


Nicolas Yax
@nicolasyax.bsky.social
PhD student working on the cognition of LLMs | HRL team - ENS Ulm | FLOWERS - Inria Bordeaux
If you are interested in this line of research of mapping LLMs you might also want to check the amazing work of Eliahu Horwitz arxiv.org/abs/2503.10633 and Momose Oyama arxiv.org/abs/2502.16173 10/10

Charting and Navigating Hugging Face's Model Atlas
As there are now millions of publicly available neural networks, searching and analyzing large model repositories becomes increasingly important. Navigating so many models requires an atlas, but as mo...
arxiv.org
April 24, 2025 at 1:15 PM
If you are interested in this line of research of mapping LLMs you might also want to check the amazing work of Eliahu Horwitz arxiv.org/abs/2503.10633 and Momose Oyama arxiv.org/abs/2502.16173 10/10
In short, PhyloLM is a cheap and versatile algorithm that generates useful representations for LLMs that can have creative applications in pratice. 9/10
paper : arxiv.org/abs/2404.04671
colab : colab.research.google.com/drive/1agNE5...
code : github.com/Nicolas-Yax/...
ICLR : Saturday 3pm Poster 505
paper : arxiv.org/abs/2404.04671
colab : colab.research.google.com/drive/1agNE5...
code : github.com/Nicolas-Yax/...
ICLR : Saturday 3pm Poster 505
April 24, 2025 at 1:15 PM
In short, PhyloLM is a cheap and versatile algorithm that generates useful representations for LLMs that can have creative applications in pratice. 9/10
paper : arxiv.org/abs/2404.04671
colab : colab.research.google.com/drive/1agNE5...
code : github.com/Nicolas-Yax/...
ICLR : Saturday 3pm Poster 505
paper : arxiv.org/abs/2404.04671
colab : colab.research.google.com/drive/1agNE5...
code : github.com/Nicolas-Yax/...
ICLR : Saturday 3pm Poster 505
A PhyloLM collaborative Huggingface space is available to try the algorithm and visualize maps : huggingface.co/spaces/nyax/... The Model Submit button has been temporarily suspended for technical reasons but it should be back very soon ! 8/10

PhyloLM - a Hugging Face Space by nyax
This app allows you to explore and compare language models through various visualizations, including similarity matrices, 2D scatter plots, and tree diagrams. You can search for models by name, adj...
huggingface.co
April 24, 2025 at 1:15 PM
A PhyloLM collaborative Huggingface space is available to try the algorithm and visualize maps : huggingface.co/spaces/nyax/... The Model Submit button has been temporarily suspended for technical reasons but it should be back very soon ! 8/10
By using code related contexts we can obtain a fairly different map. For example we notice that Qwen and GPT-3.5 have a very different way of coding compared to the other models which was not visible on the reasoning map. 7/10

April 24, 2025 at 1:15 PM
By using code related contexts we can obtain a fairly different map. For example we notice that Qwen and GPT-3.5 have a very different way of coding compared to the other models which was not visible on the reasoning map. 7/10
The contexts choice is important as it reflects different capabilities of LLMs. Here on a general reasoning type of context we can plot a map of models using UMAP. The larger the edge, the closer models are from each other. Models on the same cluster are even closer ! 6/10

April 24, 2025 at 1:15 PM
The contexts choice is important as it reflects different capabilities of LLMs. Here on a general reasoning type of context we can plot a map of models using UMAP. The larger the edge, the closer models are from each other. Models on the same cluster are even closer ! 6/10
It can also measure quantization efficiency by observing the behavioral distance between LLM and quantized versions. In the Qwen 1.5 release, GPTQ seems to perform best. This new concept of metric could provide additional insights to quantization efficiency. 5/10

April 24, 2025 at 1:15 PM
It can also measure quantization efficiency by observing the behavioral distance between LLM and quantized versions. In the Qwen 1.5 release, GPTQ seems to perform best. This new concept of metric could provide additional insights to quantization efficiency. 5/10
Aside from plotting trees, PhyloLM similarity matrix is very versatile. For example, running a logistic regression on the distance matrix makes it possible to predict performance of new models even from unseen families with good accuracy. Here is what we got on ARC. 4/10

