




Josep Ferrer
@rfeers.bsky.social
Data Scientist & Tech Writer KDnuggets, DataCap, TDS & Medium
| Outstand using data - Data Science, AI and Tech |
Join 6k data professionals reading databites.tech 🧩
| Outstand using data - Data Science, AI and Tech |
Join 6k data professionals reading databites.tech 🧩
Did you like this post?
Then join the DataBites newsletter to get weekly issues about Data Science and more! 🧩
👉🏻 databites.tech
Then join the DataBites newsletter to get weekly issues about Data Science and more! 🧩
👉🏻 databites.tech

October 22, 2025 at 10:35 AM
Did you like this post?
Then join the DataBites newsletter to get weekly issues about Data Science and more! 🧩
👉🏻 databites.tech
Then join the DataBites newsletter to get weekly issues about Data Science and more! 🧩
👉🏻 databites.tech
3. 𝗠𝗮𝘀𝘁𝗲𝗿𝗶𝗻𝗴 𝗕𝗮𝘀𝗶𝗰 𝗞𝗲𝘆𝘄𝗼𝗿𝗱𝘀
The first real step is to familiarize yourself with the commands that form the backbone of SQL querying:
• SELECT, FROM, WHERE
• ORDER BY and LIMIT Clauses
The first real step is to familiarize yourself with the commands that form the backbone of SQL querying:
• SELECT, FROM, WHERE
• ORDER BY and LIMIT Clauses

October 22, 2025 at 10:35 AM
3. 𝗠𝗮𝘀𝘁𝗲𝗿𝗶𝗻𝗴 𝗕𝗮𝘀𝗶𝗰 𝗞𝗲𝘆𝘄𝗼𝗿𝗱𝘀
The first real step is to familiarize yourself with the commands that form the backbone of SQL querying:
• SELECT, FROM, WHERE
• ORDER BY and LIMIT Clauses
The first real step is to familiarize yourself with the commands that form the backbone of SQL querying:
• SELECT, FROM, WHERE
• ORDER BY and LIMIT Clauses
🚀 New to SQL?
Then here’s a roadmap to get you started in 2025, step-by-step! 🧵👇
(Don't forget to bookmark for later!! 😉 )
Then here’s a roadmap to get you started in 2025, step-by-step! 🧵👇
(Don't forget to bookmark for later!! 😉 )

October 22, 2025 at 10:35 AM
🚀 New to SQL?
Then here’s a roadmap to get you started in 2025, step-by-step! 🧵👇
(Don't forget to bookmark for later!! 😉 )
Then here’s a roadmap to get you started in 2025, step-by-step! 🧵👇
(Don't forget to bookmark for later!! 😉 )
Did you like this post?
Then join the DataBites newsletter to get weekly issues about Data Science and more! 🧩
👉🏻 databites.tech
Then join the DataBites newsletter to get weekly issues about Data Science and more! 🧩
👉🏻 databites.tech

