


Unsloth AI
@unsloth.ai
Open source LLM fine-tuning! 🦥
Github: http://github.com/unslothai/unsloth Discord: https://discord.gg/unsloth
Github: http://github.com/unslothai/unsloth Discord: https://discord.gg/unsloth
You can now train OpenAI gpt-oss with Reinforcement Learning in our free notebook!
This notebook automatically creates faster kernels via RL.
Unsloth RL achieves the fastest inference & lowest VRAM vs. any setup - 0 accuracy loss
gpt-oss-20b GRPO Colab: colab.research.google.com/github/unslo...
This notebook automatically creates faster kernels via RL.
Unsloth RL achieves the fastest inference & lowest VRAM vs. any setup - 0 accuracy loss
gpt-oss-20b GRPO Colab: colab.research.google.com/github/unslo...

September 26, 2025 at 4:06 PM
You can now train OpenAI gpt-oss with Reinforcement Learning in our free notebook!
This notebook automatically creates faster kernels via RL.
Unsloth RL achieves the fastest inference & lowest VRAM vs. any setup - 0 accuracy loss
gpt-oss-20b GRPO Colab: colab.research.google.com/github/unslo...
This notebook automatically creates faster kernels via RL.
Unsloth RL achieves the fastest inference & lowest VRAM vs. any setup - 0 accuracy loss
gpt-oss-20b GRPO Colab: colab.research.google.com/github/unslo...
We're teaming up with Mistral and NVIDIA for an Unsloth event on Tues, Oct 21 at Y Combinator's office! 🦥
Join us in San Francisco for a night of talks, merch and more.
Food & drinks provided. RSVP required!
⭐ lu.ma/unsloth-yc
Join us in San Francisco for a night of talks, merch and more.
Food & drinks provided. RSVP required!
⭐ lu.ma/unsloth-yc

September 22, 2025 at 2:20 PM
We're teaming up with Mistral and NVIDIA for an Unsloth event on Tues, Oct 21 at Y Combinator's office! 🦥
Join us in San Francisco for a night of talks, merch and more.
Food & drinks provided. RSVP required!
⭐ lu.ma/unsloth-yc
Join us in San Francisco for a night of talks, merch and more.
Food & drinks provided. RSVP required!
⭐ lu.ma/unsloth-yc
Run DeepSeek-V3.1 locally on 170GB RAM with our Dynamic 1-bit GGUFs!🐋
The 715GB model gets reduced to 170GB (-80% size) by smartly quantizing layers.
The 1-bit GGUF passes all our code tests & we fixed the chat template.
Guide: docs.unsloth.ai/basics/deeps...
GGUF: huggingface.co/unsloth/Deep...
The 715GB model gets reduced to 170GB (-80% size) by smartly quantizing layers.
The 1-bit GGUF passes all our code tests & we fixed the chat template.
Guide: docs.unsloth.ai/basics/deeps...
GGUF: huggingface.co/unsloth/Deep...

August 22, 2025 at 8:13 PM
Run DeepSeek-V3.1 locally on 170GB RAM with our Dynamic 1-bit GGUFs!🐋
The 715GB model gets reduced to 170GB (-80% size) by smartly quantizing layers.
The 1-bit GGUF passes all our code tests & we fixed the chat template.
Guide: docs.unsloth.ai/basics/deeps...
GGUF: huggingface.co/unsloth/Deep...
The 715GB model gets reduced to 170GB (-80% size) by smartly quantizing layers.
The 1-bit GGUF passes all our code tests & we fixed the chat template.
Guide: docs.unsloth.ai/basics/deeps...
GGUF: huggingface.co/unsloth/Deep...
Learn to fine-tune OpenAI gpt-oss with our new step-by-step guide! ✨
Learn about:
• Local gpt-oss training + inference FAQ & tips
• Evaluation, hyperparameters & overfitting
• Reasoning effort, Data prep
• Run & saving your model to llama.cpp GGUF, HF etc.
🔗Guide: docs.unsloth.ai/basics/gpt-o...
Learn about:
• Local gpt-oss training + inference FAQ & tips
• Evaluation, hyperparameters & overfitting
• Reasoning effort, Data prep
• Run & saving your model to llama.cpp GGUF, HF etc.