April 24, 2025 at 1:15 PM
Aside from plotting trees, PhyloLM similarity matrix is very versatile. For example, running a logistic regression on the distance matrix makes it possible to predict performance of new models even from unseen families with good accuracy. Here is what we got on ARC. 4/10
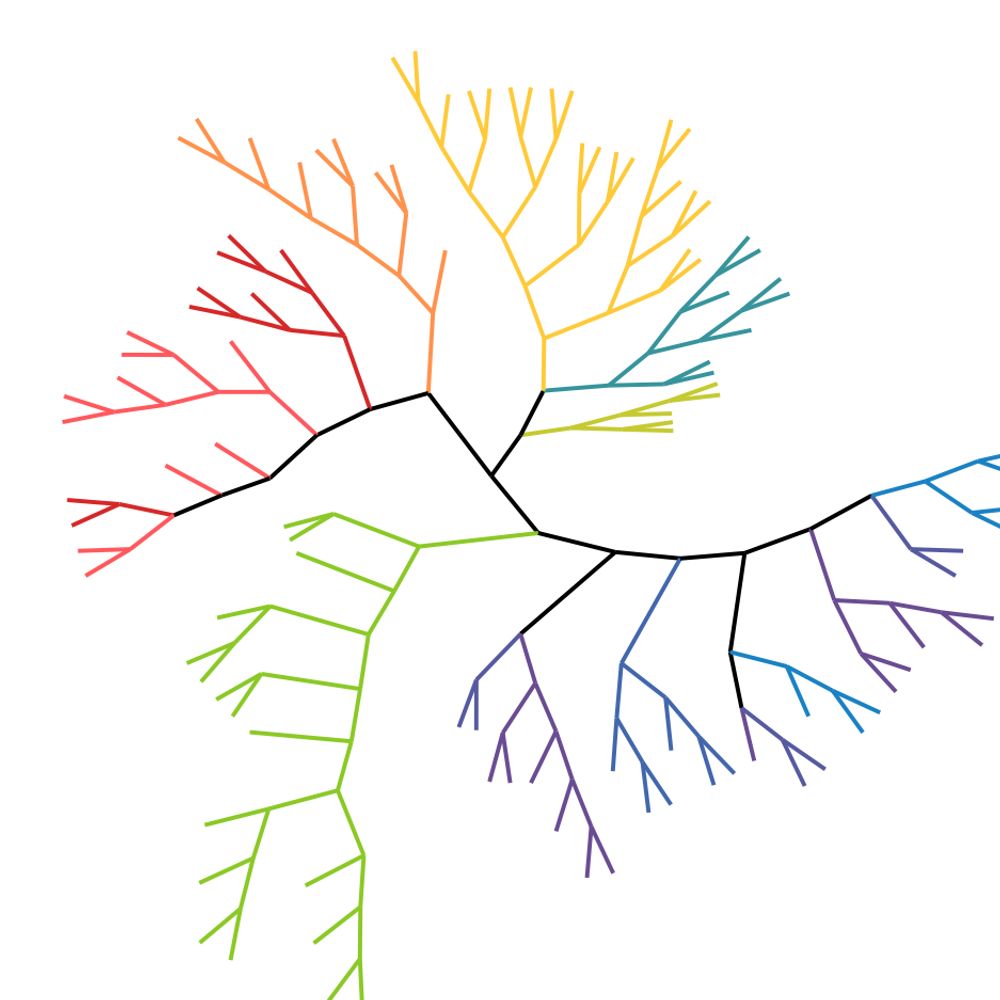
Not taking into account these requirements can still produce efficient distance vizualisation trees. However it is important to remember they do not represent evolutionary trees. Feel free to zoom in to see model names. 3/10

April 24, 2025 at 1:15 PM
Not taking into account these requirements can still produce efficient distance vizualisation trees. However it is important to remember they do not represent evolutionary trees. Feel free to zoom in to see model names. 3/10
Phylogenetic algorithms often require common ancestors to not appear in the objects studied but are clearly able to retrieve the evolution of the family. Here is an example in the richness of open-access model : @teknium.bsky.social @maximelabonne.bsky.social @mistralai.bsky.social 2/10