October 15, 2025 at 10:23 AM
Did you like this post?
Then join the DataBites newsletter to get weekly issues about Data Science and more! 🧩
👉🏻 databites.tech
Then join the DataBites newsletter to get weekly issues about Data Science and more! 🧩
👉🏻 databites.tech
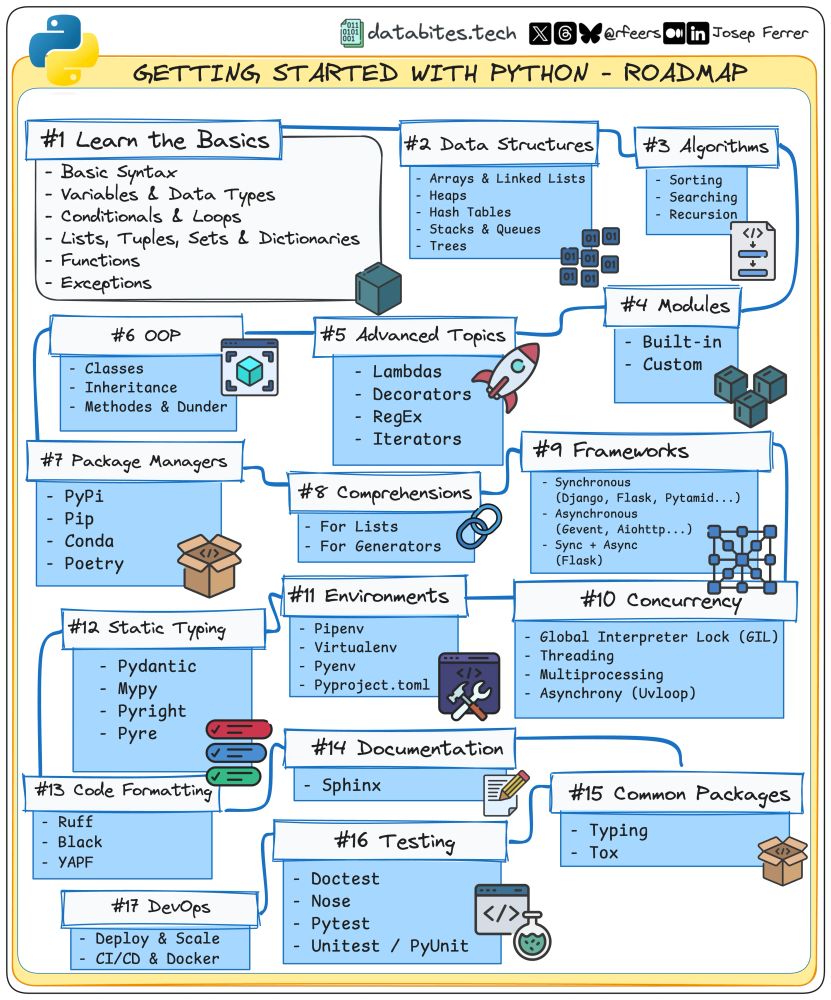
🚀 New to Python?
Then here’s a roadmap to get you started in 2025, step-by-step! 🧵👇
Then here’s a roadmap to get you started in 2025, step-by-step! 🧵👇
October 15, 2025 at 10:23 AM
🚀 New to Python?
Then here’s a roadmap to get you started in 2025, step-by-step! 🧵👇
Then here’s a roadmap to get you started in 2025, step-by-step! 🧵👇
Did you like this post?
Then join my freshly started DataBites newsletter to get all my content right to your mail every week! 🧩
👉🏻 databites.tech
Then join my freshly started DataBites newsletter to get all my content right to your mail every week! 🧩
👉🏻 databites.tech
October 14, 2025 at 10:00 AM
Did you like this post?
Then join my freshly started DataBites newsletter to get all my content right to your mail every week! 🧩
👉🏻 databites.tech
Then join my freshly started DataBites newsletter to get all my content right to your mail every week! 🧩
👉🏻 databites.tech
STEP 3 FINAL OUTPUT
The decoder weaves all its processed information to predict the next part of the sequence.
This cycle continues until it completes the sequence, creating a full, context-rich output. 🔄
The decoder weaves all its processed information to predict the next part of the sequence.
This cycle continues until it completes the sequence, creating a full, context-rich output. 🔄

October 14, 2025 at 10:00 AM
STEP 3 FINAL OUTPUT
The decoder weaves all its processed information to predict the next part of the sequence.
This cycle continues until it completes the sequence, creating a full, context-rich output. 🔄
The decoder weaves all its processed information to predict the next part of the sequence.
This cycle continues until it completes the sequence, creating a full, context-rich output. 🔄
STEP 2.5 LINEAR CLASSIFIER AND SOFTMAX
Converting scores into probabilities, this step decides the most likely next word. It works as a classifier, and the wort with the highest probability is the final output of the Decoder.
Converting scores into probabilities, this step decides the most likely next word. It works as a classifier, and the wort with the highest probability is the final output of the Decoder.