🔗Guide: docs.unsloth.ai/basics/gpt-o...

August 18, 2025 at 2:20 PM
Learn to fine-tune OpenAI gpt-oss with our new step-by-step guide! ✨
Learn about:
• Local gpt-oss training + inference FAQ & tips
• Evaluation, hyperparameters & overfitting
• Reasoning effort, Data prep
• Run & saving your model to llama.cpp GGUF, HF etc.
🔗Guide: docs.unsloth.ai/basics/gpt-o...
Learn about:
• Local gpt-oss training + inference FAQ & tips
• Evaluation, hyperparameters & overfitting
• Reasoning effort, Data prep
• Run & saving your model to llama.cpp GGUF, HF etc.
🔗Guide: docs.unsloth.ai/basics/gpt-o...
We made a complete Guide on Reinforcement Learning (RL) for LLMs!
Learn about:
• RL's goal & why it's key to building intelligent AI agents
• Why o3, Claude 4 & R1 use RL
• GRPO, RLHF, DPO, reward functions
• Training your own local R1 model with Unsloth
🔗 docs.unsloth.ai/basics/reinf...
Learn about:
• RL's goal & why it's key to building intelligent AI agents
• Why o3, Claude 4 & R1 use RL
• GRPO, RLHF, DPO, reward functions
• Training your own local R1 model with Unsloth
🔗 docs.unsloth.ai/basics/reinf...

June 17, 2025 at 3:09 PM
We made a complete Guide on Reinforcement Learning (RL) for LLMs!
Learn about:
• RL's goal & why it's key to building intelligent AI agents
• Why o3, Claude 4 & R1 use RL
• GRPO, RLHF, DPO, reward functions
• Training your own local R1 model with Unsloth
🔗 docs.unsloth.ai/basics/reinf...
Learn about:
• RL's goal & why it's key to building intelligent AI agents
• Why o3, Claude 4 & R1 use RL
• GRPO, RLHF, DPO, reward functions
• Training your own local R1 model with Unsloth
🔗 docs.unsloth.ai/basics/reinf...
You can now run DeepSeek-R1-0528 locally with our Dynamic 1-bit GGUFs! 🐋
We shrank the full 715GB model to just 168GB (-80% size).
We achieve optimal accuracy by selectively quantizing layers.
DeepSeek-R1-0528-Qwen3-8B is also supported.
GGUFs: huggingface.co/unsloth/Deep...
We shrank the full 715GB model to just 168GB (-80% size).
We achieve optimal accuracy by selectively quantizing layers.
DeepSeek-R1-0528-Qwen3-8B is also supported.
GGUFs: huggingface.co/unsloth/Deep...

May 30, 2025 at 8:35 PM
You can now run DeepSeek-R1-0528 locally with our Dynamic 1-bit GGUFs! 🐋
We shrank the full 715GB model to just 168GB (-80% size).
We achieve optimal accuracy by selectively quantizing layers.
DeepSeek-R1-0528-Qwen3-8B is also supported.
GGUFs: huggingface.co/unsloth/Deep...
We shrank the full 715GB model to just 168GB (-80% size).
We achieve optimal accuracy by selectively quantizing layers.
DeepSeek-R1-0528-Qwen3-8B is also supported.
GGUFs: huggingface.co/unsloth/Deep...
