




Navita Goyal
@navitagoyal.bsky.social
PhD student @umdcs, Member of @ClipUmd lab | Earlier @AdobeResearch, @IITRoorkee
Reposted by Navita Goyal

Interested in interpretability, data attribution, evaluation, and similar topics?
Interested in doing a postdoc with me?
Apply to the prestigious Azrieli program!
Link below 👇
DMs are open (email is good too!)
Interested in doing a postdoc with me?
Apply to the prestigious Azrieli program!
Link below 👇
DMs are open (email is good too!)
November 13, 2025 at 1:59 PM
Interested in interpretability, data attribution, evaluation, and similar topics?
Interested in doing a postdoc with me?
Apply to the prestigious Azrieli program!
Link below 👇
DMs are open (email is good too!)
Interested in doing a postdoc with me?
Apply to the prestigious Azrieli program!
Link below 👇
DMs are open (email is good too!)
Reposted by Navita Goyal

Happy to be at #EMNLP2025! Please say hello and come see our lovely work

November 5, 2025 at 2:23 AM
Happy to be at #EMNLP2025! Please say hello and come see our lovely work
Reposted by Navita Goyal

I am recruiting PhD students to start in 2026! If you are interested in robustness, training dynamics, interpretability for scientific understanding, or the science of LLM analysis you should apply. BU is building a huge LLM analysis/interp group and you’ll be joining at the ground floor.
Life update: I'm starting as faculty at Boston University
@bucds.bsky.social in 2026! BU has SCHEMES for LM interpretability & analysis, I couldn't be more pumped to join a burgeoning supergroup w/ @najoung.bsky.social @amuuueller.bsky.social. Looking for my first students, so apply and reach out!
@bucds.bsky.social in 2026! BU has SCHEMES for LM interpretability & analysis, I couldn't be more pumped to join a burgeoning supergroup w/ @najoung.bsky.social @amuuueller.bsky.social. Looking for my first students, so apply and reach out!

October 16, 2025 at 3:45 PM
I am recruiting PhD students to start in 2026! If you are interested in robustness, training dynamics, interpretability for scientific understanding, or the science of LLM analysis you should apply. BU is building a huge LLM analysis/interp group and you’ll be joining at the ground floor.
Reposted by Navita Goyal

I'll be presenting this work with @rachelrudinger at #NAACL2025 tomorrow (Wednesday 4/30) in Albuquerque during Session C (Oral/Poster 2) at 2pm! 🔬
Decomposing hypotheses in traditional NLI and defeasible NLI helps us measure various forms of consistency of LLMs. Come join us!
Decomposing hypotheses in traditional NLI and defeasible NLI helps us measure various forms of consistency of LLMs. Come join us!

April 29, 2025 at 8:40 PM
I'll be presenting this work with @rachelrudinger at #NAACL2025 tomorrow (Wednesday 4/30) in Albuquerque during Session C (Oral/Poster 2) at 2pm! 🔬
Decomposing hypotheses in traditional NLI and defeasible NLI helps us measure various forms of consistency of LLMs. Come join us!
Decomposing hypotheses in traditional NLI and defeasible NLI helps us measure various forms of consistency of LLMs. Come join us!
Reposted by Navita Goyal

