



Mathurin Massias
@mathurinmassias.bsky.social
Tenured Researcher @INRIA, Ockham team. Teacher @Polytechnique
and @ENSdeLyon
Machine Learning, Python and Optimization
and @ENSdeLyon
Machine Learning, Python and Optimization
To understand these phenomena, we study the spatial regularity of the velocity/denoiser over time: we observe a gap between the closed-form and trained model.
Applying Jacobian regularization, we recover effects seen previously on perturbed denoisers (drift vs noise)
Applying Jacobian regularization, we recover effects seen previously on perturbed denoisers (drift vs noise)

November 5, 2025 at 9:05 AM
To understand these phenomena, we study the spatial regularity of the velocity/denoiser over time: we observe a gap between the closed-form and trained model.
Applying Jacobian regularization, we recover effects seen previously on perturbed denoisers (drift vs noise)
Applying Jacobian regularization, we recover effects seen previously on perturbed denoisers (drift vs noise)
Different loss weightings favor different times: which temporal regime drives the generation quality ? Controlled perturbations reveal: drift type effects at early times (& good FID) and noise type at late times (& bad FID)

November 5, 2025 at 9:05 AM
Different loss weightings favor different times: which temporal regime drives the generation quality ? Controlled perturbations reveal: drift type effects at early times (& good FID) and noise type at late times (& bad FID)
In practice, training a denoiser involves design choices: the parametrization (velocity as in FM, residual Ɛ as in diffusion, or standard denoiser?) and the loss weighting, each influencing the generation quality

November 5, 2025 at 9:04 AM
In practice, training a denoiser involves design choices: the parametrization (velocity as in FM, residual Ɛ as in diffusion, or standard denoiser?) and the loss weighting, each influencing the generation quality
🌀🌀🌀New paper on the generation phases of Flow Matching arxiv.org/abs/2510.24830
Are FM & diffusion models nothing else than denoisers at every noise level?
In theory yes, *if trained optimally*. But in practice, do all noise level equally matter?
with @annegnx.bsky.social, S Martin & R Gribonval
Are FM & diffusion models nothing else than denoisers at every noise level?
In theory yes, *if trained optimally*. But in practice, do all noise level equally matter?
with @annegnx.bsky.social, S Martin & R Gribonval
November 5, 2025 at 9:03 AM
🌀🌀🌀New paper on the generation phases of Flow Matching arxiv.org/abs/2510.24830
Are FM & diffusion models nothing else than denoisers at every noise level?
In theory yes, *if trained optimally*. But in practice, do all noise level equally matter?
with @annegnx.bsky.social, S Martin & R Gribonval
Are FM & diffusion models nothing else than denoisers at every noise level?
In theory yes, *if trained optimally*. But in practice, do all noise level equally matter?
with @annegnx.bsky.social, S Martin & R Gribonval
Strong afternoon session: Ségolène Martin on how to go from flow matching to denoisers (and hopefully come back?) and Claire Boyer on how learning rate and working in latent spaces affect diffusion models


October 24, 2025 at 3:04 PM
Strong afternoon session: Ségolène Martin on how to go from flow matching to denoisers (and hopefully come back?) and Claire Boyer on how learning rate and working in latent spaces affect diffusion models
Followed by Scott Pesme on how to use diffusion/flow matching based MMSE to compute a MAP (and nice examples!), and Thibaut Issenhuth on new ways to learn consistency models
@skate-the-apple.bsky.social
@skate-the-apple.bsky.social


October 24, 2025 at 1:24 PM
Followed by Scott Pesme on how to use diffusion/flow matching based MMSE to compute a MAP (and nice examples!), and Thibaut Issenhuth on new ways to learn consistency models
@skate-the-apple.bsky.social
@skate-the-apple.bsky.social
Next is @annegnx.bsky.social presenting our neurips paper on why flow matching generalizes, while it shouldn't!
arxiv.org/abs/2506.03719
arxiv.org/abs/2506.03719

October 24, 2025 at 9:05 AM
Next is @annegnx.bsky.social presenting our neurips paper on why flow matching generalizes, while it shouldn't!
arxiv.org/abs/2506.03719
arxiv.org/abs/2506.03719
Kickstarting our workshop on Flow matching and Diffusion with a talk by Eric Vanden Eijnden on how to optimize learning and sampling in Stochastic Interpolants!
Broadcast available at gdr-iasis.cnrs.fr/reunions/mod...
Broadcast available at gdr-iasis.cnrs.fr/reunions/mod...


