




Marcel Böhme
@mboehme.bsky.social
Software Security @MPI, PhD @NUS, Dipl.-Inf. @TUDresden.
Research Group: http://mpi-softsec.github.io
Research Group: http://mpi-softsec.github.io
The AI reviewer lists several other items as weaknesses and the corresponding suggestions for improvement. These are summarily deemed to be fixable. Yay!
11/
11/

November 8, 2025 at 7:51 PM
The AI reviewer lists several other items as weaknesses and the corresponding suggestions for improvement. These are summarily deemed to be fixable. Yay!
11/
11/
The fourth weakness is a set of presentation issues. These are helpful but easily fixed.
10/
10/

November 8, 2025 at 7:51 PM
The fourth weakness is a set of presentation issues. These are helpful but easily fixed.
10/
10/
The third weakness is a matter of preference.
Our theorem expresses what (and how efficiently) we can learn about detecting non-zero incoherence given the alg. output: "If after n(δ,ε) samples we detect no disagreement, then incoherence is at most ε with prob. at least 1-δ".
9/
Our theorem expresses what (and how efficiently) we can learn about detecting non-zero incoherence given the alg. output: "If after n(δ,ε) samples we detect no disagreement, then incoherence is at most ε with prob. at least 1-δ".
9/

November 8, 2025 at 7:51 PM
The third weakness is a matter of preference.
Our theorem expresses what (and how efficiently) we can learn about detecting non-zero incoherence given the alg. output: "If after n(δ,ε) samples we detect no disagreement, then incoherence is at most ε with prob. at least 1-δ".
9/
Our theorem expresses what (and how efficiently) we can learn about detecting non-zero incoherence given the alg. output: "If after n(δ,ε) samples we detect no disagreement, then incoherence is at most ε with prob. at least 1-δ".
9/
The second weakness is incorrect.
Our incoherence-based detection reports indeed no false positives: A non-zero incoherence implies a non-zero error, even empirically. To cite the AI reviewer: "If two sampled programs disagree on an input, at least one of them is wrong".
8/
Our incoherence-based detection reports indeed no false positives: A non-zero incoherence implies a non-zero error, even empirically. To cite the AI reviewer: "If two sampled programs disagree on an input, at least one of them is wrong".
8/

November 8, 2025 at 7:51 PM
The second weakness is incorrect.
Our incoherence-based detection reports indeed no false positives: A non-zero incoherence implies a non-zero error, even empirically. To cite the AI reviewer: "If two sampled programs disagree on an input, at least one of them is wrong".
8/
Our incoherence-based detection reports indeed no false positives: A non-zero incoherence implies a non-zero error, even empirically. To cite the AI reviewer: "If two sampled programs disagree on an input, at least one of them is wrong".
8/
Using our own formalization, the AI reviewer literally proposes a fix where we compute pass@1 as the proportion of tasks with non-zero error. Nice!
7/
7/

November 8, 2025 at 7:51 PM
Using our own formalization, the AI reviewer literally proposes a fix where we compute pass@1 as the proportion of tasks with non-zero error. Nice!
7/
7/
The first weakness seems critical. The AI reviewer finds an error in a "key equation".
Nothing reject-worthy: Not a key equation but a remark, and the error is just a typo; e.g., 1-\bar{E}(S,1,1) fixes it.
But YES, the AI reviewer found a bug in our Equation (12). Wow!!
6/
Nothing reject-worthy: Not a key equation but a remark, and the error is just a typo; e.g., 1-\bar{E}(S,1,1) fixes it.
But YES, the AI reviewer found a bug in our Equation (12). Wow!!
6/

November 8, 2025 at 7:51 PM
The first weakness seems critical. The AI reviewer finds an error in a "key equation".
Nothing reject-worthy: Not a key equation but a remark, and the error is just a typo; e.g., 1-\bar{E}(S,1,1) fixes it.
But YES, the AI reviewer found a bug in our Equation (12). Wow!!
6/
Nothing reject-worthy: Not a key equation but a remark, and the error is just a typo; e.g., 1-\bar{E}(S,1,1) fixes it.
But YES, the AI reviewer found a bug in our Equation (12). Wow!!
6/
The three other strengths are also all items that we would consider as important strengths of our paper.
Interestingly, one item (highlighted in blue) is never mentioned in our paper, but something we are now actively pursuing.
4/
Interestingly, one item (highlighted in blue) is never mentioned in our paper, but something we are now actively pursuing.
4/