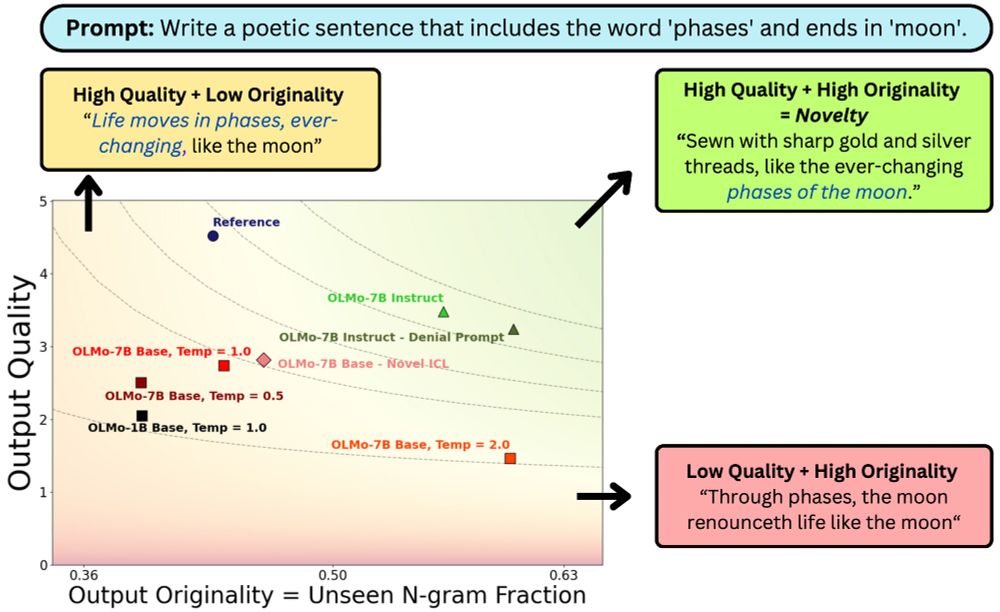
What does it mean for #LLM output to be novel?
In work w/ johnchen6.bsky.social, Jane Pan, Valerie Chen and He He, we argue it needs to be both original and high quality. While prompting tricks trade one for the other, better models (scaling/post-training) can shift the novelty frontier 🧵
In work w/ johnchen6.bsky.social, Jane Pan, Valerie Chen and He He, we argue it needs to be both original and high quality. While prompting tricks trade one for the other, better models (scaling/post-training) can shift the novelty frontier 🧵
April 29, 2025 at 4:35 PM
What does it mean for #LLM output to be novel?
In work w/ johnchen6.bsky.social, Jane Pan, Valerie Chen and He He, we argue it needs to be both original and high quality. While prompting tricks trade one for the other, better models (scaling/post-training) can shift the novelty frontier 🧵
In work w/ johnchen6.bsky.social, Jane Pan, Valerie Chen and He He, we argue it needs to be both original and high quality. While prompting tricks trade one for the other, better models (scaling/post-training) can shift the novelty frontier 🧵
Reposted by Navita Goyal

🚨 New Paper 🚨
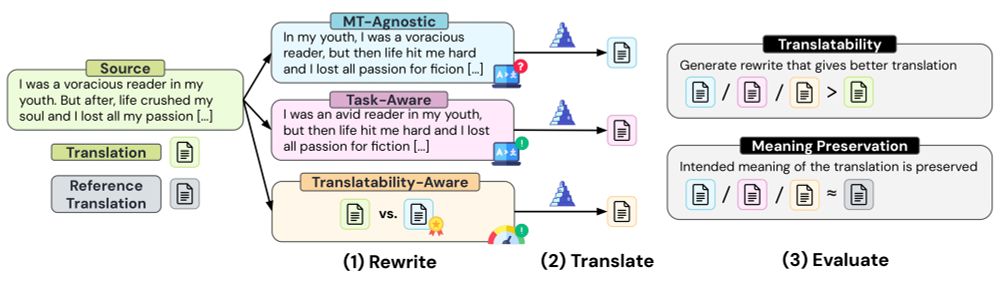
1/ We often assume that well-written text is easier to translate ✏️
But can #LLMs automatically rewrite inputs to improve machine translation? 🌍
Here’s what we found 🧵
1/ We often assume that well-written text is easier to translate ✏️
But can #LLMs automatically rewrite inputs to improve machine translation? 🌍
Here’s what we found 🧵
April 17, 2025 at 1:32 AM
🚨 New Paper 🚨
1/ We often assume that well-written text is easier to translate ✏️
But can #LLMs automatically rewrite inputs to improve machine translation? 🌍
Here’s what we found 🧵
1/ We often assume that well-written text is easier to translate ✏️
But can #LLMs automatically rewrite inputs to improve machine translation? 🌍
Here’s what we found 🧵
Reposted by Navita Goyal

🔈 NEW PAPER 🔈
Excited to share my paper that analyzes the effect of cross-lingual alignment on multilingual performance
Paper: arxiv.org/abs/2504.09378 🧵
Excited to share my paper that analyzes the effect of cross-lingual alignment on multilingual performance
Paper: arxiv.org/abs/2504.09378 🧵

Can you map it to English? The Role of Cross-Lingual Alignment in Multilingual Performance of LLMs
Large language models (LLMs) pre-trained predominantly on English text exhibit surprising multilingual capabilities, yet the mechanisms driving cross-lingual generalization remain poorly understood. T...
arxiv.org
April 18, 2025 at 3:00 PM
🔈 NEW PAPER 🔈
Excited to share my paper that analyzes the effect of cross-lingual alignment on multilingual performance
Paper: arxiv.org/abs/2504.09378 🧵
Excited to share my paper that analyzes the effect of cross-lingual alignment on multilingual performance
Paper: arxiv.org/abs/2504.09378 🧵
Reposted by Navita Goyal