October 24, 2025 at 8:30 AM
Kickstarting our workshop on Flow matching and Diffusion with a talk by Eric Vanden Eijnden on how to optimize learning and sampling in Stochastic Interpolants!
Broadcast available at gdr-iasis.cnrs.fr/reunions/mod...
Broadcast available at gdr-iasis.cnrs.fr/reunions/mod...
on second thoughts I'm not sure I understood. In the classical FM loss you do have to learn this derivative no ? The loss is :

June 27, 2025 at 5:53 AM
on second thoughts I'm not sure I understood. In the classical FM loss you do have to learn this derivative no ? The loss is :
I was thinking of this:

June 27, 2025 at 5:42 AM
I was thinking of this:
Then why does flow matching generalize?? Because it fails!
The inductive bias of the neural network prevents from perfectly learning u* and overfitting.
In particular neural networks fail to learn the velocity field for two particular time values.
See the paper for a finer analysis 😀
The inductive bias of the neural network prevents from perfectly learning u* and overfitting.
In particular neural networks fail to learn the velocity field for two particular time values.
See the paper for a finer analysis 😀

June 18, 2025 at 8:15 AM
Then why does flow matching generalize?? Because it fails!
The inductive bias of the neural network prevents from perfectly learning u* and overfitting.
In particular neural networks fail to learn the velocity field for two particular time values.
See the paper for a finer analysis 😀
The inductive bias of the neural network prevents from perfectly learning u* and overfitting.
In particular neural networks fail to learn the velocity field for two particular time values.
See the paper for a finer analysis 😀
We propose to regress directly against the optimal (deterministic) u* and show that it never degrades the performance
On the opposite, removing target stochasticity helps generalizing faster.
On the opposite, removing target stochasticity helps generalizing faster.
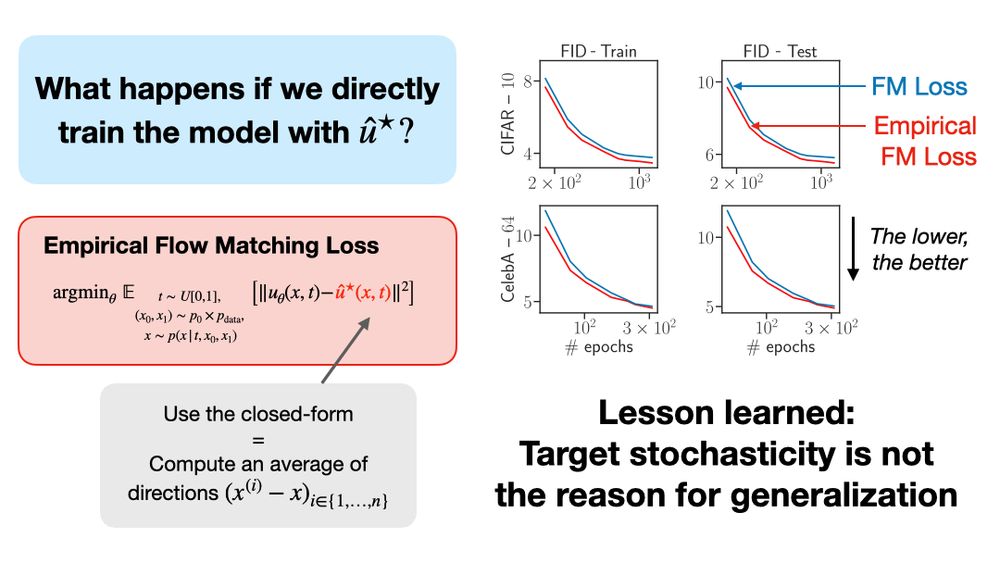
June 18, 2025 at 8:12 AM
We propose to regress directly against the optimal (deterministic) u* and show that it never degrades the performance
On the opposite, removing target stochasticity helps generalizing faster.
On the opposite, removing target stochasticity helps generalizing faster.
Yet flow matching generates new samples!
An hypothesis to explain this paradox is target stochasticity: FM targets the conditional velocity field ie only a stochastic approximation of the full velocity field u*
*We refute this hypothesis*: very early, the approximation almost equals u*
An hypothesis to explain this paradox is target stochasticity: FM targets the conditional velocity field ie only a stochastic approximation of the full velocity field u*
*We refute this hypothesis*: very early, the approximation almost equals u*
June 18, 2025 at 8:11 AM
Yet flow matching generates new samples!
An hypothesis to explain this paradox is target stochasticity: FM targets the conditional velocity field ie only a stochastic approximation of the full velocity field u*
*We refute this hypothesis*: very early, the approximation almost equals u*
