



Philippe Weinzaepfel
@weinzaepfelp.bsky.social
Principal Research Scientist in Computer Vision at Naver Labs Europe
https://philippeweinzaepfel.github.io/
https://philippeweinzaepfel.github.io/
Reposted by Philippe Weinzaepfel

🧍♀️ Introducing Anny: an open, interpretable, and differentiable human body model for all ages.
Grounded in anthropometric data (MakeHuman) & WHO stats, Anny offers:
🧠 Interpretable shape control
👶👩🦳 Unified from infants to elders
🧩 Versatile for fitting, synthesis & HMR
🌍 Open under Apache 2.0
Grounded in anthropometric data (MakeHuman) & WHO stats, Anny offers:
🧠 Interpretable shape control
👶👩🦳 Unified from infants to elders
🧩 Versatile for fitting, synthesis & HMR
🌍 Open under Apache 2.0
November 6, 2025 at 4:37 PM
🧍♀️ Introducing Anny: an open, interpretable, and differentiable human body model for all ages.
Grounded in anthropometric data (MakeHuman) & WHO stats, Anny offers:
🧠 Interpretable shape control
👶👩🦳 Unified from infants to elders
🧩 Versatile for fitting, synthesis & HMR
🌍 Open under Apache 2.0
Grounded in anthropometric data (MakeHuman) & WHO stats, Anny offers:
🧠 Interpretable shape control
👶👩🦳 Unified from infants to elders
🧩 Versatile for fitting, synthesis & HMR
🌍 Open under Apache 2.0
Reposted by Philippe Weinzaepfel

Meet Anny. One model. Every body. A new human model that fits everyone!
✅ Works for all ages
✅ Free & open (Apache 2.0)
✅ Privacy-friendly (no scans)
✅ Simple parameters
Blog: tinyurl.com/5fsekm9z
Code: github.com/naver/anny
An alternative 4 #VR, #AR #Robotics.
#3DHumanModeling #OpenSource
✅ Works for all ages
✅ Free & open (Apache 2.0)
✅ Privacy-friendly (no scans)
✅ Simple parameters
Blog: tinyurl.com/5fsekm9z
Code: github.com/naver/anny
An alternative 4 #VR, #AR #Robotics.
#3DHumanModeling #OpenSource
November 6, 2025 at 9:40 AM
Meet Anny. One model. Every body. A new human model that fits everyone!
✅ Works for all ages
✅ Free & open (Apache 2.0)
✅ Privacy-friendly (no scans)
✅ Simple parameters
Blog: tinyurl.com/5fsekm9z
Code: github.com/naver/anny
An alternative 4 #VR, #AR #Robotics.
#3DHumanModeling #OpenSource
✅ Works for all ages
✅ Free & open (Apache 2.0)
✅ Privacy-friendly (no scans)
✅ Simple parameters
Blog: tinyurl.com/5fsekm9z
Code: github.com/naver/anny
An alternative 4 #VR, #AR #Robotics.
#3DHumanModeling #OpenSource
Reposted by Philippe Weinzaepfel

Meet Anny, our Free (Apache 2.0) and Interpretable Human Body Model for all ages.
Anny is built upon #MakeHuman and enables achieving SOTA performance in Human Mesh Recovery.
ArXiv: arxiv.org/abs/2511.03589
Demo: anny-demo.europe.naverlabs.com
Code: github.com/naver/anny
Anny is built upon #MakeHuman and enables achieving SOTA performance in Human Mesh Recovery.
ArXiv: arxiv.org/abs/2511.03589
Demo: anny-demo.europe.naverlabs.com
Code: github.com/naver/anny

November 6, 2025 at 10:59 AM
Meet Anny, our Free (Apache 2.0) and Interpretable Human Body Model for all ages.
Anny is built upon #MakeHuman and enables achieving SOTA performance in Human Mesh Recovery.
ArXiv: arxiv.org/abs/2511.03589
Demo: anny-demo.europe.naverlabs.com
Code: github.com/naver/anny
Anny is built upon #MakeHuman and enables achieving SOTA performance in Human Mesh Recovery.
ArXiv: arxiv.org/abs/2511.03589
Demo: anny-demo.europe.naverlabs.com
Code: github.com/naver/anny
Reposted by Philippe Weinzaepfel

