



Sebastian Loeschcke
@sloeschcke.bsky.social
Working on Efficient Training, Low-Rank Methods, and Quantization.
PhD at the University of Copenhagen 🇩🇰
Member of @belongielab.org, Danish Data Science Academy, and Pioneer Centre for AI 🤖
🔗 sebulo.github.io/
PhD at the University of Copenhagen 🇩🇰
Member of @belongielab.org, Danish Data Science Academy, and Pioneer Centre for AI 🤖
🔗 sebulo.github.io/
🇳🇱 𝗤𝘂𝗮𝗹𝗰𝗼𝗺𝗺 𝗔𝗜 𝗥𝗲𝘀𝗲𝗮𝗿𝗰𝗵 𝗜𝗻𝘁𝗲𝗿𝗻𝘀𝗵𝗶𝗽 🇳🇱
Excited to join @qualcomm.bsky.social in Amsterdam as a research intern in the Model Efficiency group, where I’ll be working on quantization and compression of machine learning models.
I’ll return to Copenhagen in December to start the final year of my PhD.
Excited to join @qualcomm.bsky.social in Amsterdam as a research intern in the Model Efficiency group, where I’ll be working on quantization and compression of machine learning models.
I’ll return to Copenhagen in December to start the final year of my PhD.

August 13, 2025 at 6:42 PM
🇳🇱 𝗤𝘂𝗮𝗹𝗰𝗼𝗺𝗺 𝗔𝗜 𝗥𝗲𝘀𝗲𝗮𝗿𝗰𝗵 𝗜𝗻𝘁𝗲𝗿𝗻𝘀𝗵𝗶𝗽 🇳🇱
Excited to join @qualcomm.bsky.social in Amsterdam as a research intern in the Model Efficiency group, where I’ll be working on quantization and compression of machine learning models.
I’ll return to Copenhagen in December to start the final year of my PhD.
Excited to join @qualcomm.bsky.social in Amsterdam as a research intern in the Model Efficiency group, where I’ll be working on quantization and compression of machine learning models.
I’ll return to Copenhagen in December to start the final year of my PhD.
We also show strong results on other PDE benchmarks, including 𝐃𝐚𝐫𝐜𝐲 𝐟𝐥𝐨𝐰 and the 𝐁𝐮𝐫𝐠𝐞𝐫𝐬 equation, demonstrating TensorGRaD’s broad applicability across scientific domains.

June 3, 2025 at 3:17 AM
We also show strong results on other PDE benchmarks, including 𝐃𝐚𝐫𝐜𝐲 𝐟𝐥𝐨𝐰 and the 𝐁𝐮𝐫𝐠𝐞𝐫𝐬 equation, demonstrating TensorGRaD’s broad applicability across scientific domains.
We test TensorGRaD on large-scale Navier–Stokes at 1024×1024 resolution with Reynolds number 10e5, a highly turbulent setting. With mixed-precision and 75% optimizer state reduction, it 𝐦𝐚𝐭𝐜𝐡𝐞𝐬 𝐟𝐮𝐥𝐥-𝐩𝐫𝐞𝐜𝐢𝐬𝐢𝐨𝐧 𝐀𝐝𝐚𝐦 while cutting overall memory by up to 50%.

June 3, 2025 at 3:17 AM
We test TensorGRaD on large-scale Navier–Stokes at 1024×1024 resolution with Reynolds number 10e5, a highly turbulent setting. With mixed-precision and 75% optimizer state reduction, it 𝐦𝐚𝐭𝐜𝐡𝐞𝐬 𝐟𝐮𝐥𝐥-𝐩𝐫𝐞𝐜𝐢𝐬𝐢𝐨𝐧 𝐀𝐝𝐚𝐦 while cutting overall memory by up to 50%.
We also propose a 𝐦𝐢𝐱𝐞𝐝-𝐩𝐫𝐞𝐜𝐢𝐬𝐢𝐨𝐧 𝐭𝐫𝐚𝐢𝐧𝐢𝐧𝐠 strategy with weights, activations, and gradients in half precision and optimizer states in full precision, and empirically show that storing optimizer states in half precision hurts performance.

