



Mohammed Hamdy
@mmhamdy.bsky.social
A curious explorer of human and machine learning 🧐 🤝🤖
Pinned
Mohammed Hamdy
@mmhamdy.bsky.social
· Dec 19

✨ Excited to share our latest work from The Data Provenance Initiative ☸️
This is the most comprehensive audit of multimodal training data, auditing ~4000 datasets between 1990 and 2024, and covering more than 400 unique tasks in 608 languages!
🧵 1/n
This is the most comprehensive audit of multimodal training data, auditing ~4000 datasets between 1990 and 2024, and covering more than 400 unique tasks in 608 languages!
🧵 1/n
Ok, I'll confess! I too like Roland Emmerich's Godzilla. I even like the creature design in this film!

Sorry, I know it's heresy! But I liked the Matthew Broderick Godzilla. She was fast and motivated and lovely... and vulnerable! And therefor reliant on her speed & wits and much more poignant when she died. So, the others breathe fire and nukes bounce off? zzzz
www.youtube.com/watch?v=ei0A...
www.youtube.com/watch?v=ei0A...

Blowing Up Madison Square Garden | GODZILLA | Matthew Broderick, Jean Reno
YouTube video by FilmIsNow Epic Scenes
www.youtube.com
June 8, 2025 at 6:37 PM
Ok, I'll confess! I too like Roland Emmerich's Godzilla. I even like the creature design in this film!




June 2, 2025 at 8:11 PM
The Consciousness API: What if consciousness isn't contained within us, but rather we are temporary antennas, tuning into a vast, universal broadcast of awareness?
May 31, 2025 at 2:56 PM
The Consciousness API: What if consciousness isn't contained within us, but rather we are temporary antennas, tuning into a vast, universal broadcast of awareness?
In this article, I explore the story behind some of the ideas introduced in the Transformer paper.
Exploring things from the fundamental attention mechanism that lies at its heart to the surprisingly simple explanation for its name.
You may find it interesting! 🙂
👇link below
Exploring things from the fundamental attention mechanism that lies at its heart to the surprisingly simple explanation for its name.
You may find it interesting! 🙂
👇link below

March 30, 2025 at 11:38 AM
In this article, I explore the story behind some of the ideas introduced in the Transformer paper.
Exploring things from the fundamental attention mechanism that lies at its heart to the surprisingly simple explanation for its name.
You may find it interesting! 🙂
👇link below
Exploring things from the fundamental attention mechanism that lies at its heart to the surprisingly simple explanation for its name.
You may find it interesting! 🙂
👇link below
Reposted by Mohammed Hamdy

We're particularly proud to release Aya Vision 8B - it's compact 🐭 and efficient 🐎, outperforming models up to 11x its size 📈.
Releasing open weights helps to make breakthroughs in VLMs accessible to the research community.
Releasing open weights helps to make breakthroughs in VLMs accessible to the research community.

March 5, 2025 at 5:56 PM
We're particularly proud to release Aya Vision 8B - it's compact 🐭 and efficient 🐎, outperforming models up to 11x its size 📈.
Releasing open weights helps to make breakthroughs in VLMs accessible to the research community.
Releasing open weights helps to make breakthroughs in VLMs accessible to the research community.
🧬 Join us this Wednesday on @mozilla.ai discord server in our second session of the Biological Representation Learning series where we discuss landmark papers in the field!
We will be presenting the ProGen protein language model paper from Salesforce. See you there! 😃
We will be presenting the ProGen protein language model paper from Salesforce. See you there! 😃

January 27, 2025 at 12:29 PM
🧬 Join us this Wednesday on @mozilla.ai discord server in our second session of the Biological Representation Learning series where we discuss landmark papers in the field!
We will be presenting the ProGen protein language model paper from Salesforce. See you there! 😃
We will be presenting the ProGen protein language model paper from Salesforce. See you there! 😃
Reposted by Mohammed Hamdy