October 14, 2025 at 10:00 AM
STEP 2.5 LINEAR CLASSIFIER AND SOFTMAX
Converting scores into probabilities, this step decides the most likely next word. It works as a classifier, and the wort with the highest probability is the final output of the Decoder.
Converting scores into probabilities, this step decides the most likely next word. It works as a classifier, and the wort with the highest probability is the final output of the Decoder.
STEP 2.4 FEED-FORWARD NEURAL NETWORK
This step boosts the decoder's predictions using a feed-forward network.
This ensures everything is adjusted and in sync for the coming steps.
This step boosts the decoder's predictions using a feed-forward network.
This ensures everything is adjusted and in sync for the coming steps.

October 14, 2025 at 10:00 AM
STEP 2.4 FEED-FORWARD NEURAL NETWORK
This step boosts the decoder's predictions using a feed-forward network.
This ensures everything is adjusted and in sync for the coming steps.
This step boosts the decoder's predictions using a feed-forward network.
This ensures everything is adjusted and in sync for the coming steps.
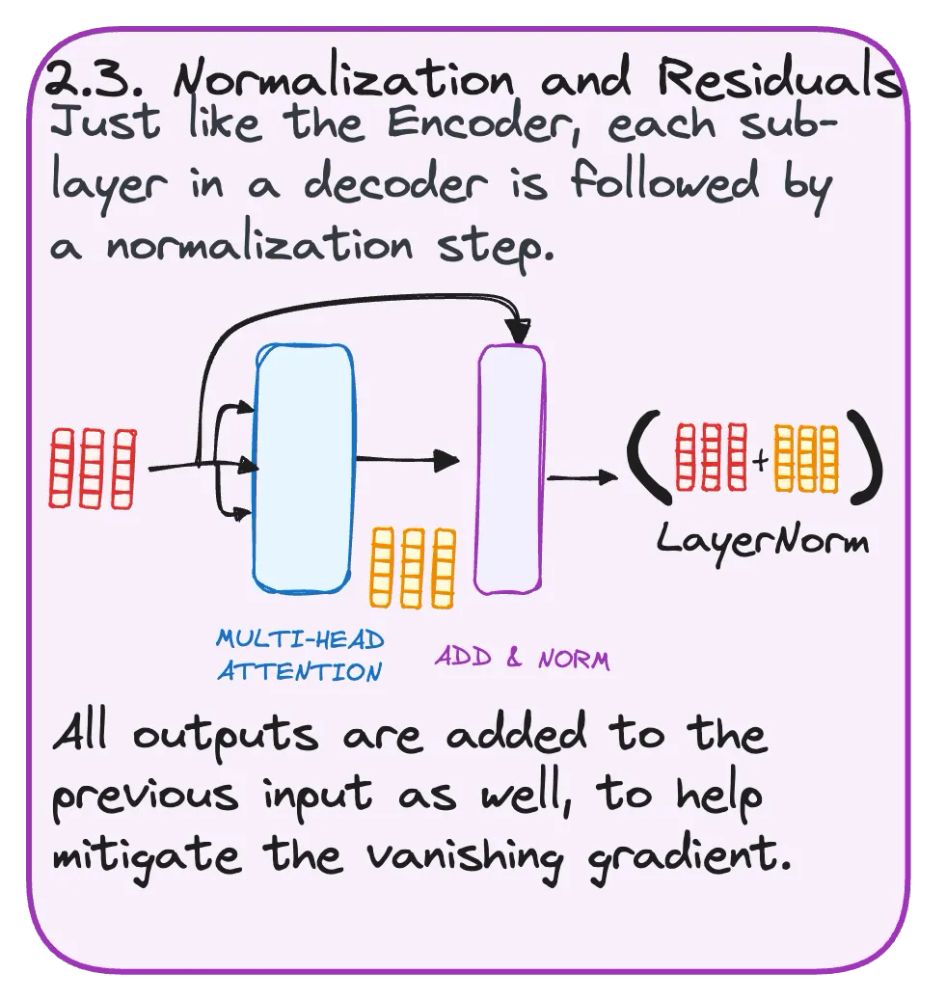
STEP 2.3 NORMALIZATION AND RESIDUALS
Normalization keeps the data smooth and uniform, preventing any part from overwhelming others.
Normalization keeps the data smooth and uniform, preventing any part from overwhelming others.
October 14, 2025 at 10:00 AM
STEP 2.3 NORMALIZATION AND RESIDUALS
Normalization keeps the data smooth and uniform, preventing any part from overwhelming others.
Normalization keeps the data smooth and uniform, preventing any part from overwhelming others.
STEP 2.2 CROSS-ATTENTION
Here, the decoder aligns the encoder's input with its processing, ensuring each piece of information is perfectly synced.
Here, the decoder aligns the encoder's input with its processing, ensuring each piece of information is perfectly synced.