June 3, 2025 at 3:17 AM
We also propose a 𝐦𝐢𝐱𝐞𝐝-𝐩𝐫𝐞𝐜𝐢𝐬𝐢𝐨𝐧 𝐭𝐫𝐚𝐢𝐧𝐢𝐧𝐠 strategy with weights, activations, and gradients in half precision and optimizer states in full precision, and empirically show that storing optimizer states in half precision hurts performance.
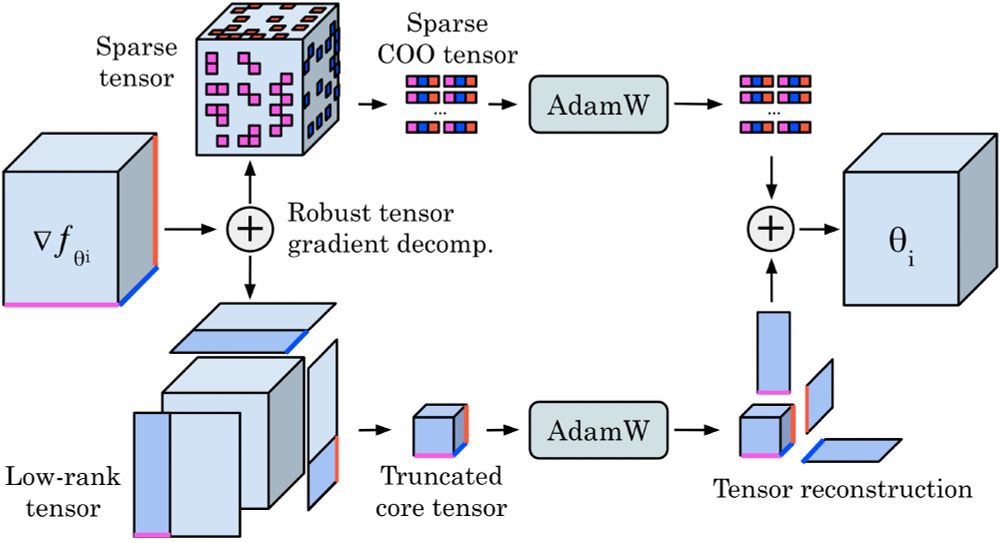
We extend low-rank and sparse methods to tensors via a 𝐫𝐨𝐛𝐮𝐬𝐭 𝐭𝐞𝐧𝐬𝐨𝐫 𝐝𝐞𝐜𝐨𝐦𝐩𝐨𝐬𝐢𝐭𝐢𝐨𝐧 that splits gradients into a low-rank Tucker part and an unstructured sparse tensor. Unlike matricized approaches, we prove our tensor-based method converges.

June 3, 2025 at 3:17 AM
We extend low-rank and sparse methods to tensors via a 𝐫𝐨𝐛𝐮𝐬𝐭 𝐭𝐞𝐧𝐬𝐨𝐫 𝐝𝐞𝐜𝐨𝐦𝐩𝐨𝐬𝐢𝐭𝐢𝐨𝐧 that splits gradients into a low-rank Tucker part and an unstructured sparse tensor. Unlike matricized approaches, we prove our tensor-based method converges.
Recent methods reduce optimizer memory for matrix weights. This includes Low-rank and sparse methods from LLMs that work on matrices. But to use them for Neural Operators, we’d need to flatten tensors, which destroys their spatial/temporal structure and hurts performance.