📢 Join us on Discord for our first Blueprints Hub event 📢
Discover Blueprints and learn how to transform text into podcast-style conversations using entirely open source tools.
🗓️ Wednesday, Jan. 22nd
⏰ 1:30-2:00 PM EST
🔗 Event: discord.gg/BaYFBaeh?eve...
#OpenSource #AI #Blueprints #MozillaAI
Discover Blueprints and learn how to transform text into podcast-style conversations using entirely open source tools.
🗓️ Wednesday, Jan. 22nd
⏰ 1:30-2:00 PM EST
🔗 Event: discord.gg/BaYFBaeh?eve...
#OpenSource #AI #Blueprints #MozillaAI
Join the Mozilla AI Discord Server!
A global space for sharing and advancing open-source AI. | 3695 members
discord.gg
January 20, 2025 at 12:15 PM
📢 Join us on Discord for our first Blueprints Hub event 📢
Discover Blueprints and learn how to transform text into podcast-style conversations using entirely open source tools.
🗓️ Wednesday, Jan. 22nd
⏰ 1:30-2:00 PM EST
🔗 Event: discord.gg/BaYFBaeh?eve...
#OpenSource #AI #Blueprints #MozillaAI
Discover Blueprints and learn how to transform text into podcast-style conversations using entirely open source tools.
🗓️ Wednesday, Jan. 22nd
⏰ 1:30-2:00 PM EST
🔗 Event: discord.gg/BaYFBaeh?eve...
#OpenSource #AI #Blueprints #MozillaAI
Reposted by Mohammed Hamdy

As the @cohereforai.bsky.social joins the Bluesky family — we will be sharing paper gems from when we first started as a lab.
This paper is part of a larger research agenda where we have focused on how to better represent the long tail = making AI work for almost all real world distributions.
This paper is part of a larger research agenda where we have focused on how to better represent the long tail = making AI work for almost all real world distributions.
How can we mitigate the disparate effect of compression 🗜️on model performance for low-resource languages 💬?
Check out our cross-institutional collaboration discusses intriguing & previously unknown generalisation properties of compression.
📜Learn more: arxiv.org/abs/2211.02738
Check out our cross-institutional collaboration discusses intriguing & previously unknown generalisation properties of compression.
📜Learn more: arxiv.org/abs/2211.02738

January 18, 2025 at 4:57 AM
As the @cohereforai.bsky.social joins the Bluesky family — we will be sharing paper gems from when we first started as a lab.
This paper is part of a larger research agenda where we have focused on how to better represent the long tail = making AI work for almost all real world distributions.
This paper is part of a larger research agenda where we have focused on how to better represent the long tail = making AI work for almost all real world distributions.
Reposted by Mohammed Hamdy

Meet Helium-1 preview, our 2B multi-lingual LLM, targeting edge and mobile devices, released under a CC-BY license. Start building with it today!
huggingface.co/kyutai/heliu...
huggingface.co/kyutai/heliu...

kyutai/helium-1-preview-2b · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
January 13, 2025 at 5:50 PM
Meet Helium-1 preview, our 2B multi-lingual LLM, targeting edge and mobile devices, released under a CC-BY license. Start building with it today!
huggingface.co/kyutai/heliu...
huggingface.co/kyutai/heliu...
✨ Excited to share our latest work from The Data Provenance Initiative ☸️
This is the most comprehensive audit of multimodal training data, auditing ~4000 datasets between 1990 and 2024, and covering more than 400 unique tasks in 608 languages!
🧵 1/n
This is the most comprehensive audit of multimodal training data, auditing ~4000 datasets between 1990 and 2024, and covering more than 400 unique tasks in 608 languages!
🧵 1/n
December 19, 2024 at 4:34 PM
✨ Excited to share our latest work from The Data Provenance Initiative ☸️
This is the most comprehensive audit of multimodal training data, auditing ~4000 datasets between 1990 and 2024, and covering more than 400 unique tasks in 608 languages!
🧵 1/n
This is the most comprehensive audit of multimodal training data, auditing ~4000 datasets between 1990 and 2024, and covering more than 400 unique tasks in 608 languages!
🧵 1/n
Reposted by Mohammed Hamdy

🌟 500! 🌟
Our Community Computer Vision Course Repo just reached 500 stars on GitHub: github.com/johko/comput... 🤩
I'm really proud of all the amazing content people from the community have contributed here and that they still keep on adding very cool and helpful material 💪
Our Community Computer Vision Course Repo just reached 500 stars on GitHub: github.com/johko/comput... 🤩
I'm really proud of all the amazing content people from the community have contributed here and that they still keep on adding very cool and helpful material 💪