October 14, 2025 at 10:00 AM
STEP 2.2 CROSS-ATTENTION
Here, the decoder aligns the encoder's input with its processing, ensuring each piece of information is perfectly synced.
Here, the decoder aligns the encoder's input with its processing, ensuring each piece of information is perfectly synced.
STEP 2.1 MASKED SELF-ATTENTION
In the self-attention step, the decoder ensures it doesn't peek ahead. Think of it as solving a puzzle without skipping ahead to see the whole picture.
In the self-attention step, the decoder ensures it doesn't peek ahead. Think of it as solving a puzzle without skipping ahead to see the whole picture.

October 14, 2025 at 10:00 AM
STEP 2.1 MASKED SELF-ATTENTION
In the self-attention step, the decoder ensures it doesn't peek ahead. Think of it as solving a puzzle without skipping ahead to see the whole picture.
In the self-attention step, the decoder ensures it doesn't peek ahead. Think of it as solving a puzzle without skipping ahead to see the whole picture.
🔗 STEP 2 - LAYERING THE DECODERS
The Decoder is made up of multiple layers that each refine the output:
• Masked Self-Attention
• Cross-Attention.
• Normalization and Residuals.
The Decoder is made up of multiple layers that each refine the output:
• Masked Self-Attention
• Cross-Attention.
• Normalization and Residuals.

October 14, 2025 at 10:00 AM
🔗 STEP 2 - LAYERING THE DECODERS
The Decoder is made up of multiple layers that each refine the output:
• Masked Self-Attention
• Cross-Attention.
• Normalization and Residuals.
The Decoder is made up of multiple layers that each refine the output:
• Masked Self-Attention
• Cross-Attention.
• Normalization and Residuals.
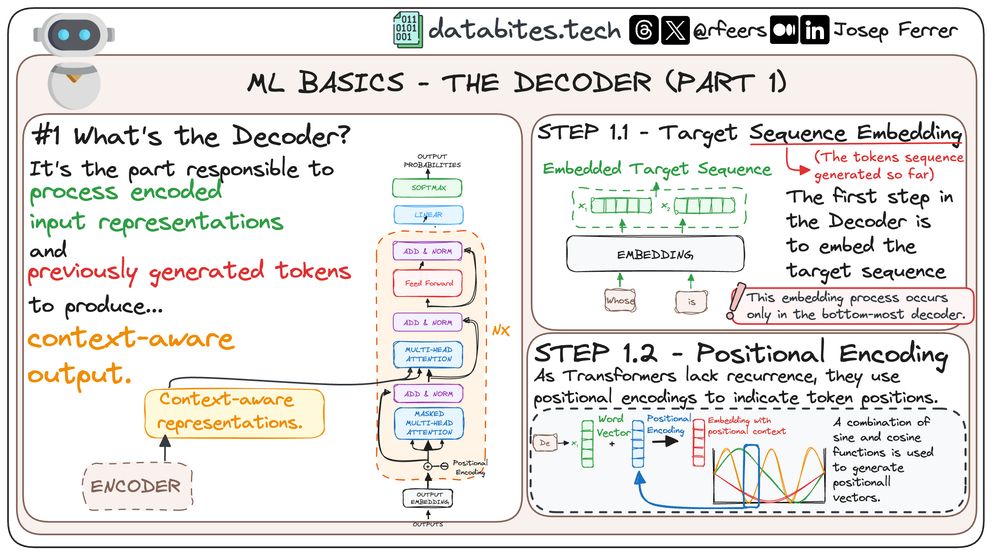
STEP 1.2 Positional Encoding
Since Transformers don't rely on sequence order like older models, they use positional encodings.
This adds a layer of 'where' to 'what'—vital for understanding the sequence in full context!
Since Transformers don't rely on sequence order like older models, they use positional encodings.
This adds a layer of 'where' to 'what'—vital for understanding the sequence in full context!