"Sliding is all you need" (aka "What really matters in image goal navigation") has been accepted to 3DV 2026 (@3dvconf.bsky.social) as an Oral presentation!
By Gianluca Monaci, @weinzaepfelp.bsky.social and myself.
@naverlabseurope.bsky.social
By Gianluca Monaci, @weinzaepfelp.bsky.social and myself.
@naverlabseurope.bsky.social
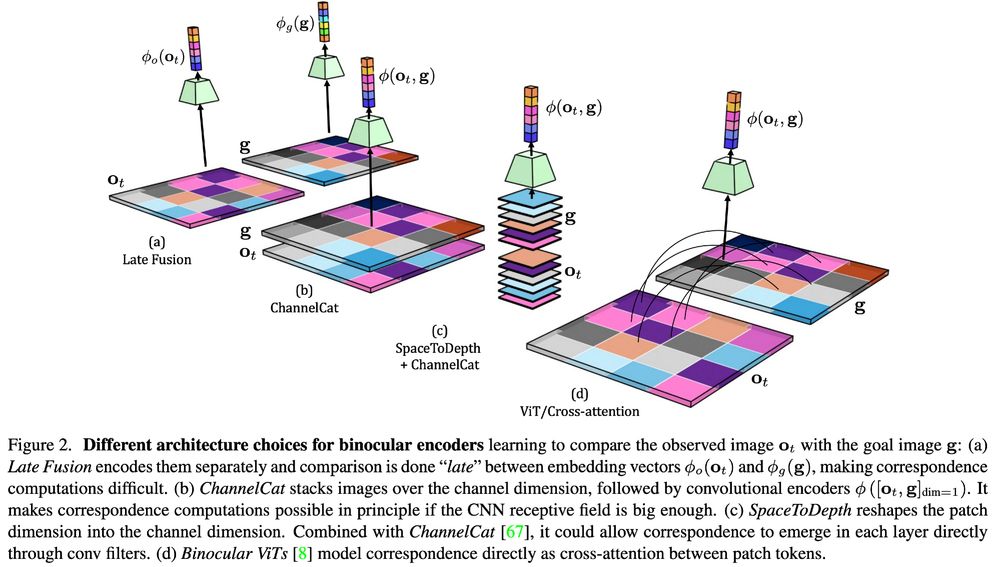
In a new paper led by Gianluca Monaci, with @weinzaepfelp.bsky.social and myself, we explore the relationship between rel pose estimation and image goal navigation and study different architectures: late fusion, channel cat (w/ or w/o space2depth) and cross-attention.
arxiv.org/abs/2507.01667
🧵1/5
arxiv.org/abs/2507.01667
🧵1/5
November 6, 2025 at 6:20 AM
"Sliding is all you need" (aka "What really matters in image goal navigation") has been accepted to 3DV 2026 (@3dvconf.bsky.social) as an Oral presentation!
By Gianluca Monaci, @weinzaepfelp.bsky.social and myself.
@naverlabseurope.bsky.social
By Gianluca Monaci, @weinzaepfelp.bsky.social and myself.
@naverlabseurope.bsky.social

Reposted by Philippe Weinzaepfel
We have a new sequence model for robotics, which will be presented at #NeurIPS2025:
Kinaema: A recurrent sequence model for memory and pose in motion
arxiv.org/abs/2510.20261
By @mbsariyildiz.bsky.social, @weinzaepfelp.bsky.social, G. Bono, G. Monaci and myself
@naverlabseurope.bsky.social
1/9
Kinaema: A recurrent sequence model for memory and pose in motion
arxiv.org/abs/2510.20261
By @mbsariyildiz.bsky.social, @weinzaepfelp.bsky.social, G. Bono, G. Monaci and myself
@naverlabseurope.bsky.social
1/9

October 24, 2025 at 7:18 AM
We have a new sequence model for robotics, which will be presented at #NeurIPS2025:
Kinaema: A recurrent sequence model for memory and pose in motion
arxiv.org/abs/2510.20261
By @mbsariyildiz.bsky.social, @weinzaepfelp.bsky.social, G. Bono, G. Monaci and myself
@naverlabseurope.bsky.social
1/9
Kinaema: A recurrent sequence model for memory and pose in motion
arxiv.org/abs/2510.20261
By @mbsariyildiz.bsky.social, @weinzaepfelp.bsky.social, G. Bono, G. Monaci and myself
@naverlabseurope.bsky.social
1/9
Reposted by Philippe Weinzaepfel
A reminder which might be relevant now: we are looking to hire a senior research scientist in Robotics at @naverlabseurope.bsky.social in Grenoble, France.