An hypothesis to explain this paradox is target stochasticity: FM targets the conditional velocity field ie only a stochastic approximation of the full velocity field u*
*We refute this hypothesis*: very early, the approximation almost equals u*
New paper on the generalization of Flow Matching www.arxiv.org/abs/2506.03719
🤯 Why does flow matching generalize? Did you know that the flow matching target you're trying to learn *can only generate training points*?
w @quentinbertrand.bsky.social @annegnx.bsky.social @remiemonet.bsky.social 👇👇👇
🤯 Why does flow matching generalize? Did you know that the flow matching target you're trying to learn *can only generate training points*?
w @quentinbertrand.bsky.social @annegnx.bsky.social @remiemonet.bsky.social 👇👇👇
June 18, 2025 at 8:08 AM
New paper on the generalization of Flow Matching www.arxiv.org/abs/2506.03719
🤯 Why does flow matching generalize? Did you know that the flow matching target you're trying to learn *can only generate training points*?
w @quentinbertrand.bsky.social @annegnx.bsky.social @remiemonet.bsky.social 👇👇👇
🤯 Why does flow matching generalize? Did you know that the flow matching target you're trying to learn *can only generate training points*?
w @quentinbertrand.bsky.social @annegnx.bsky.social @remiemonet.bsky.social 👇👇👇
I had a blast giving a summer school on generative models at AI Hub Senegal, in particular flow matching, with @quentinbertrand.bsky.social and @remiemonet.bsky.social
Our material is publicly available !!! github.com/QB3/SenHubIA...
ensdelyon.bsky.social
Our material is publicly available !!! github.com/QB3/SenHubIA...
ensdelyon.bsky.social


April 14, 2025 at 7:50 AM
I had a blast giving a summer school on generative models at AI Hub Senegal, in particular flow matching, with @quentinbertrand.bsky.social and @remiemonet.bsky.social
Our material is publicly available !!! github.com/QB3/SenHubIA...
ensdelyon.bsky.social
Our material is publicly available !!! github.com/QB3/SenHubIA...
ensdelyon.bsky.social
The optimization loss in FM is easy to evaluate, and does not require integration like in CNF. The whole process is smooth!
The illustrations are much nicer in the blog post, go read it !
👉👉 dl.heeere.com/conditional-... 👈👈
The illustrations are much nicer in the blog post, go read it !
👉👉 dl.heeere.com/conditional-... 👈👈

November 27, 2024 at 9:08 AM
The optimization loss in FM is easy to evaluate, and does not require integration like in CNF. The whole process is smooth!
The illustrations are much nicer in the blog post, go read it !
👉👉 dl.heeere.com/conditional-... 👈👈
The illustrations are much nicer in the blog post, go read it !
👉👉 dl.heeere.com/conditional-... 👈👈
FM learns a vector field u, pushing the base distrib to the target through an ODE.
The key to learn it is to introduce a conditioning random variable, breaking the pb into smaller ones that have closed form solutions.
Here's the magic: the small problems can be used to solve the original one!
The key to learn it is to introduce a conditioning random variable, breaking the pb into smaller ones that have closed form solutions.
Here's the magic: the small problems can be used to solve the original one!

