




Webis Group
@webis.de
Information is nothing without retrieval
The Webis Group contributes to information retrieval, natural language processing, machine learning, and symbolic AI.
The Webis Group contributes to information retrieval, natural language processing, machine learning, and symbolic AI.
The data spans 7 text domains:
🌐 Web: Wikipedia, GitHub, social media
💬 Political: Parliamentary proceedings, speeches
⚖️ Legal: Court decisions, federal & EU law
📰 News: Newspaper archives
🏦 Economics: public tenders
📚 Cultural: Digital heritage collections
🔬 Scientific: Papers, books, journals
🌐 Web: Wikipedia, GitHub, social media
💬 Political: Parliamentary proceedings, speeches
⚖️ Legal: Court decisions, federal & EU law
📰 News: Newspaper archives
🏦 Economics: public tenders
📚 Cultural: Digital heritage collections
🔬 Scientific: Papers, books, journals

October 27, 2025 at 12:45 PM
The data spans 7 text domains:
🌐 Web: Wikipedia, GitHub, social media
💬 Political: Parliamentary proceedings, speeches
⚖️ Legal: Court decisions, federal & EU law
📰 News: Newspaper archives
🏦 Economics: public tenders
📚 Cultural: Digital heritage collections
🔬 Scientific: Papers, books, journals
🌐 Web: Wikipedia, GitHub, social media
💬 Political: Parliamentary proceedings, speeches
⚖️ Legal: Court decisions, federal & EU law
📰 News: Newspaper archives
🏦 Economics: public tenders
📚 Cultural: Digital heritage collections
🔬 Scientific: Papers, books, journals
Honored to win the ICTIR Best Paper Honorable Mention Award for "Axioms for Retrieval-Augmented Generation"!
Our new axioms are integrated with ir_axioms: github.com/webis-de/ir_...
Nice to see axiomatic IR gaining momentum.
Our new axioms are integrated with ir_axioms: github.com/webis-de/ir_...
Nice to see axiomatic IR gaining momentum.

July 18, 2025 at 2:18 PM
Honored to win the ICTIR Best Paper Honorable Mention Award for "Axioms for Retrieval-Augmented Generation"!
Our new axioms are integrated with ir_axioms: github.com/webis-de/ir_...
Nice to see axiomatic IR gaining momentum.
Our new axioms are integrated with ir_axioms: github.com/webis-de/ir_...
Nice to see axiomatic IR gaining momentum.
We presented two papers at ICTIR 2025 today:
- Axioms for Retrieval-Augmented Generation webis.de/publications...
- Learning Effective Representations for Retrieval Using Self-Distillation with Adaptive Relevance Margins webis.de/publications...
- Axioms for Retrieval-Augmented Generation webis.de/publications...
- Learning Effective Representations for Retrieval Using Self-Distillation with Adaptive Relevance Margins webis.de/publications...

July 18, 2025 at 2:18 PM
We presented two papers at ICTIR 2025 today:
- Axioms for Retrieval-Augmented Generation webis.de/publications...
- Learning Effective Representations for Retrieval Using Self-Distillation with Adaptive Relevance Margins webis.de/publications...
- Axioms for Retrieval-Augmented Generation webis.de/publications...
- Learning Effective Representations for Retrieval Using Self-Distillation with Adaptive Relevance Margins webis.de/publications...
Thrilled to announce that Matti Wiegmann has successfully defended his PhD! 🎉🧑🎓 Huge congratulations on this incredible achievement! #PhDDefense #AcademicMilestone

July 18, 2025 at 11:44 AM
Thrilled to announce that Matti Wiegmann has successfully defended his PhD! 🎉🧑🎓 Huge congratulations on this incredible achievement! #PhDDefense #AcademicMilestone
Happy to share that our paper "The Viability of Crowdsourcing for RAG Evaluation" received the Best Paper Honourable Mention at #SIGIR2025! Very grateful to the community for recognizing our work on improving RAG evaluation.
📄 webis.de/publications...
📄 webis.de/publications...

