



micha heilbron
@mheilbron.bsky.social
Assistant Professor of Cognitive AI @UvA Amsterdam
language and vision in brains & machines
cognitive science 🤝 AI 🤝 cognitive neuroscience
michaheilbron.github.io
language and vision in brains & machines
cognitive science 🤝 AI 🤝 cognitive neuroscience
michaheilbron.github.io
However, we then used these models to predict human behaviour
Strikingly these same models that were demonstrably better at the language task, were worse at predicting human reading behaviour
Strikingly these same models that were demonstrably better at the language task, were worse at predicting human reading behaviour
August 18, 2025 at 12:40 PM
However, we then used these models to predict human behaviour
Strikingly these same models that were demonstrably better at the language task, were worse at predicting human reading behaviour
Strikingly these same models that were demonstrably better at the language task, were worse at predicting human reading behaviour
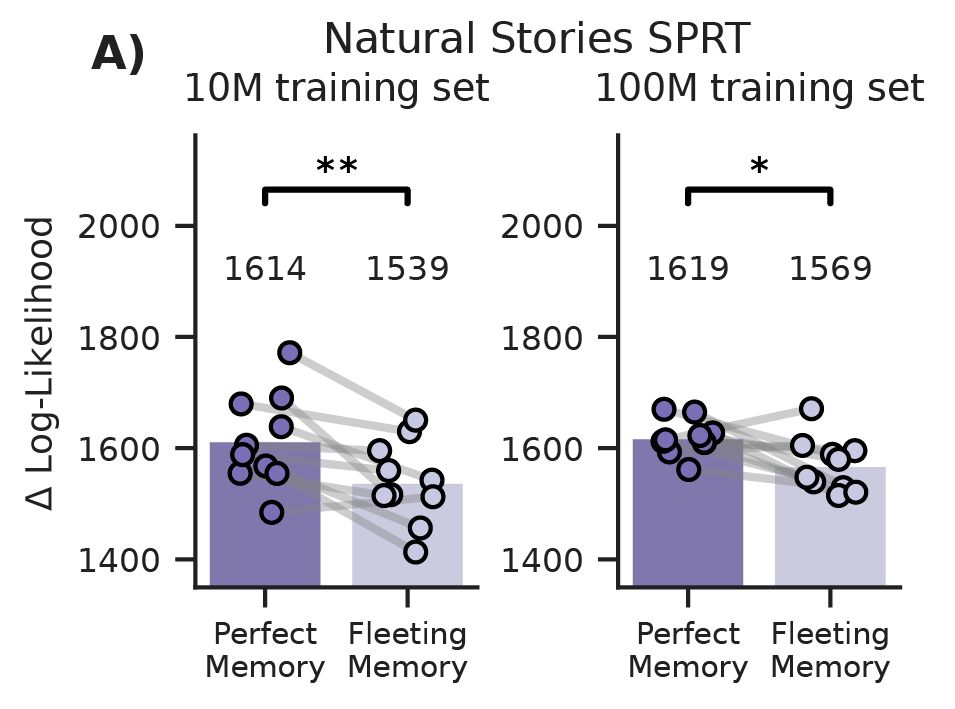
The benefit was robust
Fleeting memory models achieved better next-token prediction (lower loss) and better syntactic knowledge (higher accuracy) on the BLiMP benchmark
This was consistent across seeds and for both 10M and 100M training sets
Fleeting memory models achieved better next-token prediction (lower loss) and better syntactic knowledge (higher accuracy) on the BLiMP benchmark
This was consistent across seeds and for both 10M and 100M training sets

