



Mátyás Schubert
@matyasch.bsky.social
PhD in causal machine learning @amlab.bsky.social
LOAD is already my second work with the team of Tom Claassen and @smaglia.bsky.social 🥳 Check out the details of the paper at arxiv.org/abs/2510.14582 and load optimal adjustment sets without waiting using the publicly available code at github.com/Matyasch/load!

Local Causal Discovery for Statistically Efficient Causal Inference
Causal discovery methods can identify valid adjustment sets for causal effect estimation for a pair of target variables, even when the underlying causal graph is unknown. Global causal discovery metho...
arxiv.org
October 23, 2025 at 3:24 PM
LOAD is already my second work with the team of Tom Claassen and @smaglia.bsky.social 🥳 Check out the details of the paper at arxiv.org/abs/2510.14582 and load optimal adjustment sets without waiting using the publicly available code at github.com/Matyasch/load!
On both synthetic and realistic data LOAD
🏎️is more computationally efficient than global methods, performing close to local methods,
💎recovers high-quality, statistically efficient adjustment sets,
🔮thus enables reliable causal effect estimation even at scale
7/8
🏎️is more computationally efficient than global methods, performing close to local methods,
💎recovers high-quality, statistically efficient adjustment sets,
🔮thus enables reliable causal effect estimation even at scale
7/8


October 23, 2025 at 3:22 PM
On both synthetic and realistic data LOAD
🏎️is more computationally efficient than global methods, performing close to local methods,
💎recovers high-quality, statistically efficient adjustment sets,
🔮thus enables reliable causal effect estimation even at scale
7/8
🏎️is more computationally efficient than global methods, performing close to local methods,
💎recovers high-quality, statistically efficient adjustment sets,
🔮thus enables reliable causal effect estimation even at scale
7/8
LOAD follows 5 steps:
➡Learn causal relations between targets
✅Test identifiability of the effect
🐣Find explicit descendants of treatment
🧩Find mediators
🎯Collect optimal adjustment set
For unidentifiable effects, LOAD exits early and returns locally valid adjustments
6/8
➡Learn causal relations between targets
✅Test identifiability of the effect
🐣Find explicit descendants of treatment
🧩Find mediators
🎯Collect optimal adjustment set
For unidentifiable effects, LOAD exits early and returns locally valid adjustments
6/8
October 23, 2025 at 3:22 PM
LOAD follows 5 steps:
➡Learn causal relations between targets
✅Test identifiability of the effect
🐣Find explicit descendants of treatment
🧩Find mediators
🎯Collect optimal adjustment set
For unidentifiable effects, LOAD exits early and returns locally valid adjustments
6/8
➡Learn causal relations between targets
✅Test identifiability of the effect
🐣Find explicit descendants of treatment
🧩Find mediators
🎯Collect optimal adjustment set
For unidentifiable effects, LOAD exits early and returns locally valid adjustments
6/8
To do this, we develop a sufficient and necessary test for the identifiability of the causal effect of a treatment on an outcome using only local information around the treatment and its siblings, no matter how far the treatment and the outcome are in the causal graph 🔭
5/8
5/8

October 23, 2025 at 3:22 PM
To do this, we develop a sufficient and necessary test for the identifiability of the causal effect of a treatment on an outcome using only local information around the treatment and its siblings, no matter how far the treatment and the outcome are in the causal graph 🔭
5/8
5/8
🎯 Local Optimal Adjustments Discovery (LOAD) does exactly that! It provably finds the same ✨optimal adjustments✨ as global methods, but using much more ⚡computationally efficient⚡ local causal discovery around variables
4/8
4/8
October 23, 2025 at 3:22 PM
🎯 Local Optimal Adjustments Discovery (LOAD) does exactly that! It provably finds the same ✨optimal adjustments✨ as global methods, but using much more ⚡computationally efficient⚡ local causal discovery around variables
4/8
4/8
🌐 Global discovery methods can find optimal adjustment sets, but at a huge computational cost.
📍 Local discovery methods are fast, but can only find sub-optimal adjustment sets.
Can we get the best of both worlds and find optimal adjustment sets from local information?
3/8
📍 Local discovery methods are fast, but can only find sub-optimal adjustment sets.
Can we get the best of both worlds and find optimal adjustment sets from local information?
3/8

