



Declan Campbell
@thisisadax.bsky.social
Cognitive neuroscience. Deep learning. PhD Student at Princeton Neuroscience with @cocoscilab.bsky.social and Cohen Lab.
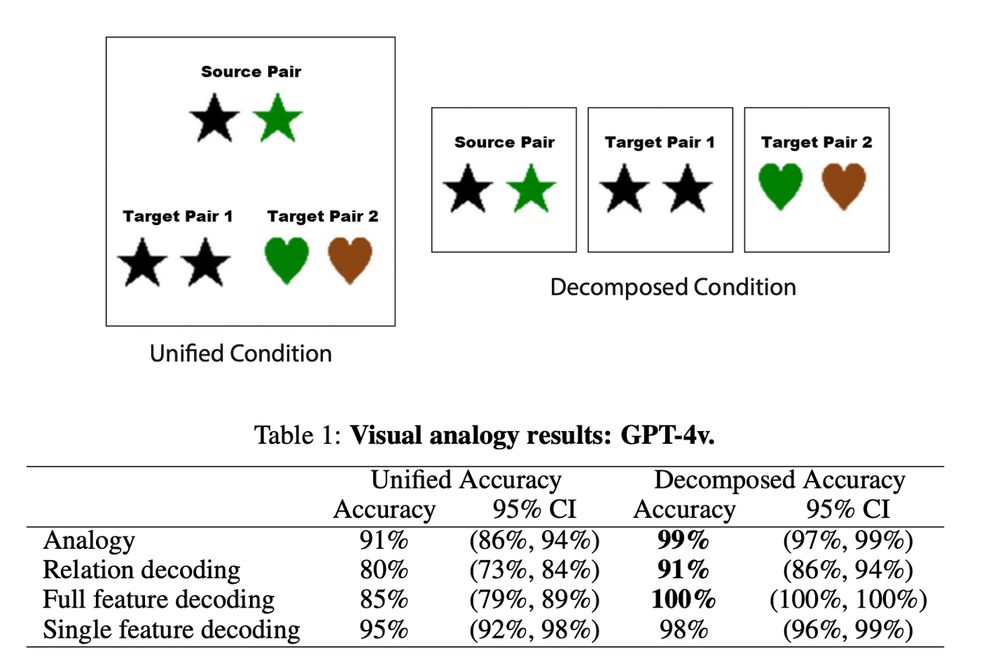
(6) Finally, we found that breaking 🪚🔨 visual analogy tasks into smaller chunks (i.e. performing object segmentation) to mitigate the influence of feature interference improves performance on those tasks.
November 15, 2024 at 3:09 AM
(6) Finally, we found that breaking 🪚🔨 visual analogy tasks into smaller chunks (i.e. performing object segmentation) to mitigate the influence of feature interference improves performance on those tasks.
(5) We developed a scene description benchmark inspired by visual working memory tasks to more directly evaluate how feature overlap affects performance. Key finding: Errors spike when objects share overlapping features - driven by 'illusory conjunctions' where features get mixed up!
November 15, 2024 at 3:09 AM
(5) We developed a scene description benchmark inspired by visual working memory tasks to more directly evaluate how feature overlap affects performance. Key finding: Errors spike when objects share overlapping features - driven by 'illusory conjunctions' where features get mixed up!
