




Bradley Love
@profdata.bsky.social
Senior research scientist at Los Alamos National Laboratory. Former UCL, UTexas, Alan Turing Institute, Ellis EU. CogSci, AI, Comp Neuro, AI for scientific discovery https://bradlove.org
moderation@blueskyweb.xyz, send to me, or send directly to the Met (London police) who are investigating www.met.police.uk. I could see this being super distressing for a vulnerable person, so hope this does not become more common. For me, it's been an exercise in rapidly learning to not care! 2/2

Home
Your local police force - online. Report a crime, contact us and other services, plus crime prevention advice, crime news, appeals and statistics.
www.met.police.uk
July 18, 2025 at 10:14 PM
moderation@blueskyweb.xyz, send to me, or send directly to the Met (London police) who are investigating www.met.police.uk. I could see this being super distressing for a vulnerable person, so hope this does not become more common. For me, it's been an exercise in rapidly learning to not care! 2/2
Bonus: I found it counterintuitive that (in theory) the learning problem is the same for any word ordering. Aligning proof and simulation was key. Now, new avenues open to address positional biases, better training and knowing when to trust LLMs. w @ken-lxl.bsky.social arxiv.org/abs/2505.08739

Probability Consistency in Large Language Models: Theoretical Foundations Meet Empirical Discrepancies
Can autoregressive large language models (LLMs) learn consistent probability distributions when trained on sequences in different token orders? We prove formally that for any well-defined probability ...
arxiv.org
May 14, 2025 at 3:02 PM
Bonus: I found it counterintuitive that (in theory) the learning problem is the same for any word ordering. Aligning proof and simulation was key. Now, new avenues open to address positional biases, better training and knowing when to trust LLMs. w @ken-lxl.bsky.social arxiv.org/abs/2505.08739
When LLMs diverge from one another because of word order (data factorization), it indicates their probability distributions are inconsistent, which is a red flag (not trustworthy). We trace deviations to self-attention positional and locality biases. 2/2 arxiv.org/abs/2505.08739
Probability Consistency in Large Language Models: Theoretical Foundations Meet Empirical Discrepancies
Can autoregressive large language models (LLMs) learn consistent probability distributions when trained on sequences in different token orders? We prove formally that for any well-defined probability ...
arxiv.org
May 14, 2025 at 3:02 PM
When LLMs diverge from one another because of word order (data factorization), it indicates their probability distributions are inconsistent, which is a red flag (not trustworthy). We trace deviations to self-attention positional and locality biases. 2/2 arxiv.org/abs/2505.08739
with @ken-lxl.bsky.social , @robmok.bsky.social , Brett Roads
February 17, 2025 at 3:23 PM
with @ken-lxl.bsky.social , @robmok.bsky.social , Brett Roads
A 7B is small enough to train efficiently on 4 A100s (thanks Microsoft) and at the time Mistral performed relatively well for its size.
November 27, 2024 at 5:11 PM
A 7B is small enough to train efficiently on 4 A100s (thanks Microsoft) and at the time Mistral performed relatively well for its size.
Yes, the model weights and all materials are openly available. We really want to offer easy to use tools people can use through the web without hassle. To do that, we need to do more work (will be announcing an open source effort soon) and need some funding for hosting a model endpoint.
November 27, 2024 at 5:09 PM
Yes, the model weights and all materials are openly available. We really want to offer easy to use tools people can use through the web without hassle. To do that, we need to do more work (will be announcing an open source effort soon) and need some funding for hosting a model endpoint.
While BrainBench focused on neuroscience, our approach is science general, so others can adopt our template. Everything is open weight and open source. Thanks to the entire team and the expert participants. Sign up for news at braingpt.org 8/8

BrainGPT
This is the homepage for BrainGPT, a Large Language Model tool to assist neuroscientific research.
BrainGPT.org
November 27, 2024 at 2:13 PM
While BrainBench focused on neuroscience, our approach is science general, so others can adopt our template. Everything is open weight and open source. Thanks to the entire team and the expert participants. Sign up for news at braingpt.org 8/8
Finally, LLMs can be augmented with neuroscience knowledge for better performance. We tuned Mistral on 20 years of the neuroscience literature using LoRA. The tuned model, which we refer to as BrainGPT, performed better on BrainBench. 7/8