July 16, 2025 at 9:04 PM
Happy to share that our paper "The Viability of Crowdsourcing for RAG Evaluation" received the Best Paper Honourable Mention at #SIGIR2025! Very grateful to the community for recognizing our work on improving RAG evaluation.
📄 webis.de/publications...
📄 webis.de/publications...
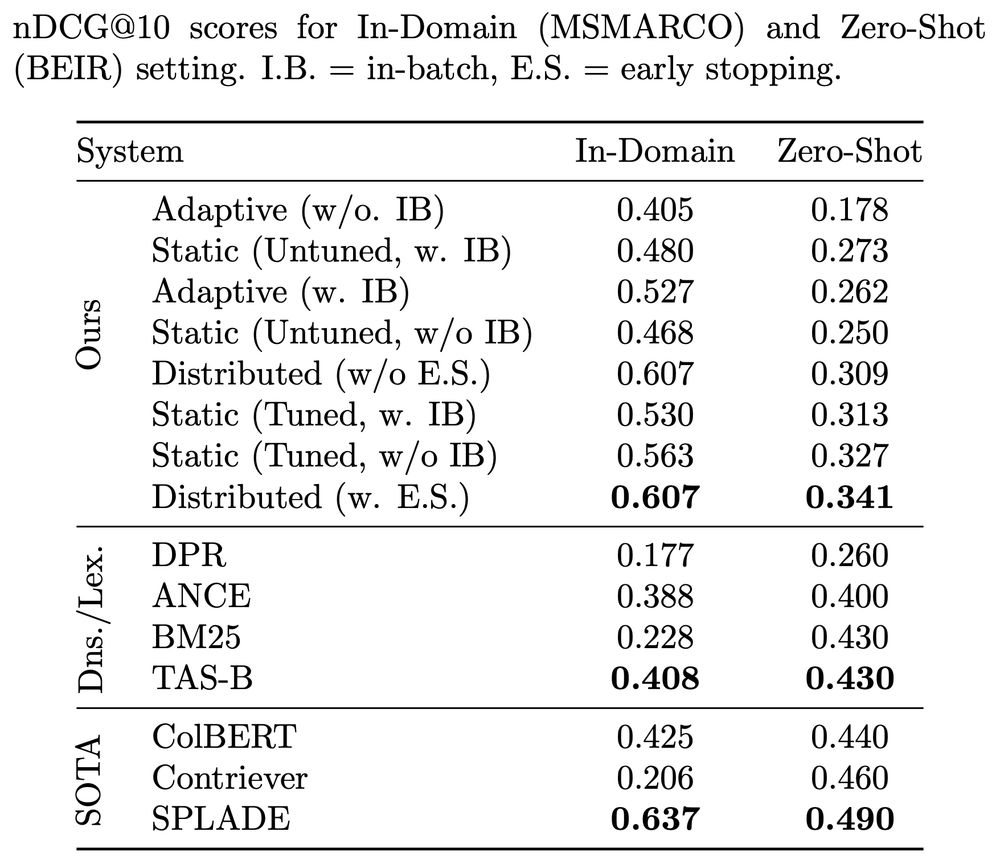
Results on BEIR demonstrate that our method matches teacher distillation effectiveness, while using only 13.5% of the data and achieving 3-15x training speedup. This makes effective bi-encoder training more accessible, especially for low-resource settings.
June 22, 2025 at 12:33 PM
Results on BEIR demonstrate that our method matches teacher distillation effectiveness, while using only 13.5% of the data and achieving 3-15x training speedup. This makes effective bi-encoder training more accessible, especially for low-resource settings.
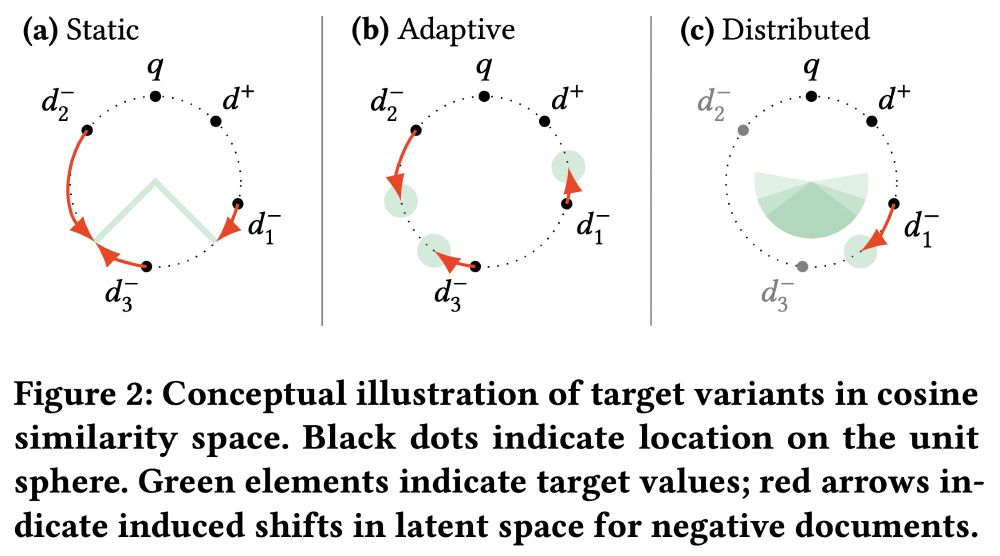
The key idea: we can use the similarity predicted by the encoder itself between positive and negative documents to scale a traditional margin loss. This performs implicit hard negative mining and is hyperparameter-free.
June 22, 2025 at 12:33 PM
