




Roei Herzig
@roeiherz.bsky.social
Research Scientist @ IBM Research. Postdoc @ Berkeley AI. PhD @ Tel Aviv University. Working on Compositionality, Multimodal Foundation Models, and Structured Physical Intelligence.
🔗 https://roeiherz.github.io/
📍Bay area 🇺🇲
🔗 https://roeiherz.github.io/
📍Bay area 🇺🇲
We found that 4D representations maintain a shared geometric structure between the points and robot state representations up to a linear transformation, and thus enabling efficient transfer learning from human video data to low-level robotic control.

February 24, 2025 at 3:49 AM
We found that 4D representations maintain a shared geometric structure between the points and robot state representations up to a linear transformation, and thus enabling efficient transfer learning from human video data to low-level robotic control.
For example, VLAs use language decoders, which are pretrained on tasks like visual question answering and image captioning.
This presents a discrepancy between the models’ high-level pre-training objective and the need for robotic models to predict low-level actions.
This presents a discrepancy between the models’ high-level pre-training objective and the need for robotic models to predict low-level actions.
February 24, 2025 at 3:49 AM
For example, VLAs use language decoders, which are pretrained on tasks like visual question answering and image captioning.
This presents a discrepancy between the models’ high-level pre-training objective and the need for robotic models to predict low-level actions.
This presents a discrepancy between the models’ high-level pre-training objective and the need for robotic models to predict low-level actions.
Pretraining has significantly contributed to recent Foundational Model success. However, in robotics, progress has been limited due to a lack of robotic annotations and insufficient representations that accurately model the physical world.
February 24, 2025 at 3:49 AM
Pretraining has significantly contributed to recent Foundational Model success. However, in robotics, progress has been limited due to a lack of robotic annotations and insufficient representations that accurately model the physical world.
Our paper: arxiv.org/pdf/2502.13142.
Our project page and code will be released soon!
Team: \w Dantong Niu, Yuvan Sharma, Haoru Xue, Giscard Biamby, Junyi Zhang, Ziteng Ji, and Trevor Darrell.
Our project page and code will be released soon!
Team: \w Dantong Niu, Yuvan Sharma, Haoru Xue, Giscard Biamby, Junyi Zhang, Ziteng Ji, and Trevor Darrell.

February 24, 2025 at 3:49 AM
Our paper: arxiv.org/pdf/2502.13142.
Our project page and code will be released soon!
Team: \w Dantong Niu, Yuvan Sharma, Haoru Xue, Giscard Biamby, Junyi Zhang, Ziteng Ji, and Trevor Darrell.
Our project page and code will be released soon!
Team: \w Dantong Niu, Yuvan Sharma, Haoru Xue, Giscard Biamby, Junyi Zhang, Ziteng Ji, and Trevor Darrell.
Wow! This image so horrible and beautiful at the same time.
January 15, 2025 at 9:49 PM
Wow! This image so horrible and beautiful at the same time.
I wouldn't recommend deleting the old users on X and Facebook as this social network is still in a beta version.
January 8, 2025 at 9:32 PM
I wouldn't recommend deleting the old users on X and Facebook as this social network is still in a beta version.
The Star of David on the Christmas tree is quite hilarious :)
December 24, 2024 at 5:32 PM
The Star of David on the Christmas tree is quite hilarious :)
This fantastic work was done by the outstanding students, Brandon Huang, Chancharik Mitra and Tianning Chai, as well as Zhiqiu Lin, Assaf Arbelle, Rogerio Feris, Leonid Karlinsky.
I also want to special thanks the amazing Trevor Darrell and Deva Ramanan for their invaluable guidance.
I also want to special thanks the amazing Trevor Darrell and Deva Ramanan for their invaluable guidance.

