



Sonia Murthy
@soniakmurthy.bsky.social
cs phd student and kempner institute graduate fellow at harvard.
interested in language, cognition, and ai
soniamurthy.com
interested in language, cognition, and ai
soniamurthy.com
Thanks Hope! I just came across your related work with the CSS team at Microsoft- I'd love to chat about it sometime if you're free 🙂
February 11, 2025 at 11:20 PM
Thanks Hope! I just came across your related work with the CSS team at Microsoft- I'd love to chat about it sometime if you're free 🙂
Hi Daniel- thanks so much. The preprint is dependable, though missing a little additional discussion that made it into the camera-ready. I can email you the camera ready and will update arxiv with it shortly. Thank you!
February 11, 2025 at 11:13 PM
Hi Daniel- thanks so much. The preprint is dependable, though missing a little additional discussion that made it into the camera-ready. I can email you the camera ready and will update arxiv with it shortly. Thank you!
Many thanks to my collaborators and @kempnerinstitute.bsky.social for helping make this idea come to life, and to @rdhawkins.bsky.social for helping plant the seeds 🌱
February 10, 2025 at 5:20 PM
Many thanks to my collaborators and @kempnerinstitute.bsky.social for helping make this idea come to life, and to @rdhawkins.bsky.social for helping plant the seeds 🌱
(9/9) Code and data for our experiments can be found at: github.com/skmur/onefis...
Preprint: arxiv.org/abs/2411.04427
Also, check out our feature in the @kempnerinstitute.bsky.social Deeper Learning Blog! bit.ly/417WVDL
Preprint: arxiv.org/abs/2411.04427
Also, check out our feature in the @kempnerinstitute.bsky.social Deeper Learning Blog! bit.ly/417WVDL
GitHub - skmur/onefish-twofish: One fish, two fish, but not the whole sea: Alignment reduces language models' conceptual diversity (NAACL 2025)
One fish, two fish, but not the whole sea: Alignment reduces language models' conceptual diversity (NAACL 2025) - skmur/onefish-twofish
github.com
February 10, 2025 at 5:20 PM
(9/9) Code and data for our experiments can be found at: github.com/skmur/onefis...
Preprint: arxiv.org/abs/2411.04427
Also, check out our feature in the @kempnerinstitute.bsky.social Deeper Learning Blog! bit.ly/417WVDL
Preprint: arxiv.org/abs/2411.04427
Also, check out our feature in the @kempnerinstitute.bsky.social Deeper Learning Blog! bit.ly/417WVDL
(8/9) We think that better understanding such tradeoffs will be important to building LLMs that are aligned to human values– human values are diverse, our models should be too.
February 10, 2025 at 5:20 PM
(8/9) We think that better understanding such tradeoffs will be important to building LLMs that are aligned to human values– human values are diverse, our models should be too.
(7/9) This suggests a trade-off: increasing model safety in terms of value alignment decreases safety in terms of diversity of thoughts and opinion.
February 10, 2025 at 5:20 PM
(7/9) This suggests a trade-off: increasing model safety in terms of value alignment decreases safety in terms of diversity of thoughts and opinion.
(6/9) We put a suite of aligned models, and their instruction fine-tuned counterparts, to the test and found:
* no model reaches human-like diversity of thought.
* aligned models show LESS conceptual diversity than instruction fine-tuned counterparts
* no model reaches human-like diversity of thought.
