



Thom Volker
@thomvolker.bsky.social
PhD Candidate in Statistics, Utrecht University
Creates fake data for a living.
thomvolker.github.io
Creates fake data for a living.
thomvolker.github.io

Anarchy!
(for a presentation, having to set "print = FALSE" all the time is annoying)
(for a presentation, having to set "print = FALSE" all the time is annoying)

November 5, 2025 at 4:10 PM
Anarchy!
(for a presentation, having to set "print = FALSE" all the time is annoying)
(for a presentation, having to set "print = FALSE" all the time is annoying)
“Have you thought about including…”
Sir, may I first introduce my team and myself?
Sir, may I first introduce my team and myself?

October 22, 2025 at 12:01 PM
“Have you thought about including…”
Sir, may I first introduce my team and myself?
Sir, may I first introduce my team and myself?

Elsevier, wtf is this supposed to mean?
September 30, 2025 at 8:02 AM
Elsevier, wtf is this supposed to mean?
The prediction intervals scale adaptively with the fraction of missing information, yielding wider intervals for cases with more severe missingness. The prediction intervals remain confidence valid, regardless of whether missingness occurs in train and/or test data (preprint on this coming up).

September 29, 2025 at 1:32 PM
The prediction intervals scale adaptively with the fraction of missing information, yielding wider intervals for cases with more severe missingness. The prediction intervals remain confidence valid, regardless of whether missingness occurs in train and/or test data (preprint on this coming up).
Cool stuff!
Florian van Leeuwen and I implemented a prediction function in the #mice package that allows the incorporation of missing data uncertainty in a prediction interval.
The `predict_mi()` function is available in the current development version: github.com/amices/mice
#Rstats #statsky
Florian van Leeuwen and I implemented a prediction function in the #mice package that allows the incorporation of missing data uncertainty in a prediction interval.
The `predict_mi()` function is available in the current development version: github.com/amices/mice
#Rstats #statsky
![Image of R code. To reproduce:
library(ggplot2)
library(dplyr)
library(mice, warn.conflicts = FALSE)
imp <- mice(nhanes, m = 5, maxit = 5, seed = 1,
ignore = rep(c(FALSE, TRUE), c(20, 5)),
print = FALSE)
impdats <- complete(imp, "all")
train <- lapply(impdats, function(dat) subset(dat, !imp$ignore))
test <- lapply(impdats, function(dat) subset(dat, imp$ignore))
fits <- lapply(train, function(dat) lm(age ~ bmi + hyp + chl, data = dat))
preds <- predict_mi(object = fits, newdata = test, pool = TRUE, interval = "prediction")
preds
preds %>%
as.data.frame() %>%
mutate(case = 1:nrow(preds),
y = test[[1]]$age) %>%
ggplot(aes(x = fit, y = case, col = rowSums(is.na(nhanes[imp$ignore,]))>0)) +
geom_point() +
geom_errorbar(aes(xmin = lwr, xmax = upr)) +
theme_minimal() +
scale_color_manual(values = mice::mdc(1:2), labels = c("observed", "missing")) +
theme(legend.title = element_blank(),
legend.position = "bottom") +
labs(x = "prediction",
title = "Pooled prediction intervals")](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:omgr6y6c62b4qar7fganjtdy/bafkreiesbac4qo25mh5rkegnw4ntcvbwedvpzqms4zn7xiothhzlgchxcm@jpeg)
September 29, 2025 at 1:32 PM
Cool stuff!
Florian van Leeuwen and I implemented a prediction function in the #mice package that allows the incorporation of missing data uncertainty in a prediction interval.
The `predict_mi()` function is available in the current development version: github.com/amices/mice
#Rstats #statsky
Florian van Leeuwen and I implemented a prediction function in the #mice package that allows the incorporation of missing data uncertainty in a prediction interval.
The `predict_mi()` function is available in the current development version: github.com/amices/mice
#Rstats #statsky
Had a blast cycling on Corse today!

September 9, 2025 at 7:48 PM
Had a blast cycling on Corse today!
Been working on a tutorial on synthetic data for open science for @lmu-osc.bsky.social
A draft version is now up: lmu-osc.github.io/synthetic-da...
It covers model building, evaluating synthetic data utility with density ratio estimation, and disclosure risk.
Feedback is very welcome!
A draft version is now up: lmu-osc.github.io/synthetic-da...
It covers model building, evaluating synthetic data utility with density ratio estimation, and disclosure risk.
Feedback is very welcome!

