




Nathaniel Haines
@natehaines.bsky.social
Paid to do
p(b | a) p(a)
p(a | b) = —————————
p(b)
Data Scientist | Computational Psychologist | Devout Bayesian
https://bayesianbeginnings.com/
p(b | a) p(a)
p(a | b) = —————————
p(b)
Data Scientist | Computational Psychologist | Devout Bayesian
https://bayesianbeginnings.com/
SIX YEARS after the initial blog post, this paper is finally published.. what a wild ride
- the blog: bit.ly/3GbOqQa
- original tweet thread: x.com/Nate__Haines...
- published (open access) paper: doi.org/10.1037/met0...
- the blog: bit.ly/3GbOqQa
- original tweet thread: x.com/Nate__Haines...
- published (open access) paper: doi.org/10.1037/met0...

April 17, 2025 at 1:22 PM
SIX YEARS after the initial blog post, this paper is finally published.. what a wild ride
- the blog: bit.ly/3GbOqQa
- original tweet thread: x.com/Nate__Haines...
- published (open access) paper: doi.org/10.1037/met0...
- the blog: bit.ly/3GbOqQa
- original tweet thread: x.com/Nate__Haines...
- published (open access) paper: doi.org/10.1037/met0...
My read is quite different, e.g. www.sciencedirect.com/science/arti...

April 7, 2025 at 11:53 PM
My read is quite different, e.g. www.sciencedirect.com/science/arti...
Ah yeah this form of probability distortion is generally attributed to Goldstein & Einhorn (1987). e.g. see eq ~23
sci-hub.se/https://psyc...
sci-hub.se/https://psyc...

April 6, 2025 at 4:00 PM
Ah yeah this form of probability distortion is generally attributed to Goldstein & Einhorn (1987). e.g. see eq ~23
sci-hub.se/https://psyc...
sci-hub.se/https://psyc...
I mean snipping the quote like that is a bit misleading ..
there are of course many different ways that noise could arise. the two models have different implications re mechanisms, but the data I had available were not able to distinguish between them
there are of course many different ways that noise could arise. the two models have different implications re mechanisms, but the data I had available were not able to distinguish between them

April 6, 2025 at 3:31 PM
I mean snipping the quote like that is a bit misleading ..
there are of course many different ways that noise could arise. the two models have different implications re mechanisms, but the data I had available were not able to distinguish between them
there are of course many different ways that noise could arise. the two models have different implications re mechanisms, but the data I had available were not able to distinguish between them

My team at Ledger just released `bermuda`, an open-source library for insurance triangle data manipulation! Check out the repo and docs below to see if it would be useful for your own work:
GitHub: github.com/LedgerInvest...
Docs: ledger-investing-bermuda-ledger.readthedocs-hosted.com/en/latest/
GitHub: github.com/LedgerInvest...
Docs: ledger-investing-bermuda-ledger.readthedocs-hosted.com/en/latest/

March 4, 2025 at 6:48 PM
My team at Ledger just released `bermuda`, an open-source library for insurance triangle data manipulation! Check out the repo and docs below to see if it would be useful for your own work:
GitHub: github.com/LedgerInvest...
Docs: ledger-investing-bermuda-ledger.readthedocs-hosted.com/en/latest/
GitHub: github.com/LedgerInvest...
Docs: ledger-investing-bermuda-ledger.readthedocs-hosted.com/en/latest/

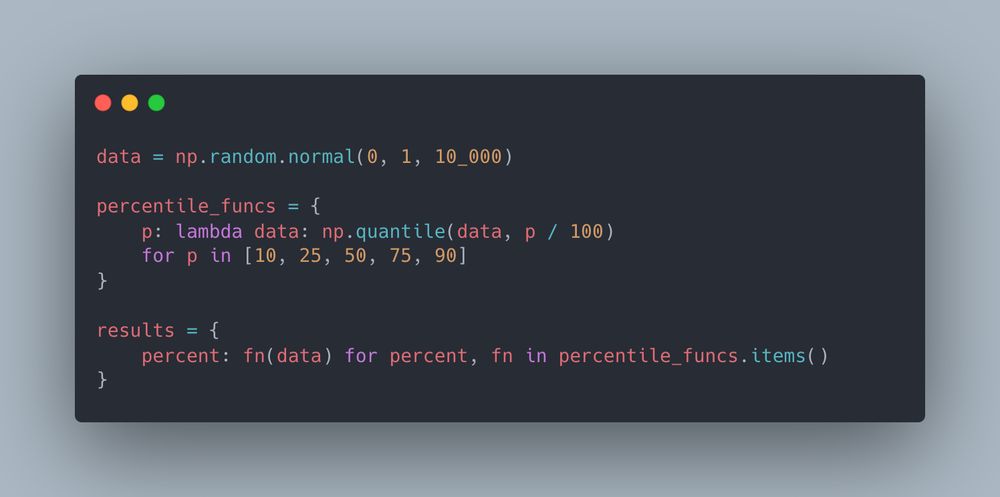
time for a valentines day pop-quiz! without cheating, what will the output of `results` look like?
February 14, 2025 at 8:14 PM
time for a valentines day pop-quiz! without cheating, what will the output of `results` look like?
np! the normal (as opposed to logistic) variant is then below, which is also used in signal detection theory (and my Dunning-Kruger effect blog 🤓)
haines-lab.com/post/2021-01...
haines-lab.com/post/2021-01...