October 14, 2025 at 10:00 AM
STEP 1.2 Positional Encoding
Since Transformers don't rely on sequence order like older models, they use positional encodings.
This adds a layer of 'where' to 'what'—vital for understanding the sequence in full context!
Since Transformers don't rely on sequence order like older models, they use positional encodings.
This adds a layer of 'where' to 'what'—vital for understanding the sequence in full context!
🔄 STEP 1 - PROCESSING THE TARGET SEQUENCE
STEP 1.1 Target Sequence Embedding
The Decoder begins by embedding the sequence it needs to process, turning raw data into a format it can understand.
STEP 1.1 Target Sequence Embedding
The Decoder begins by embedding the sequence it needs to process, turning raw data into a format it can understand.

October 14, 2025 at 10:00 AM
🔄 STEP 1 - PROCESSING THE TARGET SEQUENCE
STEP 1.1 Target Sequence Embedding
The Decoder begins by embedding the sequence it needs to process, turning raw data into a format it can understand.
STEP 1.1 Target Sequence Embedding
The Decoder begins by embedding the sequence it needs to process, turning raw data into a format it can understand.
1️⃣ WHAT'S THE DECODER? 🎯
The Decoder is the brain behind transforming encoded inputs and previously generated tokens into context-aware outputs.
Imagine it as the artist who paints the final picture from sketches. 🖌️
The Decoder is the brain behind transforming encoded inputs and previously generated tokens into context-aware outputs.
Imagine it as the artist who paints the final picture from sketches. 🖌️

