




Maziyar PANAHI
@maziyarpanahi.bsky.social
AI x Healthcare | ❤️ #opensource | e/acc 🇫🇷
Follow me on X: https://x.com/MaziyarPanahi
Follow me on X: https://x.com/MaziyarPanahi
coverage includes:
BC4CHEMD,
BC5CDR (chem + disease),
BC2GM,
JNLPBA,
BioNLP 2013 CG,
GELLUS,
FSU,
CLL,
Anatomy (AnatEM),
Linnaeus,
Species‑800,
NCBI‑Disease.
pick a size to match latency/accuracy needs and your deployment constraints.
🧵 (5/6)
BC4CHEMD,
BC5CDR (chem + disease),
BC2GM,
JNLPBA,
BioNLP 2013 CG,
GELLUS,
FSU,
CLL,
Anatomy (AnatEM),
Linnaeus,
Species‑800,
NCBI‑Disease.
pick a size to match latency/accuracy needs and your deployment constraints.
🧵 (5/6)

September 17, 2025 at 2:18 PM
coverage includes:
BC4CHEMD,
BC5CDR (chem + disease),
BC2GM,
JNLPBA,
BioNLP 2013 CG,
GELLUS,
FSU,
CLL,
Anatomy (AnatEM),
Linnaeus,
Species‑800,
NCBI‑Disease.
pick a size to match latency/accuracy needs and your deployment constraints.
🧵 (5/6)
BC4CHEMD,
BC5CDR (chem + disease),
BC2GM,
JNLPBA,
BioNLP 2013 CG,
GELLUS,
FSU,
CLL,
Anatomy (AnatEM),
Linnaeus,
Species‑800,
NCBI‑Disease.
pick a size to match latency/accuracy needs and your deployment constraints.
🧵 (5/6)
what’s in the release: 91 models across sizes (~60M → ~770M; Tiny → XLarge).
domain‑adapted for clinical/biomedical text while keeping flexible zero‑shot behavior.
seamless with gliner and the @hf.co ecosystem.
🧵 (4/6)
domain‑adapted for clinical/biomedical text while keeping flexible zero‑shot behavior.
seamless with gliner and the @hf.co ecosystem.
🧵 (4/6)

September 17, 2025 at 2:18 PM
what’s in the release: 91 models across sizes (~60M → ~770M; Tiny → XLarge).
domain‑adapted for clinical/biomedical text while keeping flexible zero‑shot behavior.
seamless with gliner and the @hf.co ecosystem.
🧵 (4/6)
domain‑adapted for clinical/biomedical text while keeping flexible zero‑shot behavior.
seamless with gliner and the @hf.co ecosystem.
🧵 (4/6)
why zero‑shot?
define labels at inference, no retraining.
go from “disease” to “gene mutation” to “device” by changing the label list.
perfect for shifting schemas across hospitals, projects,
and ontologies without new annotation cycles.
🧵 (3/6)
define labels at inference, no retraining.
go from “disease” to “gene mutation” to “device” by changing the label list.
perfect for shifting schemas across hospitals, projects,
and ontologies without new annotation cycles.
🧵 (3/6)

September 17, 2025 at 2:18 PM
why zero‑shot?
define labels at inference, no retraining.
go from “disease” to “gene mutation” to “device” by changing the label list.
perfect for shifting schemas across hospitals, projects,
and ontologies without new annotation cycles.
🧵 (3/6)
define labels at inference, no retraining.
go from “disease” to “gene mutation” to “device” by changing the label list.
perfect for shifting schemas across hospitals, projects,
and ontologies without new annotation cycles.
🧵 (3/6)
performance snapshot:
across 91 base→fine‑tuned pairs,
average F1 jumps from 0.519 → 0.809 (+0.290, ~80% relative).
consistent gains for chemicals, diseases, anatomy, genes/proteins, and oncology corpora.
🧵 (2/6)
across 91 base→fine‑tuned pairs,
average F1 jumps from 0.519 → 0.809 (+0.290, ~80% relative).
consistent gains for chemicals, diseases, anatomy, genes/proteins, and oncology corpora.
🧵 (2/6)

September 17, 2025 at 2:18 PM
performance snapshot:
across 91 base→fine‑tuned pairs,
average F1 jumps from 0.519 → 0.809 (+0.290, ~80% relative).
consistent gains for chemicals, diseases, anatomy, genes/proteins, and oncology corpora.
🧵 (2/6)
across 91 base→fine‑tuned pairs,
average F1 jumps from 0.519 → 0.809 (+0.290, ~80% relative).
consistent gains for chemicals, diseases, anatomy, genes/proteins, and oncology corpora.
🧵 (2/6)
Introducing 90+ open-source, state‑of‑the‑art biomedical and clinical zero‑shot NER models on @hf.co by OpenMed
Apache‑2.0 licensed and ready to use
Built on GLiNER and covering 12+ biomedical datasets
🧵 (1/6)
Apache‑2.0 licensed and ready to use
Built on GLiNER and covering 12+ biomedical datasets
🧵 (1/6)