The key idea: we can use the similarity predicted by the encoder itself between positive and negative documents to scale a traditional margin loss. This performs implicit hard negative mining and is hyperparameter-free.
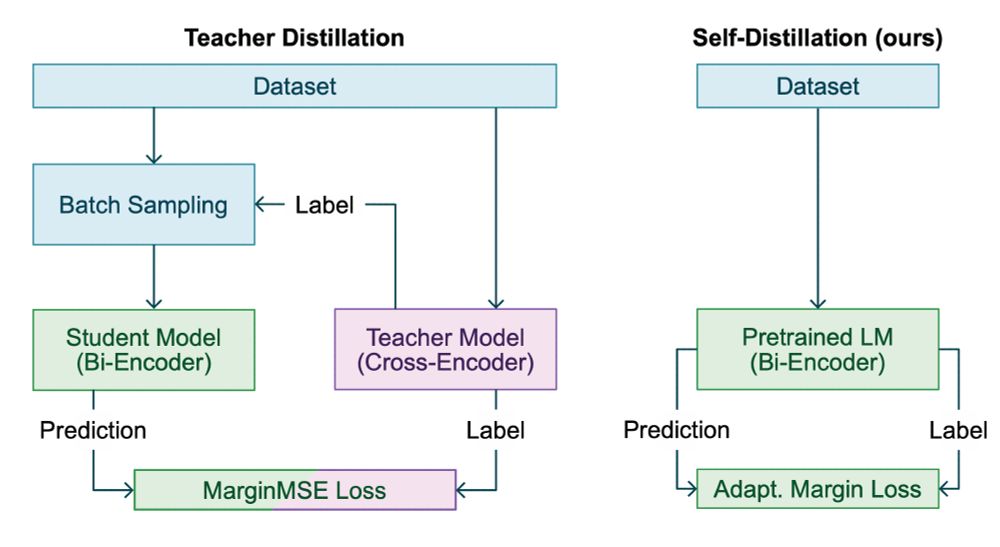
Our paper on self-distillation for training bi-encoders got accepted at #ICTIR2025! By exploiting pretrained encoder capabilities, our approach eliminates expensive teacher models and batch sampling while maintaining the same effectiveness.
June 22, 2025 at 12:33 PM
Our paper on self-distillation for training bi-encoders got accepted at #ICTIR2025! By exploiting pretrained encoder capabilities, our approach eliminates expensive teacher models and batch sampling while maintaining the same effectiveness.
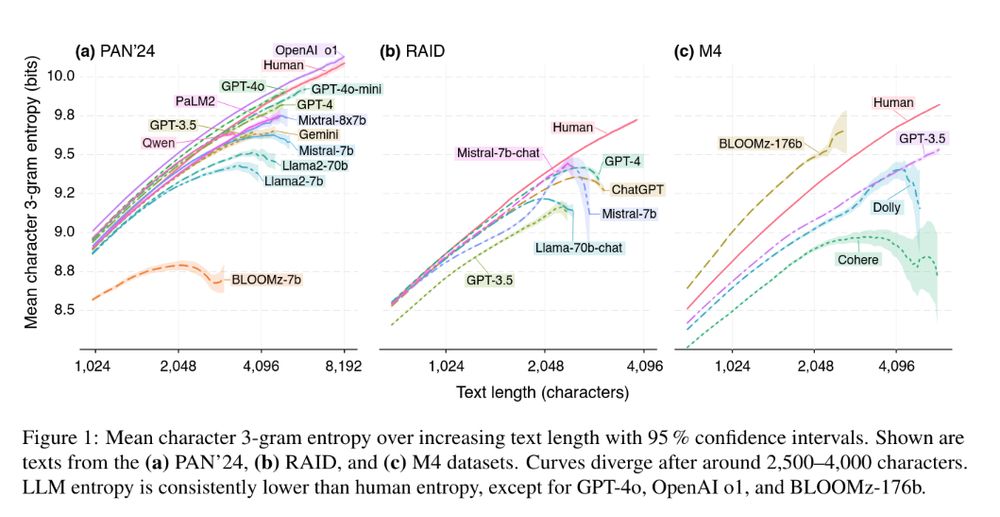
Our paper titled “The Two Paradigms of LLM Detection: Authorship Attribution vs. Authorship Verification” has been accepted to #ACL2025 (Findings). downloads.webis.de/publications...
We discuss why LLM detection is a one-class problem and how that affects the prospective… 1/3 #ACL #NLP #ARR #LLM
We discuss why LLM detection is a one-class problem and how that affects the prospective… 1/3 #ACL #NLP #ARR #LLM