Have work on the actionable impact of interpretability findings? Consider submitting to our Actionable Interpretability workshop at ICML! See below for more info.
Website: actionable-interpretability.github.io
Deadline: May 9
Website: actionable-interpretability.github.io
Deadline: May 9

🎉 Our Actionable Interpretability workshop has been accepted to #ICML2025! 🎉
> Follow @actinterp.bsky.social
> Website actionable-interpretability.github.io
@talhaklay.bsky.social @anja.re @mariusmosbach.bsky.social @sarah-nlp.bsky.social @iftenney.bsky.social
Paper submission deadline: May 9th!
> Follow @actinterp.bsky.social
> Website actionable-interpretability.github.io
@talhaklay.bsky.social @anja.re @mariusmosbach.bsky.social @sarah-nlp.bsky.social @iftenney.bsky.social
Paper submission deadline: May 9th!

April 3, 2025 at 5:58 PM
Have work on the actionable impact of interpretability findings? Consider submitting to our Actionable Interpretability workshop at ICML! See below for more info.
Website: actionable-interpretability.github.io
Deadline: May 9
Website: actionable-interpretability.github.io
Deadline: May 9
Reposted by Navita Goyal

Thinking about paying $20k/month for a "PhD-level AI agent"? You might want to wait until their web browsing skills are on par with those of human PhD students 😛 Check out our new BEARCUBS benchmark, which shows web agents struggle to perform simple multimodal browsing tasks!

Introducing 🐻 BEARCUBS 🐻, a “small but mighty” dataset of 111 QA pairs designed to assess computer-using web agents in multimodal interactions on the live web!
✅ Humans achieve 85% accuracy
❌ OpenAI Operator: 24%
❌ Anthropic Computer Use: 14%
❌ Convergence AI Proxy: 13%
✅ Humans achieve 85% accuracy
❌ OpenAI Operator: 24%
❌ Anthropic Computer Use: 14%
❌ Convergence AI Proxy: 13%

March 12, 2025 at 4:08 PM
Thinking about paying $20k/month for a "PhD-level AI agent"? You might want to wait until their web browsing skills are on par with those of human PhD students 😛 Check out our new BEARCUBS benchmark, which shows web agents struggle to perform simple multimodal browsing tasks!
Reposted by Navita Goyal

🚨 Our team at UMD is looking for participants to study how #LLM agent plans can help you answer complex questions
💰 $1 per question
🏆 Top-3 fastest + most accurate win $50
⏳ Questions take ~3 min => $20/hr+
Click here to sign up (please join, reposts appreciated 🙏): preferences.umiacs.umd.edu
💰 $1 per question
🏆 Top-3 fastest + most accurate win $50
⏳ Questions take ~3 min => $20/hr+
Click here to sign up (please join, reposts appreciated 🙏): preferences.umiacs.umd.edu
March 11, 2025 at 2:30 PM
🚨 Our team at UMD is looking for participants to study how #LLM agent plans can help you answer complex questions
💰 $1 per question
🏆 Top-3 fastest + most accurate win $50
⏳ Questions take ~3 min => $20/hr+
Click here to sign up (please join, reposts appreciated 🙏): preferences.umiacs.umd.edu
💰 $1 per question
🏆 Top-3 fastest + most accurate win $50
⏳ Questions take ~3 min => $20/hr+
Click here to sign up (please join, reposts appreciated 🙏): preferences.umiacs.umd.edu
Reposted by Navita Goyal
🚨 New Position Paper 🚨
Multiple choice evals for LLMs are simple and popular, but we know they are awful 😬
We complain they're full of errors, saturated, and test nothing meaningful, so why do we still use them? 🫠
Here's why MCQA evals are broken, and how to fix them 🧵
Multiple choice evals for LLMs are simple and popular, but we know they are awful 😬
We complain they're full of errors, saturated, and test nothing meaningful, so why do we still use them? 🫠
Here's why MCQA evals are broken, and how to fix them 🧵