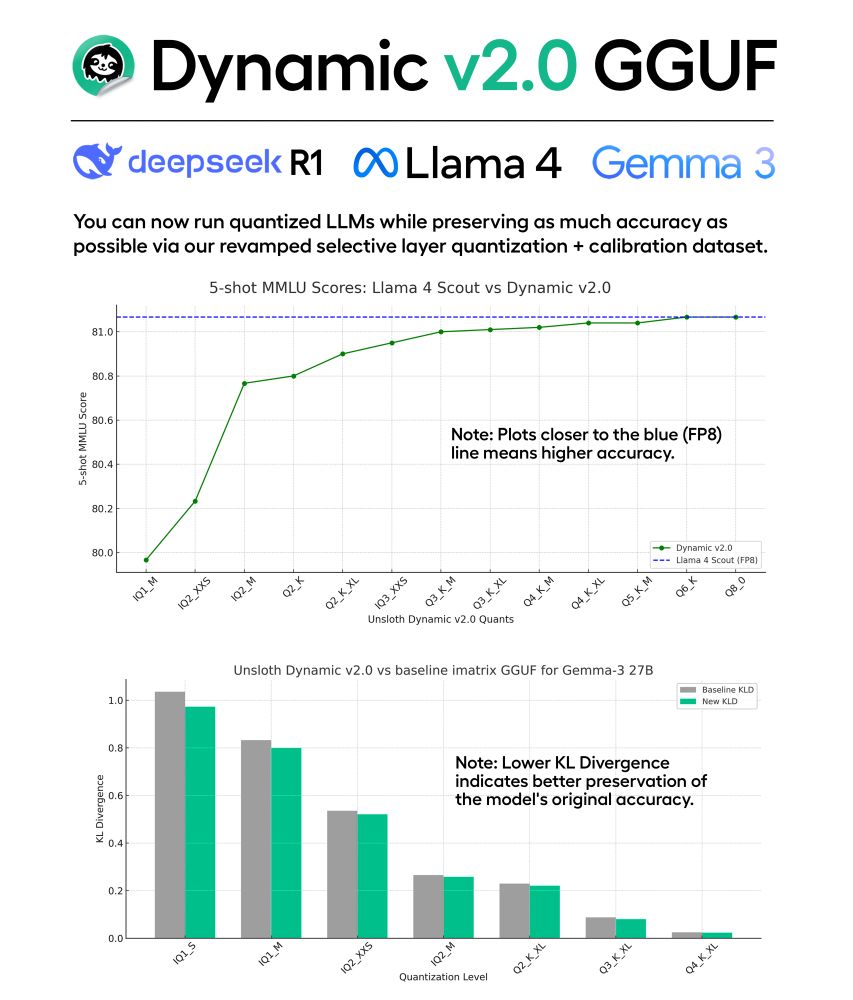
Introducing Unsloth Dynamic v2.0 GGUFs!
v2.0 sets new benchmarks on 5-shot MMLU + KL Divergence. So, you can now run quantized LLMs with minimal accuracy loss.
For benchmarks, we built an evaluation framework to match official MMLU scores of Llama 4 & Gemma 3
Blog: docs.unsloth.ai/basics/dynam...
v2.0 sets new benchmarks on 5-shot MMLU + KL Divergence. So, you can now run quantized LLMs with minimal accuracy loss.
For benchmarks, we built an evaluation framework to match official MMLU scores of Llama 4 & Gemma 3
Blog: docs.unsloth.ai/basics/dynam...
April 24, 2025 at 7:12 PM
Introducing Unsloth Dynamic v2.0 GGUFs!
v2.0 sets new benchmarks on 5-shot MMLU + KL Divergence. So, you can now run quantized LLMs with minimal accuracy loss.
For benchmarks, we built an evaluation framework to match official MMLU scores of Llama 4 & Gemma 3
Blog: docs.unsloth.ai/basics/dynam...
v2.0 sets new benchmarks on 5-shot MMLU + KL Divergence. So, you can now run quantized LLMs with minimal accuracy loss.
For benchmarks, we built an evaluation framework to match official MMLU scores of Llama 4 & Gemma 3
Blog: docs.unsloth.ai/basics/dynam...
You can now run Llama 4 on your local device! 🦙
We shrank Maverick (402B) from 400GB to 122GB (-70%).
Our Dynamic 1.78-bit iMatrix GGUFs ensures optimal accuracy & size by selectively quantizing layers.
Scout + Maverick GGUFs: huggingface.co/collections/...
Guide: docs.unsloth.ai/basics/tutor...
We shrank Maverick (402B) from 400GB to 122GB (-70%).
Our Dynamic 1.78-bit iMatrix GGUFs ensures optimal accuracy & size by selectively quantizing layers.
Scout + Maverick GGUFs: huggingface.co/collections/...
Guide: docs.unsloth.ai/basics/tutor...

April 8, 2025 at 8:39 PM
You can now run Llama 4 on your local device! 🦙
We shrank Maverick (402B) from 400GB to 122GB (-70%).