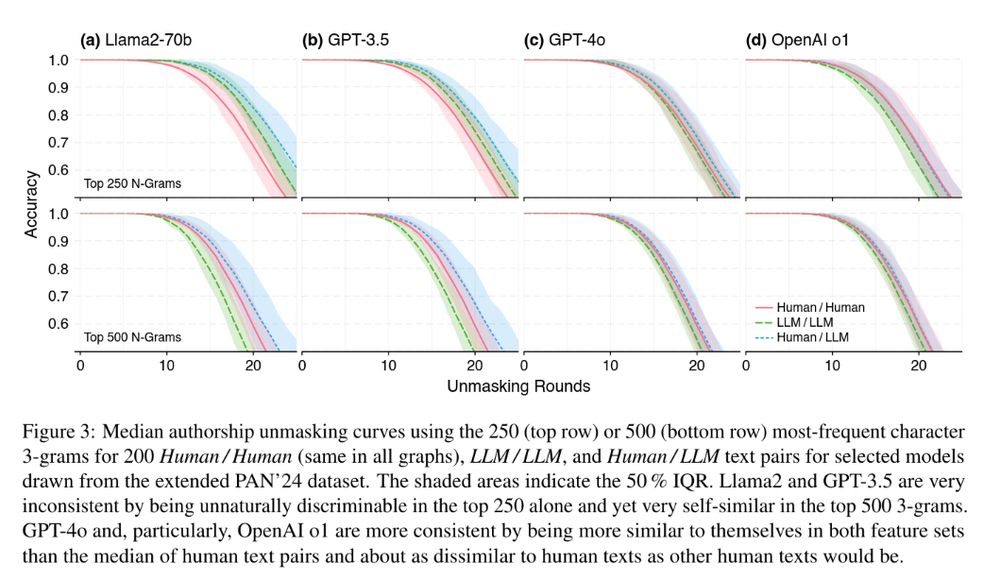
June 2, 2025 at 7:38 AM
🧵 3/4 In a lot of cases, survey participants did not notice brand or product placements in the responses. As a first step towards ad-blockers for LLMs, we created a dataset of responses with and without ads and trained classifiers on the task of identifying the ads.
dl.acm.org/doi/10.1145/...
dl.acm.org/doi/10.1145/...