October 23, 2025 at 6:19 PM
A reminder which might be relevant now: we are looking to hire a senior research scientist in Robotics at @naverlabseurope.bsky.social in Grenoble, France.
Reposted by Philippe Weinzaepfel
We have a new internship position open in our team at Naver Labs Europe, on AI for robotics: manipulation using 3D foundation models.
@naverlabseurope.bsky.social
This is a collaboration with Sorbonne University/ISIR (Nicolas Thome)
You can apply online:
careers.werecruit.io/en/naver-lab...
@naverlabseurope.bsky.social
This is a collaboration with Sorbonne University/ISIR (Nicolas Thome)
You can apply online:
careers.werecruit.io/en/naver-lab...

October 20, 2025 at 10:27 AM
We have a new internship position open in our team at Naver Labs Europe, on AI for robotics: manipulation using 3D foundation models.
@naverlabseurope.bsky.social
This is a collaboration with Sorbonne University/ISIR (Nicolas Thome)
You can apply online:
careers.werecruit.io/en/naver-lab...
@naverlabseurope.bsky.social
This is a collaboration with Sorbonne University/ISIR (Nicolas Thome)
You can apply online:
careers.werecruit.io/en/naver-lab...
Reposted by Philippe Weinzaepfel
Aloha #iccv25 – here we come! Excited to be presenting new *St3R models PANSt3R, HAMSt3R & HOSt3R. We're also introducing ‘Geo4D' and ‘LUDVIG’ 🫢 giving invited talks and mentoring! Full @iccv.bsky.social
programme below (or tinyurl.com/asbn5b5d) 🧵1/9
programme below (or tinyurl.com/asbn5b5d) 🧵1/9

ICCV 2025
5 papers, invited speaker, WiCV sponsor and Challenge sponsor
tinyurl.com
October 18, 2025 at 6:56 AM
Aloha #iccv25 – here we come! Excited to be presenting new *St3R models PANSt3R, HAMSt3R & HOSt3R. We're also introducing ‘Geo4D' and ‘LUDVIG’ 🫢 giving invited talks and mentoring! Full @iccv.bsky.social
programme below (or tinyurl.com/asbn5b5d) 🧵1/9
programme below (or tinyurl.com/asbn5b5d) 🧵1/9
Reposted by Philippe Weinzaepfel

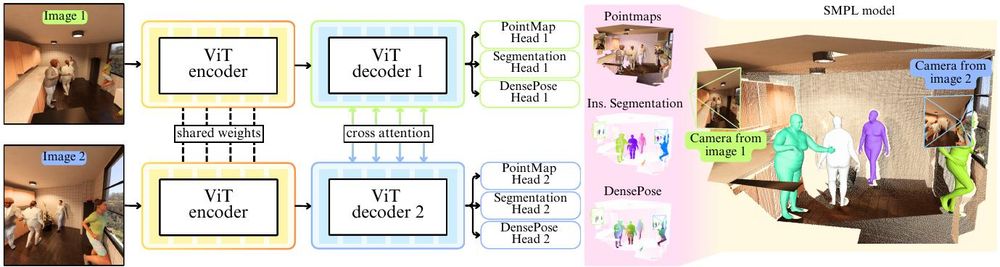
𝗛𝗔𝗠𝗦𝘁𝟯𝗥: 𝗛𝘂𝗺𝗮𝗻-𝗔𝘄𝗮𝗿𝗲 𝗠𝘂𝗹𝘁𝗶-𝘃𝗶𝗲𝘄 𝗦𝘁𝗲𝗿𝗲𝗼 𝟯𝗗 𝗥𝗲𝗰𝗼𝗻𝘀𝘁𝗿𝘂𝗰𝘁𝗶𝗼𝗻
Sara Rojas, Matthieu Armando, Bernard Ghamen ... Gregory Rogez
arxiv.org/abs/2508.16433
Trending on www.scholar-inbox.com
Sara Rojas, Matthieu Armando, Bernard Ghamen ... Gregory Rogez
arxiv.org/abs/2508.16433
Trending on www.scholar-inbox.com