Our Dynamic 1.78-bit iMatrix GGUFs ensures optimal accuracy & size by selectively quantizing layers.
Scout + Maverick GGUFs: huggingface.co/collections/...
Guide: docs.unsloth.ai/basics/tutor...
We shrank Maverick (402B) from 400GB to 122GB (-70%).
Our Dynamic 1.78-bit iMatrix GGUFs ensures optimal accuracy & size by selectively quantizing layers.
Scout + Maverick GGUFs: huggingface.co/collections/...
Guide: docs.unsloth.ai/basics/tutor...
We teamed up with 🤗Hugging Face to release a free notebook for fine-tuning Gemma 3 with GRPO
Learn to:
• Enable reasoning in Gemma 3 (1B)
• Prepare/understand reward functions
• Make GRPO work for tiny LLMs
Notebook: colab.research.google.com/github/unslo...
Details: huggingface.co/reasoning-co...
Learn to:
• Enable reasoning in Gemma 3 (1B)
• Prepare/understand reward functions
• Make GRPO work for tiny LLMs
Notebook: colab.research.google.com/github/unslo...
Details: huggingface.co/reasoning-co...
March 19, 2025 at 4:31 PM
We teamed up with 🤗Hugging Face to release a free notebook for fine-tuning Gemma 3 with GRPO
Learn to:
• Enable reasoning in Gemma 3 (1B)
• Prepare/understand reward functions
• Make GRPO work for tiny LLMs
Notebook: colab.research.google.com/github/unslo...
Details: huggingface.co/reasoning-co...
Learn to:
• Enable reasoning in Gemma 3 (1B)
• Prepare/understand reward functions
• Make GRPO work for tiny LLMs
Notebook: colab.research.google.com/github/unslo...
Details: huggingface.co/reasoning-co...
We made a Guide to teach you how to Fine-tune LLMs correctly!
Learn about:
• Choosing the right parameters & training method
• RL, GRPO, DPO, CPT
• Data prep, Overfitting, Evaluation
• Training with Unsloth & deploy on vLLM, Ollama, Open WebUI
🔗https://docs.unsloth.ai/get-started/fine-tuning-guide
Learn about:
• Choosing the right parameters & training method
• RL, GRPO, DPO, CPT
• Data prep, Overfitting, Evaluation
• Training with Unsloth & deploy on vLLM, Ollama, Open WebUI
🔗https://docs.unsloth.ai/get-started/fine-tuning-guide

March 10, 2025 at 4:30 PM
We made a Guide to teach you how to Fine-tune LLMs correctly!
Learn about:
• Choosing the right parameters & training method
• RL, GRPO, DPO, CPT
• Data prep, Overfitting, Evaluation
• Training with Unsloth & deploy on vLLM, Ollama, Open WebUI
🔗https://docs.unsloth.ai/get-started/fine-tuning-guide
Learn about:
• Choosing the right parameters & training method
• RL, GRPO, DPO, CPT
• Data prep, Overfitting, Evaluation
• Training with Unsloth & deploy on vLLM, Ollama, Open WebUI
🔗https://docs.unsloth.ai/get-started/fine-tuning-guide
Tutorial: Train your own Reasoning LLM for free!
Make Llama 3.1 (8B) have chain-of-thought with DeepSeek's GRPO algorithm. Unsloth enables 90% less VRAM use.
Learn about:
• Reward Functions + dataset prep
• Training on free Colab GPUs
• Running + Evaluating
Guide: docs.unsloth.ai/basics/reaso...
Make Llama 3.1 (8B) have chain-of-thought with DeepSeek's GRPO algorithm. Unsloth enables 90% less VRAM use.
Learn about:
• Reward Functions + dataset prep
• Training on free Colab GPUs
• Running + Evaluating
Guide: docs.unsloth.ai/basics/reaso...

February 25, 2025 at 6:32 PM
Tutorial: Train your own Reasoning LLM for free!
Make Llama 3.1 (8B) have chain-of-thought with DeepSeek's GRPO algorithm. Unsloth enables 90% less VRAM use.
Learn about:
• Reward Functions + dataset prep
• Training on free Colab GPUs
• Running + Evaluating
Guide: docs.unsloth.ai/basics/reaso...