June 3, 2025 at 3:17 AM
Recent methods reduce optimizer memory for matrix weights. This includes Low-rank and sparse methods from LLMs that work on matrices. But to use them for Neural Operators, we’d need to flatten tensors, which destroys their spatial/temporal structure and hurts performance.
These Neural Operators use tensor weights. However, optimizers like Adam store two full tensors per weight, making memory the bottleneck at scale.
TensorGRaD reduces this overhead by up to 75% (𝑑𝑎𝑟𝑘 𝑔𝑟𝑒𝑒𝑛 𝑏𝑎𝑟𝑠), without hurting accuracy.
TensorGRaD reduces this overhead by up to 75% (𝑑𝑎𝑟𝑘 𝑔𝑟𝑒𝑒𝑛 𝑏𝑎𝑟𝑠), without hurting accuracy.

June 3, 2025 at 3:17 AM
These Neural Operators use tensor weights. However, optimizers like Adam store two full tensors per weight, making memory the bottleneck at scale.
TensorGRaD reduces this overhead by up to 75% (𝑑𝑎𝑟𝑘 𝑔𝑟𝑒𝑒𝑛 𝑏𝑎𝑟𝑠), without hurting accuracy.
TensorGRaD reduces this overhead by up to 75% (𝑑𝑎𝑟𝑘 𝑔𝑟𝑒𝑒𝑛 𝑏𝑎𝑟𝑠), without hurting accuracy.
Scientific computing operates on multiscale, multidimensional (𝐭𝐞𝐧𝐬𝐨𝐫) 𝐝𝐚𝐭𝐚. In weather forecasting, for example, inputs span space, time, and variables. Neural operators can capture these multiscale phenomena by learning an operator that maps between function spaces.

June 3, 2025 at 3:17 AM
Scientific computing operates on multiscale, multidimensional (𝐭𝐞𝐧𝐬𝐨𝐫) 𝐝𝐚𝐭𝐚. In weather forecasting, for example, inputs span space, time, and variables. Neural operators can capture these multiscale phenomena by learning an operator that maps between function spaces.
Check out our new preprint 𝐓𝐞𝐧𝐬𝐨𝐫𝐆𝐑𝐚𝐃.
We use a robust decomposition of the gradient tensors into low-rank + sparse parts to reduce optimizer memory for Neural Operators by up to 𝟕𝟓%, while matching the performance of Adam, even on turbulent Navier–Stokes (Re 10e5).
We use a robust decomposition of the gradient tensors into low-rank + sparse parts to reduce optimizer memory for Neural Operators by up to 𝟕𝟓%, while matching the performance of Adam, even on turbulent Navier–Stokes (Re 10e5).
June 3, 2025 at 3:17 AM
Check out our new preprint 𝐓𝐞𝐧𝐬𝐨𝐫𝐆𝐑𝐚𝐃.
We use a robust decomposition of the gradient tensors into low-rank + sparse parts to reduce optimizer memory for Neural Operators by up to 𝟕𝟓%, while matching the performance of Adam, even on turbulent Navier–Stokes (Re 10e5).
We use a robust decomposition of the gradient tensors into low-rank + sparse parts to reduce optimizer memory for Neural Operators by up to 𝟕𝟓%, while matching the performance of Adam, even on turbulent Navier–Stokes (Re 10e5).
Visited the beautiful UC Santa Barbara yesterday.


March 8, 2025 at 5:41 PM
Visited the beautiful UC Santa Barbara yesterday.
☀️ Moved to Pasadena, California! ☀️
For the next five months, I’ll be a Visiting Student Researcher at Anima Anandkumar's group at Caltech, collaborating with her team and Jean Kossaifi from NVIDIA on Efficient Machine Learning and AI4Science.
For the next five months, I’ll be a Visiting Student Researcher at Anima Anandkumar's group at Caltech, collaborating with her team and Jean Kossaifi from NVIDIA on Efficient Machine Learning and AI4Science.

