




Roei Herzig
@roeiherz.bsky.social
Research Scientist @ IBM Research. Postdoc @ Berkeley AI. PhD @ Tel Aviv University. Working on Compositionality, Multimodal Foundation Models, and Structured Physical Intelligence.
🔗 https://roeiherz.github.io/
📍Bay area 🇺🇲
🔗 https://roeiherz.github.io/
📍Bay area 🇺🇲
We found that 4D representations maintain a shared geometric structure between the points and robot state representations up to a linear transformation, and thus enabling efficient transfer learning from human video data to low-level robotic control.

February 24, 2025 at 3:49 AM
We found that 4D representations maintain a shared geometric structure between the points and robot state representations up to a linear transformation, and thus enabling efficient transfer learning from human video data to low-level robotic control.
Our paper: arxiv.org/pdf/2502.13142.
Our project page and code will be released soon!
Team: \w Dantong Niu, Yuvan Sharma, Haoru Xue, Giscard Biamby, Junyi Zhang, Ziteng Ji, and Trevor Darrell.
Our project page and code will be released soon!
Team: \w Dantong Niu, Yuvan Sharma, Haoru Xue, Giscard Biamby, Junyi Zhang, Ziteng Ji, and Trevor Darrell.

February 24, 2025 at 3:49 AM
Our paper: arxiv.org/pdf/2502.13142.
Our project page and code will be released soon!
Team: \w Dantong Niu, Yuvan Sharma, Haoru Xue, Giscard Biamby, Junyi Zhang, Ziteng Ji, and Trevor Darrell.
Our project page and code will be released soon!
Team: \w Dantong Niu, Yuvan Sharma, Haoru Xue, Giscard Biamby, Junyi Zhang, Ziteng Ji, and Trevor Darrell.
What happens when vision🤝 robotics meet? 🚨 Happy to share our new work on Pretraining Robotic Foundational Models!🔥
ARM4R is an Autoregressive Robotic Model that leverages low-level 4D Representations learned from human video data to yield a better robotic model.
BerkeleyAI 😊
ARM4R is an Autoregressive Robotic Model that leverages low-level 4D Representations learned from human video data to yield a better robotic model.
BerkeleyAI 😊
February 24, 2025 at 3:49 AM
What happens when vision🤝 robotics meet? 🚨 Happy to share our new work on Pretraining Robotic Foundational Models!🔥
ARM4R is an Autoregressive Robotic Model that leverages low-level 4D Representations learned from human video data to yield a better robotic model.
BerkeleyAI 😊
ARM4R is an Autoregressive Robotic Model that leverages low-level 4D Representations learned from human video data to yield a better robotic model.
BerkeleyAI 😊
The best friend of Auto-regressive Robotic Models is 4D representations...🤖😻❤️
February 20, 2025 at 5:01 AM
The best friend of Auto-regressive Robotic Models is 4D representations...🤖😻❤️
For all our @neuripsconf.bsky.social friends🤖🦋, our work is presented NOW at POSTER #3701.
Come hear us talk our work on many-shot in-context learning and test-time scaling by leveraging the activations! You won't be disappointed😎
#Multimodal-InContextLearning #NeurIPS
Come hear us talk our work on many-shot in-context learning and test-time scaling by leveraging the activations! You won't be disappointed😎
#Multimodal-InContextLearning #NeurIPS

December 12, 2024 at 7:13 PM
For all our @neuripsconf.bsky.social friends🤖🦋, our work is presented NOW at POSTER #3701.
Come hear us talk our work on many-shot in-context learning and test-time scaling by leveraging the activations! You won't be disappointed😎
#Multimodal-InContextLearning #NeurIPS
Come hear us talk our work on many-shot in-context learning and test-time scaling by leveraging the activations! You won't be disappointed😎
#Multimodal-InContextLearning #NeurIPS
This fantastic work was done by the outstanding students, Brandon Huang, Chancharik Mitra and Tianning Chai, as well as Zhiqiu Lin, Assaf Arbelle, Rogerio Feris, Leonid Karlinsky.
I also want to special thanks the amazing Trevor Darrell and Deva Ramanan for their invaluable guidance.
I also want to special thanks the amazing Trevor Darrell and Deva Ramanan for their invaluable guidance.

December 4, 2024 at 9:24 PM
This fantastic work was done by the outstanding students, Brandon Huang, Chancharik Mitra and Tianning Chai, as well as Zhiqiu Lin, Assaf Arbelle, Rogerio Feris, Leonid Karlinsky.
I also want to special thanks the amazing Trevor Darrell and Deva Ramanan for their invaluable guidance.
I also want to special thanks the amazing Trevor Darrell and Deva Ramanan for their invaluable guidance.
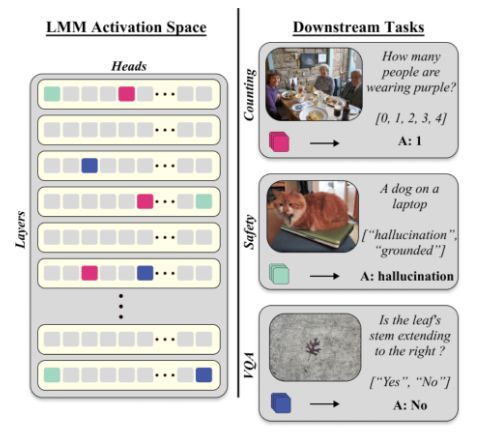
We tried several different tasks, such as Safety, Visual Question Answering (VQA), and Classification benchmarks.
The results suggest that SAVs are particularly useful even when compared to LoRA (where there are not a lot of samples to fine-tune the model).
The results suggest that SAVs are particularly useful even when compared to LoRA (where there are not a lot of samples to fine-tune the model).

December 4, 2024 at 9:24 PM
We tried several different tasks, such as Safety, Visual Question Answering (VQA), and Classification benchmarks.
The results suggest that SAVs are particularly useful even when compared to LoRA (where there are not a lot of samples to fine-tune the model).
The results suggest that SAVs are particularly useful even when compared to LoRA (where there are not a lot of samples to fine-tune the model).
What we did? ->
We propose an algorithm for finding small sets of attention heads (~20!) as multimodal features in Generative LMMs that can be used for discriminative VL tasks, outperforming encoder-only architectures (CLIP, SigLIP) without training.
We propose an algorithm for finding small sets of attention heads (~20!) as multimodal features in Generative LMMs that can be used for discriminative VL tasks, outperforming encoder-only architectures (CLIP, SigLIP) without training.
December 4, 2024 at 9:24 PM
What we did? ->
We propose an algorithm for finding small sets of attention heads (~20!) as multimodal features in Generative LMMs that can be used for discriminative VL tasks, outperforming encoder-only architectures (CLIP, SigLIP) without training.
We propose an algorithm for finding small sets of attention heads (~20!) as multimodal features in Generative LMMs that can be used for discriminative VL tasks, outperforming encoder-only architectures (CLIP, SigLIP) without training.