April 24, 2025 at 1:15 PM
Phylogenetic algorithms often require common ancestors to not appear in the objects studied but are clearly able to retrieve the evolution of the family. Here is an example in the richness of open-access model : @teknium.bsky.social @maximelabonne.bsky.social @mistralai.bsky.social 2/10
We build a distance matrix from comparing outputs of LLMs to a hundred of different contexts and build maps and trees from this distance matrix. Because PhyloLM only requires sampling very few tokens after a very short contexts the algorithm is particularly cheap to run. 1/10

April 24, 2025 at 1:15 PM
We build a distance matrix from comparing outputs of LLMs to a hundred of different contexts and build maps and trees from this distance matrix. Because PhyloLM only requires sampling very few tokens after a very short contexts the algorithm is particularly cheap to run. 1/10
Related work on contamination in LLMs :
arxiv.org/abs/2402.15938 Dong et al. 2024
arxiv.org/abs/2310.15007 Meeus et al. 2023
arxiv.org/abs/2310.17623 Oren et al. 2024
arxiv.org/abs/2402.15938 Dong et al. 2024
arxiv.org/abs/2310.15007 Meeus et al. 2023
arxiv.org/abs/2310.17623 Oren et al. 2024

Generalization or Memorization: Data Contamination and Trustworthy Evaluation for Large Language Models
Recent statements about the impressive capabilities of large language models (LLMs) are usually supported by evaluating on open-access benchmarks. Considering the vast size and wide-ranging sources of...
arxiv.org
November 15, 2024 at 1:48 PM
Related work on contamination in LLMs :
arxiv.org/abs/2402.15938 Dong et al. 2024
arxiv.org/abs/2310.15007 Meeus et al. 2023
arxiv.org/abs/2310.17623 Oren et al. 2024
arxiv.org/abs/2402.15938 Dong et al. 2024
arxiv.org/abs/2310.15007 Meeus et al. 2023
arxiv.org/abs/2310.17623 Oren et al. 2024
LogProber paper : www.arxiv.org/abs/2408.14352
git : github.com/Nicolas-Yax/...
collab : colab.research.google.com/drive/1GDbmE...
git : github.com/Nicolas-Yax/...
collab : colab.research.google.com/drive/1GDbmE...
Assessing Contamination in Large Language Models: Introducing the LogProber method
In machine learning, contamination refers to situations where testing data leak into the training set. The issue is particularly relevant for the evaluation of the performance of Large Language Models...
www.arxiv.org
November 15, 2024 at 1:48 PM
LogProber paper : www.arxiv.org/abs/2408.14352
git : github.com/Nicolas-Yax/...
collab : colab.research.google.com/drive/1GDbmE...
git : github.com/Nicolas-Yax/...
collab : colab.research.google.com/drive/1GDbmE...
It is part of a research agenda to open the LLM black box and provide tools for researchers to better interact with models in a more transparent manner. The last paper in this agenda was PhyloLM proposing methods to investigate the phylogeny of LLMs arxiv.org/abs/2404.04671 15/15
arxiv.org
November 15, 2024 at 1:48 PM
It is part of a research agenda to open the LLM black box and provide tools for researchers to better interact with models in a more transparent manner. The last paper in this agenda was PhyloLM proposing methods to investigate the phylogeny of LLMs arxiv.org/abs/2404.04671 15/15
This method was first introduced in our paper Studying and improving reasoning in humans and machines investigating the evolution of cognitive biases in language models. www.nature.com/articles/s44... 14/15
www.nature.com
November 15, 2024 at 1:48 PM
This method was first introduced in our paper Studying and improving reasoning in humans and machines investigating the evolution of cognitive biases in language models. www.nature.com/articles/s44... 14/15
As such, LogProber can be a useful tool to check contamination in language models at a very low cost (one forward pass) given some very high level assumptions about the training method (that are very often verified in practice). 13/15
November 15, 2024 at 1:48 PM
As such, LogProber can be a useful tool to check contamination in language models at a very low cost (one forward pass) given some very high level assumptions about the training method (that are very often verified in practice). 13/15
Lastly, the A scenario is more common in instruction finetuning scenarios. In open access models finetuning databases are often shared making it possible to check directly if the item is found in the training set which is rarely the case for pretraining databases. 12/15
November 15, 2024 at 1:48 PM
Lastly, the A scenario is more common in instruction finetuning scenarios. In open access models finetuning databases are often shared making it possible to check directly if the item is found in the training set which is rarely the case for pretraining databases. 12/15