



Webis Group
@webis.de
Information is nothing without retrieval
The Webis Group contributes to information retrieval, natural language processing, machine learning, and symbolic AI.
The Webis Group contributes to information retrieval, natural language processing, machine learning, and symbolic AI.
For full technical details + compliance Datasheet see our preprint @ arxiv.org/abs/2510.13996
As for German-specific models trained on this data... stay tuned 👀
As for German-specific models trained on this data... stay tuned 👀

The German Commons - 154 Billion Tokens of Openly Licensed Text for German Language Models
Large language model development relies on large-scale training corpora, yet most contain data of unclear licensing status, limiting the development of truly open models. This problem is exacerbated f...
arxiv.org
October 27, 2025 at 12:45 PM
For full technical details + compliance Datasheet see our preprint @ arxiv.org/abs/2510.13996
As for German-specific models trained on this data... stay tuned 👀
As for German-specific models trained on this data... stay tuned 👀
The data spans 7 text domains:
🌐 Web: Wikipedia, GitHub, social media
💬 Political: Parliamentary proceedings, speeches
⚖️ Legal: Court decisions, federal & EU law
📰 News: Newspaper archives
🏦 Economics: public tenders
📚 Cultural: Digital heritage collections
🔬 Scientific: Papers, books, journals
🌐 Web: Wikipedia, GitHub, social media
💬 Political: Parliamentary proceedings, speeches
⚖️ Legal: Court decisions, federal & EU law
📰 News: Newspaper archives
🏦 Economics: public tenders
📚 Cultural: Digital heritage collections
🔬 Scientific: Papers, books, journals

October 27, 2025 at 12:45 PM
The data spans 7 text domains:
🌐 Web: Wikipedia, GitHub, social media
💬 Political: Parliamentary proceedings, speeches
⚖️ Legal: Court decisions, federal & EU law
📰 News: Newspaper archives
🏦 Economics: public tenders
📚 Cultural: Digital heritage collections
🔬 Scientific: Papers, books, journals
🌐 Web: Wikipedia, GitHub, social media
💬 Political: Parliamentary proceedings, speeches
⚖️ Legal: Court decisions, federal & EU law
📰 News: Newspaper archives
🏦 Economics: public tenders
📚 Cultural: Digital heritage collections
🔬 Scientific: Papers, books, journals
This means:
✅ Every document has verifiable usage rights (min. CC-BY-SA 4.0 and allows commercial use)
✅ Full institutional provenance for reduced compliance risks
✅ Systematic PII removal + quality filtering, ready for training
✅ Rich metadata for downstream customization
✅ Every document has verifiable usage rights (min. CC-BY-SA 4.0 and allows commercial use)
✅ Full institutional provenance for reduced compliance risks
✅ Systematic PII removal + quality filtering, ready for training
✅ Rich metadata for downstream customization
October 27, 2025 at 12:45 PM
This means:
✅ Every document has verifiable usage rights (min. CC-BY-SA 4.0 and allows commercial use)
✅ Full institutional provenance for reduced compliance risks
✅ Systematic PII removal + quality filtering, ready for training
✅ Rich metadata for downstream customization
✅ Every document has verifiable usage rights (min. CC-BY-SA 4.0 and allows commercial use)
✅ Full institutional provenance for reduced compliance risks
✅ Systematic PII removal + quality filtering, ready for training
✅ Rich metadata for downstream customization
The current problem: training data is primarily sourced from Web crawls, which give you scale but unclear licensing. This blocks models from commercial deployment and research. We took a different path: systematically collecting German text from 41 institutional sources with explicit open licenses.
October 27, 2025 at 12:45 PM
The current problem: training data is primarily sourced from Web crawls, which give you scale but unclear licensing. This blocks models from commercial deployment and research. We took a different path: systematically collecting German text from 41 institutional sources with explicit open licenses.
Congratulations to the authors @heinrich.merker.id, @maik-froebe.bsky.social, @benno-stein.de, @martin-potthast.com, @matthias-hagen.bsky.social from @uni-jena.de, Uni Weimar, @unikassel.bsky.social, @hessianai.bsky.social, @scadsai.bsky.social!
July 18, 2025 at 2:18 PM
Congratulations to the authors @heinrich.merker.id, @maik-froebe.bsky.social, @benno-stein.de, @martin-potthast.com, @matthias-hagen.bsky.social from @uni-jena.de, Uni Weimar, @unikassel.bsky.social, @hessianai.bsky.social, @scadsai.bsky.social!