Make Llama 3.1 (8B) have chain-of-thought with DeepSeek's GRPO algorithm. Unsloth enables 90% less VRAM use.
Learn about:
• Reward Functions + dataset prep
• Training on free Colab GPUs
• Running + Evaluating
Guide: docs.unsloth.ai/basics/reaso...
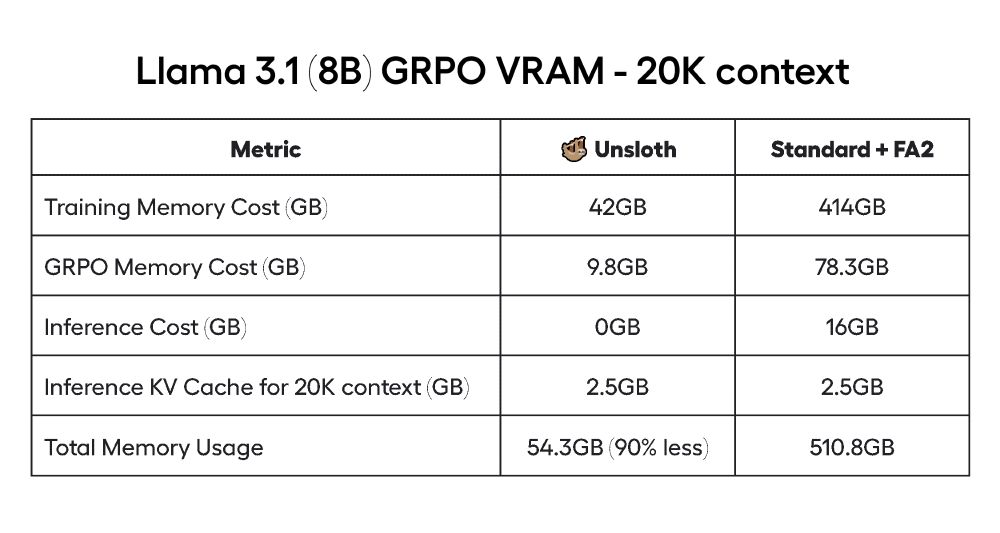
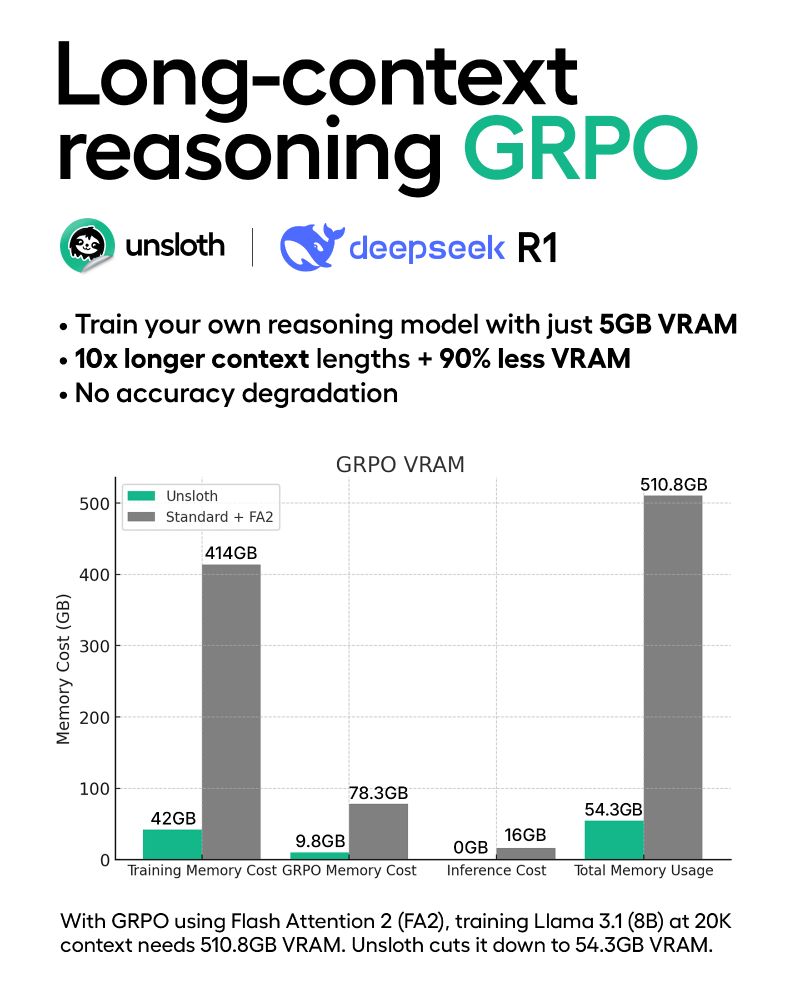
For our benchmarks, a standard GRPO QLoRA setup (TRL + FA2) for Llama 3.1 (8B) at 20K context required 510.8GB VRAM. Unsloth’s GRPO algorithms reduces this to just 54.3GB.