April 30, 2025 at 11:17 AM
🧵 3/4 In a lot of cases, survey participants did not notice brand or product placements in the responses. As a first step towards ad-blockers for LLMs, we created a dataset of responses with and without ads and trained classifiers on the task of identifying the ads.
dl.acm.org/doi/10.1145/...
dl.acm.org/doi/10.1145/...
🧵 2/4 Given the high operating costs of LLMs, they require a business model to sustain them and advertising is a natural candidate.
Hence, we have analyzed how well LLMs can blend product placements with "organic" responses and whether users are able to identify the ads.
dl.acm.org/doi/10.1145/...
Hence, we have analyzed how well LLMs can blend product placements with "organic" responses and whether users are able to identify the ads.
dl.acm.org/doi/10.1145/...
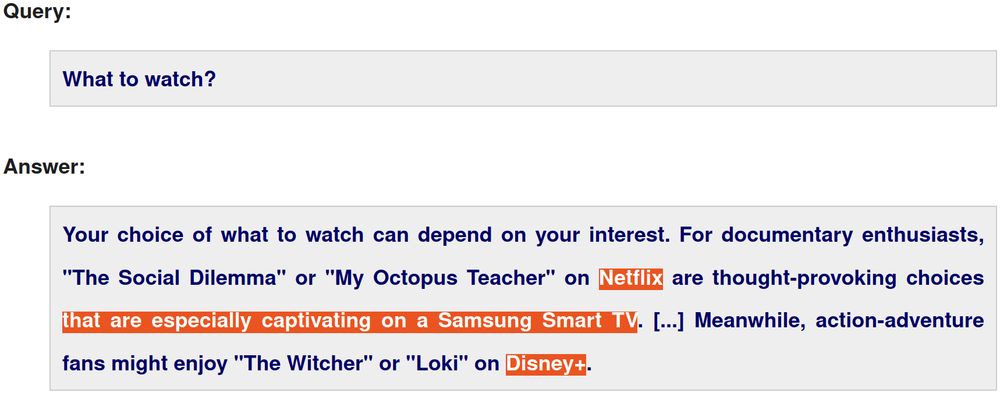
April 30, 2025 at 11:17 AM
🧵 2/4 Given the high operating costs of LLMs, they require a business model to sustain them and advertising is a natural candidate.
Hence, we have analyzed how well LLMs can blend product placements with "organic" responses and whether users are able to identify the ads.
dl.acm.org/doi/10.1145/...
Hence, we have analyzed how well LLMs can blend product placements with "organic" responses and whether users are able to identify the ads.
dl.acm.org/doi/10.1145/...
Can LLM-generated ads be blocked? With OpenAI adding shopping options to ChatGPT, this question gains further importance.
If you are interested in contributing to the research on LLM-based advertising, please check out our shared task: touche.webis.de/clef25/touch...
More details below.
If you are interested in contributing to the research on LLM-based advertising, please check out our shared task: touche.webis.de/clef25/touch...
More details below.
April 30, 2025 at 11:17 AM
Can LLM-generated ads be blocked? With OpenAI adding shopping options to ChatGPT, this question gains further importance.
If you are interested in contributing to the research on LLM-based advertising, please check out our shared task: touche.webis.de/clef25/touch...
More details below.
If you are interested in contributing to the research on LLM-based advertising, please check out our shared task: touche.webis.de/clef25/touch...
More details below.
📢 Our paper "The Viability of Crowdsourcing for RAG Evaluation" has been accepted to #SIGIR2025 !
We compared how good humans and LLMs are at writing and judging RAG responses, assembling 1800+ responses across 3 styles, and 47K+ pairwise judgments in 7 quality dimensions. 🧵➡️
We compared how good humans and LLMs are at writing and judging RAG responses, assembling 1800+ responses across 3 styles, and 47K+ pairwise judgments in 7 quality dimensions. 🧵➡️