October 23, 2025 at 3:21 PM
🌐 Global discovery methods can find optimal adjustment sets, but at a huge computational cost.
📍 Local discovery methods are fast, but can only find sub-optimal adjustment sets.
Can we get the best of both worlds and find optimal adjustment sets from local information?
3/8
📍 Local discovery methods are fast, but can only find sub-optimal adjustment sets.
Can we get the best of both worlds and find optimal adjustment sets from local information?
3/8
While all valid adjustment sets enable unbiased estimation of causal effects, using the optimal adjustment set in terms of asymptotic variance is crucial for reliable causal effect estimation!⚠️
But how to find the optimal adjustment set if the causal graph is not available?
2/8
But how to find the optimal adjustment set if the causal graph is not available?
2/8

October 23, 2025 at 3:21 PM
While all valid adjustment sets enable unbiased estimation of causal effects, using the optimal adjustment set in terms of asymptotic variance is crucial for reliable causal effect estimation!⚠️
But how to find the optimal adjustment set if the causal graph is not available?
2/8
But how to find the optimal adjustment set if the causal graph is not available?
2/8
10/10 SNAP is joint work with a fantastic team of Tom Claassen and @smaglia.bsky.social. Visit our project page on matyasch.github.io/snap/, run SNAP using our publicly available code at github.com/matyasch/snap, and visit to our poster at #aistats2025! 🏖️