December 4, 2024 at 9:24 PM
This fantastic work was done by the outstanding students, Brandon Huang, Chancharik Mitra and Tianning Chai, as well as Zhiqiu Lin, Assaf Arbelle, Rogerio Feris, Leonid Karlinsky.
I also want to special thanks the amazing Trevor Darrell and Deva Ramanan for their invaluable guidance.
I also want to special thanks the amazing Trevor Darrell and Deva Ramanan for their invaluable guidance.
Key-takeaways:
(1) Utilizing truly multimodal features (like those found in generative architectures)
(2) Demonstrating how generative LMMs can be used for discriminative VL tasks
(3) It is very convenient to have all the information in a small and different head for different VL tasks.
(1) Utilizing truly multimodal features (like those found in generative architectures)
(2) Demonstrating how generative LMMs can be used for discriminative VL tasks
(3) It is very convenient to have all the information in a small and different head for different VL tasks.
December 4, 2024 at 9:24 PM
Key-takeaways:
(1) Utilizing truly multimodal features (like those found in generative architectures)
(2) Demonstrating how generative LMMs can be used for discriminative VL tasks
(3) It is very convenient to have all the information in a small and different head for different VL tasks.
(1) Utilizing truly multimodal features (like those found in generative architectures)
(2) Demonstrating how generative LMMs can be used for discriminative VL tasks
(3) It is very convenient to have all the information in a small and different head for different VL tasks.
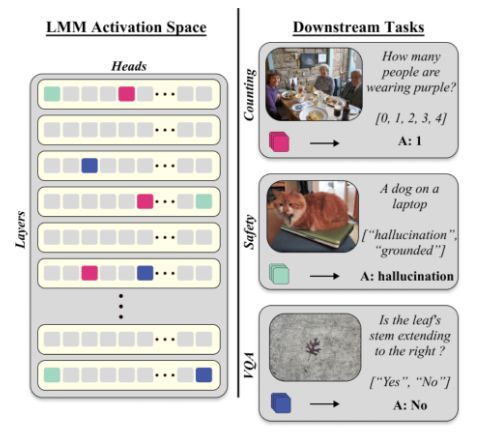
We tried several different tasks, such as Safety, Visual Question Answering (VQA), and Classification benchmarks.
The results suggest that SAVs are particularly useful even when compared to LoRA (where there are not a lot of samples to fine-tune the model).
The results suggest that SAVs are particularly useful even when compared to LoRA (where there are not a lot of samples to fine-tune the model).

December 4, 2024 at 9:24 PM
We tried several different tasks, such as Safety, Visual Question Answering (VQA), and Classification benchmarks.
The results suggest that SAVs are particularly useful even when compared to LoRA (where there are not a lot of samples to fine-tune the model).
The results suggest that SAVs are particularly useful even when compared to LoRA (where there are not a lot of samples to fine-tune the model).
What we did? ->
We propose an algorithm for finding small sets of attention heads (~20!) as multimodal features in Generative LMMs that can be used for discriminative VL tasks, outperforming encoder-only architectures (CLIP, SigLIP) without training.
We propose an algorithm for finding small sets of attention heads (~20!) as multimodal features in Generative LMMs that can be used for discriminative VL tasks, outperforming encoder-only architectures (CLIP, SigLIP) without training.
December 4, 2024 at 9:24 PM
What we did? ->
We propose an algorithm for finding small sets of attention heads (~20!) as multimodal features in Generative LMMs that can be used for discriminative VL tasks, outperforming encoder-only architectures (CLIP, SigLIP) without training.
We propose an algorithm for finding small sets of attention heads (~20!) as multimodal features in Generative LMMs that can be used for discriminative VL tasks, outperforming encoder-only architectures (CLIP, SigLIP) without training.
Motivation:
On the one hand, encoder-only architectures are great for discriminative VL tasks but lack multimodal features.
On the other hand, decoder-only architectures have a joint multimodal representation but are not suited for decoding tasks.
Can we enjoy both worlds? The answer is YES!
On the one hand, encoder-only architectures are great for discriminative VL tasks but lack multimodal features.
On the other hand, decoder-only architectures have a joint multimodal representation but are not suited for decoding tasks.
Can we enjoy both worlds? The answer is YES!
December 4, 2024 at 9:24 PM
Motivation:
On the one hand, encoder-only architectures are great for discriminative VL tasks but lack multimodal features.
On the other hand, decoder-only architectures have a joint multimodal representation but are not suited for decoding tasks.
Can we enjoy both worlds? The answer is YES!
On the one hand, encoder-only architectures are great for discriminative VL tasks but lack multimodal features.
On the other hand, decoder-only architectures have a joint multimodal representation but are not suited for decoding tasks.
Can we enjoy both worlds? The answer is YES!
I think for two main reasons. Firstly, ICL is an emergent property of LLMs/VLMs, not something they were pre-trained to do originally. Second, those VLMs that suffer from poor ICL are usually those who were instruction-tuned, while most pretrained VLMs (i.e., generative models) should still have it.
November 30, 2024 at 2:04 AM
I think for two main reasons. Firstly, ICL is an emergent property of LLMs/VLMs, not something they were pre-trained to do originally. Second, those VLMs that suffer from poor ICL are usually those who were instruction-tuned, while most pretrained VLMs (i.e., generative models) should still have it.
I took my two kids there last April, and I was amazed at how much they could climb even at a young age!
Also, I highly recommend visiting north of California (Mendocino, Fort Bragg, etc.) during this time of year!
Also, I highly recommend visiting north of California (Mendocino, Fort Bragg, etc.) during this time of year!
November 30, 2024 at 1:38 AM
I took my two kids there last April, and I was amazed at how much they could climb even at a young age!
Also, I highly recommend visiting north of California (Mendocino, Fort Bragg, etc.) during this time of year!
Also, I highly recommend visiting north of California (Mendocino, Fort Bragg, etc.) during this time of year!