April 7, 2025 at 3:34 PM
📢 Our paper "The Viability of Crowdsourcing for RAG Evaluation" has been accepted to #SIGIR2025 !
We compared how good humans and LLMs are at writing and judging RAG responses, assembling 1800+ responses across 3 styles, and 47K+ pairwise judgments in 7 quality dimensions. 🧵➡️
We compared how good humans and LLMs are at writing and judging RAG responses, assembling 1800+ responses across 3 styles, and 47K+ pairwise judgments in 7 quality dimensions. 🧵➡️
Below you can see our past tweets, just imported from “the darkened X”.
Above, we see nothing but Bluesky.
Above, we see nothing but Bluesky.

November 8, 2024 at 7:47 PM
Below you can see our past tweets, just imported from “the darkened X”.
Above, we see nothing but Bluesky.
Above, we see nothing but Bluesky.
Goodbye Washington! We had a fantastic week with interesting talks, discussions, and new ideas at #SIGIR24 #SIGIR2024. We hope to see you all again next year in Italy :) https://x.com/webis_de/status/1815115279510208625/photo/1




November 8, 2024 at 7:25 PM
Goodbye Washington! We had a fantastic week with interesting talks, discussions, and new ideas at #SIGIR24 #SIGIR2024. We hope to see you all again next year in Italy :) https://x.com/webis_de/status/1815115279510208625/photo/1
In our experiments, LLMs struggle with the task in a zero-shot setting, especially due to low precision values. Sentence transformers, however, can be finetuned to successfully detect the inserted ads and achieve precision and recall values of above 0.9 for unseen meta topics. https://t.co/VuuaW...

November 8, 2024 at 7:25 PM
In our experiments, LLMs struggle with the task in a zero-shot setting, especially due to low precision values. Sentence transformers, however, can be finetuned to successfully detect the inserted ads and achieve precision and recall values of above 0.9 for unseen meta topics. https://t.co/VuuaW...
The Webis Generated Native Ads 2024 is the first public dataset to evaluate models on the task of detecting ads in responses of conversational search engines.
It was created by simulating an advertising service for queries from popular meta topics (product/service categories). https://t.co/pjHr...
It was created by simulating an advertising service for queries from popular meta topics (product/service categories). https://t.co/pjHr...

November 8, 2024 at 7:25 PM
The Webis Generated Native Ads 2024 is the first public dataset to evaluate models on the task of detecting ads in responses of conversational search engines.
It was created by simulating an advertising service for queries from popular meta topics (product/service categories). https://t.co/pjHr...
It was created by simulating an advertising service for queries from popular meta topics (product/service categories). https://t.co/pjHr...
What if conversational search will be financed by inserting ads directly into generated responses? We present our work on detecting these generated native ads at #TheWebConf24.
Come visit us at the short paper poster session on Thursday in the Central Ballroom. https://t.co/NRKbal57WO
Come visit us at the short paper poster session on Thursday in the Central Ballroom. https://t.co/NRKbal57WO

November 8, 2024 at 7:25 PM
What if conversational search will be financed by inserting ads directly into generated responses? We present our work on detecting these generated native ads at #TheWebConf24.
Come visit us at the short paper poster session on Thursday in the Central Ballroom. https://t.co/NRKbal57WO
Come visit us at the short paper poster session on Thursday in the Central Ballroom. https://t.co/NRKbal57WO
Right now, we will start the second half of the SCAI'24 workshop at #CHIIR2024 in hybrid mode. We will move from the big ideas and human-centered metrics to the challenges of human-in-the-loop evaluations. https://x.com/webis_de/status/1768277930768015536/photo/1



November 8, 2024 at 7:25 PM
Right now, we will start the second half of the SCAI'24 workshop at #CHIIR2024 in hybrid mode. We will move from the big ideas and human-centered metrics to the challenges of human-in-the-loop evaluations. https://x.com/webis_de/status/1768277930768015536/photo/1
How will conversational search AI pay for itself?
It may be native ads or product placement in generated answers. At #CHIIR2024 next week, we'll present a user study showing that many people don't recognize ads inserted by LLMs in generated search results: https://t.co/hrZE9moeKy https://t.co/qg...
It may be native ads or product placement in generated answers. At #CHIIR2024 next week, we'll present a user study showing that many people don't recognize ads inserted by LLMs in generated search results: https://t.co/hrZE9moeKy https://t.co/qg...