February 24, 2025 at 9:04 PM
🚨 New Position Paper 🚨
Multiple choice evals for LLMs are simple and popular, but we know they are awful 😬
We complain they're full of errors, saturated, and test nothing meaningful, so why do we still use them? 🫠
Here's why MCQA evals are broken, and how to fix them 🧵
Multiple choice evals for LLMs are simple and popular, but we know they are awful 😬
We complain they're full of errors, saturated, and test nothing meaningful, so why do we still use them? 🫠
Here's why MCQA evals are broken, and how to fix them 🧵
Reposted by Navita Goyal
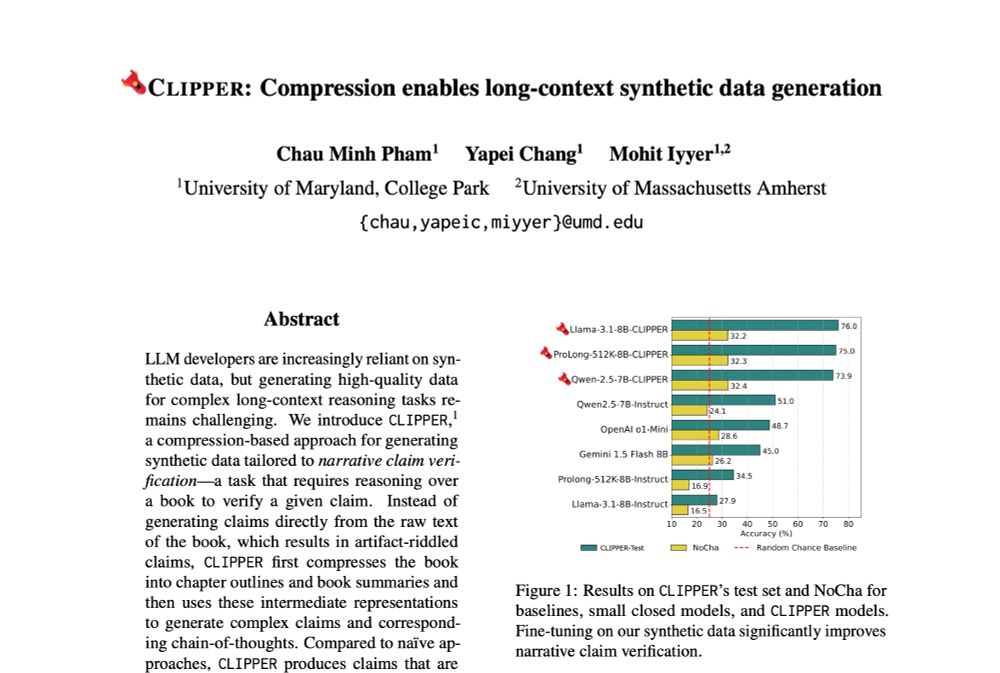
How can we generate synthetic data for a task that requires global reasoning over a long context (e.g., verifying claims about a book)? LLMs aren't good at *solving* such tasks, let alone generating data for them. Check out our paper for a compression-based solution!

⚠️Current methods for generating instruction-following data fall short for long-range reasoning tasks like narrative claim verification.
We present CLIPPER ✂️, a compression-based pipeline that produces grounded instructions for ~$0.5 each, 34x cheaper than human annotations.
We present CLIPPER ✂️, a compression-based pipeline that produces grounded instructions for ~$0.5 each, 34x cheaper than human annotations.
February 21, 2025 at 4:37 PM
How can we generate synthetic data for a task that requires global reasoning over a long context (e.g., verifying claims about a book)? LLMs aren't good at *solving* such tasks, let alone generating data for them. Check out our paper for a compression-based solution!
Reposted by Navita Goyal

This paper is really cool. They decompose NLI (and defeasible NLI) hypotheses into atoms, and then use these atoms to measure the logical consistency of LLMs.
E.g. for an entailment NLI example, each hypothesis atom should also be entailed by the premise.
Very nice idea 👏👏
E.g. for an entailment NLI example, each hypothesis atom should also be entailed by the premise.
Very nice idea 👏👏

February 18, 2025 at 4:14 PM
This paper is really cool. They decompose NLI (and defeasible NLI) hypotheses into atoms, and then use these atoms to measure the logical consistency of LLMs.
E.g. for an entailment NLI example, each hypothesis atom should also be entailed by the premise.
Very nice idea 👏👏
E.g. for an entailment NLI example, each hypothesis atom should also be entailed by the premise.
Very nice idea 👏👏
Reposted by Navita Goyal