Sequential Non-Ancestor Pruning | Matyas Schubert
matyasch.github.io
February 13, 2025 at 2:04 PM
10/10 SNAP is joint work with a fantastic team of Tom Claassen and @smaglia.bsky.social. Visit our project page on matyasch.github.io/snap/, run SNAP using our publicly available code at github.com/matyasch/snap, and visit to our poster at #aistats2025! 🏖️
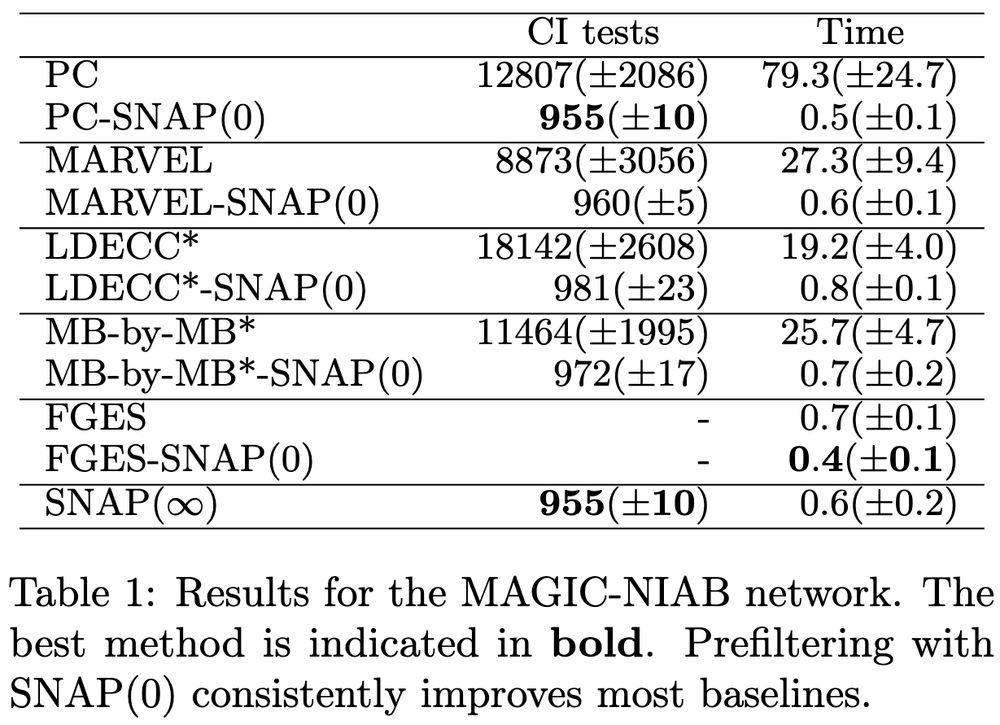
9/10 We also evaluate SNAP on semi-synthetic settings including data generated from the MAGIC-NIAB network, which captures genetic effects and phenotypic interactions 🧬 We see that SNAP greatly reduces the number of CI tests and execution time compared to most baselines.
February 13, 2025 at 2:03 PM
9/10 We also evaluate SNAP on semi-synthetic settings including data generated from the MAGIC-NIAB network, which captures genetic effects and phenotypic interactions 🧬 We see that SNAP greatly reduces the number of CI tests and execution time compared to most baselines.
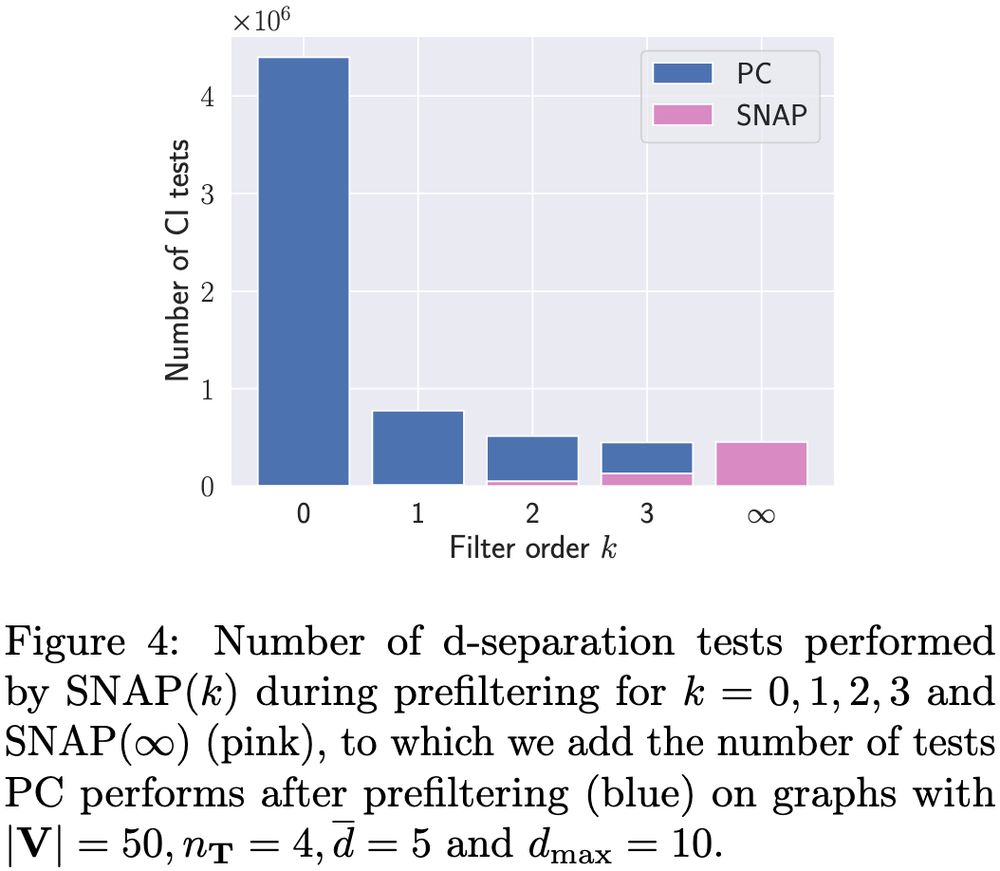
8/10 Many non-ancestors are already identified by marginal tests, enabling prefiltering with SNAP(0) to significantly speed up computation time. Increasing the number of prefiltering iterations k further reduces the number of CI tests needed, especially in dense graphs 🧶