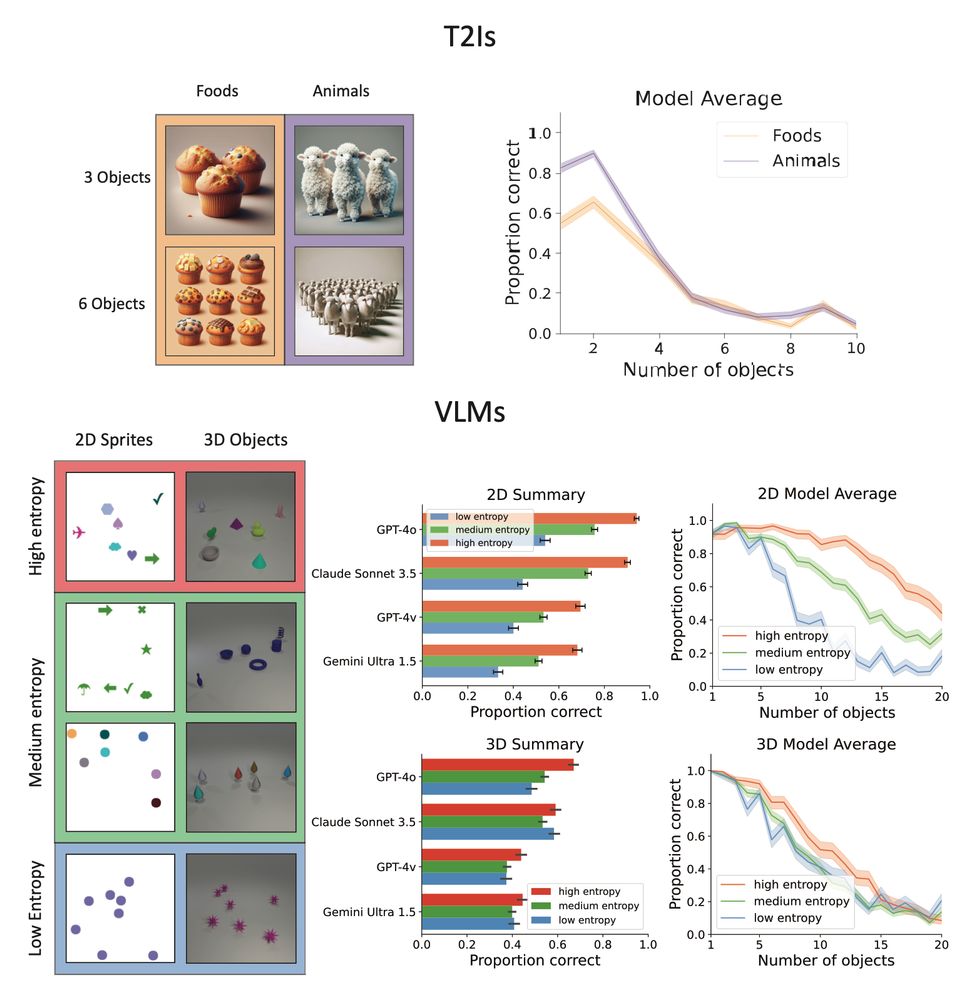
(4) Both multimodal LMs & text-to-image models show strict capacity limits - similar to human 'subitizing' limits during rapid parallel processing. Key finding: They improve with visually distinct objects, suggesting failures stem from feature interference.
November 15, 2024 at 3:09 AM
(4) Both multimodal LMs & text-to-image models show strict capacity limits - similar to human 'subitizing' limits during rapid parallel processing. Key finding: They improve with visually distinct objects, suggesting failures stem from feature interference.
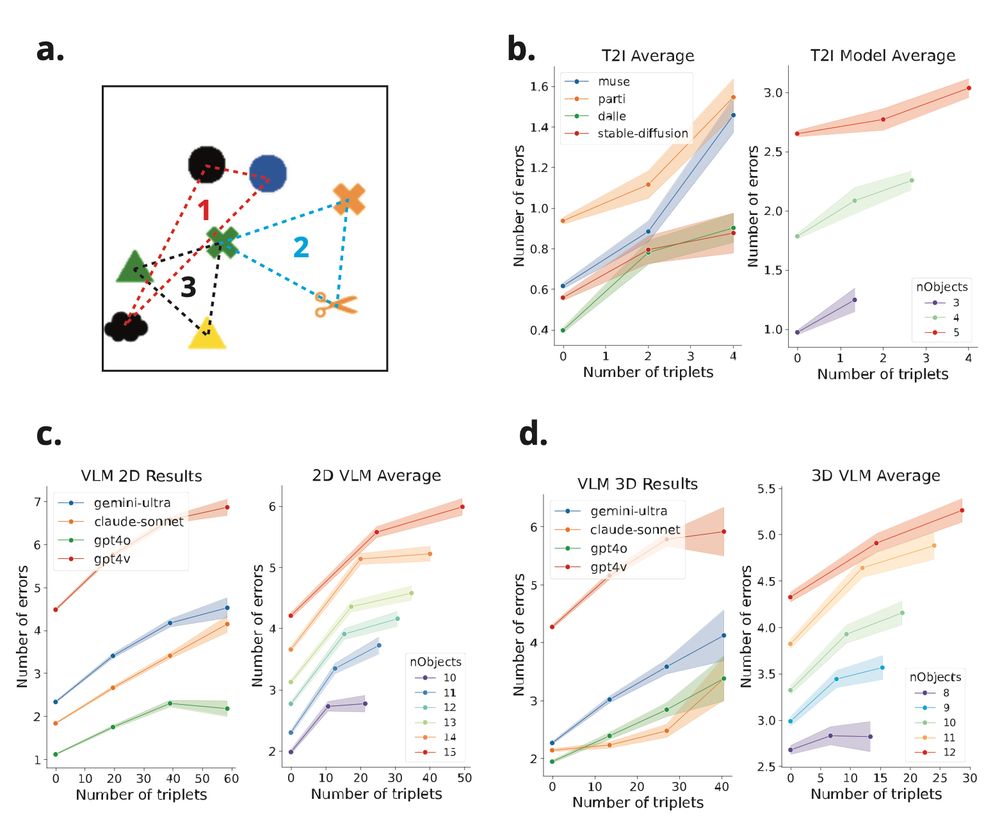
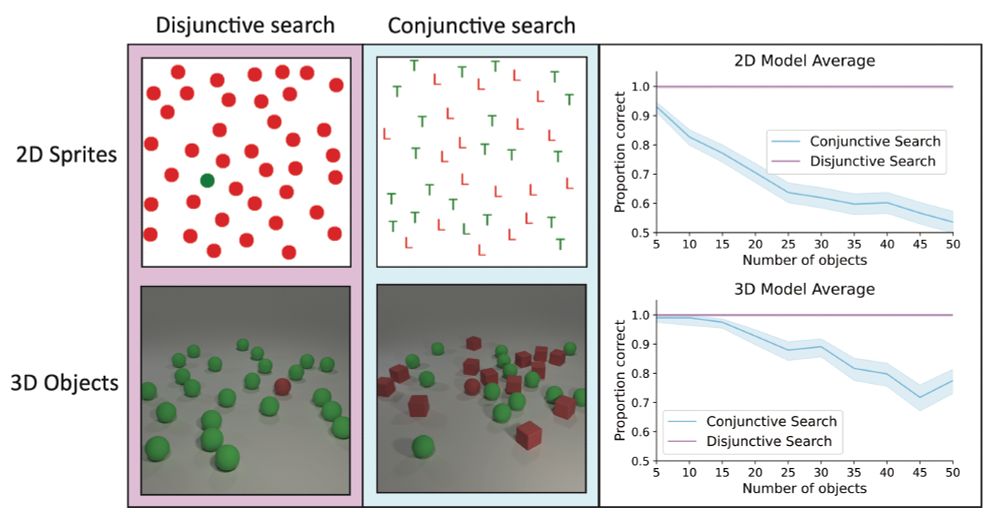
(3) To investigate this, we tested VLMs on classic visual search tasks. They excel at finding unique objects (e.g., one green shape among red shapes 🔴🟢🔴🔴). But searching for specific feature combinations? Performance drops substantially - similar to people when under time pressure.
November 15, 2024 at 3:09 AM
(3) To investigate this, we tested VLMs on classic visual search tasks. They excel at finding unique objects (e.g., one green shape among red shapes 🔴🟢🔴🔴). But searching for specific feature combinations? Performance drops substantially - similar to people when under time pressure.