October 14, 2025 at 10:00 AM
1️⃣ WHAT'S THE DECODER? 🎯
The Decoder is the brain behind transforming encoded inputs and previously generated tokens into context-aware outputs.
Imagine it as the artist who paints the final picture from sketches. 🖌️
The Decoder is the brain behind transforming encoded inputs and previously generated tokens into context-aware outputs.
Imagine it as the artist who paints the final picture from sketches. 🖌️
The Transformer's decoder clearly explained 👇🏻
October 14, 2025 at 10:00 AM
The Transformer's decoder clearly explained 👇🏻
Did you like this post?
Then join my freshly started DataBites newsletter to get all my content right to your mail every week! 🧩
👉🏻 databites.tech
Then join my freshly started DataBites newsletter to get all my content right to your mail every week! 🧩
👉🏻 databites.tech
October 13, 2025 at 10:00 AM
Did you like this post?
Then join my freshly started DataBites newsletter to get all my content right to your mail every week! 🧩
👉🏻 databites.tech
Then join my freshly started DataBites newsletter to get all my content right to your mail every week! 🧩
👉🏻 databites.tech
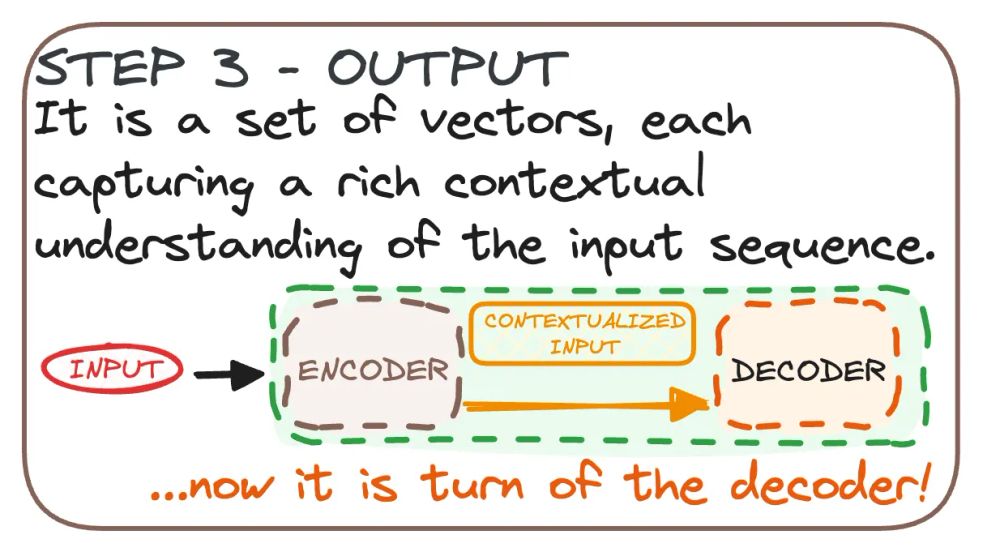
𝗦𝗧𝗘𝗣 3: 𝗢𝗨𝗧𝗣𝗨𝗧 🎯
The encoder's final output is a set of vectors, each capturing a rich contextual understanding of the input sequence.
This output is ready to be decoded and used for various NLP tasks! 🎉
The encoder's final output is a set of vectors, each capturing a rich contextual understanding of the input sequence.
This output is ready to be decoded and used for various NLP tasks! 🎉
October 13, 2025 at 10:00 AM
𝗦𝗧𝗘𝗣 3: 𝗢𝗨𝗧𝗣𝗨𝗧 🎯
The encoder's final output is a set of vectors, each capturing a rich contextual understanding of the input sequence.
This output is ready to be decoded and used for various NLP tasks! 🎉
The encoder's final output is a set of vectors, each capturing a rich contextual understanding of the input sequence.
This output is ready to be decoded and used for various NLP tasks! 🎉
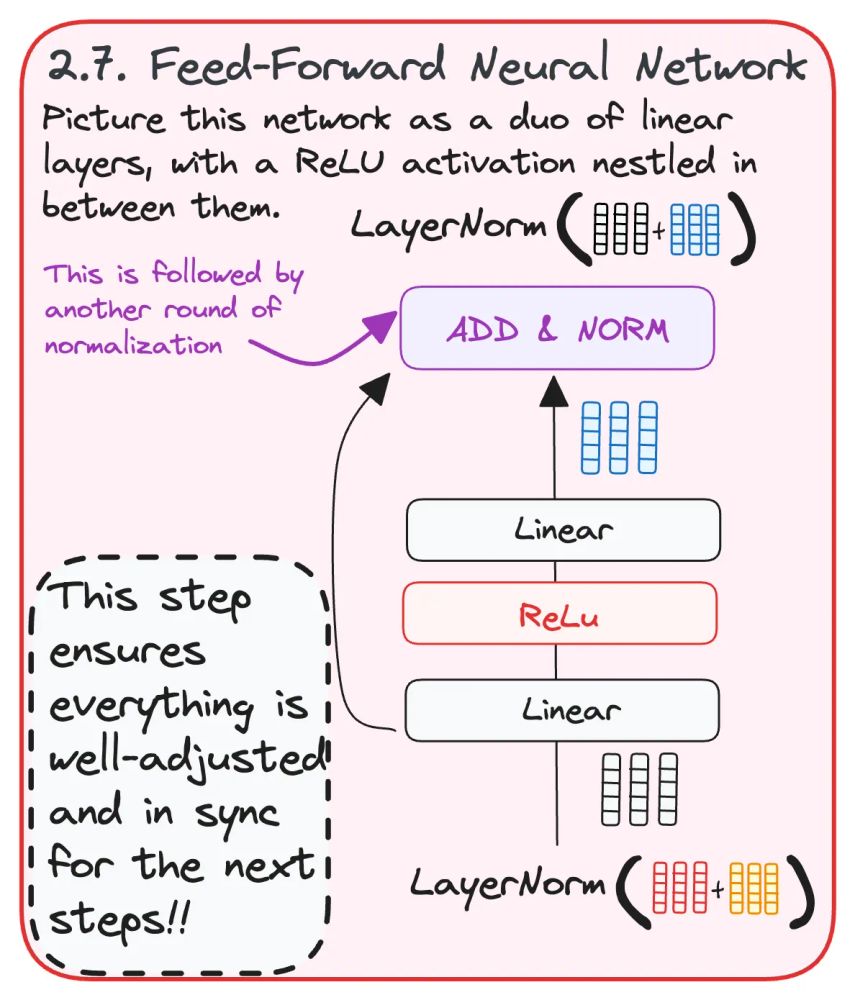
𝗦𝗧𝗘𝗣 2.7: 𝗙𝗘𝗘𝗗-𝗙𝗢𝗥𝗪𝗔𝗥𝗗 𝗡𝗘𝗨𝗥𝗔𝗟 𝗡𝗘𝗧𝗪𝗢𝗥𝗞 🧠
After normalization, a feed-forward network processes the output, adding another round of refinement to the context.
This is the final touch before sending the information to the next layer! 🚀
After normalization, a feed-forward network processes the output, adding another round of refinement to the context.
This is the final touch before sending the information to the next layer! 🚀
October 13, 2025 at 10:00 AM
𝗦𝗧𝗘𝗣 2.7: 𝗙𝗘𝗘𝗗-𝗙𝗢𝗥𝗪𝗔𝗥𝗗 𝗡𝗘𝗨𝗥𝗔𝗟 𝗡𝗘𝗧𝗪𝗢𝗥𝗞 🧠
After normalization, a feed-forward network processes the output, adding another round of refinement to the context.
This is the final touch before sending the information to the next layer! 🚀
After normalization, a feed-forward network processes the output, adding another round of refinement to the context.
This is the final touch before sending the information to the next layer! 🚀
𝗦𝗧𝗘𝗣 2.6: 𝗡𝗢𝗥𝗠𝗔𝗟𝗜𝗭𝗔𝗧𝗜𝗢𝗡 𝗔𝗡𝗗 𝗥𝗘𝗦𝗜𝗗𝗨𝗔𝗟𝗦 🔄
Each sub-layer in the encoder is followed by a normalization step and a residual connection.
This helps mitigate the vanishing gradient problem.
Ensures everything is balanced and ready for the next steps! ⚖️
Each sub-layer in the encoder is followed by a normalization step and a residual connection.
This helps mitigate the vanishing gradient problem.
Ensures everything is balanced and ready for the next steps! ⚖️