August 26, 2025 at 6:00 AM
𝗛𝗔𝗠𝗦𝘁𝟯𝗥: 𝗛𝘂𝗺𝗮𝗻-𝗔𝘄𝗮𝗿𝗲 𝗠𝘂𝗹𝘁𝗶-𝘃𝗶𝗲𝘄 𝗦𝘁𝗲𝗿𝗲𝗼 𝟯𝗗 𝗥𝗲𝗰𝗼𝗻𝘀𝘁𝗿𝘂𝗰𝘁𝗶𝗼𝗻
Sara Rojas, Matthieu Armando, Bernard Ghamen ... Gregory Rogez
arxiv.org/abs/2508.16433
Trending on www.scholar-inbox.com
Sara Rojas, Matthieu Armando, Bernard Ghamen ... Gregory Rogez
arxiv.org/abs/2508.16433
Trending on www.scholar-inbox.com
Reposted by Philippe Weinzaepfel
𝗛𝗢𝗦𝘁𝟯𝗥: 𝗞𝗲𝘆𝗽𝗼𝗶𝗻𝘁-𝗳𝗿𝗲𝗲 𝗛𝗮𝗻𝗱-𝗢𝗯𝗷𝗲𝗰𝘁 𝟯𝗗 𝗥𝗲𝗰𝗼𝗻𝘀𝘁𝗿𝘂𝗰𝘁𝗶𝗼𝗻 𝗳𝗿𝗼𝗺 𝗥𝗚𝗕 𝗶𝗺𝗮𝗴𝗲𝘀
Anilkumar Swamy, Vincent Leroy, Philippe Weinzaepfel ... Grégory Rogez
arxiv.org/abs/2508.16465
Trending on www.scholar-inbox.com
Anilkumar Swamy, Vincent Leroy, Philippe Weinzaepfel ... Grégory Rogez
arxiv.org/abs/2508.16465
Trending on www.scholar-inbox.com