November 8, 2025 at 7:51 PM
The three other strengths are also all items that we would consider as important strengths of our paper.
Interestingly, one item (highlighted in blue) is never mentioned in our paper, but something we are now actively pursuing.
4/
Interestingly, one item (highlighted in blue) is never mentioned in our paper, but something we are now actively pursuing.
4/
Our AI reviewer establishes 4 strengths. Most human reviewers might have a hard time to establish strengths so succinctly and at this level of details. Great!
Apart from a minor error (no executable semantics needed; only ability to execute), the first strength looks good.
3/
Apart from a minor error (no executable semantics needed; only ability to execute), the first strength looks good.
3/

November 8, 2025 at 7:51 PM
Our AI reviewer establishes 4 strengths. Most human reviewers might have a hard time to establish strengths so succinctly and at this level of details. Great!
Apart from a minor error (no executable semantics needed; only ability to execute), the first strength looks good.
3/
Apart from a minor error (no executable semantics needed; only ability to execute), the first strength looks good.
3/
Let's find out which strengths the AI reviewer establishes for our paper. We'll look at weaknesses (those that get papers rejected) later.
The summary of review definitely hits the nail on the head. We can see motivation and main contributions. Nice!
2/
The summary of review definitely hits the nail on the head. We can see motivation and main contributions. Nice!
2/

November 8, 2025 at 7:51 PM
Let's find out which strengths the AI reviewer establishes for our paper. We'll look at weaknesses (those that get papers rejected) later.
The summary of review definitely hits the nail on the head. We can see motivation and main contributions. Nice!
2/
The summary of review definitely hits the nail on the head. We can see motivation and main contributions. Nice!
2/
🧵 A human review of our AI review at #AAAI26.
📝: arxiv.org/abs/2507.00057
🦋 : bsky.app/profile/did:...
We are off to a good start. While the synopsis misses the motivation (*why* this is interesting), it offers the most important points. Good abstract-length summary.
1/
📝: arxiv.org/abs/2507.00057
🦋 : bsky.app/profile/did:...
We are off to a good start. While the synopsis misses the motivation (*why* this is interesting), it offers the most important points. Good abstract-length summary.
1/

November 8, 2025 at 7:51 PM
🧵 A human review of our AI review at #AAAI26.
📝: arxiv.org/abs/2507.00057
🦋 : bsky.app/profile/did:...
We are off to a good start. While the synopsis misses the motivation (*why* this is interesting), it offers the most important points. Good abstract-length summary.
1/
📝: arxiv.org/abs/2507.00057
🦋 : bsky.app/profile/did:...
We are off to a good start. While the synopsis misses the motivation (*why* this is interesting), it offers the most important points. Good abstract-length summary.
1/
What's most interesting is that we linked pass@1, a common measure of LLM performance, to incoherence and found that a ranking of LLMs using our metric is similar to the same as a pass@1-based ranking which requires some explicit definition of correctness, e.g., manually-provided "golden" programs.

November 8, 2025 at 8:00 AM
What's most interesting is that we linked pass@1, a common measure of LLM performance, to incoherence and found that a ranking of LLMs using our metric is similar to the same as a pass@1-based ranking which requires some explicit definition of correctness, e.g., manually-provided "golden" programs.
Just accepted at #AAAI26 in Singapore: Our paper on estimating the *correctness* of LLM-generated code in the absence of oracles (e.g., a ground-truth implementation).
📝 arxiv.org/abs/2507.00057
with Thomas Valentin (ENS Paris-Saclay), Ardi Madadi, and Gaetano Sapia (#MPI_SP).
📝 arxiv.org/abs/2507.00057
with Thomas Valentin (ENS Paris-Saclay), Ardi Madadi, and Gaetano Sapia (#MPI_SP).

November 8, 2025 at 8:00 AM
Just accepted at #AAAI26 in Singapore: Our paper on estimating the *correctness* of LLM-generated code in the absence of oracles (e.g., a ground-truth implementation).
📝 arxiv.org/abs/2507.00057
with Thomas Valentin (ENS Paris-Saclay), Ardi Madadi, and Gaetano Sapia (#MPI_SP).
📝 arxiv.org/abs/2507.00057
with Thomas Valentin (ENS Paris-Saclay), Ardi Madadi, and Gaetano Sapia (#MPI_SP).
🧗 Manually writing fuzz drivers doesn't scale.
🚩 Auto-generating them gives false positives.
👩💻 Invivo fuzzing requires a user to configure the system and to execute the target.
🤖 Can we substitute the user and auto-generate configuration and executions?
Find out @ gpsapia.github.io/files/ICSE_2...
🚩 Auto-generating them gives false positives.
👩💻 Invivo fuzzing requires a user to configure the system and to execute the target.
🤖 Can we substitute the user and auto-generate configuration and executions?
Find out @ gpsapia.github.io/files/ICSE_2...

