



Pierre Peterlongo
@pierrepeterlongo.bsky.social
Inria Senior researcher.
Head of the https://team.inria.fr/genscale/ at Inria and Irisa.
Algorithmics for sequencing data analyses, genomics and metagenomics.
Head of the https://team.inria.fr/genscale/ at Inria and Irisa.
Algorithmics for sequencing data analyses, genomics and metagenomics.
📊 Experimental results show Kaminari's superiority in index size and query performance across various genomic datasets. 5/8


May 27, 2025 at 12:06 PM
📊 Experimental results show Kaminari's superiority in index size and query performance across various genomic datasets. 5/8
🔍 Key findings include:
- Use of minimizers and integer compression for indexing.
- Lower memory footprint and faster query times.
- Minimal impact of false positives on result ranking, using the Rank-Biased Overlap (RBO) metric.
2/8
- Use of minimizers and integer compression for indexing.
- Lower memory footprint and faster query times.
- Minimal impact of false positives on result ranking, using the Rank-Biased Overlap (RBO) metric.
2/8

May 27, 2025 at 12:06 PM
🔍 Key findings include:
- Use of minimizers and integer compression for indexing.
- Lower memory footprint and faster query times.
- Minimal impact of false positives on result ranking, using the Rank-Biased Overlap (RBO) metric.
2/8
- Use of minimizers and integer compression for indexing.
- Lower memory footprint and faster query times.
- Minimal impact of false positives on result ranking, using the Rank-Biased Overlap (RBO) metric.
2/8
📜 Excited to share insights from our recent paper: "Kaminari: a resource-frugal index for approximate colored k-mer queries". The study aims to efficiently identify documents containing a query string, focusing on DNA strings. www.biorxiv.org/content/10.1... 🧬 🖥️ 1/8

May 27, 2025 at 12:06 PM
📜 Excited to share insights from our recent paper: "Kaminari: a resource-frugal index for approximate colored k-mer queries". The study aims to efficiently identify documents containing a query string, focusing on DNA strings. www.biorxiv.org/content/10.1... 🧬 🖥️ 1/8
Note that the "conservative update" is also something we implemented (without describing it) in fimpera github.com/lrobidou/fim...

March 20, 2025 at 7:59 AM
Note that the "conservative update" is also something we implemented (without describing it) in fimpera github.com/lrobidou/fim...
Results: slightly longer insertion time, but 2 to 3 times lower abundance overestimations.

March 18, 2025 at 4:31 PM
Results: slightly longer insertion time, but 2 to 3 times lower abundance overestimations.
In two words: increase only minimal stored values of a cBF when adding elements to this filter.

March 18, 2025 at 4:31 PM
In two words: increase only minimal stored values of a cBF when adding elements to this filter.
Maybe the simplest idea to decrease overestimations of a counting bloom filter. A trivial observation + 10 lines of code.
I'm surprised it has not been described before. Please comment if this is not the case.
Blog post here:
pierrepeterlongo.github.io/2025/03/17/m... 🧪🧬🖥️
I'm surprised it has not been described before. Please comment if this is not the case.
Blog post here:
pierrepeterlongo.github.io/2025/03/17/m... 🧪🧬🖥️

March 18, 2025 at 4:31 PM
Maybe the simplest idea to decrease overestimations of a counting bloom filter. A trivial observation + 10 lines of code.
I'm surprised it has not been described before. Please comment if this is not the case.
Blog post here:
pierrepeterlongo.github.io/2025/03/17/m... 🧪🧬🖥️
I'm surprised it has not been described before. Please comment if this is not the case.
Blog post here:
pierrepeterlongo.github.io/2025/03/17/m... 🧪🧬🖥️
🚨🚨🚨
We are hiring
🚨🚨🚨
After the creation of logan-search (see: bsky.app/profile/pier...) we propose a 2-years engineer position for continuing the development and optimizations.
With @rayanchikhi.bsky.social and @tlemane.bsky.social
Details + applications: recrutement.inria.fr/public/class...
We are hiring
🚨🚨🚨
After the creation of logan-search (see: bsky.app/profile/pier...) we propose a 2-years engineer position for continuing the development and optimizations.
With @rayanchikhi.bsky.social and @tlemane.bsky.social
Details + applications: recrutement.inria.fr/public/class...