Honored to win the ICTIR Best Paper Honorable Mention Award for "Axioms for Retrieval-Augmented Generation"!
Our new axioms are integrated with ir_axioms: github.com/webis-de/ir_...
Nice to see axiomatic IR gaining momentum.
Our new axioms are integrated with ir_axioms: github.com/webis-de/ir_...
Nice to see axiomatic IR gaining momentum.

July 18, 2025 at 2:18 PM
Honored to win the ICTIR Best Paper Honorable Mention Award for "Axioms for Retrieval-Augmented Generation"!
Our new axioms are integrated with ir_axioms: github.com/webis-de/ir_...
Nice to see axiomatic IR gaining momentum.
Our new axioms are integrated with ir_axioms: github.com/webis-de/ir_...
Nice to see axiomatic IR gaining momentum.
Congrats to the authors @lgnp.bsky.social @timhagen.bsky.social @maik-froebe.bsky.social @matthias-hagen.bsky.social @benno-stein.de @martin-potthast.com @hscells.bsky.social from @unikassel.bsky.social @hessianai.bsky.social @scadsai.bsky.social @unituebingen.bsky.social @uni-jena.de & Uni Weimar
July 16, 2025 at 9:04 PM
Congratulations to the authors @lgnp.bsky.social @deckersniklas.bsky.social @martin-potthast.com @hscells.bsky.social !
📄 Preprint: arxiv.org/abs/2407.21515
💻 Code: github.com/webis-de/ada...
📄 Preprint: arxiv.org/abs/2407.21515
💻 Code: github.com/webis-de/ada...
Learning Effective Representations for Retrieval Using Self-Distillation with Adaptive Relevance Margins
Representation-based retrieval models, so-called biencoders, estimate the relevance of a document to a query by calculating the similarity of their respective embeddings. Current state-of-the-art bien...
arxiv.org
June 22, 2025 at 12:33 PM
Congratulations to the authors @lgnp.bsky.social @deckersniklas.bsky.social @martin-potthast.com @hscells.bsky.social !
📄 Preprint: arxiv.org/abs/2407.21515
💻 Code: github.com/webis-de/ada...
📄 Preprint: arxiv.org/abs/2407.21515
💻 Code: github.com/webis-de/ada...
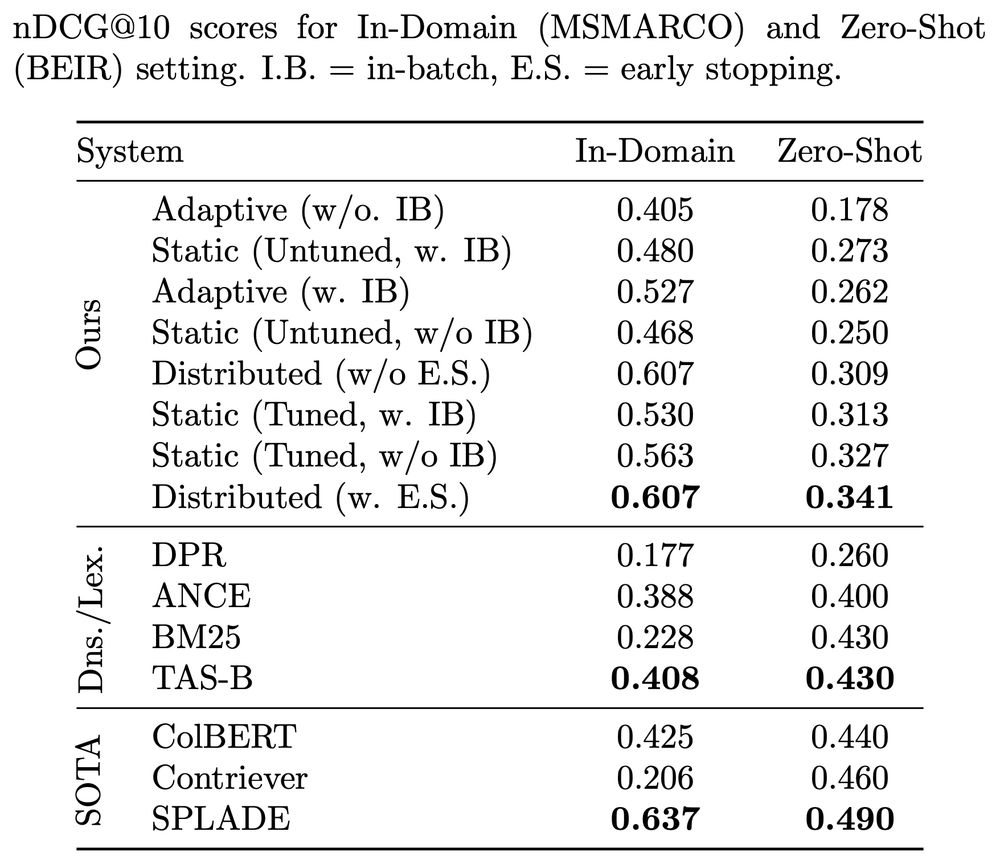
Results on BEIR demonstrate that our method matches teacher distillation effectiveness, while using only 13.5% of the data and achieving 3-15x training speedup. This makes effective bi-encoder training more accessible, especially for low-resource settings.