August 21, 2025 at 3:11 PM
Been working on a tutorial on synthetic data for open science for @lmu-osc.bsky.social
A draft version is now up: lmu-osc.github.io/synthetic-da...
It covers model building, evaluating synthetic data utility with density ratio estimation, and disclosure risk.
Feedback is very welcome!
A draft version is now up: lmu-osc.github.io/synthetic-da...
It covers model building, evaluating synthetic data utility with density ratio estimation, and disclosure risk.
Feedback is very welcome!

Never not thinking about this Tumblr post in this "AI for everything"-era
"... should I have a computer that eats my dinner and fucks my wife?"
"... should I have a computer that eats my dinner and fucks my wife?"
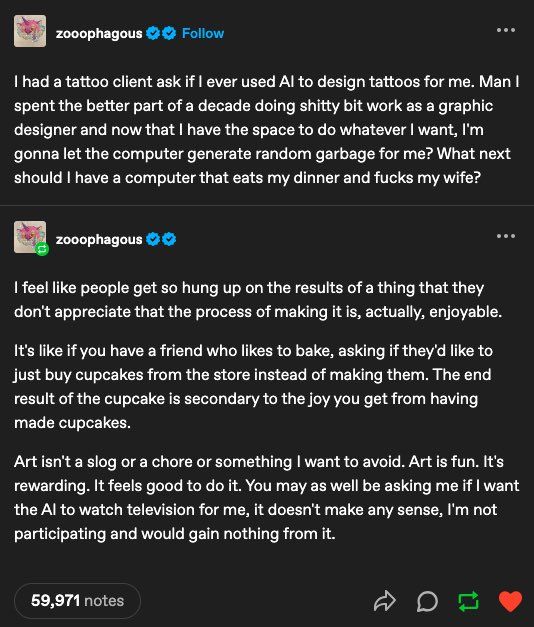
August 14, 2025 at 9:12 AM
Never not thinking about this Tumblr post in this "AI for everything"-era
"... should I have a computer that eats my dinner and fucks my wife?"
"... should I have a computer that eats my dinner and fucks my wife?"
It turns out that arrays are all you need.
![#Image with the following code:
params <- sapply( # stack predictions in array: 1st dim observations
predlist, # 2nd dim terms
function(pred) { # 3rd dim pred or var
array( # 4th dim imputations
c(as.matrix(pred$fit)[,seq_len(nterms)], pred$se.fit),
dim = c(n, nterms, 2)
)
}, simplify = "array"
)](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:omgr6y6c62b4qar7fganjtdy/bafkreiaptppzgatpxtdldmt5sghmousps2hxgxikzg6padazpnm65eeooq@jpeg)
August 9, 2025 at 8:07 AM
It turns out that arrays are all you need.
I'd say that adding this large constant effectively undoes the log-transformation but applies a linear transformation: log(y+a) ~ log a + y / k (k is some constant; assuming y is small relative to a). So, different scale but same fit. Basically @bbolker.bsky.social's 1st order Taylor approximation.
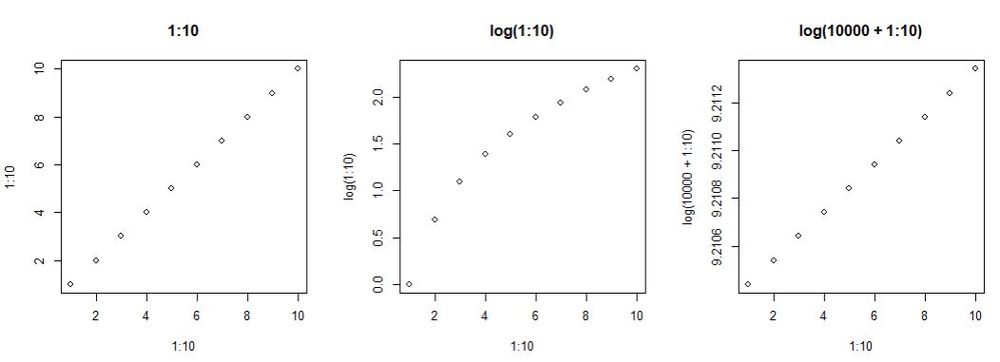
August 1, 2025 at 9:19 AM
I'd say that adding this large constant effectively undoes the log-transformation but applies a linear transformation: log(y+a) ~ log a + y / k (k is some constant; assuming y is small relative to a). So, different scale but same fit. Basically @bbolker.bsky.social's 1st order Taylor approximation.
Greetings from the Alps!