Please join us for:
AI at Work: Building and Evaluating Trust
Presented by our Trustworthy AI in Law & Society (TRIALS) institute.
Feb 3-4
Washington DC
Open to all!
Details and registration at: trails.gwu.edu/trailscon-2025
Sponsorship details at: trails.gwu.edu/media/556
AI at Work: Building and Evaluating Trust
Presented by our Trustworthy AI in Law & Society (TRIALS) institute.
Feb 3-4
Washington DC
Open to all!
Details and registration at: trails.gwu.edu/trailscon-2025
Sponsorship details at: trails.gwu.edu/media/556

January 16, 2025 at 3:22 PM
Please join us for:
AI at Work: Building and Evaluating Trust
Presented by our Trustworthy AI in Law & Society (TRIALS) institute.
Feb 3-4
Washington DC
Open to all!
Details and registration at: trails.gwu.edu/trailscon-2025
Sponsorship details at: trails.gwu.edu/media/556
AI at Work: Building and Evaluating Trust
Presented by our Trustworthy AI in Law & Society (TRIALS) institute.
Feb 3-4
Washington DC
Open to all!
Details and registration at: trails.gwu.edu/trailscon-2025
Sponsorship details at: trails.gwu.edu/media/556
Reposted by Navita Goyal
The Impact of Explanations on Fairness in Human-AI Decision-Making: Protected vs Proxy Features
Despite hopes that explanations improve fairness, we see that when biases are hidden behind proxy features, explanations may not help.
Navita Goyal, Connor Baumler +al IUI’24
hal3.name/docs/daume23...
>
Despite hopes that explanations improve fairness, we see that when biases are hidden behind proxy features, explanations may not help.
Navita Goyal, Connor Baumler +al IUI’24
hal3.name/docs/daume23...
>

December 9, 2024 at 11:41 AM
The Impact of Explanations on Fairness in Human-AI Decision-Making: Protected vs Proxy Features
Despite hopes that explanations improve fairness, we see that when biases are hidden behind proxy features, explanations may not help.
Navita Goyal, Connor Baumler +al IUI’24
hal3.name/docs/daume23...
>
Despite hopes that explanations improve fairness, we see that when biases are hidden behind proxy features, explanations may not help.
Navita Goyal, Connor Baumler +al IUI’24
hal3.name/docs/daume23...
>
Reposted by Navita Goyal

This is my first time serving as an AC for a big conference.
Just read this great work by Goyal et al. arxiv.org/abs/2411.11437
I'm optimizing for high coverage and low redundancy—assigning reviewers based on relevant topics or affinity scores alone feels off. Seniority and diversity matter!
Just read this great work by Goyal et al. arxiv.org/abs/2411.11437
I'm optimizing for high coverage and low redundancy—assigning reviewers based on relevant topics or affinity scores alone feels off. Seniority and diversity matter!

Causal Effect of Group Diversity on Redundancy and Coverage in Peer-Reviewing
A large host of scientific journals and conferences solicit peer reviews from multiple reviewers for the same submission, aiming to gather a broader range of perspectives and mitigate individual biase...
arxiv.org
December 5, 2024 at 12:44 AM
This is my first time serving as an AC for a big conference.
Just read this great work by Goyal et al. arxiv.org/abs/2411.11437
I'm optimizing for high coverage and low redundancy—assigning reviewers based on relevant topics or affinity scores alone feels off. Seniority and diversity matter!
Just read this great work by Goyal et al. arxiv.org/abs/2411.11437
I'm optimizing for high coverage and low redundancy—assigning reviewers based on relevant topics or affinity scores alone feels off. Seniority and diversity matter!
Reposted by Navita Goyal
Large Language Models Help Humans Verify Truthfulness—Except When They Are Convincingly Wrong
Should one use chatbots or web search to fact check? Chatbots help more on avg, but people uncritically accept their suggestions much more often.
by Chenglei Si +al NAACL’24
hal3.name/docs/daume24...
>
Should one use chatbots or web search to fact check? Chatbots help more on avg, but people uncritically accept their suggestions much more often.
by Chenglei Si +al NAACL’24
hal3.name/docs/daume24...
>

December 3, 2024 at 9:31 AM
Large Language Models Help Humans Verify Truthfulness—Except When They Are Convincingly Wrong
Should one use chatbots or web search to fact check? Chatbots help more on avg, but people uncritically accept their suggestions much more often.
by Chenglei Si +al NAACL’24
hal3.name/docs/daume24...
>
Should one use chatbots or web search to fact check? Chatbots help more on avg, but people uncritically accept their suggestions much more often.
by Chenglei Si +al NAACL’24
hal3.name/docs/daume24...
>