August 18, 2025 at 12:40 PM
The benefit was robust
Fleeting memory models achieved better next-token prediction (lower loss) and better syntactic knowledge (higher accuracy) on the BLiMP benchmark
This was consistent across seeds and for both 10M and 100M training sets
Fleeting memory models achieved better next-token prediction (lower loss) and better syntactic knowledge (higher accuracy) on the BLiMP benchmark
This was consistent across seeds and for both 10M and 100M training sets
But we noticed this naive decay was too strong
Human memory has a brief 'echoic' buffer that perfectly preserves the immediate past. When we added this – a short window of perfect retention before the decay -- the pattern flipped
Now, fleeting memory *helped* (lower loss)
Human memory has a brief 'echoic' buffer that perfectly preserves the immediate past. When we added this – a short window of perfect retention before the decay -- the pattern flipped
Now, fleeting memory *helped* (lower loss)

August 18, 2025 at 12:40 PM
But we noticed this naive decay was too strong
Human memory has a brief 'echoic' buffer that perfectly preserves the immediate past. When we added this – a short window of perfect retention before the decay -- the pattern flipped
Now, fleeting memory *helped* (lower loss)
Human memory has a brief 'echoic' buffer that perfectly preserves the immediate past. When we added this – a short window of perfect retention before the decay -- the pattern flipped
Now, fleeting memory *helped* (lower loss)
Our first attempt, a "naive" memory decay starting from the most recent word, actually *impaired* language learning. Models with this decay had higher validation loss, and this worsened (even higher loss) as the decay became stronger

August 18, 2025 at 12:40 PM
Our first attempt, a "naive" memory decay starting from the most recent word, actually *impaired* language learning. Models with this decay had higher validation loss, and this worsened (even higher loss) as the decay became stronger
To test this in a modern context, we propose the ‘fleeting memory transformer’
We applied a power-law memory decay to the self-attention scores, simulating how access to past words fades over time, and ran controlled experiments on the developmentally realistic BabyLM corpus
We applied a power-law memory decay to the self-attention scores, simulating how access to past words fades over time, and ran controlled experiments on the developmentally realistic BabyLM corpus

August 18, 2025 at 12:40 PM
To test this in a modern context, we propose the ‘fleeting memory transformer’
We applied a power-law memory decay to the self-attention scores, simulating how access to past words fades over time, and ran controlled experiments on the developmentally realistic BabyLM corpus
We applied a power-law memory decay to the self-attention scores, simulating how access to past words fades over time, and ran controlled experiments on the developmentally realistic BabyLM corpus
CCN has arrived here here in Amsterdam!
Come find me to meet or catch up
Some highlights from students and collaborators:
Come find me to meet or catch up
Some highlights from students and collaborators:

August 12, 2025 at 11:14 AM
CCN has arrived here here in Amsterdam!
Come find me to meet or catch up
Some highlights from students and collaborators:
Come find me to meet or catch up
Some highlights from students and collaborators:
Remarkably, these prediction effects appeared independent of recent experience with the specific images presented
This suggests they rely on long-term, ingrained priors about the statistical structure of the visual world, rather than on recent exposure to these specific images
This suggests they rely on long-term, ingrained priors about the statistical structure of the visual world, rather than on recent exposure to these specific images