February 13, 2025 at 7:24 PM
np! the normal (as opposed to logistic) variant is then below, which is also used in signal detection theory (and my Dunning-Kruger effect blog 🤓)
haines-lab.com/post/2021-01...
haines-lab.com/post/2021-01...
Yes it's specifically the discrimination parameters, e.g. "a" in the 2PL model in the image below:

February 13, 2025 at 5:21 PM
Yes it's specifically the discrimination parameters, e.g. "a" in the 2PL model in the image below:
In a funny turn of events, I have come to disagree with one of Paul Meehl's greatest pieces. After spending a couple years in the insurance industry, I can confidently say that actuaries use just as much subjective judgement as clinicians 🤖


January 7, 2025 at 7:02 PM
In a funny turn of events, I have come to disagree with one of Paul Meehl's greatest pieces. After spending a couple years in the insurance industry, I can confidently say that actuaries use just as much subjective judgement as clinicians 🤖

7/N Finally, in Part 2, we develop an algorithm for item reduction that uses our various metrics. We simulate data from 500 people and 100 items, then perform item reduction to just 15 items. Results show that the Bayes factor method is best able to recover the true trait values:

January 1, 2025 at 5:06 PM
7/N Finally, in Part 2, we develop an algorithm for item reduction that uses our various metrics. We simulate data from 500 people and 100 items, then perform item reduction to just 15 items. Results show that the Bayes factor method is best able to recover the true trait values:
6/N In come Bayes factors! Bayes factors can be used to tell us how informative an item (or set of items is) in relation to the true underlying trait level we aim to measure, akin to what we get with the more basic alpha measure. They also do a good job accounting for redundancy


January 1, 2025 at 5:06 PM
6/N In come Bayes factors! Bayes factors can be used to tell us how informative an item (or set of items is) in relation to the true underlying trait level we aim to measure, akin to what we get with the more basic alpha measure. They also do a good job accounting for redundancy
5/N Of course, K-L divergence also has issues! Although it does a good job capturing informativeness, it does not do a great job capturing the direction of informativeness. Ideally, we want our metric to capture how informative our items are wrt the latent trait of interest 🤓

January 1, 2025 at 5:06 PM
5/N Of course, K-L divergence also has issues! Although it does a good job capturing informativeness, it does not do a great job capturing the direction of informativeness. Ideally, we want our metric to capture how informative our items are wrt the latent trait of interest 🤓
4/N However, Fisher information has shortcomings too—a big one being that it does a bad job accounting for redundant information across items. Therefore, we shift our perspective a bit (going Bayesian 🤪) and look into K-L divergence as an alternative measure of item information


January 1, 2025 at 5:06 PM
4/N However, Fisher information has shortcomings too—a big one being that it does a bad job accounting for redundant information across items. Therefore, we shift our perspective a bit (going Bayesian 🤪) and look into K-L divergence as an alternative measure of item information
3/N We then discuss how Fisher information allows us to view item information more holistically, with an emphasis on how different items are more-or-less informative for different people. We compare Fisher information to alpha to see what more it offers:

January 1, 2025 at 5:06 PM
3/N We then discuss how Fisher information allows us to view item information more holistically, with an emphasis on how different items are more-or-less informative for different people. We compare Fisher information to alpha to see what more it offers:
2/N In Part 1, we walk through each of the above metrics in detail, starting with good ole' Cronbach's alpha. Of course, a good blog post would not be complete without some drama, so we get into why iterative item selection with alpha (alpha-hacking as I call it) is not ideal..

January 1, 2025 at 5:06 PM
2/N In Part 1, we walk through each of the above metrics in detail, starting with good ole' Cronbach's alpha. Of course, a good blog post would not be complete without some drama, so we get into why iterative item selection with alpha (alpha-hacking as I call it) is not ideal..
1/N Some New Years reading to share! In this post, we dive into Cronbach's alpha, Fisher info, KL divergence, and Bayes factors as measures of item informativeness. We then use these metrics to reduce a large 100 item pool down to just 15 items while maximizing information 🤖

January 1, 2025 at 5:06 PM
1/N Some New Years reading to share! In this post, we dive into Cronbach's alpha, Fisher info, KL divergence, and Bayes factors as measures of item informativeness. We then use these metrics to reduce a large 100 item pool down to just 15 items while maximizing information 🤖


November 25, 2024 at 1:59 PM
While we are on the subject of fraudulent data and broken data processing + analysis lineage... check out my blog out how to use renv, Docker, and GitHub Actions to automate building computationally reproducible R projects!
haines-lab.com/post/2022-01...
haines-lab.com/post/2022-01...

November 20, 2024 at 10:01 PM
While we are on the subject of fraudulent data and broken data processing + analysis lineage... check out my blog out how to use renv, Docker, and GitHub Actions to automate building computationally reproducible R projects!
haines-lab.com/post/2022-01...
haines-lab.com/post/2022-01...

PyData NYC 2024 was a success! One of the most enjoyable conferences I've attended—learned a ton, and got to meet and hang out with some cool people. My talk was recorded, so look out for a post on that in coming weeks! 🤓
nyc2024.pydata.org/cfp/talk/WAW...
nyc2024.pydata.org/cfp/talk/WAW...




November 15, 2024 at 12:24 PM
PyData NYC 2024 was a success! One of the most enjoyable conferences I've attended—learned a ton, and got to meet and hang out with some cool people. My talk was recorded, so look out for a post on that in coming weeks! 🤓
nyc2024.pydata.org/cfp/talk/WAW...
nyc2024.pydata.org/cfp/talk/WAW...