The 5GB VRAM requirement for Qwen2.5 (1.5B) is down from 7GB in our previous GRPO release two weeks ago!
The 5GB VRAM requirement for Qwen2.5 (1.5B) is down from 7GB in our previous GRPO release two weeks ago!
February 20, 2025 at 6:41 PM
For our benchmarks, a standard GRPO QLoRA setup (TRL + FA2) for Llama 3.1 (8B) at 20K context required 510.8GB VRAM. Unsloth’s GRPO algorithms reduces this to just 54.3GB.
The 5GB VRAM requirement for Qwen2.5 (1.5B) is down from 7GB in our previous GRPO release two weeks ago!
The 5GB VRAM requirement for Qwen2.5 (1.5B) is down from 7GB in our previous GRPO release two weeks ago!
Today, we’re launching new algorithms that enable 10x longer context lengths & 90% less VRAM for training Reasoning Models (GRPO).
Using Unsloth, you can now train your own reasoning model with just 5GB VRAM for Qwen2.5-1.5B with no accuracy loss.
Blog: unsloth.ai/blog/grpo
Using Unsloth, you can now train your own reasoning model with just 5GB VRAM for Qwen2.5-1.5B with no accuracy loss.
Blog: unsloth.ai/blog/grpo
February 20, 2025 at 6:41 PM
Today, we’re launching new algorithms that enable 10x longer context lengths & 90% less VRAM for training Reasoning Models (GRPO).
Using Unsloth, you can now train your own reasoning model with just 5GB VRAM for Qwen2.5-1.5B with no accuracy loss.
Blog: unsloth.ai/blog/grpo
Using Unsloth, you can now train your own reasoning model with just 5GB VRAM for Qwen2.5-1.5B with no accuracy loss.
Blog: unsloth.ai/blog/grpo
You can now reproduce DeepSeek-R1's reasoning on your own local device!
Experience the "Aha" moment with just 7GB VRAM.
Unsloth reduces GRPO training memory use by 80%.
15GB VRAM can transform Llama-3.1 (8B) & Phi-4 (14B) into reasoning models.
Blog: unsloth.ai/blog/r1-reas...
Experience the "Aha" moment with just 7GB VRAM.
Unsloth reduces GRPO training memory use by 80%.
15GB VRAM can transform Llama-3.1 (8B) & Phi-4 (14B) into reasoning models.
Blog: unsloth.ai/blog/r1-reas...

February 6, 2025 at 6:09 PM
You can now reproduce DeepSeek-R1's reasoning on your own local device!
Experience the "Aha" moment with just 7GB VRAM.
Unsloth reduces GRPO training memory use by 80%.
15GB VRAM can transform Llama-3.1 (8B) & Phi-4 (14B) into reasoning models.
Blog: unsloth.ai/blog/r1-reas...
Experience the "Aha" moment with just 7GB VRAM.
Unsloth reduces GRPO training memory use by 80%.
15GB VRAM can transform Llama-3.1 (8B) & Phi-4 (14B) into reasoning models.
Blog: unsloth.ai/blog/r1-reas...