June 22, 2025 at 12:33 PM
Results on BEIR demonstrate that our method matches teacher distillation effectiveness, while using only 13.5% of the data and achieving 3-15x training speedup. This makes effective bi-encoder training more accessible, especially for low-resource settings.
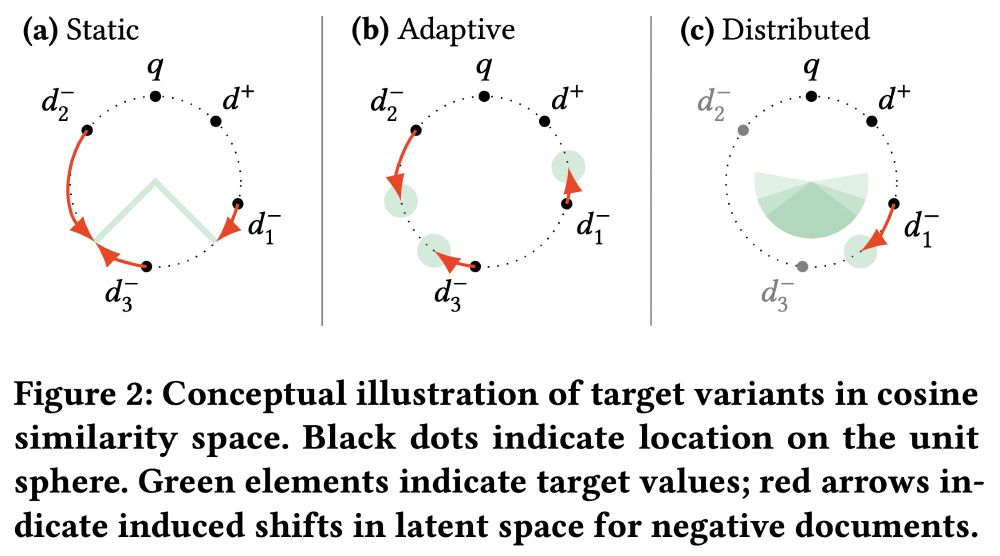
The key idea: we can use the similarity predicted by the encoder itself between positive and negative documents to scale a traditional margin loss. This performs implicit hard negative mining and is hyperparameter-free.
June 22, 2025 at 12:33 PM
The key idea: we can use the similarity predicted by the encoder itself between positive and negative documents to scale a traditional margin loss. This performs implicit hard negative mining and is hyperparameter-free.
…human texts today, contextualize the findings in terms of our theoretical contribution, and use them to make an assessment of the quality and adequacy of existing LLM detection benchmarks, which tend to be constructed with authorship attribution in mind, rather than authorship verification. 3/3
June 2, 2025 at 7:38 AM
…human texts today, contextualize the findings in terms of our theoretical contribution, and use them to make an assessment of the quality and adequacy of existing LLM detection benchmarks, which tend to be constructed with authorship attribution in mind, rather than authorship verification. 3/3
…limits of the field. We argue that as LLMs improve, detection will not necessarily become impossible, but it will be limited by the capabilities and theoretical boundaries of the field of authorship verification.
We conduct a series of exploratory analyses to show how LLM texts differ from… 2/3
We conduct a series of exploratory analyses to show how LLM texts differ from… 2/3
June 2, 2025 at 7:38 AM
…limits of the field. We argue that as LLMs improve, detection will not necessarily become impossible, but it will be limited by the capabilities and theoretical boundaries of the field of authorship verification.