May 23, 2025 at 11:39 AM
Remarkably, these prediction effects appeared independent of recent experience with the specific images presented
This suggests they rely on long-term, ingrained priors about the statistical structure of the visual world, rather than on recent exposure to these specific images
This suggests they rely on long-term, ingrained priors about the statistical structure of the visual world, rather than on recent exposure to these specific images
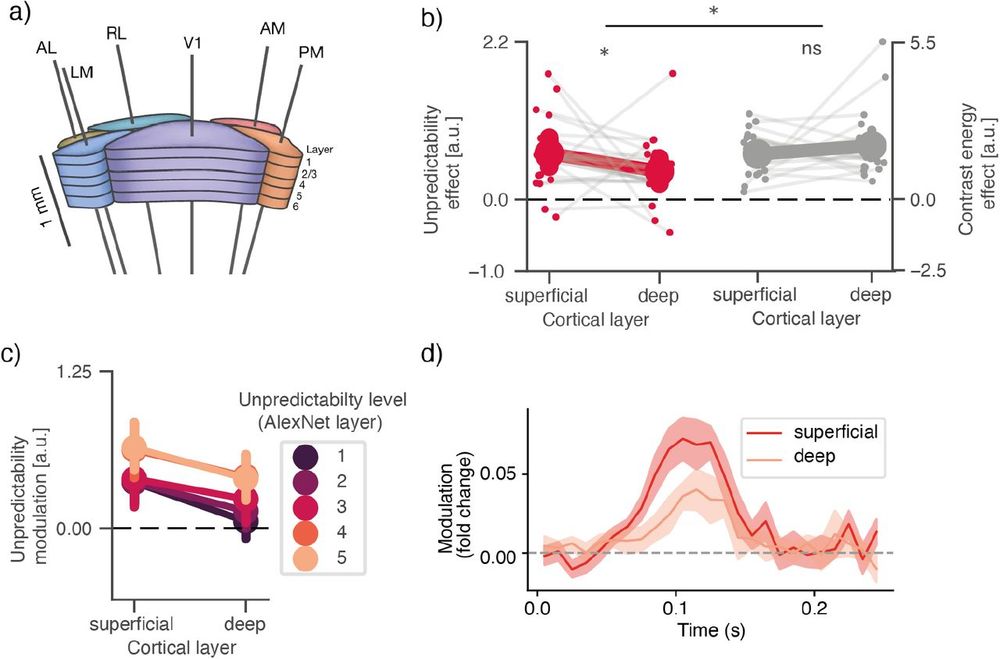
In V1, this sensitivity to unpredictability – presumably a neural marker of prediction error – was stronger in superficial cortical layers
This aligns with hierarchical predictive coding models that postulate that prediction error are computed in superficial layers
This aligns with hierarchical predictive coding models that postulate that prediction error are computed in superficial layers
May 23, 2025 at 11:39 AM
In V1, this sensitivity to unpredictability – presumably a neural marker of prediction error – was stronger in superficial cortical layers
This aligns with hierarchical predictive coding models that postulate that prediction error are computed in superficial layers
This aligns with hierarchical predictive coding models that postulate that prediction error are computed in superficial layers
Like @martinavinck.bsky.social et al, we found a striking dissociation:
Neurons were most sensitive to the *predictability* of high-level visual features (red line), even in areas like V1, most sensitive to low-level visual *features* (blue line)
& this dissociation was found across visual cortex
Neurons were most sensitive to the *predictability* of high-level visual features (red line), even in areas like V1, most sensitive to low-level visual *features* (blue line)
& this dissociation was found across visual cortex

May 23, 2025 at 11:39 AM
Like @martinavinck.bsky.social et al, we found a striking dissociation:
Neurons were most sensitive to the *predictability* of high-level visual features (red line), even in areas like V1, most sensitive to low-level visual *features* (blue line)
& this dissociation was found across visual cortex
Neurons were most sensitive to the *predictability* of high-level visual features (red line), even in areas like V1, most sensitive to low-level visual *features* (blue line)
& this dissociation was found across visual cortex
To understand *what* the visual system is predicting, we quantified unpredictability at multiple levels of abstraction (using CNN layers as a proxy)
This can dissociate predictability of low-level features (e.g. lines/edges) versus higher-level features (e.g., textures, objects)
This can dissociate predictability of low-level features (e.g. lines/edges) versus higher-level features (e.g., textures, objects)