GitHub - johko/computer-vision-course: This repo is the homebase of a community driven course on Computer Vision with Neural Networks. Feel free to join us on the Hugging Face discord: hf.co/join/disc...
This repo is the homebase of a community driven course on Computer Vision with Neural Networks. Feel free to join us on the Hugging Face discord: hf.co/join/discord - johko/computer-vision-course
github.com
December 1, 2024 at 8:41 PM
🌟 500! 🌟
Our Community Computer Vision Course Repo just reached 500 stars on GitHub: github.com/johko/comput... 🤩
I'm really proud of all the amazing content people from the community have contributed here and that they still keep on adding very cool and helpful material 💪
Our Community Computer Vision Course Repo just reached 500 stars on GitHub: github.com/johko/comput... 🤩
I'm really proud of all the amazing content people from the community have contributed here and that they still keep on adding very cool and helpful material 💪
The Hudsucker Proxy is the most underrated Coen Brothers film!

November 29, 2024 at 12:26 PM
The Hudsucker Proxy is the most underrated Coen Brothers film!
Funny thought: if "post-training" refers mostly to supervised instruction-tuning and alignment of a "pre-trained" model, then where does the actual "training" happen! 😀
Question — who came up with the term “post-training?” Emerged in the last 12-18 months but I don’t know where from, and I need to know.
🙇
🙇
November 27, 2024 at 3:53 AM
Funny thought: if "post-training" refers mostly to supervised instruction-tuning and alignment of a "pre-trained" model, then where does the actual "training" happen! 😀
Reposted by Mohammed Hamdy

Super excited to announce our best open-source language models yet. OLMo 2.
These instruct models are hot off the press -- finished training with our new RL method this morning and vibes are very good.
These instruct models are hot off the press -- finished training with our new RL method this morning and vibes are very good.

November 26, 2024 at 8:57 PM
Super excited to announce our best open-source language models yet. OLMo 2.
These instruct models are hot off the press -- finished training with our new RL method this morning and vibes are very good.
These instruct models are hot off the press -- finished training with our new RL method this morning and vibes are very good.
Reposted by Mohammed Hamdy

Let's go! We are releasing SmolVLM, a smol 2B VLM built for on-device inference that outperforms all models at similar GPU RAM usage and tokens throughputs.
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!

November 26, 2024 at 3:57 PM
Let's go! We are releasing SmolVLM, a smol 2B VLM built for on-device inference that outperforms all models at similar GPU RAM usage and tokens throughputs.
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!
Reposted by Mohammed Hamdy

A vertical takeoff of life science with #AI LLLMs.
Publication of 10 new foundation models of Proteins, DNA, RNA, methylation, cells, and interactions, evolution, and design in the past couple of weeks!
Unprecedented progress, reviewed in the new Ground Truths
erictopol.substack.com/p/learning-t...
Publication of 10 new foundation models of Proteins, DNA, RNA, methylation, cells, and interactions, evolution, and design in the past couple of weeks!
Unprecedented progress, reviewed in the new Ground Truths
erictopol.substack.com/p/learning-t...

November 24, 2024 at 6:12 PM
A vertical takeoff of life science with #AI LLLMs.
Publication of 10 new foundation models of Proteins, DNA, RNA, methylation, cells, and interactions, evolution, and design in the past couple of weeks!
Unprecedented progress, reviewed in the new Ground Truths
erictopol.substack.com/p/learning-t...
Publication of 10 new foundation models of Proteins, DNA, RNA, methylation, cells, and interactions, evolution, and design in the past couple of weeks!
Unprecedented progress, reviewed in the new Ground Truths
erictopol.substack.com/p/learning-t...
A Data-centric AI starter pack (Needless to say, this is by no means exhaustive). Please feel free to mention anyone I've missed in this list and I will update it.
go.bsky.app/SNj7M2Y
go.bsky.app/SNj7M2Y
November 25, 2024 at 1:23 AM
A Data-centric AI starter pack (Needless to say, this is by no means exhaustive). Please feel free to mention anyone I've missed in this list and I will update it.
go.bsky.app/SNj7M2Y
go.bsky.app/SNj7M2Y
Reposted by Mohammed Hamdy

