



Max Seitzer
@maxseitzer.bsky.social
Research Scientist in the DINO team at Meta FAIR. Previously: PhD at Max-Planck Institute for Intelligent Systems, Tübingen. Representation learning, agents, structure.
… @timdarcet.bsky.social, Theo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Couprie, @jmairal.bsky.social, Herve Jegou, Patrick Labatut, Piotr Bojanowski
And of course, it’s open source! github.com/facebookrese...
📜 Paper: ai.meta.com/research/pub...
And of course, it’s open source! github.com/facebookrese...
📜 Paper: ai.meta.com/research/pub...

GitHub - facebookresearch/dinov3: Reference PyTorch implementation and models for DINOv3
Reference PyTorch implementation and models for DINOv3 - facebookresearch/dinov3
github.com
August 14, 2025 at 6:52 PM
… @timdarcet.bsky.social, Theo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Couprie, @jmairal.bsky.social, Herve Jegou, Patrick Labatut, Piotr Bojanowski
And of course, it’s open source! github.com/facebookrese...
📜 Paper: ai.meta.com/research/pub...
And of course, it’s open source! github.com/facebookrese...
📜 Paper: ai.meta.com/research/pub...
Immensely proud to have been part of this project. Thank you to the team: @oriane_simeoni, @huyvvo, @baldassarrefe.bsky.social, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michael Ramamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, …

August 14, 2025 at 6:52 PM
Immensely proud to have been part of this project. Thank you to the team: @oriane_simeoni, @huyvvo, @baldassarrefe.bsky.social, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michael Ramamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, …
And here’s my favorite figure from the paper, showing high resolution DINOv3 representations in all their detail-capturing glory ✨

August 14, 2025 at 6:52 PM
And here’s my favorite figure from the paper, showing high resolution DINOv3 representations in all their detail-capturing glory ✨
To recap:
1) The promise of SSL is finally realized, enabling foundation models across domains
2) High quality dense features enabling SotA applications
3) A versatile family of models for diverse deploy scenarios
So many great ideas (Gram anchoring!) to how we got there, please read the paper!
1) The promise of SSL is finally realized, enabling foundation models across domains
2) High quality dense features enabling SotA applications
3) A versatile family of models for diverse deploy scenarios
So many great ideas (Gram anchoring!) to how we got there, please read the paper!

August 14, 2025 at 6:52 PM
To recap:
1) The promise of SSL is finally realized, enabling foundation models across domains
2) High quality dense features enabling SotA applications
3) A versatile family of models for diverse deploy scenarios
So many great ideas (Gram anchoring!) to how we got there, please read the paper!
1) The promise of SSL is finally realized, enabling foundation models across domains
2) High quality dense features enabling SotA applications
3) A versatile family of models for diverse deploy scenarios
So many great ideas (Gram anchoring!) to how we got there, please read the paper!
Satellite you said? Yes, the same DINOv3 algorithm trained on satellite imagery produces a SotA model for geospatial tasks like canopy height estimation. And of course, learns beautiful feature maps. This is the magic of SSL 🪄

August 14, 2025 at 6:52 PM
Satellite you said? Yes, the same DINOv3 algorithm trained on satellite imagery produces a SotA model for geospatial tasks like canopy height estimation. And of course, learns beautiful feature maps. This is the magic of SSL 🪄
3) DINOv3 is a family of models covering all use cases:
• ViT-7B flagship model
• ViT-S/S+/B/L/H+ (21M-840M params)
• ConvNeXt variants for efficient inference
• Text-aligned ViT-L (dino.txt)
• ViT-L/7B for satellite
All inheriting the great dense features of the 7B!
• ViT-7B flagship model
• ViT-S/S+/B/L/H+ (21M-840M params)
• ConvNeXt variants for efficient inference
• Text-aligned ViT-L (dino.txt)
• ViT-L/7B for satellite
All inheriting the great dense features of the 7B!
August 14, 2025 at 6:52 PM
3) DINOv3 is a family of models covering all use cases:
• ViT-7B flagship model
• ViT-S/S+/B/L/H+ (21M-840M params)
• ConvNeXt variants for efficient inference
• Text-aligned ViT-L (dino.txt)
• ViT-L/7B for satellite
All inheriting the great dense features of the 7B!
• ViT-7B flagship model
• ViT-S/S+/B/L/H+ (21M-840M params)
• ConvNeXt variants for efficient inference
• Text-aligned ViT-L (dino.txt)
• ViT-L/7B for satellite
All inheriting the great dense features of the 7B!
Well, Jianyuan Wang of VGGT fame simply dropped DINOv3 into his pipeline and off-handedly got a new SotA 3D model out. Seems promising enough?