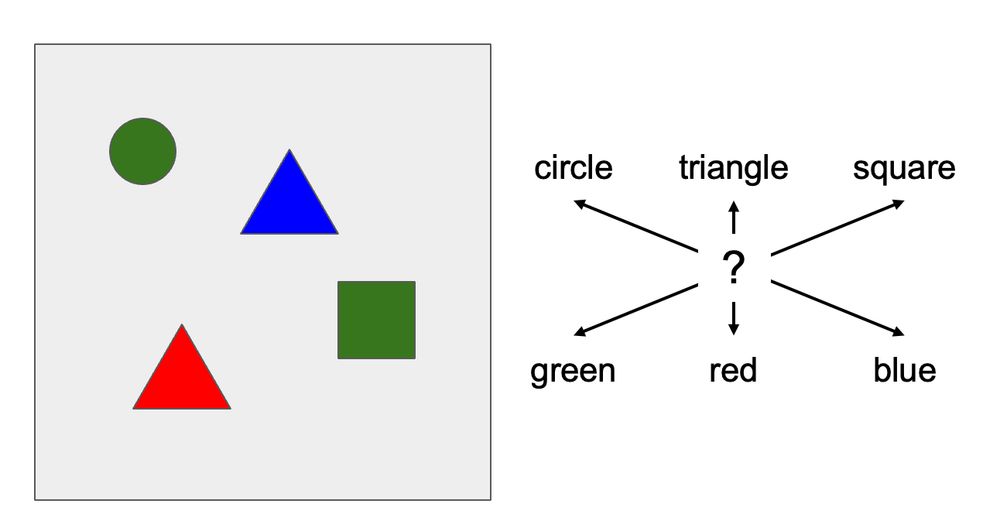
(2) The binding problem refers to difficulties in maintaining correct associations between features (like color & shape 🖍️⬛️) when representing multiple objects over the same representational substrate. These difficulties are a consequence of interference in parallel processing systems.
November 15, 2024 at 3:09 AM
(2) The binding problem refers to difficulties in maintaining correct associations between features (like color & shape 🖍️⬛️) when representing multiple objects over the same representational substrate. These difficulties are a consequence of interference in parallel processing systems.
(1) Vision language models can explain complex charts & decode memes, but struggle with simple tasks young kids find easy - like counting objects or finding items in cluttered scenes! Our 🆒🆕 #NeurIPS2024 paper shows why: they face the same 'binding problem' that constrains human vision! 🧵👇

November 15, 2024 at 3:09 AM
(1) Vision language models can explain complex charts & decode memes, but struggle with simple tasks young kids find easy - like counting objects or finding items in cluttered scenes! Our 🆒🆕 #NeurIPS2024 paper shows why: they face the same 'binding problem' that constrains human vision! 🧵👇