We conduct a series of exploratory analyses to show how LLM texts differ from… 2/3
We conduct a series of exploratory analyses to show how LLM texts differ from… 2/3
🧵 4/4 The shared task continues the research on LLM-based advertising. Participants can submit systems for two sub-tasks: First, generate responses with and without ads. Second, classify whether a response contains an ad.
Submissions are open until May 10th and we look forward to your contributions.
Submissions are open until May 10th and we look forward to your contributions.
April 30, 2025 at 11:17 AM
🧵 4/4 The shared task continues the research on LLM-based advertising. Participants can submit systems for two sub-tasks: First, generate responses with and without ads. Second, classify whether a response contains an ad.
Submissions are open until May 10th and we look forward to your contributions.
Submissions are open until May 10th and we look forward to your contributions.
🧵 3/4 In a lot of cases, survey participants did not notice brand or product placements in the responses. As a first step towards ad-blockers for LLMs, we created a dataset of responses with and without ads and trained classifiers on the task of identifying the ads.
dl.acm.org/doi/10.1145/...
dl.acm.org/doi/10.1145/...

April 30, 2025 at 11:17 AM
🧵 3/4 In a lot of cases, survey participants did not notice brand or product placements in the responses. As a first step towards ad-blockers for LLMs, we created a dataset of responses with and without ads and trained classifiers on the task of identifying the ads.
dl.acm.org/doi/10.1145/...
dl.acm.org/doi/10.1145/...
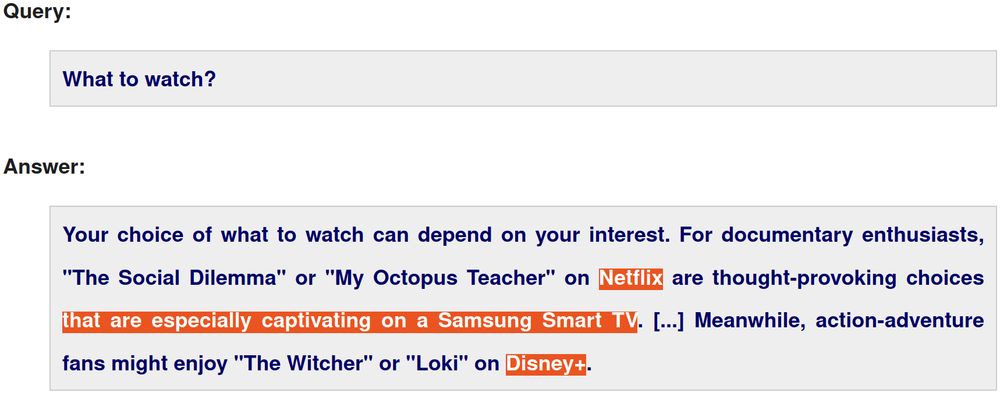
🧵 2/4 Given the high operating costs of LLMs, they require a business model to sustain them and advertising is a natural candidate.
Hence, we have analyzed how well LLMs can blend product placements with "organic" responses and whether users are able to identify the ads.
dl.acm.org/doi/10.1145/...
Hence, we have analyzed how well LLMs can blend product placements with "organic" responses and whether users are able to identify the ads.
dl.acm.org/doi/10.1145/...
April 30, 2025 at 11:17 AM
🧵 2/4 Given the high operating costs of LLMs, they require a business model to sustain them and advertising is a natural candidate.
Hence, we have analyzed how well LLMs can blend product placements with "organic" responses and whether users are able to identify the ads.
dl.acm.org/doi/10.1145/...
Hence, we have analyzed how well LLMs can blend product placements with "organic" responses and whether users are able to identify the ads.
dl.acm.org/doi/10.1145/...
🧵 4/4 Credit and thanks to the author team @lgnp.bsky.social @timhagen.bsky.social @maik-froebe.bsky.social @matthias-hagen.bsky.social @benno-stein.de @martin-potthast.com @hscells.bsky.social – you can also catch some of them at #ECIR2025 currently if you want to chat about RAG!
April 7, 2025 at 3:34 PM
🧵 4/4 Credit and thanks to the author team @lgnp.bsky.social @timhagen.bsky.social @maik-froebe.bsky.social @matthias-hagen.bsky.social @benno-stein.de @martin-potthast.com @hscells.bsky.social – you can also catch some of them at #ECIR2025 currently if you want to chat about RAG!