* aligned models show LESS conceptual diversity than instruction fine-tuned counterparts
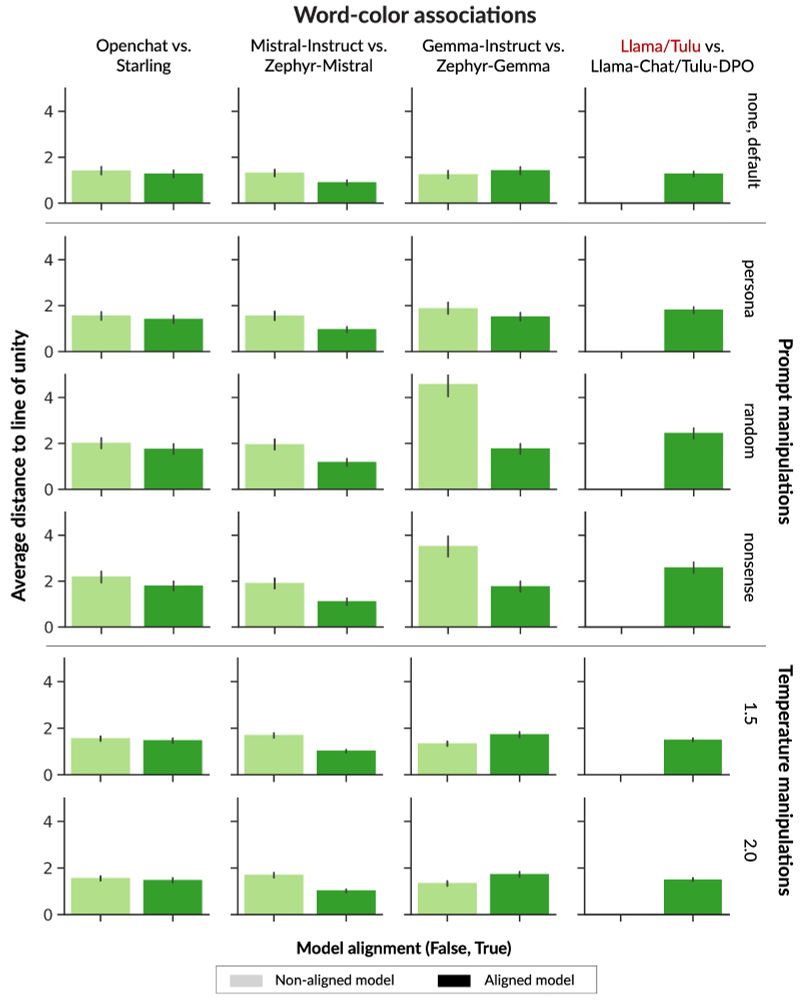
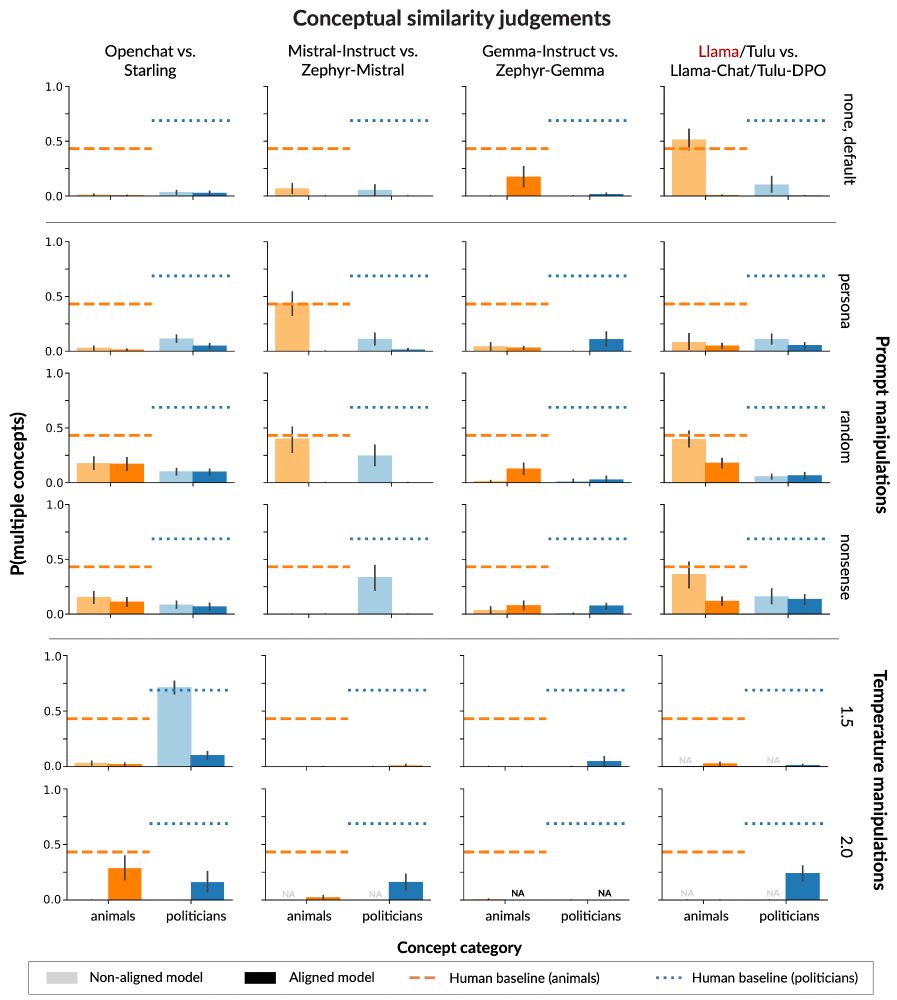
February 10, 2025 at 5:20 PM
(6/9) We put a suite of aligned models, and their instruction fine-tuned counterparts, to the test and found:
* no model reaches human-like diversity of thought.