November 27, 2024 at 2:13 PM
Finally, LLMs can be augmented with neuroscience knowledge for better performance. We tuned Mistral on 20 years of the neuroscience literature using LoRA. The tuned model, which we refer to as BrainGPT, performed better on BrainBench. 7/8
Indeed, follow-up work on teaming finds that joint LLM and human teams outperform either alone, because LLMs and humans make different types of errors. We offer a simple method to combine confidence-weighted judgements.
arxiv.org/abs/2408.08083 6/8
arxiv.org/abs/2408.08083 6/8
Confidence-weighted integration of human and machine judgments for superior decision-making
Large language models (LLMs) have emerged as powerful tools in various domains. Recent studies have shown that LLMs can surpass humans in certain tasks, such as predicting the outcomes of neuroscience...
arxiv.org
November 27, 2024 at 2:13 PM
Indeed, follow-up work on teaming finds that joint LLM and human teams outperform either alone, because LLMs and humans make different types of errors. We offer a simple method to combine confidence-weighted judgements.
arxiv.org/abs/2408.08083 6/8
arxiv.org/abs/2408.08083 6/8
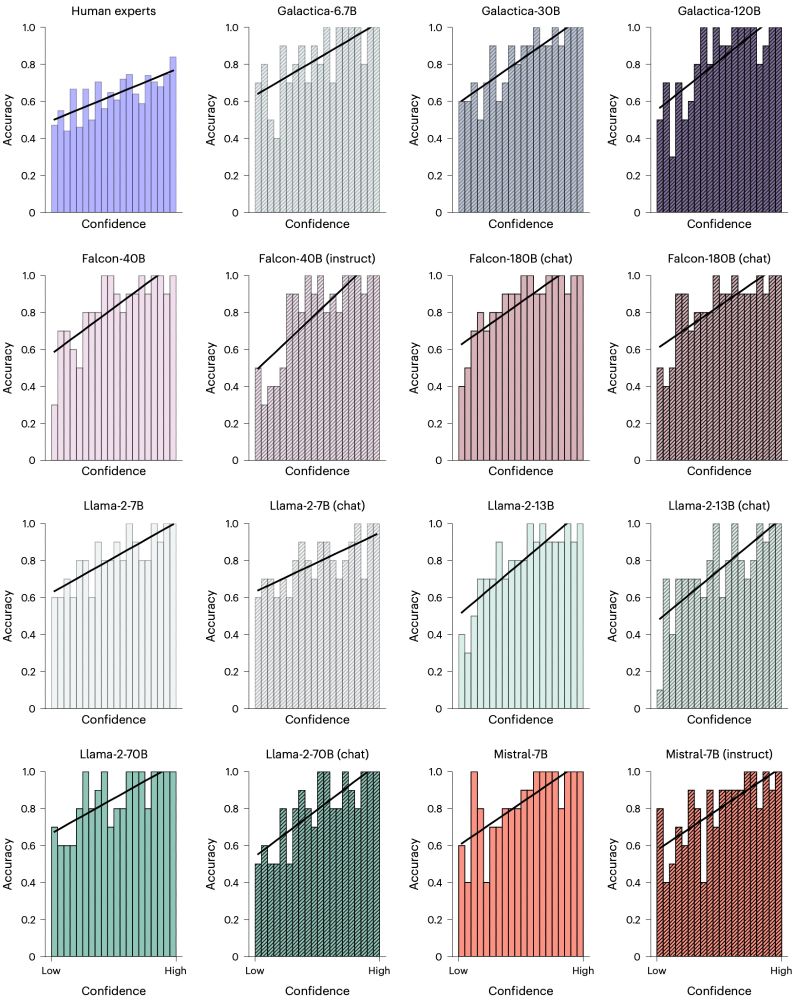
In the Nature HB paper, both human experts and LLMs were well calibrated - when they were more certain of their decisions, they were more likely to be correct. Calibration is beneficial for human-machine teaming. 5/8
November 27, 2024 at 2:13 PM
In the Nature HB paper, both human experts and LLMs were well calibrated - when they were more certain of their decisions, they were more likely to be correct. Calibration is beneficial for human-machine teaming. 5/8
There were no signs of leakage from the training to test set. We performed standard checks. In follow-up work, we trained an LLM from scratch to rule out leakage; even this smaller model was superhuman on BrainBench arxiv.org/abs/2405.09395 4/8
Matching domain experts by training from scratch on domain knowledge
Recently, large language models (LLMs) have outperformed human experts in predicting the results of neuroscience experiments (Luo et al., 2024). What is the basis for this performance? One possibility...
arxiv.org
November 27, 2024 at 2:13 PM
There were no signs of leakage from the training to test set. We performed standard checks. In follow-up work, we trained an LLM from scratch to rule out leakage; even this smaller model was superhuman on BrainBench arxiv.org/abs/2405.09395 4/8