November 3, 2025 at 6:24 PM
🧗 Manually writing fuzz drivers doesn't scale.
🚩 Auto-generating them gives false positives.
👩💻 Invivo fuzzing requires a user to configure the system and to execute the target.
🤖 Can we substitute the user and auto-generate configuration and executions?
Find out @ gpsapia.github.io/files/ICSE_2...
🚩 Auto-generating them gives false positives.
👩💻 Invivo fuzzing requires a user to configure the system and to execute the target.
🤖 Can we substitute the user and auto-generate configuration and executions?
Find out @ gpsapia.github.io/files/ICSE_2...
Gaetano's paper on Scaling Security Testing by Adressing the Reachability Gap has been accepted at #ICSE26!
📝 gpsapia.github.io/files/ICSE_2...
🧑💻 github.com/GPSapia/Reac...
How to scale automatic security testing to arbitrary systems?
📝 gpsapia.github.io/files/ICSE_2...
🧑💻 github.com/GPSapia/Reac...
How to scale automatic security testing to arbitrary systems?

November 3, 2025 at 6:24 PM
Gaetano's paper on Scaling Security Testing by Adressing the Reachability Gap has been accepted at #ICSE26!
📝 gpsapia.github.io/files/ICSE_2...
🧑💻 github.com/GPSapia/Reac...
How to scale automatic security testing to arbitrary systems?
📝 gpsapia.github.io/files/ICSE_2...
🧑💻 github.com/GPSapia/Reac...
How to scale automatic security testing to arbitrary systems?
AAAI'26 has been adopting AI reviews in two stages of the review process. I can see that we have to handle the reviewer overload, but I don't think AI reviews are beneficial, at all, for our scientific progress.
If our paper gets accepted at #AAAI26, I will review our AI-generated review here 🤠
If our paper gets accepted at #AAAI26, I will review our AI-generated review here 🤠

October 25, 2025 at 12:18 PM
AAAI'26 has been adopting AI reviews in two stages of the review process. I can see that we have to handle the reviewer overload, but I don't think AI reviews are beneficial, at all, for our scientific progress.
If our paper gets accepted at #AAAI26, I will review our AI-generated review here 🤠
If our paper gets accepted at #AAAI26, I will review our AI-generated review here 🤠
We believe that our probabilistic perspective of correctness for the LLM-generated program as a random variable gives rise to a proliferation of new techniques built for trustworthy code generation with probabilistic guarantees.
Comments and feedback welcome!
Comments and feedback welcome!

July 2, 2025 at 7:30 AM
We believe that our probabilistic perspective of correctness for the LLM-generated program as a random variable gives rise to a proliferation of new techniques built for trustworthy code generation with probabilistic guarantees.
Comments and feedback welcome!
Comments and feedback welcome!
This work on "Estimating Correctness Without Oracles in LLM-Based Code Generation" was led by Thomas Valentin (ENS Paris Saclay) with the generous advice and help from Ardi Madadi (MPI-SP) and Gaetano Sapia (MPI-SP).