August 27, 2025 at 6:00 AM
𝗛𝗢𝗦𝘁𝟯𝗥: 𝗞𝗲𝘆𝗽𝗼𝗶𝗻𝘁-𝗳𝗿𝗲𝗲 𝗛𝗮𝗻𝗱-𝗢𝗯𝗷𝗲𝗰𝘁 𝟯𝗗 𝗥𝗲𝗰𝗼𝗻𝘀𝘁𝗿𝘂𝗰𝘁𝗶𝗼𝗻 𝗳𝗿𝗼𝗺 𝗥𝗚𝗕 𝗶𝗺𝗮𝗴𝗲𝘀
Anilkumar Swamy, Vincent Leroy, Philippe Weinzaepfel ... Grégory Rogez
arxiv.org/abs/2508.16465
Trending on www.scholar-inbox.com
Anilkumar Swamy, Vincent Leroy, Philippe Weinzaepfel ... Grégory Rogez
arxiv.org/abs/2508.16465
Trending on www.scholar-inbox.com
Reposted by Philippe Weinzaepfel
HOSt3R (Keypoint-free Hand-Object 3D Reconstruction from RGB images) builds upon DUSt3R for unconstrained hand-object 3D reconstruction - example 3D shape output below.
Paper: arxiv.org/abs/2508.16465
More info on @naverlabseurope.bsky.social
@iccv.bsky.social ➡️ tinyurl.com/2p9kcb86
2/2🧵
Paper: arxiv.org/abs/2508.16465
More info on @naverlabseurope.bsky.social
@iccv.bsky.social ➡️ tinyurl.com/2p9kcb86
2/2🧵
August 25, 2025 at 2:15 PM
HOSt3R (Keypoint-free Hand-Object 3D Reconstruction from RGB images) builds upon DUSt3R for unconstrained hand-object 3D reconstruction - example 3D shape output below.
Paper: arxiv.org/abs/2508.16465
More info on @naverlabseurope.bsky.social
@iccv.bsky.social ➡️ tinyurl.com/2p9kcb86
2/2🧵
Paper: arxiv.org/abs/2508.16465
More info on @naverlabseurope.bsky.social
@iccv.bsky.social ➡️ tinyurl.com/2p9kcb86
2/2🧵
Reposted by Philippe Weinzaepfel
Announcing 2 new members of the *St3R family for human-centric 3D vision tasks!
Meet HAMst3R & HOSt3R
@iccv.bsky.social
- HAMSt3R (Human-Aware Multi-view Stereo 3D Reconstruction) extends MASt3R to handle scenes involving people.
Paper: arxiv.org/abs/2508.16433
1/2 🧵
Meet HAMst3R & HOSt3R
@iccv.bsky.social
- HAMSt3R (Human-Aware Multi-view Stereo 3D Reconstruction) extends MASt3R to handle scenes involving people.
Paper: arxiv.org/abs/2508.16433
1/2 🧵
August 25, 2025 at 2:15 PM
Announcing 2 new members of the *St3R family for human-centric 3D vision tasks!
Meet HAMst3R & HOSt3R
@iccv.bsky.social
- HAMSt3R (Human-Aware Multi-view Stereo 3D Reconstruction) extends MASt3R to handle scenes involving people.
Paper: arxiv.org/abs/2508.16433
1/2 🧵
Meet HAMst3R & HOSt3R
@iccv.bsky.social
- HAMSt3R (Human-Aware Multi-view Stereo 3D Reconstruction) extends MASt3R to handle scenes involving people.
Paper: arxiv.org/abs/2508.16433
1/2 🧵
Reposted by Philippe Weinzaepfel
Major announcement ✨registration is OPEN✨
AI for Robotics workshop (4th edition): Spatial AI
🗓️Nov 21-22 Grenoble, France!
Details: tinyurl.com/bdtk2nzs
⭐⭐ 14 confirmed speakers ⭐⭐: 🧵2/3
Poster submissions (travel grant possible): 🧵 3/3
Spread the word!
AI for Robotics workshop (4th edition): Spatial AI
🗓️Nov 21-22 Grenoble, France!
Details: tinyurl.com/bdtk2nzs
⭐⭐ 14 confirmed speakers ⭐⭐: 🧵2/3
Poster submissions (travel grant possible): 🧵 3/3
Spread the word!

July 29, 2025 at 4:01 PM
Major announcement ✨registration is OPEN✨
AI for Robotics workshop (4th edition): Spatial AI
🗓️Nov 21-22 Grenoble, France!
Details: tinyurl.com/bdtk2nzs
⭐⭐ 14 confirmed speakers ⭐⭐: 🧵2/3
Poster submissions (travel grant possible): 🧵 3/3
Spread the word!
AI for Robotics workshop (4th edition): Spatial AI
🗓️Nov 21-22 Grenoble, France!
Details: tinyurl.com/bdtk2nzs
⭐⭐ 14 confirmed speakers ⭐⭐: 🧵2/3
Poster submissions (travel grant possible): 🧵 3/3
Spread the word!
Reposted by Philippe Weinzaepfel

This is what you do when you set allow_sliding=true in your Habitat simulator. If you want to run test with sim2real transfer, you might want to consider wearing a helmet !
July 4, 2025 at 5:20 PM
This is what you do when you set allow_sliding=true in your Habitat simulator. If you want to run test with sim2real transfer, you might want to consider wearing a helmet !
Reposted by Philippe Weinzaepfel
In a new paper led by Gianluca Monaci, with @weinzaepfelp.bsky.social and myself, we explore the relationship between rel pose estimation and image goal navigation and study different architectures: late fusion, channel cat (w/ or w/o space2depth) and cross-attention.
arxiv.org/abs/2507.01667
🧵1/5
arxiv.org/abs/2507.01667
🧵1/5
July 4, 2025 at 5:00 PM
In a new paper led by Gianluca Monaci, with @weinzaepfelp.bsky.social and myself, we explore the relationship between rel pose estimation and image goal navigation and study different architectures: late fusion, channel cat (w/ or w/o space2depth) and cross-attention.
arxiv.org/abs/2507.01667
🧵1/5
arxiv.org/abs/2507.01667
🧵1/5
Reposted by Philippe Weinzaepfel