January 28, 2025 at 3:57 PM
☀️ Moved to Pasadena, California! ☀️
For the next five months, I’ll be a Visiting Student Researcher at Anima Anandkumar's group at Caltech, collaborating with her team and Jean Kossaifi from NVIDIA on Efficient Machine Learning and AI4Science.
For the next five months, I’ll be a Visiting Student Researcher at Anima Anandkumar's group at Caltech, collaborating with her team and Jean Kossaifi from NVIDIA on Efficient Machine Learning and AI4Science.
Come by our poster session tomorrow!
🗓️ West Ballroom A-D #6104
🕒 Thu, 12 Dec, 4:30 p.m. – 7:30 p.m. PST
@madstoftrup.bsky.social and I are presenting LoQT: Low-Rank Adapters for Quantized Pretraining: arxiv.org/abs/2405.16528
#Neurips2024
🗓️ West Ballroom A-D #6104
🕒 Thu, 12 Dec, 4:30 p.m. – 7:30 p.m. PST
@madstoftrup.bsky.social and I are presenting LoQT: Low-Rank Adapters for Quantized Pretraining: arxiv.org/abs/2405.16528
#Neurips2024

December 12, 2024 at 5:02 AM
Come by our poster session tomorrow!
🗓️ West Ballroom A-D #6104
🕒 Thu, 12 Dec, 4:30 p.m. – 7:30 p.m. PST
@madstoftrup.bsky.social and I are presenting LoQT: Low-Rank Adapters for Quantized Pretraining: arxiv.org/abs/2405.16528
#Neurips2024
🗓️ West Ballroom A-D #6104
🕒 Thu, 12 Dec, 4:30 p.m. – 7:30 p.m. PST
@madstoftrup.bsky.social and I are presenting LoQT: Low-Rank Adapters for Quantized Pretraining: arxiv.org/abs/2405.16528
#Neurips2024
Copenhagen University and Aarhus University meet-up in Vancouver 🇩🇰🇨🇦
#NeurIPS2024
#NeurIPS2024



December 11, 2024 at 7:27 AM
Copenhagen University and Aarhus University meet-up in Vancouver 🇩🇰🇨🇦
#NeurIPS2024
#NeurIPS2024
Pre-NeurIPS Poster Session in Copenhagen.
Thanks to the Pioneer Centre for AI and @ellis.eu for sponsoring.
@neuripsconf.bsky.social
#neurips2024
Thanks to the Pioneer Centre for AI and @ellis.eu for sponsoring.
@neuripsconf.bsky.social
#neurips2024


November 22, 2024 at 7:00 PM
Pre-NeurIPS Poster Session in Copenhagen.
Thanks to the Pioneer Centre for AI and @ellis.eu for sponsoring.
@neuripsconf.bsky.social
#neurips2024
Thanks to the Pioneer Centre for AI and @ellis.eu for sponsoring.
@neuripsconf.bsky.social
#neurips2024
LoQT will be presented at NeurIPS 2024! 🎉
This research was funded by @DataScienceDK, and @AiCentreDK and is a collaboration between @DIKU_Institut, @ITUkbh, and @csaudk
This research was funded by @DataScienceDK, and @AiCentreDK and is a collaboration between @DIKU_Institut, @ITUkbh, and @csaudk