September 17, 2025 at 2:18 PM
Introducing 90+ open-source, state‑of‑the‑art biomedical and clinical zero‑shot NER models on @hf.co by OpenMed
Apache‑2.0 licensed and ready to use
Built on GLiNER and covering 12+ biomedical datasets
🧵 (1/6)
Apache‑2.0 licensed and ready to use
Built on GLiNER and covering 12+ biomedical datasets
🧵 (1/6)
welcome GPT-5-Codex
September 17, 2025 at 2:13 PM
welcome GPT-5-Codex
These 380+ models aren't just free, they're top-tier, matching or beating paid options. With sizes from 109M to 568M parameters, they're ready for real-world use.
Plus, they integrate seamlessly with Hugging Face and PyTorch.
Plus, they integrate seamlessly with Hugging Face and PyTorch.

July 21, 2025 at 6:29 PM
These 380+ models aren't just free, they're top-tier, matching or beating paid options. With sizes from 109M to 568M parameters, they're ready for real-world use.
Plus, they integrate seamlessly with Hugging Face and PyTorch.
Plus, they integrate seamlessly with Hugging Face and PyTorch.
Healthcare AI has been locked behind paywalls for too long. Costly licenses and limited access have slowed innovation. OpenMed changes that by making advanced models freely available to everyone. No more barriers, just progress!

July 21, 2025 at 6:29 PM
Healthcare AI has been locked behind paywalls for too long. Costly licenses and limited access have slowed innovation. OpenMed changes that by making advanced models freely available to everyone. No more barriers, just progress!
Yeah, not joking! Bye until you stop treating Devs as your customers instead of partners.

May 7, 2025 at 6:37 PM
Yeah, not joking! Bye until you stop treating Devs as your customers instead of partners.
After 14 years, I'm canceling my Apple Developer membership. I've always believed Apple should pay developers to build apps, not charge them.
iPhone is useless without developers' work. Stop taking money from developers; they already ensure your overpriced devices sell!
iPhone is useless without developers' work. Stop taking money from developers; they already ensure your overpriced devices sell!

May 7, 2025 at 6:37 PM
After 14 years, I'm canceling my Apple Developer membership. I've always believed Apple should pay developers to build apps, not charge them.
iPhone is useless without developers' work. Stop taking money from developers; they already ensure your overpriced devices sell!
iPhone is useless without developers' work. Stop taking money from developers; they already ensure your overpriced devices sell!
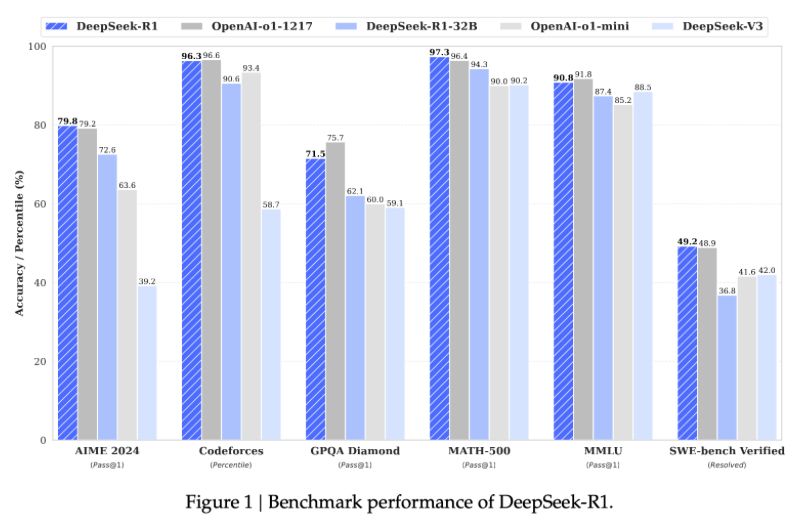
Building reasoning models is no easy feat!
🚀 DeepSeek-R1’s journey highlights key challenges with PRM (Process Reward Models) and MCTS (Monte Carlo Tree Search). From annotation hurdles to scaling limits, the path to scalable AI reasoning is full of learnings.
#AI #ReinforcementLearning #rl
🚀 DeepSeek-R1’s journey highlights key challenges with PRM (Process Reward Models) and MCTS (Monte Carlo Tree Search). From annotation hurdles to scaling limits, the path to scalable AI reasoning is full of learnings.
#AI #ReinforcementLearning #rl
January 20, 2025 at 4:46 PM
Building reasoning models is no easy feat!
🚀 DeepSeek-R1’s journey highlights key challenges with PRM (Process Reward Models) and MCTS (Monte Carlo Tree Search). From annotation hurdles to scaling limits, the path to scalable AI reasoning is full of learnings.
#AI #ReinforcementLearning #rl
🚀 DeepSeek-R1’s journey highlights key challenges with PRM (Process Reward Models) and MCTS (Monte Carlo Tree Search). From annotation hurdles to scaling limits, the path to scalable AI reasoning is full of learnings.
#AI #ReinforcementLearning #rl
Thank you! ☺️ love a strong dollar! 😆

January 16, 2025 at 5:29 PM
Thank you! ☺️ love a strong dollar! 😆
o1 still not compatible with web search is a big problem!