Excited to share our latest work in the *St3R family. PanSt3R, accepted at #ICCV25 proposes a unified and integrated approach for panoptic 3D scene reconstruction and panoptic segmentation in a single forward pass.
www.arxiv.org/abs/2506.21348
www.arxiv.org/abs/2506.21348

June 30, 2025 at 12:47 PM
Excited to share our latest work in the *St3R family. PanSt3R, accepted at #ICCV25 proposes a unified and integrated approach for panoptic 3D scene reconstruction and panoptic segmentation in a single forward pass.
www.arxiv.org/abs/2506.21348
www.arxiv.org/abs/2506.21348
Reposted by Philippe Weinzaepfel
We extended MUSt3R with semantic awareness and multi-view panoptic segmentation capabilities in PanSt3R, accepted at #ICCV2025
www.arxiv.org/abs/2506.21348
www.arxiv.org/abs/2506.21348
June 30, 2025 at 1:07 PM
We extended MUSt3R with semantic awareness and multi-view panoptic segmentation capabilities in PanSt3R, accepted at #ICCV2025
www.arxiv.org/abs/2506.21348
www.arxiv.org/abs/2506.21348
Wanna the outstanding performance of MASt3R while using a ViT-B or ViT-S encoder instead of its ViT-L one? Don't miss how we build DUNE, a single encoder for diverse 2D & 3D tasks, at this afternoon #CVPR2025 poster session (poster #376).
paper: arxiv.org/abs/2503.14405
code: github.com/naver/dune
paper: arxiv.org/abs/2503.14405
code: github.com/naver/dune

June 15, 2025 at 12:02 PM
Wanna the outstanding performance of MASt3R while using a ViT-B or ViT-S encoder instead of its ViT-L one? Don't miss how we build DUNE, a single encoder for diverse 2D & 3D tasks, at this afternoon #CVPR2025 poster session (poster #376).
paper: arxiv.org/abs/2503.14405
code: github.com/naver/dune
paper: arxiv.org/abs/2503.14405
code: github.com/naver/dune
Reposted by Philippe Weinzaepfel
Our work on "Reasoning in visual navigation..." presented as a "Highlight" by Boris Chidlovskii and Francesco Giuliari at #cvpr2025!
Interactive site, play around with dynamical models:
europe.naverlabs.com/research/pub...
Thanks @weinzaepfelp.bsky.social for the photo.
@steevenj7.bsky.social
Interactive site, play around with dynamical models:
europe.naverlabs.com/research/pub...
Thanks @weinzaepfelp.bsky.social for the photo.
@steevenj7.bsky.social