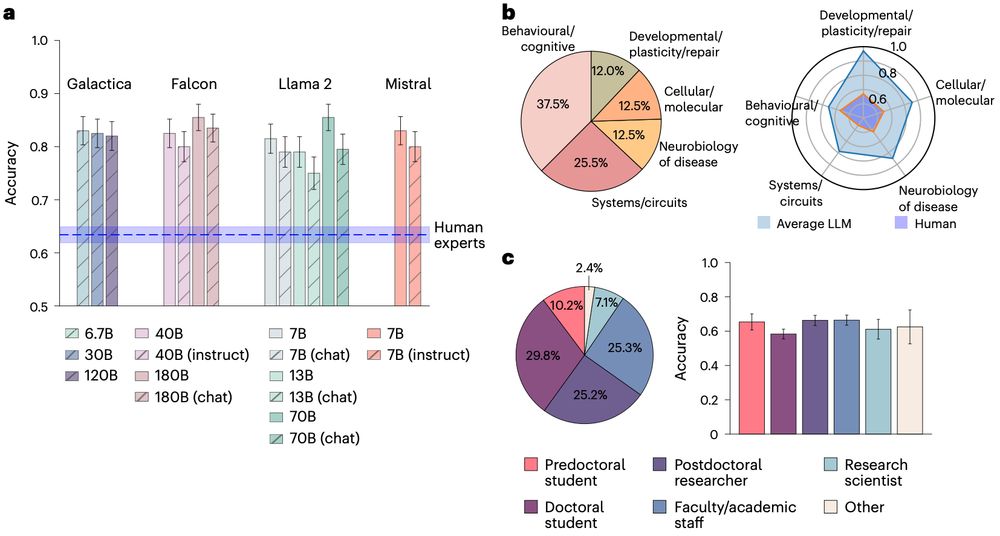
All 15 LLMs considered crushed human experts at BrainBench's predictive task. LLMs correctly predicted neuroscience results (across all sub areas) dramatically better than human experts, including those with decades of experience. 3/8
November 27, 2024 at 2:13 PM
All 15 LLMs considered crushed human experts at BrainBench's predictive task. LLMs correctly predicted neuroscience results (across all sub areas) dramatically better than human experts, including those with decades of experience. 3/8
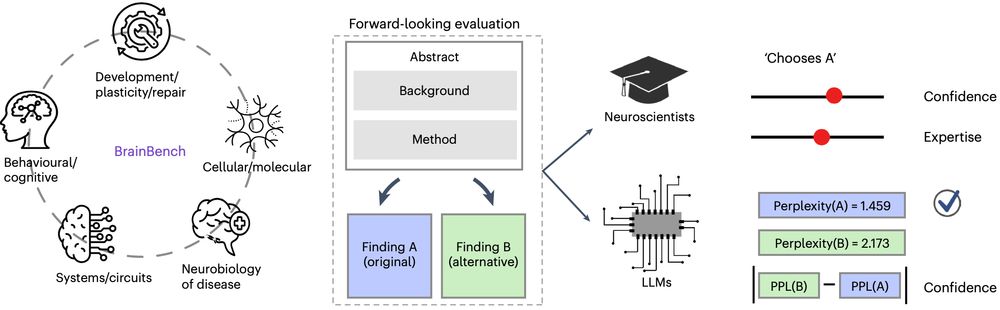
To test, we created BrainBench, a forward-looking benchmark that stresses prediction over retrieval of facts, avoiding LLM's "hallucination" issue. The task was to predict which version of a Journal of Neuroscience abstract gave the actual result. 2/6
November 27, 2024 at 2:13 PM
To test, we created BrainBench, a forward-looking benchmark that stresses prediction over retrieval of facts, avoiding LLM's "hallucination" issue. The task was to predict which version of a Journal of Neuroscience abstract gave the actual result. 2/6
Thanks Gary! I have no idea because I don't see how we get anyone to learn over more than a billion tokens. Maybe one could bootstrap some estimate from the perplexity difference between forward and backward, assuming we can get a sense of how that affects learning? Just off the top of my head...
November 20, 2024 at 10:27 PM
Thanks Gary! I have no idea because I don't see how we get anyone to learn over more than a billion tokens. Maybe one could bootstrap some estimate from the perplexity difference between forward and backward, assuming we can get a sense of how that affects learning? Just off the top of my head...
i am not seeing the issue. every method is the same, but the text is reversed. we even tokenize separately for forward and backward to make comparable. Perplexity is calculated over the entire option for the benchmark items. The difficulty doesn't have to be the same - it just turned out that way.
November 19, 2024 at 5:49 PM
i am not seeing the issue. every method is the same, but the text is reversed. we even tokenize separately for forward and backward to make comparable. Perplexity is calculated over the entire option for the benchmark items. The difficulty doesn't have to be the same - it just turned out that way.