February 13, 2025 at 2:02 PM
8/10 Many non-ancestors are already identified by marginal tests, enabling prefiltering with SNAP(0) to significantly speed up computation time. Increasing the number of prefiltering iterations k further reduces the number of CI tests needed, especially in dense graphs 🧶
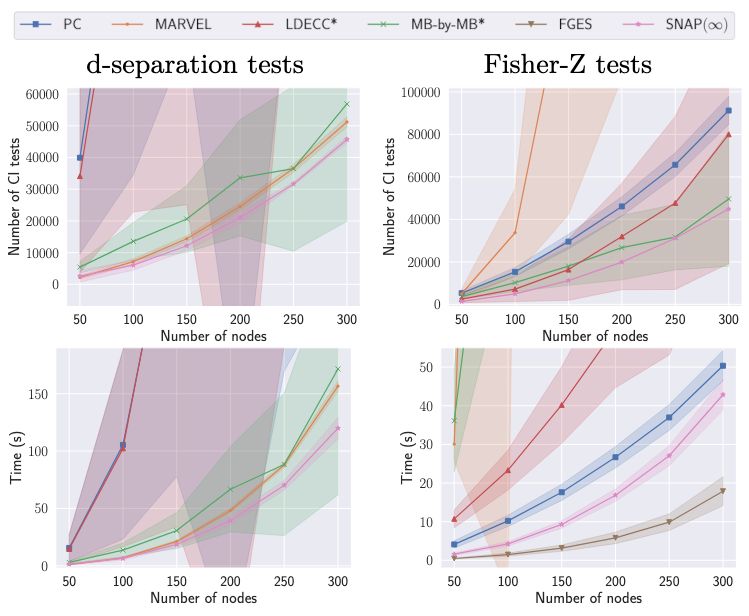
7/10 SNAP(∞) consistently ranks among the best in the number of CI tests and computation time across all domains, while maintaining a comparable intervention distance. In contrast, other methods vary in performance depending on the setting 🚀

February 13, 2025 at 2:02 PM
7/10 SNAP(∞) consistently ranks among the best in the number of CI tests and computation time across all domains, while maintaining a comparable intervention distance. In contrast, other methods vary in performance depending on the setting 🚀
6/10 We can also run SNAP until completion, to obtain a stand-alone causal discovery algorithm, called SNAP(∞). SNAP(∞) is sound and complete over the possible ancestors of targets ✅ Thus, unlike previous work on local causal discovery, it finds efficient adjustment sets.
February 13, 2025 at 2:01 PM
6/10 We can also run SNAP until completion, to obtain a stand-alone causal discovery algorithm, called SNAP(∞). SNAP(∞) is sound and complete over the possible ancestors of targets ✅ Thus, unlike previous work on local causal discovery, it finds efficient adjustment sets.
5/10 SNAP is straightforward to combine with readily available causal discovery algorithms 🧩 We can simply stop it at any maximum iteration k and run another algorithm on the remaining variables. We refer to this approach as prefiltering with SNAP(k).
February 13, 2025 at 2:01 PM
5/10 SNAP is straightforward to combine with readily available causal discovery algorithms 🧩 We can simply stop it at any maximum iteration k and run another algorithm on the remaining variables. We refer to this approach as prefiltering with SNAP(k).
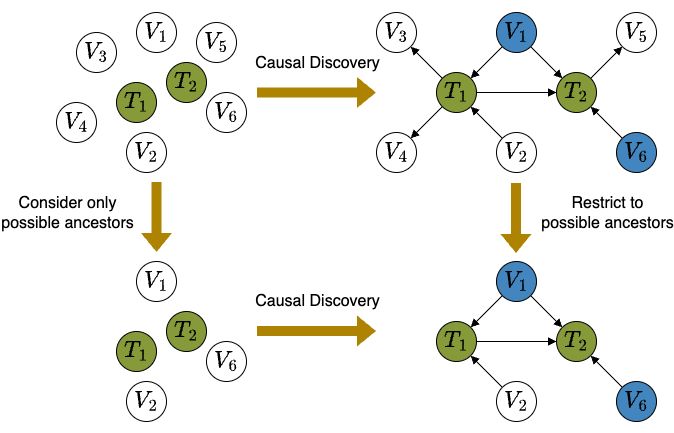
4/10 To solve this task, we show that only possible ancestors of the targets are required to identify their causal relationships and efficient adjustment sets💡 Driven by this, we propose SNAP to progressively prune non-ancestors, leading to much fewer higher order CI tests.
February 13, 2025 at 2:00 PM
4/10 To solve this task, we show that only possible ancestors of the targets are required to identify their causal relationships and efficient adjustment sets💡 Driven by this, we propose SNAP to progressively prune non-ancestors, leading to much fewer higher order CI tests.
3/10 We formalize this as the task of “targeted causal effect estimation with an unknown graph”, which focuses on identifying causal effects between a small set of target variables in a ✨computationally and statistically efficient way✨
February 13, 2025 at 2:00 PM
3/10 We formalize this as the task of “targeted causal effect estimation with an unknown graph”, which focuses on identifying causal effects between a small set of target variables in a ✨computationally and statistically efficient way✨