It's Sunday morning so taking a minute for a nerdy thread (on math, tokenizers and LLMs) of the work of our intern Garreth
By adding a few lines of code to the base Llama 3 tokenizer, he got a free boost in arithmetic performance 😮
[thread]
By adding a few lines of code to the base Llama 3 tokenizer, he got a free boost in arithmetic performance 😮
[thread]
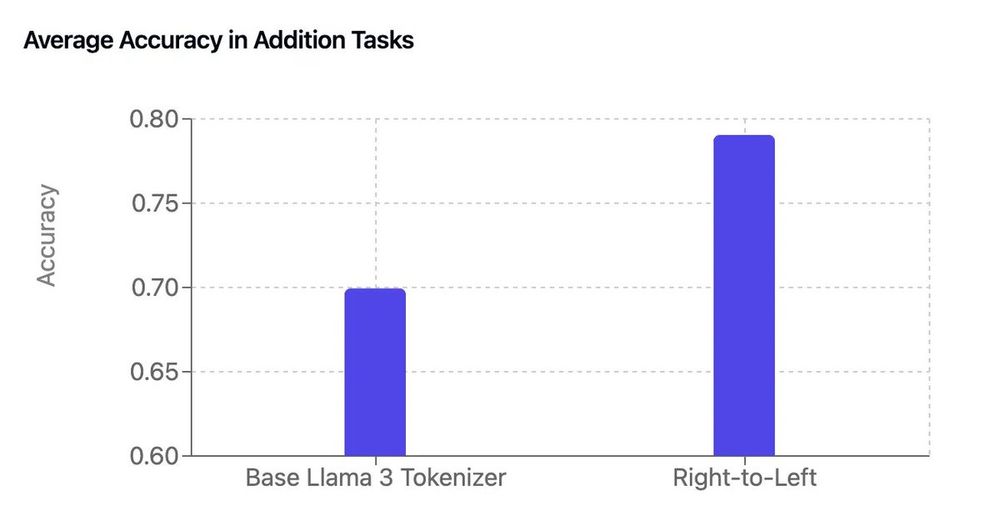
November 24, 2024 at 11:05 AM
It's Sunday morning so taking a minute for a nerdy thread (on math, tokenizers and LLMs) of the work of our intern Garreth
By adding a few lines of code to the base Llama 3 tokenizer, he got a free boost in arithmetic performance 😮
[thread]
By adding a few lines of code to the base Llama 3 tokenizer, he got a free boost in arithmetic performance 😮
[thread]
November 22, 2024 at 9:28 AM
NLP? RL? Why not both?!
arxiv.org/abs/2411.14251
arxiv.org/abs/2411.14251

Natural Language Reinforcement Learning
Reinforcement Learning (RL) mathematically formulates decision-making with Markov Decision Process (MDP). With MDPs, researchers have achieved remarkable breakthroughs across various domains, includin...
arxiv.org
November 22, 2024 at 5:02 AM
NLP? RL? Why not both?!
arxiv.org/abs/2411.14251
arxiv.org/abs/2411.14251
Reposted by Mohammed Hamdy

1/ I work in #NeuroAI, a growing field of research, which many people have only the haziest conception of...
As way of introduction to this research approach, I'll provide here a very short thread outlining the definition of the field I gave recently at our BRAIN NeuroAI workshop at the NIH.
🧠📈
As way of introduction to this research approach, I'll provide here a very short thread outlining the definition of the field I gave recently at our BRAIN NeuroAI workshop at the NIH.
🧠📈
November 21, 2024 at 4:20 PM
1/ I work in #NeuroAI, a growing field of research, which many people have only the haziest conception of...
As way of introduction to this research approach, I'll provide here a very short thread outlining the definition of the field I gave recently at our BRAIN NeuroAI workshop at the NIH.
🧠📈
As way of introduction to this research approach, I'll provide here a very short thread outlining the definition of the field I gave recently at our BRAIN NeuroAI workshop at the NIH.
🧠📈