December 12, 2024 at 2:30 PM
🚨🚨🚨
We are hiring
🚨🚨🚨
After the creation of logan-search (see: bsky.app/profile/pier...) we propose a 2-years engineer position for continuing the development and optimizations.
With @rayanchikhi.bsky.social and @tlemane.bsky.social
Details + applications: recrutement.inria.fr/public/class...
We are hiring
🚨🚨🚨
After the creation of logan-search (see: bsky.app/profile/pier...) we propose a 2-years engineer position for continuing the development and optimizations.
With @rayanchikhi.bsky.social and @tlemane.bsky.social
Details + applications: recrutement.inria.fr/public/class...
Amazing ideas here www.biorxiv.org/content/bior... from
@yoann.bsky.social
and collaborators.
Reorganize minimizers to allow kmers dichotomic search. That's brilliant.
#bioinformatics 🧬🖥️
@yoann.bsky.social
and collaborators.
Reorganize minimizers to allow kmers dichotomic search. That's brilliant.
#bioinformatics 🧬🖥️

December 4, 2024 at 12:10 PM
Amazing ideas here www.biorxiv.org/content/bior... from
@yoann.bsky.social
and collaborators.
Reorganize minimizers to allow kmers dichotomic search. That's brilliant.
#bioinformatics 🧬🖥️
@yoann.bsky.social
and collaborators.
Reorganize minimizers to allow kmers dichotomic search. That's brilliant.
#bioinformatics 🧬🖥️
🔬 We anticipate this tool will revolutionize the accessibility of public genomics data. Our hope is to empower new discoveries by the community 💖
Developed w/ @TeoLemane, & collabs @RayanChikhi, @RNA_Life, Alex Morales, and Luke Pereira
Developed w/ @TeoLemane, & collabs @RayanChikhi, @RNA_Life, Alex Morales, and Luke Pereira

November 11, 2024 at 7:29 PM
🔬 We anticipate this tool will revolutionize the accessibility of public genomics data. Our hope is to empower new discoveries by the community 💖
Developed w/ @TeoLemane, & collabs @RayanChikhi, @RNA_Life, Alex Morales, and Luke Pereira
Developed w/ @TeoLemane, & collabs @RayanChikhi, @RNA_Life, Alex Morales, and Luke Pereira
🧪 Logan Search returns a list of SRA accessions, not alignments. To bring you closer to the data we’ve also created a microservice to instantly retrieve Logan contigs matching your search.
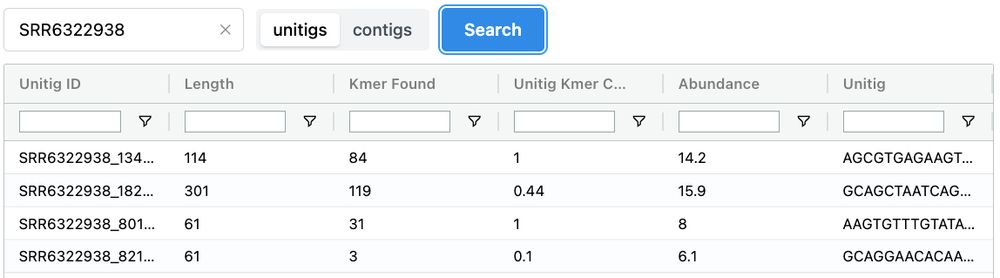
November 11, 2024 at 7:29 PM
🧪 Logan Search returns a list of SRA accessions, not alignments. To bring you closer to the data we’ve also created a microservice to instantly retrieve Logan contigs matching your search.
📊 The output datasets are easily visualized with custom plots in Logan Search, which accesses a harmonized set of query and SRA meta-data including sequencing technology, type of molecule, geographic distribution, and sample origins. Learn more about your sequence.
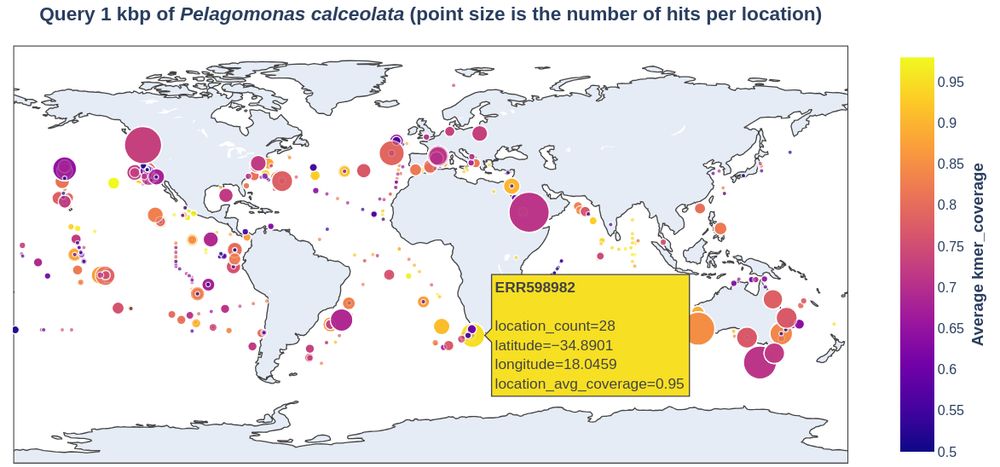