July 2, 2025 at 7:30 AM
This work on "Estimating Correctness Without Oracles in LLM-Based Code Generation" was led by Thomas Valentin (ENS Paris Saclay) with the generous advice and help from Ardi Madadi (MPI-SP) and Gaetano Sapia (MPI-SP).
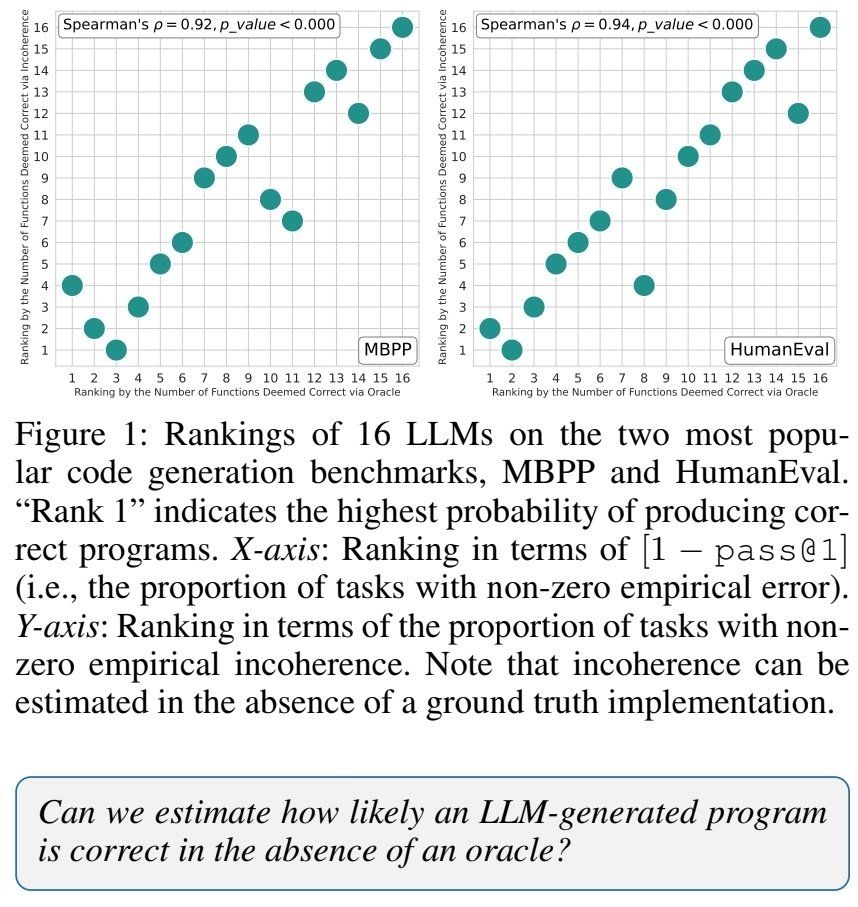
A traditional pass@1 based evaluation of the code generation abilities of LLMs can be reliably substituted with our oracle-less evaluation. This brings substantial benefits. For instance, it removes reliance on human-written oracles (reducing data leakage and overfitting problems).
July 2, 2025 at 7:29 AM
A traditional pass@1 based evaluation of the code generation abilities of LLMs can be reliably substituted with our oracle-less evaluation. This brings substantial benefits. For instance, it removes reliance on human-written oracles (reducing data leakage and overfitting problems).
It's been a lot of fun! Up here in Trondheim the sun never really sets at this time of the year. This is a picture from 9:30pm which feels like an eternal 4pm.
See y'all next year!
See y'all next year!