August 14, 2025 at 6:52 PM
Well, Jianyuan Wang of VGGT fame simply dropped DINOv3 into his pipeline and off-handedly got a new SotA 3D model out. Seems promising enough?
But what do these great features bring us? We reached SotA on three long-standing vision tasks, simply by building on a frozen ❄️ (!) DINOv3 backbone: detection (66.1 mAP@COCO), segmentation (63 mIoU@ADE), depth (eg 4.3 ARel@NYU). Not convinced yet?
August 14, 2025 at 6:52 PM
But what do these great features bring us? We reached SotA on three long-standing vision tasks, simply by building on a frozen ❄️ (!) DINOv3 backbone: detection (66.1 mAP@COCO), segmentation (63 mIoU@ADE), depth (eg 4.3 ARel@NYU). Not convinced yet?
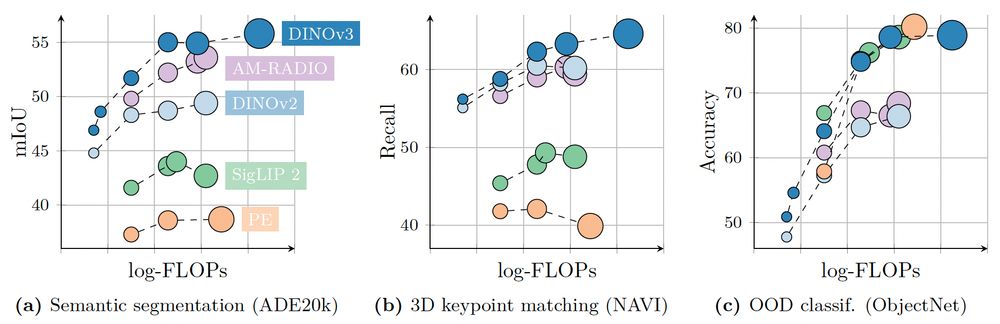
2) DINOv3’s global understanding is strong, but its dense representations truly shine! There’s a clear gap between DINOv3 and prior methods across many tasks. This matters as pretrained dense features power many applications: MLLMs, video&3D understanding, robotics, generative models, …


August 14, 2025 at 6:52 PM
2) DINOv3’s global understanding is strong, but its dense representations truly shine! There’s a clear gap between DINOv3 and prior methods across many tasks. This matters as pretrained dense features power many applications: MLLMs, video&3D understanding, robotics, generative models, …
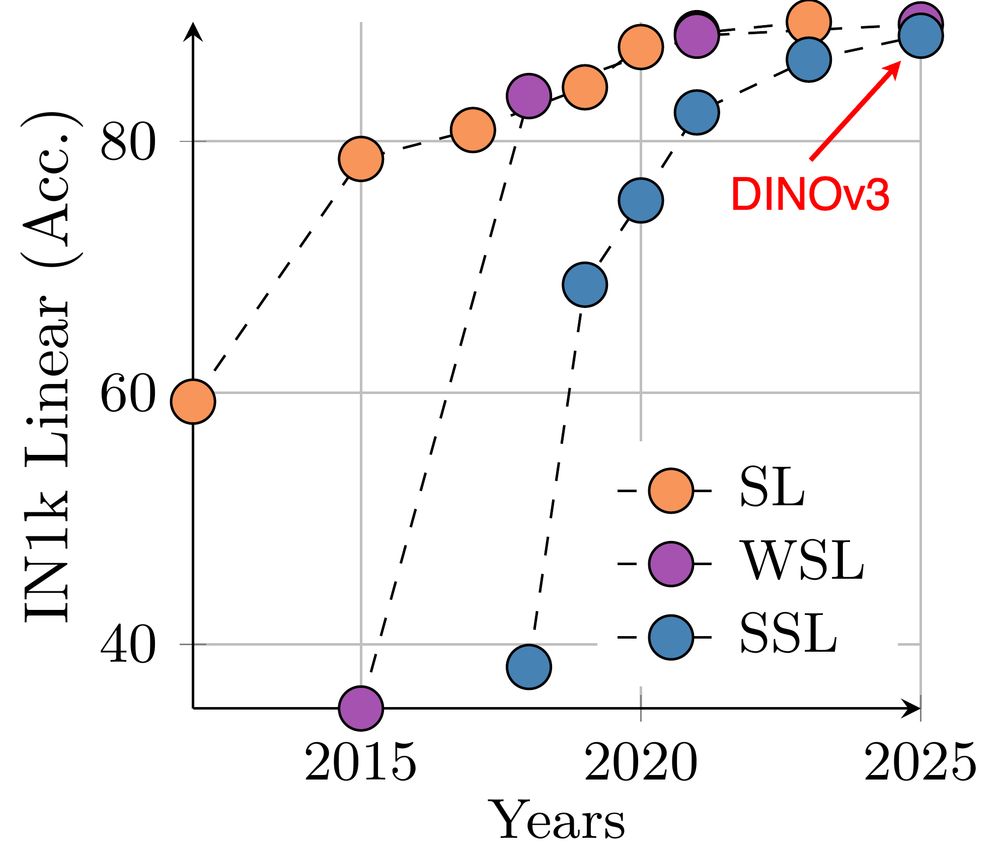
1) Some history: on ImageNet classification, supervised and weakly-supervised models converged to the same plateau over the last years. With DINOv3, SSL finally reaches that level. This alone is a big deal: no more reliance on annotated data!
August 14, 2025 at 6:52 PM
1) Some history: on ImageNet classification, supervised and weakly-supervised models converged to the same plateau over the last years. With DINOv3, SSL finally reaches that level. This alone is a big deal: no more reliance on annotated data!