November 11, 2024 at 7:29 PM
📊 The output datasets are easily visualized with custom plots in Logan Search, which accesses a harmonized set of query and SRA meta-data including sequencing technology, type of molecule, geographic distribution, and sample origins. Learn more about your sequence.
Logan Search transforms your query🧬 to its k-mers🔢 (k=31), and in the time it takes to brew a coffee, it will retrieve every dataset containing your k-mers. It’s the only service working at this scale.
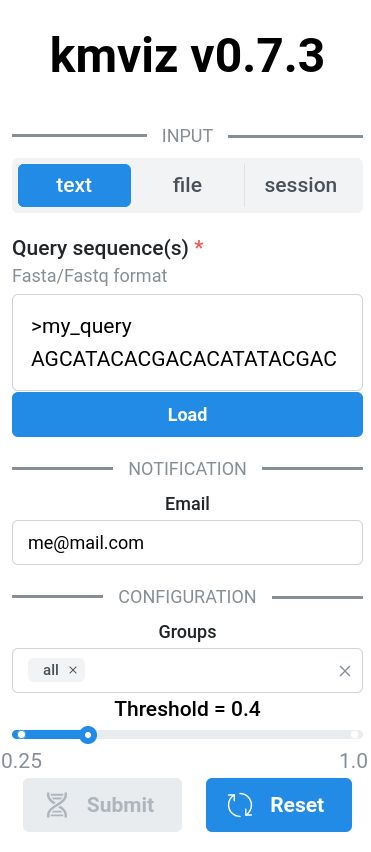

November 11, 2024 at 7:29 PM
Logan Search transforms your query🧬 to its k-mers🔢 (k=31), and in the time it takes to brew a coffee, it will retrieve every dataset containing your k-mers. It’s the only service working at this scale.
🧬🔍There are 50 petabases of freely-available DNA sequencing data. We introducing Logan Search which allows you to search for any DNA sequence in minutes, bringing Earth’s largest genomic resource to your fingertips.
🏔️ logan-search.org 🏔️
#Genomics #Bioinformatics #OpenScience
🏔️ logan-search.org 🏔️
#Genomics #Bioinformatics #OpenScience

November 11, 2024 at 7:29 PM
🧬🔍There are 50 petabases of freely-available DNA sequencing data. We introducing Logan Search which allows you to search for any DNA sequence in minutes, bringing Earth’s largest genomic resource to your fingertips.
🏔️ logan-search.org 🏔️
#Genomics #Bioinformatics #OpenScience
🏔️ logan-search.org 🏔️
#Genomics #Bioinformatics #OpenScience