June 29, 2025 at 7:31 AM
It's been a lot of fun! Up here in Trondheim the sun never really sets at this time of the year. This is a picture from 9:30pm which feels like an eternal 4pm.
See y'all next year!
See y'all next year!
Will Wilson (@AntithesisHQ.bsky.social) talked about the four professional paths with a beautiful historical metaphor from being a member of a guilt (academia) to being a siege engineer (startup founder). He also talked about his efforts at Antithesis to build a deterministic VM for fuzzing.
June 29, 2025 at 7:30 AM
Will Wilson (@AntithesisHQ.bsky.social) talked about the four professional paths with a beautiful historical metaphor from being a member of a guilt (academia) to being a siege engineer (startup founder). He also talked about his efforts at Antithesis to build a deterministic VM for fuzzing.
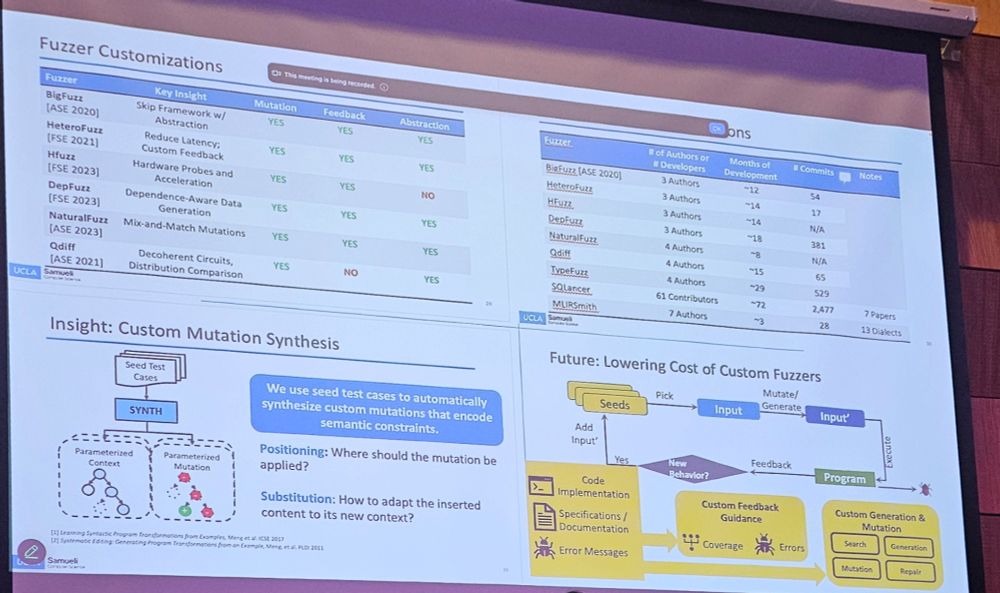
Miryung Kim (UCLA) talked about challenges in domain-specific fuzzing beyond those of general-purpose, including very slow targets (from HW circuits to distributed systems), and her approach to developing domain-specific program transformations, mutation operators, feedback, etc.
June 29, 2025 at 7:29 AM
Miryung Kim (UCLA) talked about challenges in domain-specific fuzzing beyond those of general-purpose, including very slow targets (from HW circuits to distributed systems), and her approach to developing domain-specific program transformations, mutation operators, feedback, etc.
It was great to see the community come together again at our 4th #FUZZING workshop in Trondheim this year! We drew a big crowd. Enjoyed the super lively discussions.
Thanks to the organizers:
* @rohan.padhye.org
* @yannicnoller.bsky.social
* @ruijiemeng.bsky.social and
* László Szekeres (Google)
Thanks to the organizers:
* @rohan.padhye.org
* @yannicnoller.bsky.social
* @ruijiemeng.bsky.social and
* László Szekeres (Google)

June 29, 2025 at 7:25 AM
It was great to see the community come together again at our 4th #FUZZING workshop in Trondheim this year! We drew a big crowd. Enjoyed the super lively discussions.
Thanks to the organizers:
* @rohan.padhye.org
* @yannicnoller.bsky.social
* @ruijiemeng.bsky.social and
* László Szekeres (Google)
Thanks to the organizers:
* @rohan.padhye.org
* @yannicnoller.bsky.social
* @ruijiemeng.bsky.social and
* László Szekeres (Google)
Thrilled to share a recent opinion piece at the IEEE Security and Privacy (Vol. 23, Issue 3).
Basically a long-term perspective on the field meant for both researchers and practitioners.
📝 ieeexplore.ieee.org/stamp/stamp....
Basically a long-term perspective on the field meant for both researchers and practitioners.
📝 ieeexplore.ieee.org/stamp/stamp....

June 19, 2025 at 9:40 AM
Thrilled to share a recent opinion piece at the IEEE Security and Privacy (Vol. 23, Issue 3).
Basically a long-term perspective on the field meant for both researchers and practitioners.
📝 ieeexplore.ieee.org/stamp/stamp....
Basically a long-term perspective on the field meant for both researchers and practitioners.
📝 ieeexplore.ieee.org/stamp/stamp....
My amazing co-chair Lingming Zhang and I, 12 area chairs in 9 areas, and 260 PC members are looking forward to your submissions to the 40th IEEE/ACM International Conference on Automated Software Engineering in Seoul!
📝 conf.researchr.org/track/ase-20... (CfP)
📝 ase25.hotcrp.com/u/0/ (Submission)
📝 conf.researchr.org/track/ase-20... (CfP)
📝 ase25.hotcrp.com/u/0/ (Submission)

May 3, 2025 at 4:54 PM
My amazing co-chair Lingming Zhang and I, 12 area chairs in 9 areas, and 260 PC members are looking forward to your submissions to the 40th IEEE/ACM International Conference on Automated Software Engineering in Seoul!
📝 conf.researchr.org/track/ase-20... (CfP)
📝 ase25.hotcrp.com/u/0/ (Submission)
📝 conf.researchr.org/track/ase-20... (CfP)
📝 ase25.hotcrp.com/u/0/ (Submission)