November 18, 2024 at 9:29 AM
LoQT will be presented at NeurIPS 2024! 🎉
This research was funded by @DataScienceDK, and @AiCentreDK and is a collaboration between @DIKU_Institut, @ITUkbh, and @csaudk
This research was funded by @DataScienceDK, and @AiCentreDK and is a collaboration between @DIKU_Institut, @ITUkbh, and @csaudk
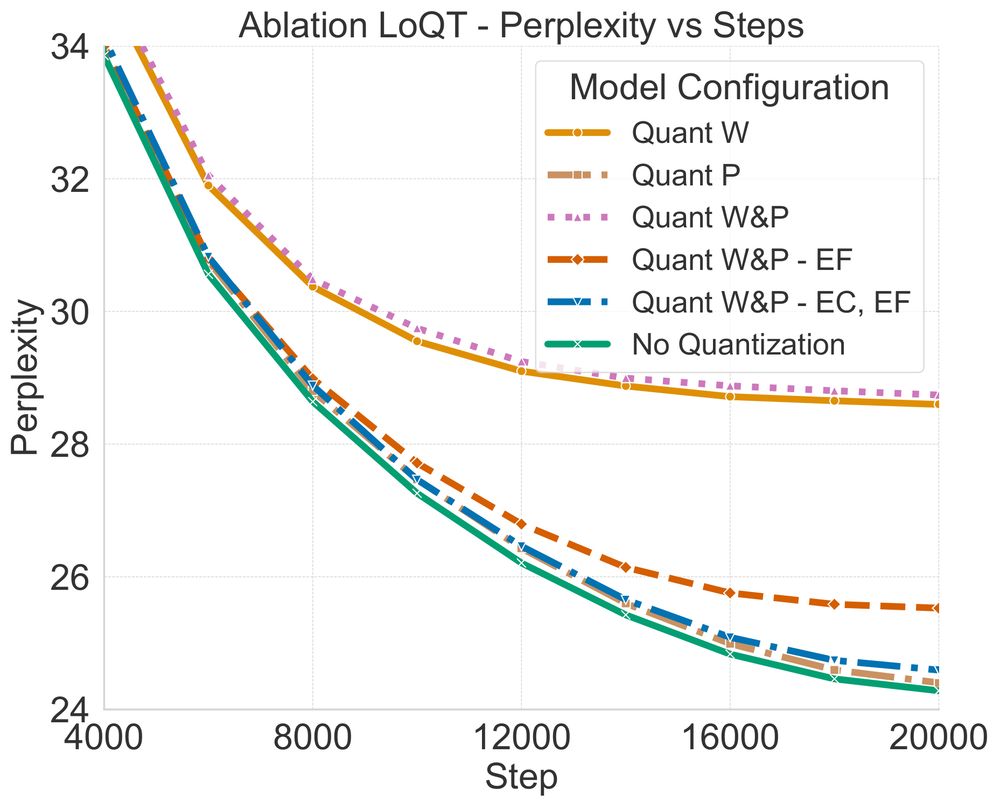
We periodically merge the low-rank adapters into the quantized model over exponentially increasing intervals. After each merge, we reinitialize the adapters and continue training.
We show LoQT works for both LLM pre-training and downstream task adaptation📊.
3/4
We show LoQT works for both LLM pre-training and downstream task adaptation📊.
3/4
November 18, 2024 at 9:29 AM
We periodically merge the low-rank adapters into the quantized model over exponentially increasing intervals. After each merge, we reinitialize the adapters and continue training.
We show LoQT works for both LLM pre-training and downstream task adaptation📊.
3/4
We show LoQT works for both LLM pre-training and downstream task adaptation📊.
3/4
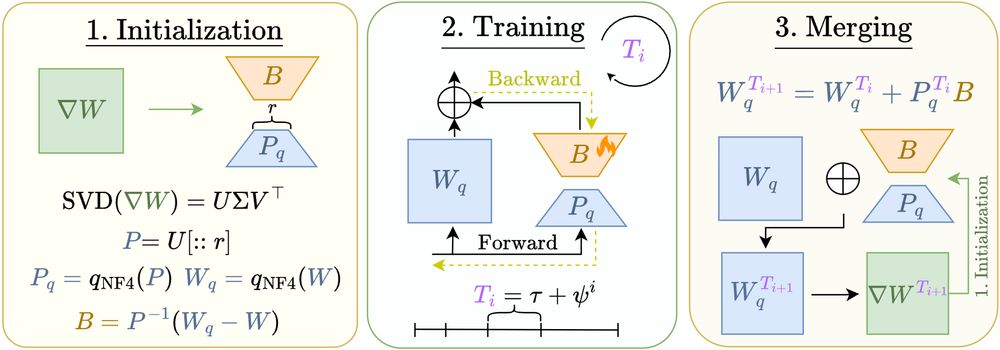
LoQT initializes low-rank adapters using the gradients of a base model. We then train a single adapter per layer, keeping the others frozen❄️ and quantized📉.