October 13, 2025 at 10:00 AM
𝗦𝗧𝗘𝗣 2.6: 𝗡𝗢𝗥𝗠𝗔𝗟𝗜𝗭𝗔𝗧𝗜𝗢𝗡 𝗔𝗡𝗗 𝗥𝗘𝗦𝗜𝗗𝗨𝗔𝗟𝗦 🔄
Each sub-layer in the encoder is followed by a normalization step and a residual connection.
This helps mitigate the vanishing gradient problem.
Ensures everything is balanced and ready for the next steps! ⚖️
Each sub-layer in the encoder is followed by a normalization step and a residual connection.
This helps mitigate the vanishing gradient problem.
Ensures everything is balanced and ready for the next steps! ⚖️
𝗦𝗧𝗘𝗣 2.5: 𝗖𝗢𝗠𝗕𝗜𝗡𝗜𝗡𝗚 𝗦𝗢𝗙𝗧𝗠𝗔𝗫 𝗥𝗘𝗦𝗨𝗟𝗧𝗦 🍹
The attention weights are multiplied by the value vectors, producing an output that is a weighted sum of the values.
This integrates the context into the output representation! 🎯
The attention weights are multiplied by the value vectors, producing an output that is a weighted sum of the values.
This integrates the context into the output representation! 🎯