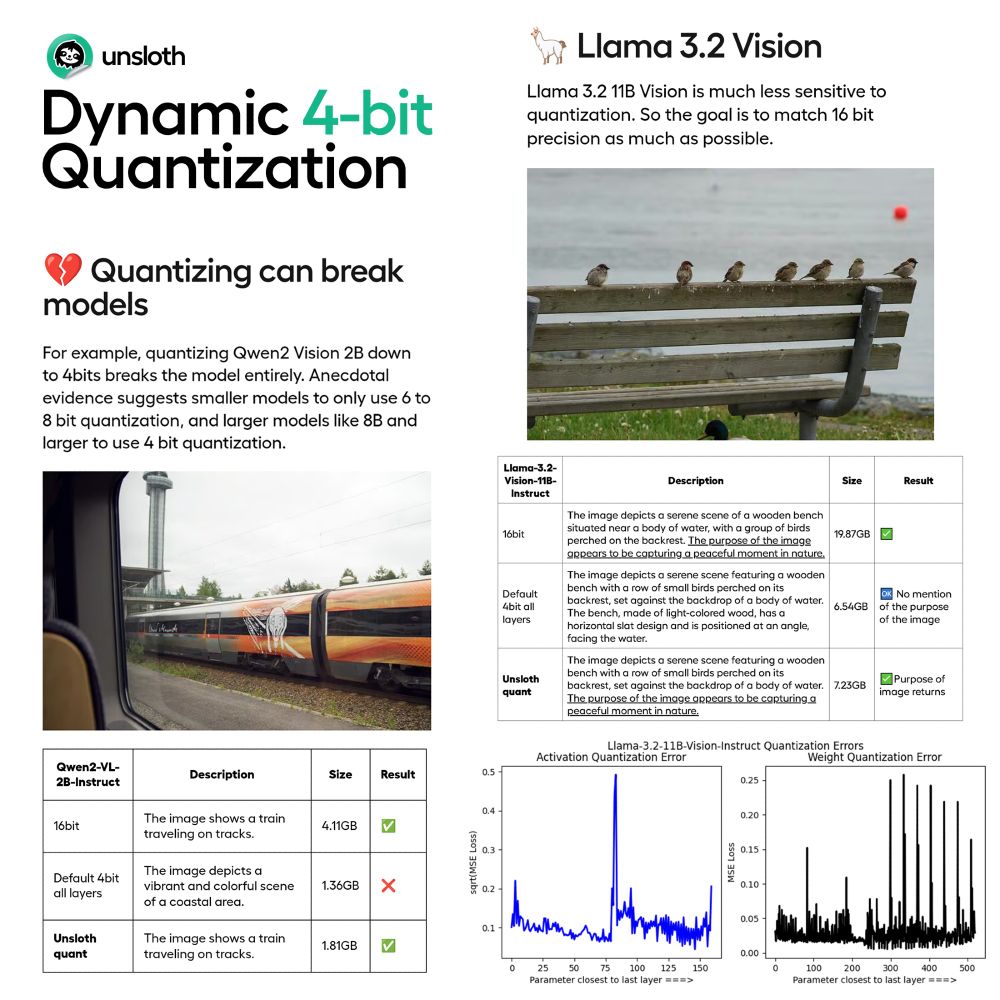
Introducing Unsloth Dynamic 4-bit Quantization!
Naive quantization often harms accuracy but we avoid quantizing certain parameters. This achieves higher accuracy using only <10% more VRAM than BnB 4bit
Read our Blog: unsloth.ai/blog/dynamic...
Quants on Hugging Face: huggingface.co/collections/...
Naive quantization often harms accuracy but we avoid quantizing certain parameters. This achieves higher accuracy using only <10% more VRAM than BnB 4bit
Read our Blog: unsloth.ai/blog/dynamic...
Quants on Hugging Face: huggingface.co/collections/...
December 4, 2024 at 7:51 PM
Introducing Unsloth Dynamic 4-bit Quantization!
Naive quantization often harms accuracy but we avoid quantizing certain parameters. This achieves higher accuracy using only <10% more VRAM than BnB 4bit
Read our Blog: unsloth.ai/blog/dynamic...
Quants on Hugging Face: huggingface.co/collections/...
Naive quantization often harms accuracy but we avoid quantizing certain parameters. This achieves higher accuracy using only <10% more VRAM than BnB 4bit
Read our Blog: unsloth.ai/blog/dynamic...
Quants on Hugging Face: huggingface.co/collections/...