July 26, 2025 at 5:23 PM
Greetings from the Alps!
Best part of going to a conference is that you can append a trip to the Dolomites to it

July 24, 2025 at 5:47 PM
Best part of going to a conference is that you can append a trip to the Dolomites to it
Some time ago, generated synthetic data using GANs for some simple examples, to understand GANs a bit better. Turned out it's harder than I thought to tune these things appropriately. Anyway, I turned my struggles into a blog post that might interest some of you: thomvolker.github.io/blog/1407_ga...
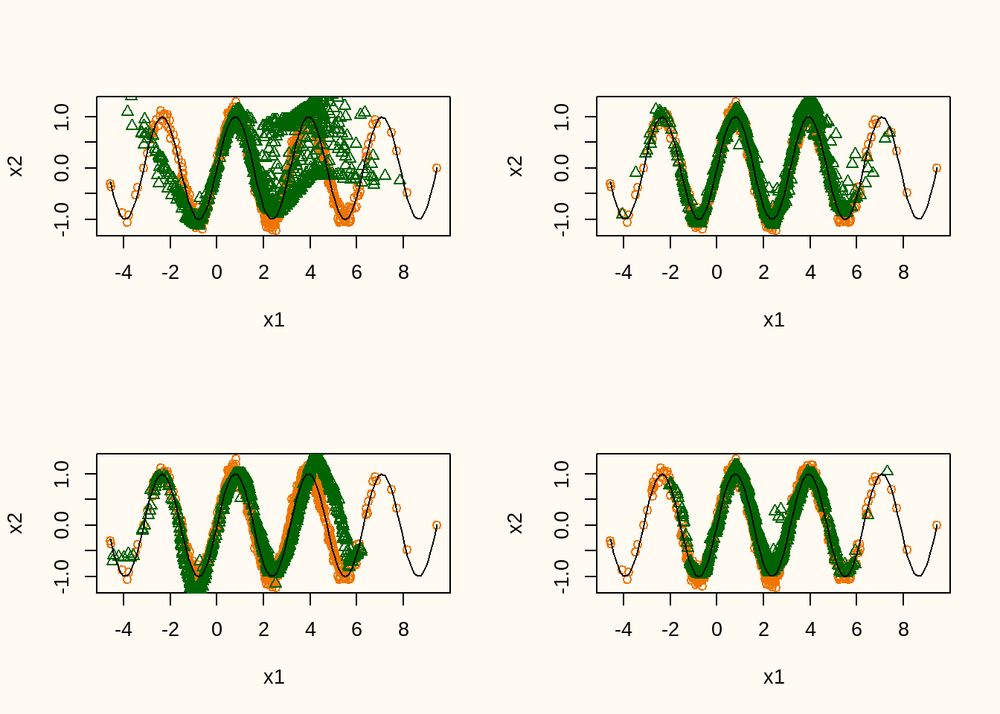
July 14, 2025 at 9:36 PM
Some time ago, generated synthetic data using GANs for some simple examples, to understand GANs a bit better. Turned out it's harder than I thought to tune these things appropriately. Anyway, I turned my struggles into a blog post that might interest some of you: thomvolker.github.io/blog/1407_ga...
Took me only one day to get convinced of positron. How cool is it that TODO's in quarto can be linked to Github issues in a single click!
*sorry for typos and weird text, there are TODO's here for a reason
*sorry for typos and weird text, there are TODO's here for a reason
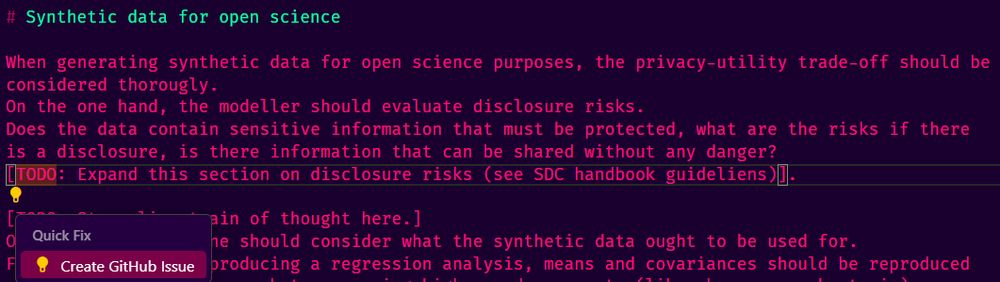
July 11, 2025 at 8:41 PM
Took me only one day to get convinced of positron. How cool is it that TODO's in quarto can be linked to Github issues in a single click!
*sorry for typos and weird text, there are TODO's here for a reason
*sorry for typos and weird text, there are TODO's here for a reason
I'm beginning to doubt training grok on a mixture of 4chan and Elon tweets was a good idea.

