Feature Description Framework
arxiv.org/abs/2506.15538
🧵 (1/7)
We introduce PRISM, a framework for extracting multi-concept feature descriptions to better understand polysemanticity.
📄 Capturing Polysemanticity with PRISM: A Multi-Concept Feature Description Framework
arxiv.org/abs/2506.15538
🧵 (1/7)
June 19, 2025 at 3:18 PM
🔍 When do neurons encode multiple concepts?
We introduce PRISM, a framework for extracting multi-concept feature descriptions to better understand polysemanticity.
📄 Capturing Polysemanticity with PRISM: A Multi-Concept Feature Description Framework
arxiv.org/abs/2506.15538
🧵 (1/7)
We introduce PRISM, a framework for extracting multi-concept feature descriptions to better understand polysemanticity.
📄 Capturing Polysemanticity with PRISM: A Multi-Concept Feature Description Framework
arxiv.org/abs/2506.15538
🧵 (1/7)
Reposted by Explainable AI
🚨 New preprint! Excited to share our work on extracting and evaluating the potentially many feature descriptions of language models
👉 arxiv.org/abs/2506.15538
👉 arxiv.org/abs/2506.15538
🔍 When do neurons encode multiple concepts?
We introduce PRISM, a framework for extracting multi-concept feature descriptions to better understand polysemanticity.
📄 Capturing Polysemanticity with PRISM: A Multi-Concept Feature Description Framework
arxiv.org/abs/2506.15538
🧵 (1/7)
We introduce PRISM, a framework for extracting multi-concept feature descriptions to better understand polysemanticity.
📄 Capturing Polysemanticity with PRISM: A Multi-Concept Feature Description Framework
arxiv.org/abs/2506.15538
🧵 (1/7)
June 19, 2025 at 4:44 PM
🚨 New preprint! Excited to share our work on extracting and evaluating the potentially many feature descriptions of language models
👉 arxiv.org/abs/2506.15538
👉 arxiv.org/abs/2506.15538
Reposted by Explainable AI

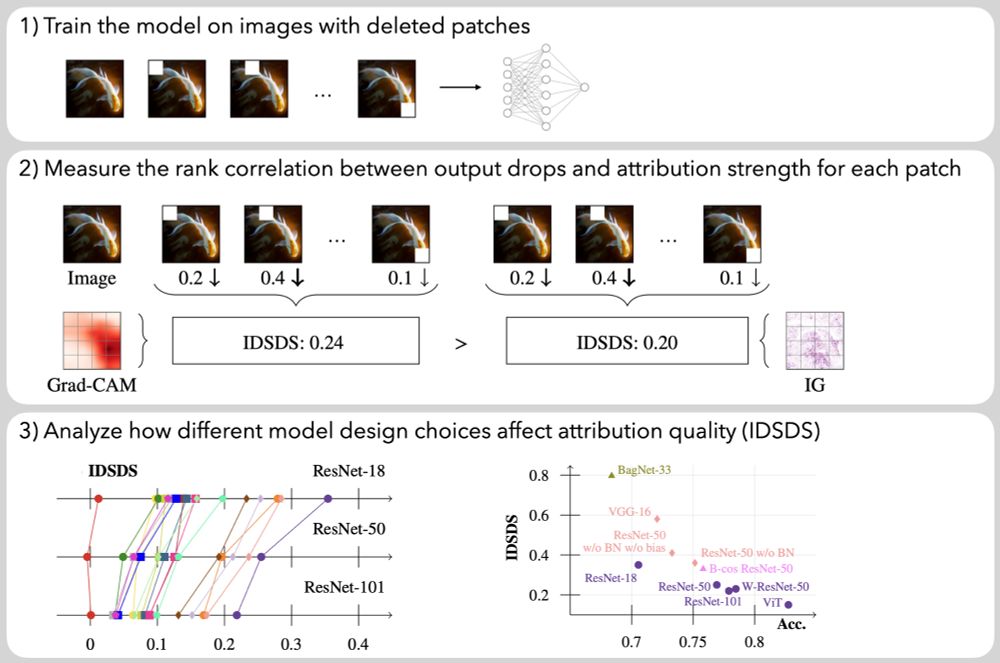
Want to learn about how model design choices affect the attribution quality of vision models? Visit our #NeurIPS2024 poster on Friday afternoon (East Exhibition Hall A-C #2910)!
Paper: arxiv.org/abs/2407.11910
Code: github.com/visinf/idsds
Paper: arxiv.org/abs/2407.11910
Code: github.com/visinf/idsds
December 13, 2024 at 10:10 AM
Want to learn about how model design choices affect the attribution quality of vision models? Visit our #NeurIPS2024 poster on Friday afternoon (East Exhibition Hall A-C #2910)!
Paper: arxiv.org/abs/2407.11910
Code: github.com/visinf/idsds
Paper: arxiv.org/abs/2407.11910
Code: github.com/visinf/idsds