June 14, 2025 at 5:33 PM
Our work on "Reasoning in visual navigation..." presented as a "Highlight" by Boris Chidlovskii and Francesco Giuliari at #cvpr2025!
Interactive site, play around with dynamical models:
europe.naverlabs.com/research/pub...
Thanks @weinzaepfelp.bsky.social for the photo.
@steevenj7.bsky.social
Interactive site, play around with dynamical models:
europe.naverlabs.com/research/pub...
Thanks @weinzaepfelp.bsky.social for the photo.
@steevenj7.bsky.social
Checkout MUSt3R and Pow3R during this morning session at #CVPR2025 (posters 82 & 84) and give a try to their code.
Get the Pow3R to integrate priors into your 3D reconstructions; and obtain nice SfM/SLAM reconstructions with MUSt3R by leverating a memory mechanism.
Get the Pow3R to integrate priors into your 3D reconstructions; and obtain nice SfM/SLAM reconstructions with MUSt3R by leverating a memory mechanism.
MUSt3R and Pow3R code the same day 😮!
All @naverlabseurope.bsky.social code & data can be accessed here europe.naverlabs.com/research/code/
All @naverlabseurope.bsky.social code & data can be accessed here europe.naverlabs.com/research/code/
June 13, 2025 at 9:45 AM
Checkout MUSt3R and Pow3R during this morning session at #CVPR2025 (posters 82 & 84) and give a try to their code.
Get the Pow3R to integrate priors into your 3D reconstructions; and obtain nice SfM/SLAM reconstructions with MUSt3R by leverating a memory mechanism.
Get the Pow3R to integrate priors into your 3D reconstructions; and obtain nice SfM/SLAM reconstructions with MUSt3R by leverating a memory mechanism.
Reposted by Philippe Weinzaepfel
MUSt3R and Pow3R code the same day 😮!
All @naverlabseurope.bsky.social code & data can be accessed here europe.naverlabs.com/research/code/
All @naverlabseurope.bsky.social code & data can be accessed here europe.naverlabs.com/research/code/
June 13, 2025 at 8:49 AM
MUSt3R and Pow3R code the same day 😮!
All @naverlabseurope.bsky.social code & data can be accessed here europe.naverlabs.com/research/code/
All @naverlabseurope.bsky.social code & data can be accessed here europe.naverlabs.com/research/code/
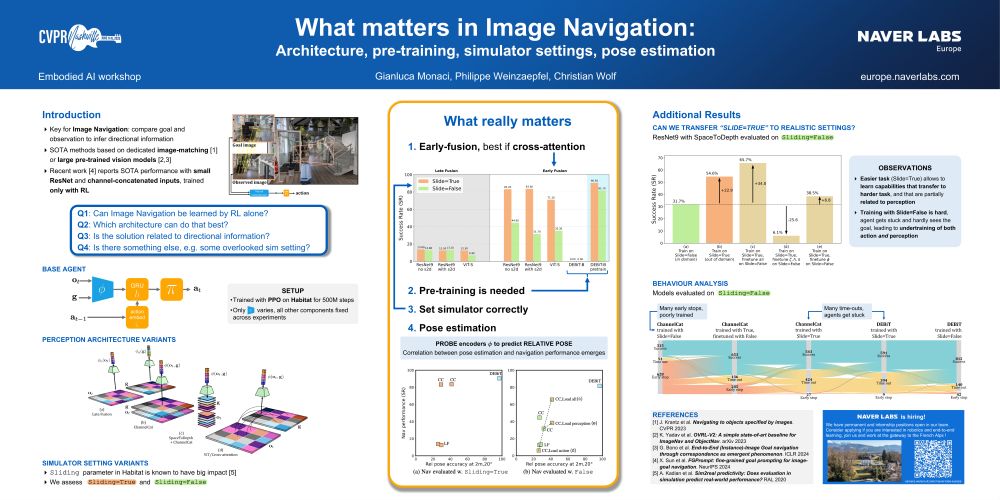
During today's #CVPR2025 workshops, I will present:
- What matters in ImageNav: architecture, pre-training, sim settings, pose (poster & highlight at the Embodied AI workshop)
- CondiMen: Conditional Multi-person Human Mesh Recovery (Poster at the Rhobin workshop and at the 3D Humans workshop)
- What matters in ImageNav: architecture, pre-training, sim settings, pose (poster & highlight at the Embodied AI workshop)
- CondiMen: Conditional Multi-person Human Mesh Recovery (Poster at the Rhobin workshop and at the 3D Humans workshop)

June 12, 2025 at 12:19 PM
During today's #CVPR2025 workshops, I will present:
- What matters in ImageNav: architecture, pre-training, sim settings, pose (poster & highlight at the Embodied AI workshop)
- CondiMen: Conditional Multi-person Human Mesh Recovery (Poster at the Rhobin workshop and at the 3D Humans workshop)
- What matters in ImageNav: architecture, pre-training, sim settings, pose (poster & highlight at the Embodied AI workshop)
- CondiMen: Conditional Multi-person Human Mesh Recovery (Poster at the Rhobin workshop and at the 3D Humans workshop)
Good morning Nashville !
Few pics from an (really) early jet-lagged run
Few pics from an (really) early jet-lagged run




June 11, 2025 at 12:00 PM
Good morning Nashville !
Few pics from an (really) early jet-lagged run
Few pics from an (really) early jet-lagged run