May 23, 2025 at 11:39 AM
To understand *what* the visual system is predicting, we quantified unpredictability at multiple levels of abstraction (using CNN layers as a proxy)
This can dissociate predictability of low-level features (e.g. lines/edges) versus higher-level features (e.g., textures, objects)
This can dissociate predictability of low-level features (e.g. lines/edges) versus higher-level features (e.g., textures, objects)
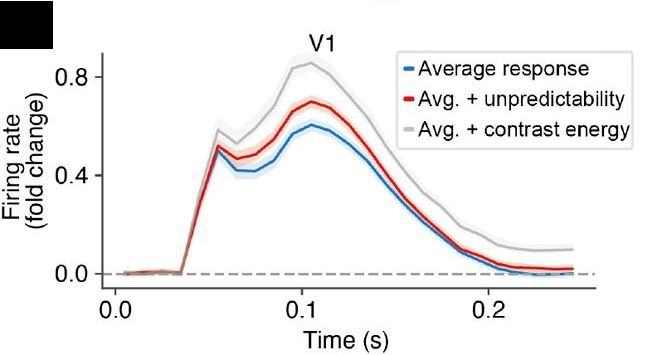
Across visual cortex, we found clear predictability effects: less predictable image patches evoked stronger neural responses
This aligns with core predictive processing ideas (prediction error) and the established literature using controlled designs (expectation suppression)
This aligns with core predictive processing ideas (prediction error) and the established literature using controlled designs (expectation suppression)
May 23, 2025 at 11:39 AM
Across visual cortex, we found clear predictability effects: less predictable image patches evoked stronger neural responses
This aligns with core predictive processing ideas (prediction error) and the established literature using controlled designs (expectation suppression)
This aligns with core predictive processing ideas (prediction error) and the established literature using controlled designs (expectation suppression)
Building on @martinavinck.bsky.social et al., we used deep generative models to quantify how predictable receptive field (RF) patches in images are from their surroundings
We then related these scores to spiking from Allen Institute Neuropixels, controlling for low-level features
We then related these scores to spiking from Allen Institute Neuropixels, controlling for low-level features

May 23, 2025 at 11:39 AM
Building on @martinavinck.bsky.social et al., we used deep generative models to quantify how predictable receptive field (RF) patches in images are from their surroundings
We then related these scores to spiking from Allen Institute Neuropixels, controlling for low-level features
We then related these scores to spiking from Allen Institute Neuropixels, controlling for low-level features



en route to Scotland, visiting universities of Edinburgh and Glasgow tomorrow & Friday.
do reach out if you are around and want to talk language models, brains, or anything in between!
do reach out if you are around and want to talk language models, brains, or anything in between!

March 19, 2025 at 5:15 PM
en route to Scotland, visiting universities of Edinburgh and Glasgow tomorrow & Friday.
do reach out if you are around and want to talk language models, brains, or anything in between!
do reach out if you are around and want to talk language models, brains, or anything in between!
lovely and slightly surreal to be back at Queen Square after all those years, but had a blast talking about generative AI and the predictive brain at the FIL today @peterkok.bsky.social @clarepress.bsky.social

March 19, 2025 at 3:12 PM
lovely and slightly surreal to be back at Queen Square after all those years, but had a blast talking about generative AI and the predictive brain at the FIL today @peterkok.bsky.social @clarepress.bsky.social
If we group variables into “low-level” vs “cognitive”, we find a striking dissociation: for skipping, low-level variables can account for much more unique variation than lexical processing-based explanations, whereas for reading times, it is exactly the other way around

October 2, 2023 at 1:02 PM
If we group variables into “low-level” vs “cognitive”, we find a striking dissociation: for skipping, low-level variables can account for much more unique variation than lexical processing-based explanations, whereas for reading times, it is exactly the other way around
Using set theory, we can then precisely quantify how much overlapping and shared variation is accounted for by each type of explanation

October 2, 2023 at 1:02 PM
Using set theory, we can then precisely quantify how much overlapping and shared variation is accounted for by each type of explanation
We investigated this in three large corpora of natural reading (>1M words).
For each word in the text, we model how much information (in bits) was available at the previous fixation location, from both prediction — p(word | context) — and preview — P(word | preview)
For each word in the text, we model how much information (in bits) was available at the previous fixation location, from both prediction — p(word | context) — and preview — P(word | preview)

October 2, 2023 at 1:01 PM
We investigated this in three large corpora of natural reading (>1M words).
For each word in the text, we model how much information (in bits) was available at the previous fixation location, from both prediction — p(word | context) — and preview — P(word | preview)
For each word in the text, we model how much information (in bits) was available at the previous fixation location, from both prediction — p(word | context) — and preview — P(word | preview)