* aligned models show LESS conceptual diversity than instruction fine-tuned counterparts
* no model reaches human-like diversity of thought.
* aligned models show LESS conceptual diversity than instruction fine-tuned counterparts
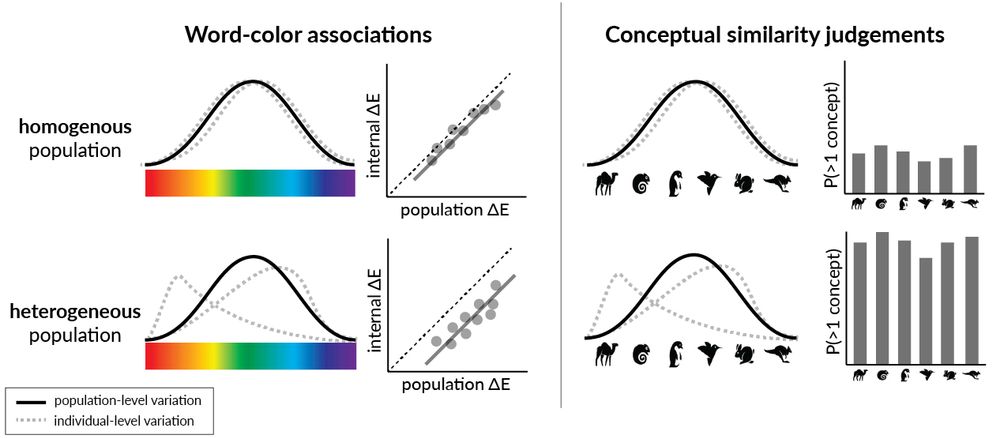
(5/9) Our experiments are inspired by human studies in two domains with rich behavioral data.
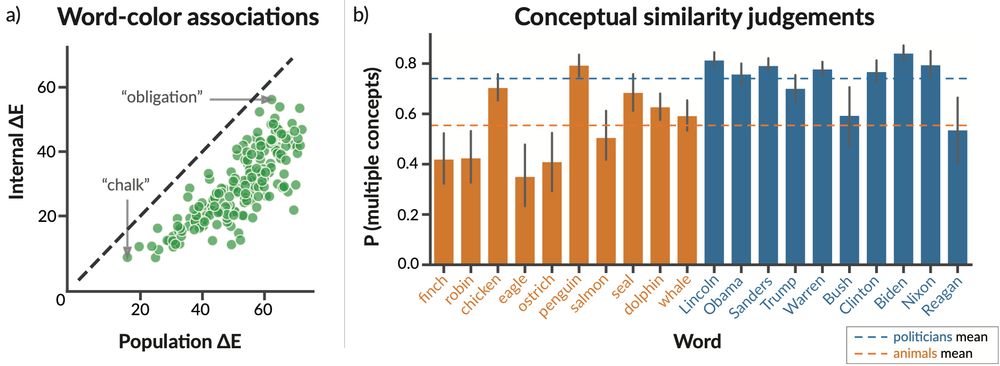
February 10, 2025 at 5:20 PM
(5/9) Our experiments are inspired by human studies in two domains with rich behavioral data.
(4/9) We introduce a new way of measuring the conceptual diversity of synthetically-generated LLM "populations" by considering how its “individuals’” variability relates to that of the population.
February 10, 2025 at 5:20 PM
(4/9) We introduce a new way of measuring the conceptual diversity of synthetically-generated LLM "populations" by considering how its “individuals’” variability relates to that of the population.
(3/9) One key issue is whether LLMs capture conceptual diversity: the variation among individuals’ representations of a particular domain. How do we measure this? And how does alignment affect this?
February 10, 2025 at 5:20 PM
(3/9) One key issue is whether LLMs capture conceptual diversity: the variation among individuals’ representations of a particular domain. How do we measure this? And how does alignment affect this?
(2/9) There's a lot of interest right now in getting LLMs to mimic the response distributions of “populations”--heterogeneous collections of individuals– for the purposes of political polling, opinion surveys, and behavioral research.
February 10, 2025 at 5:20 PM
(2/9) There's a lot of interest right now in getting LLMs to mimic the response distributions of “populations”--heterogeneous collections of individuals– for the purposes of political polling, opinion surveys, and behavioral research.