October 13, 2025 at 10:00 AM
𝗦𝗧𝗘𝗣 2.5: 𝗖𝗢𝗠𝗕𝗜𝗡𝗜𝗡𝗚 𝗦𝗢𝗙𝗧𝗠𝗔𝗫 𝗥𝗘𝗦𝗨𝗟𝗧𝗦 🍹
The attention weights are multiplied by the value vectors, producing an output that is a weighted sum of the values.
This integrates the context into the output representation! 🎯
The attention weights are multiplied by the value vectors, producing an output that is a weighted sum of the values.
This integrates the context into the output representation! 🎯
𝗦𝗧𝗘𝗣 2.4: 𝗔𝗣𝗣𝗟𝗬𝗜𝗡𝗚 𝗦𝗢𝗙𝗧𝗠𝗔𝗫 🔀
A softmax function is applied to obtain attention weights, highlighting important words while downplaying less relevant ones.
This sharpens the focus on key parts of the input! 🔍
A softmax function is applied to obtain attention weights, highlighting important words while downplaying less relevant ones.
This sharpens the focus on key parts of the input! 🔍

October 13, 2025 at 10:00 AM
𝗦𝗧𝗘𝗣 2.4: 𝗔𝗣𝗣𝗟𝗬𝗜𝗡𝗚 𝗦𝗢𝗙𝗧𝗠𝗔𝗫 🔀
A softmax function is applied to obtain attention weights, highlighting important words while downplaying less relevant ones.
This sharpens the focus on key parts of the input! 🔍
A softmax function is applied to obtain attention weights, highlighting important words while downplaying less relevant ones.
This sharpens the focus on key parts of the input! 🔍
𝗦𝗧𝗘𝗣 2.3: 𝗦𝗖𝗔𝗟𝗜𝗡𝗚 𝗧𝗛𝗘 𝗔𝗧𝗧𝗘𝗡𝗧𝗜𝗢𝗡 𝗦𝗖𝗢𝗥𝗘𝗦 📈
The scores are scaled by the square root of the dimension of the query and key vectors to ensure stable gradients.
This prevents large values from skewing the results. 📊
The scores are scaled by the square root of the dimension of the query and key vectors to ensure stable gradients.
This prevents large values from skewing the results. 📊

October 13, 2025 at 10:00 AM
𝗦𝗧𝗘𝗣 2.3: 𝗦𝗖𝗔𝗟𝗜𝗡𝗚 𝗧𝗛𝗘 𝗔𝗧𝗧𝗘𝗡𝗧𝗜𝗢𝗡 𝗦𝗖𝗢𝗥𝗘𝗦 📈
The scores are scaled by the square root of the dimension of the query and key vectors to ensure stable gradients.
This prevents large values from skewing the results. 📊
The scores are scaled by the square root of the dimension of the query and key vectors to ensure stable gradients.
This prevents large values from skewing the results. 📊
𝗦𝗧𝗘𝗣 2.2: 𝗠𝗔𝗧𝗥𝗜𝗫 𝗠𝗨𝗟𝗧𝗜𝗣𝗟𝗜𝗖𝗔𝗧𝗜𝗢𝗡 🔢
Scores are assigned to each word pair by multiplying the query and key vectors.
This assigns a relative importance score to each word in the sequence.
It’s like ranking the words based on their relevance to each other!
Scores are assigned to each word pair by multiplying the query and key vectors.
This assigns a relative importance score to each word in the sequence.
It’s like ranking the words based on their relevance to each other!

October 13, 2025 at 10:00 AM
𝗦𝗧𝗘𝗣 2.2: 𝗠𝗔𝗧𝗥𝗜𝗫 𝗠𝗨𝗟𝗧𝗜𝗣𝗟𝗜𝗖𝗔𝗧𝗜𝗢𝗡 🔢
Scores are assigned to each word pair by multiplying the query and key vectors.
This assigns a relative importance score to each word in the sequence.
It’s like ranking the words based on their relevance to each other!
Scores are assigned to each word pair by multiplying the query and key vectors.
This assigns a relative importance score to each word in the sequence.
It’s like ranking the words based on their relevance to each other!