November 8, 2024 at 7:25 PM
How will conversational search AI pay for itself?
It may be native ads or product placement in generated answers. At #CHIIR2024 next week, we'll present a user study showing that many people don't recognize ads inserted by LLMs in generated search results: https://t.co/hrZE9moeKy https://t.co/qg...
It may be native ads or product placement in generated answers. At #CHIIR2024 next week, we'll present a user study showing that many people don't recognize ads inserted by LLMs in generated search results: https://t.co/hrZE9moeKy https://t.co/qg...
Working in Argumentation? Time to participate in Touché 2024!
Three shared tasks:
- Human Value Detection
- Ideology and Power Identification in Parliamentary Debates
- Image Retrieval/Generation for Arguments
Submission deadline is May 6th!
More info: https://t.co/rtgSDxpDTx https://t.co/S6Kl...
Three shared tasks:
- Human Value Detection
- Ideology and Power Identification in Parliamentary Debates
- Image Retrieval/Generation for Arguments
Submission deadline is May 6th!
More info: https://t.co/rtgSDxpDTx https://t.co/S6Kl...

November 8, 2024 at 7:24 PM
Working in Argumentation? Time to participate in Touché 2024!
Three shared tasks:
- Human Value Detection
- Ideology and Power Identification in Parliamentary Debates
- Image Retrieval/Generation for Arguments
Submission deadline is May 6th!
More info: https://t.co/rtgSDxpDTx https://t.co/S6Kl...
Three shared tasks:
- Human Value Detection
- Ideology and Power Identification in Parliamentary Debates
- Image Retrieval/Generation for Arguments
Submission deadline is May 6th!
More info: https://t.co/rtgSDxpDTx https://t.co/S6Kl...
Today, we were happy to welcome @anja_reu and @juliusgonsior to our seminar to learn about current challenges in math retrieval/active learning: "Transformer Encoders for Mathematical Answer Retrieval" and "The Missing Piece of Active Learning Research: a Reference Benchmark". https://t.co/eh4IH...




November 8, 2024 at 7:24 PM
Today, we were happy to welcome @anja_reu and @juliusgonsior to our seminar to learn about current challenges in math retrieval/active learning: "Transformer Encoders for Mathematical Answer Retrieval" and "The Missing Piece of Active Learning Research: a Reference Benchmark". https://t.co/eh4IH...
Today we had the pleasure of listening to a talk from @WojciechKusa about evaluating automated citation screening in systematic reviews. Very interesting to hear about the work he has done in new metrics and datasets for this domain! https://x.com/webis_de/status/1710256640941822084/photo/1


November 8, 2024 at 7:24 PM
Today we had the pleasure of listening to a talk from @WojciechKusa about evaluating automated citation screening in systematic reviews. Very interesting to hear about the work he has done in new metrics and datasets for this domain! https://x.com/webis_de/status/1710256640941822084/photo/1
Our @H1iReimer and @maik_froebe are thrilled to present two new resources at the @SIGIRConf poster session:
• The TIREx platform to run reproducible, blinded IR experiments & shared tasks 🧪
• The Archive Query Log, 350M queries crawled from the Internet Archive 🔍
#SIGIR2023 https://t.co/Np...
• The TIREx platform to run reproducible, blinded IR experiments & shared tasks 🧪
• The Archive Query Log, 350M queries crawled from the Internet Archive 🔍
#SIGIR2023 https://t.co/Np...

November 8, 2024 at 7:24 PM
Our @H1iReimer and @maik_froebe are thrilled to present two new resources at the @SIGIRConf poster session:
• The TIREx platform to run reproducible, blinded IR experiments & shared tasks 🧪
• The Archive Query Log, 350M queries crawled from the Internet Archive 🔍
#SIGIR2023 https://t.co/Np...
• The TIREx platform to run reproducible, blinded IR experiments & shared tasks 🧪
• The Archive Query Log, 350M queries crawled from the Internet Archive 🔍
#SIGIR2023 https://t.co/Np...
TIREx archives the Docker images for future replication and reproduction. Software submissions on TIREx can run on new additions to ir_datasets as retrieval approaches were implemented against the ir_datasets interface, promoting IR experiment #standardization. https://t.co/XRNGHmgBOa



November 8, 2024 at 7:24 PM
TIREx archives the Docker images for future replication and reproduction. Software submissions on TIREx can run on new additions to ir_datasets as retrieval approaches were implemented against the ir_datasets interface, promoting IR experiment #standardization. https://t.co/XRNGHmgBOa