



Unsloth AI
@unsloth.ai
Open source LLM fine-tuning! 🦥
Github: http://github.com/unslothai/unsloth Discord: https://discord.gg/unsloth
Github: http://github.com/unslothai/unsloth Discord: https://discord.gg/unsloth
The 1.58-bit quant fits in 131GB VRAM (2× H100s) for fast throughput inference at ~140 tokens/s.
For best results, use 2.51-bit Dynamic quant & at least 160GB+ combined VRAM + RAM.
Basic 1-bit & 2-bit quantization causes the model to produce repetition and poor code. Our dynamic quants solve this.
For best results, use 2.51-bit Dynamic quant & at least 160GB+ combined VRAM + RAM.
Basic 1-bit & 2-bit quantization causes the model to produce repetition and poor code. Our dynamic quants solve this.
March 25, 2025 at 11:54 PM
The 1.58-bit quant fits in 131GB VRAM (2× H100s) for fast throughput inference at ~140 tokens/s.
For best results, use 2.51-bit Dynamic quant & at least 160GB+ combined VRAM + RAM.
Basic 1-bit & 2-bit quantization causes the model to produce repetition and poor code. Our dynamic quants solve this.
For best results, use 2.51-bit Dynamic quant & at least 160GB+ combined VRAM + RAM.
Basic 1-bit & 2-bit quantization causes the model to produce repetition and poor code. Our dynamic quants solve this.
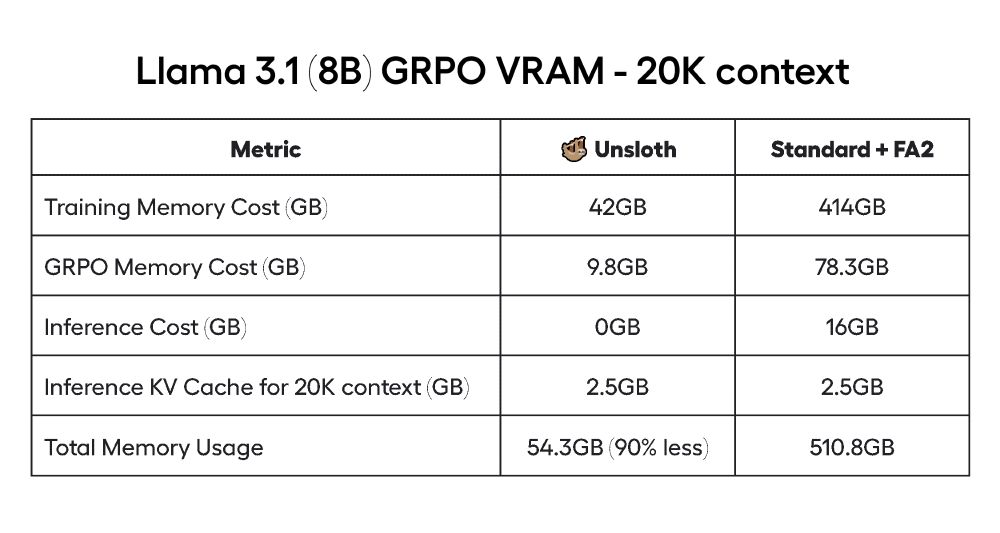
For our benchmarks, a standard GRPO QLoRA setup (TRL + FA2) for Llama 3.1 (8B) at 20K context required 510.8GB VRAM. Unsloth’s GRPO algorithms reduces this to just 54.3GB.
The 5GB VRAM requirement for Qwen2.5 (1.5B) is down from 7GB in our previous GRPO release two weeks ago!
The 5GB VRAM requirement for Qwen2.5 (1.5B) is down from 7GB in our previous GRPO release two weeks ago!
February 20, 2025 at 6:41 PM
For our benchmarks, a standard GRPO QLoRA setup (TRL + FA2) for Llama 3.1 (8B) at 20K context required 510.8GB VRAM. Unsloth’s GRPO algorithms reduces this to just 54.3GB.
The 5GB VRAM requirement for Qwen2.5 (1.5B) is down from 7GB in our previous GRPO release two weeks ago!
The 5GB VRAM requirement for Qwen2.5 (1.5B) is down from 7GB in our previous GRPO release two weeks ago!