July 9, 2025 at 6:32 AM
I'm beginning to doubt training grok on a mixture of 4chan and Elon tweets was a good idea.
I cannot be convinced there exists a better title than "ItJustAintDopeToDropTheSlope.pdf" (which is how the .pdf on OSF is called).

July 8, 2025 at 7:00 AM
I cannot be convinced there exists a better title than "ItJustAintDopeToDropTheSlope.pdf" (which is how the .pdf on OSF is called).
My university mailbox moves them straight to the spam folder:
July 4, 2025 at 6:47 AM
My university mailbox moves them straight to the spam folder:
This more than ever

July 1, 2025 at 10:32 PM
This more than ever

MICE is also not supposed to work in this case:
From the "Flexible Imputation with Missing Data" book by Stef van Buuren (section 2.7 "When not to use multiple imputation")
From the "Flexible Imputation with Missing Data" book by Stef van Buuren (section 2.7 "When not to use multiple imputation")

June 26, 2025 at 11:28 AM
MICE is also not supposed to work in this case:
From the "Flexible Imputation with Missing Data" book by Stef van Buuren (section 2.7 "When not to use multiple imputation")
From the "Flexible Imputation with Missing Data" book by Stef van Buuren (section 2.7 "When not to use multiple imputation")
After two weeks, I'm finally done!
In this post, I explain different approaches for solving linear regression in R: directly, using QR, singular value and Cholesky decompositions, and do some benchmarking for comparison with in-built approaches.
thomvolker.github.io/blog/2506_re...
In this post, I explain different approaches for solving linear regression in R: directly, using QR, singular value and Cholesky decompositions, and do some benchmarking for comparison with in-built approaches.
thomvolker.github.io/blog/2506_re...
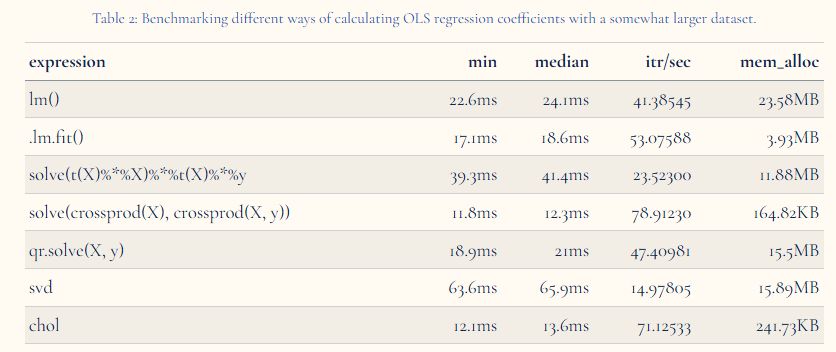
June 18, 2025 at 2:22 PM
After two weeks, I'm finally done!
In this post, I explain different approaches for solving linear regression in R: directly, using QR, singular value and Cholesky decompositions, and do some benchmarking for comparison with in-built approaches.
thomvolker.github.io/blog/2506_re...
In this post, I explain different approaches for solving linear regression in R: directly, using QR, singular value and Cholesky decompositions, and do some benchmarking for comparison with in-built approaches.
thomvolker.github.io/blog/2506_re...