December 19, 2024 at 5:34 PM
o1 still not compatible with web search is a big problem!
What the hell happened to Archer on Netflix_France? Out of 13 seasons we now only have 2! We are not getting anything new, now we are losing old ones we liked. It's time to cancel until there is something to watch.

December 15, 2024 at 1:08 PM
What the hell happened to Archer on Netflix_France? Out of 13 seasons we now only have 2! We are not getting anything new, now we are losing old ones we liked. It's time to cancel until there is something to watch.
It's not the best, but still nice to be able to use VSCode/Cursor over SSH. I rarely run any code on my macbook anymore!

December 7, 2024 at 11:56 AM
It's not the best, but still nice to be able to use VSCode/Cursor over SSH. I rarely run any code on my macbook anymore!
That’s all I’m gonna say!

December 6, 2024 at 12:18 AM
That’s all I’m gonna say!
Who’s playing the new Star Wars Outlaws on PS5?

December 1, 2024 at 10:03 AM
Who’s playing the new Star Wars Outlaws on PS5?
And here I thought Anthropic was adding response styles as features! It turns out it’s just a way to switch to shorter responses to save tokens!

November 27, 2024 at 2:00 PM
And here I thought Anthropic was adding response styles as features! It turns out it’s just a way to switch to shorter responses to save tokens!
Are you kidding me!? Back to JSON I guess! 😅
"Does Prompt Formatting Have Any Impact on LLM Performance?" - arxiv.org/pdf/2411.10541
"Does Prompt Formatting Have Any Impact on LLM Performance?" - arxiv.org/pdf/2411.10541

November 25, 2024 at 10:27 AM
Are you kidding me!? Back to JSON I guess! 😅
"Does Prompt Formatting Have Any Impact on LLM Performance?" - arxiv.org/pdf/2411.10541
"Does Prompt Formatting Have Any Impact on LLM Performance?" - arxiv.org/pdf/2411.10541
Having fun with batch sizes, from bottom to top:
• Gradient steps: 16
• Micro batch size: 4
• Gradient steps: 8
• Micro batch size: 3
• Gradient steps: 16
• Micro batch size: 3
• Gradient steps: 16
• Micro batch size: 4
• Gradient steps: 8
• Micro batch size: 3
• Gradient steps: 16
• Micro batch size: 3

November 21, 2024 at 11:46 AM
Having fun with batch sizes, from bottom to top:
• Gradient steps: 16
• Micro batch size: 4
• Gradient steps: 8
• Micro batch size: 3
• Gradient steps: 16
• Micro batch size: 3
• Gradient steps: 16
• Micro batch size: 4
• Gradient steps: 8
• Micro batch size: 3
• Gradient steps: 16
• Micro batch size: 3
Casual day in Paris! Snow & LLMs! ❄️

November 21, 2024 at 10:16 AM
Casual day in Paris! Snow & LLMs! ❄️
Don't forget the CALME-3 models!🇫🇷🥳
My 3B LLM collection on @huggingface.bsky.social :
• 3 new instruction-tuned models
• 3 French language models (Project Baguette)
• 6 specialized French legal models (LoiLlama & LoiQwen)
• 54M-token French legal synthetic dataset
My 3B LLM collection on @huggingface.bsky.social :
• 3 new instruction-tuned models
• 3 French language models (Project Baguette)
• 6 specialized French legal models (LoiLlama & LoiQwen)
• 54M-token French legal synthetic dataset

November 20, 2024 at 1:59 PM
Don't forget the CALME-3 models!🇫🇷🥳
My 3B LLM collection on @huggingface.bsky.social :
• 3 new instruction-tuned models
• 3 French language models (Project Baguette)
• 6 specialized French legal models (LoiLlama & LoiQwen)
• 54M-token French legal synthetic dataset
My 3B LLM collection on @huggingface.bsky.social :
• 3 new instruction-tuned models
• 3 French language models (Project Baguette)
• 6 specialized French legal models (LoiLlama & LoiQwen)
• 54M-token French legal synthetic dataset
I mean what the actual F! iPhone Mirroring is not available in EU!

November 18, 2024 at 10:13 PM
I mean what the actual F! iPhone Mirroring is not available in EU!
That's how the image_generation tool works behind the scene in Misral LeChat:

November 18, 2024 at 6:37 PM
That's how the image_generation tool works behind the scene in Misral LeChat:
Here is the Web Search with inline citations. (like after each sentence or statement made by the model based on the given context, not just listing references all at once at the end)

November 18, 2024 at 6:36 PM
Here is the Web Search with inline citations. (like after each sentence or statement made by the model based on the given context, not just listing references all at once at the end)