This reduces memory for gradients, optimizer states, and weights—even when pretraining from scratch.
2/4
This reduces memory for gradients, optimizer states, and weights—even when pretraining from scratch.
2/4
November 18, 2024 at 9:29 AM
LoQT initializes low-rank adapters using the gradients of a base model. We then train a single adapter per layer, keeping the others frozen❄️ and quantized📉.
This reduces memory for gradients, optimizer states, and weights—even when pretraining from scratch.
2/4
This reduces memory for gradients, optimizer states, and weights—even when pretraining from scratch.
2/4
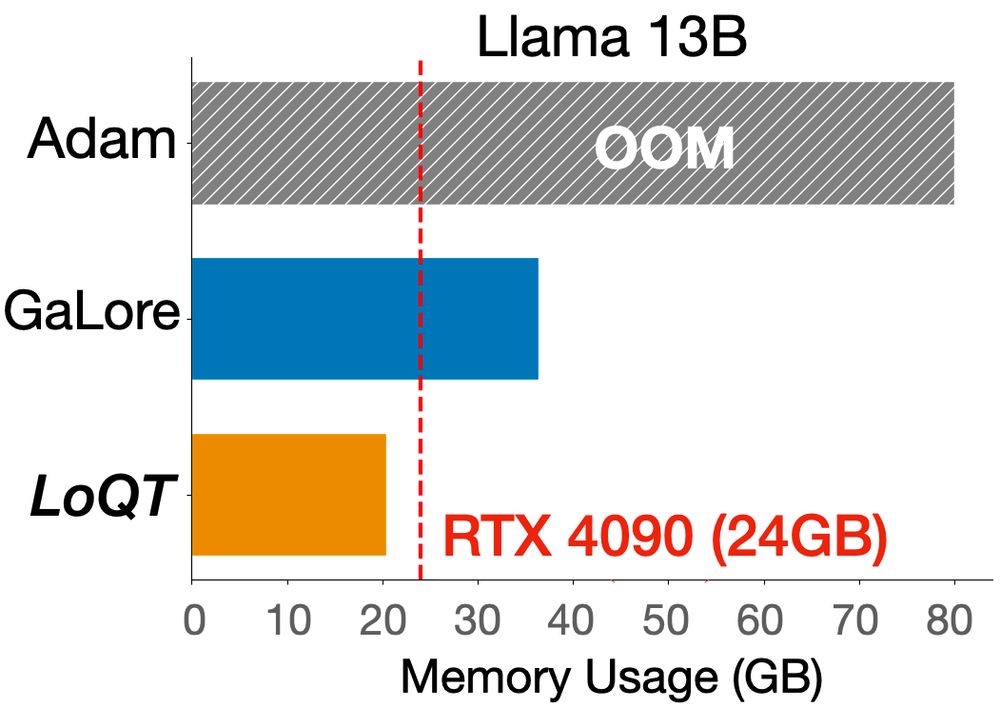
Ever wanted to train your own 13B Llama2 model from scratch on a 24GB GPU? Or fine-tune one without compromising performance compared to full training? 🦙
You now can, with LoQT: Low-Rank Adapters for Quantized Pretaining! arxiv.org/abs/2405.16528
1/4
You now can, with LoQT: Low-Rank Adapters for Quantized Pretaining! arxiv.org/abs/2405.16528
1/4
November 18, 2024 at 9:29 AM
Ever wanted to train your own 13B Llama2 model from scratch on a 24GB GPU? Or fine-tune one without compromising performance compared to full training? 🦙
You now can, with LoQT: Low-Rank Adapters for Quantized Pretaining! arxiv.org/abs/2405.16528
1/4
You now can, with LoQT: Low-Rank Adapters for Quantized Pretaining! arxiv.org/abs/2405.16528
1/4