November 27, 2024 at 9:06 AM
FM learns a vector field u, pushing the base distrib to the target through an ODE.
The key to learn it is to introduce a conditioning random variable, breaking the pb into smaller ones that have closed form solutions.
Here's the magic: the small problems can be used to solve the original one!
The key to learn it is to introduce a conditioning random variable, breaking the pb into smaller ones that have closed form solutions.
Here's the magic: the small problems can be used to solve the original one!
FM is a technique to train continuous normalizing flows (CNF) that progressively transform a simple base distrib to the target one
2 benefits:
- no need to compute likelihoods nor solve ODE in training
- makes the problem better posed by defining a *unique sequence of densities* from base to target
2 benefits:
- no need to compute likelihoods nor solve ODE in training
- makes the problem better posed by defining a *unique sequence of densities* from base to target
November 27, 2024 at 9:05 AM
FM is a technique to train continuous normalizing flows (CNF) that progressively transform a simple base distrib to the target one
2 benefits:
- no need to compute likelihoods nor solve ODE in training
- makes the problem better posed by defining a *unique sequence of densities* from base to target
2 benefits:
- no need to compute likelihoods nor solve ODE in training
- makes the problem better posed by defining a *unique sequence of densities* from base to target
Anne Gagneux, Ségolène Martin, @quentinbertrand.bsky.social Remi Emonet and I wrote a tutorial blog post on flow matching: dl.heeere.com/conditional-... with lots of illustrations and intuition!
We got this idea after their cool work on improving Plug and Play with FM: arxiv.org/abs/2410.02423
We got this idea after their cool work on improving Plug and Play with FM: arxiv.org/abs/2410.02423
November 27, 2024 at 9:00 AM
Anne Gagneux, Ségolène Martin, @quentinbertrand.bsky.social Remi Emonet and I wrote a tutorial blog post on flow matching: dl.heeere.com/conditional-... with lots of illustrations and intuition!
We got this idea after their cool work on improving Plug and Play with FM: arxiv.org/abs/2410.02423
We got this idea after their cool work on improving Plug and Play with FM: arxiv.org/abs/2410.02423
Johnson-Lindenstrauss lemma in action:
it is possible to embed any cloud of N points from R^d into R^k without distorting their respective distances too much, provided k is not too small (independently of d!)
Better: any random Gaussian embedding works with high proba!
it is possible to embed any cloud of N points from R^d into R^k without distorting their respective distances too much, provided k is not too small (independently of d!)
Better: any random Gaussian embedding works with high proba!
November 25, 2024 at 9:58 AM
Johnson-Lindenstrauss lemma in action:
it is possible to embed any cloud of N points from R^d into R^k without distorting their respective distances too much, provided k is not too small (independently of d!)
Better: any random Gaussian embedding works with high proba!
it is possible to embed any cloud of N points from R^d into R^k without distorting their respective distances too much, provided k is not too small (independently of d!)
Better: any random Gaussian embedding works with high proba!
Conditioning of a function = ratio between highest and smallest eigenvalues of its Hessian.
Higher conditioning => harder to minimize the function
Gradient Descent gets faster on function with decreasing conditioning L/mu 👇
Higher conditioning => harder to minimize the function
Gradient Descent gets faster on function with decreasing conditioning L/mu 👇
November 22, 2024 at 1:52 PM
Conditioning of a function = ratio between highest and smallest eigenvalues of its Hessian.
Higher conditioning => harder to minimize the function
Gradient Descent gets faster on function with decreasing conditioning L/mu 👇
Higher conditioning => harder to minimize the function
Gradient Descent gets faster on function with decreasing conditioning L/mu 👇
New blog post: the Hutchinson trace estimator, or how to evaluate divergence/Jacobian trace cheaply. Fundamental for Continuous Normalizing Flows
mathurinm.github.io/hutchinson/
mathurinm.github.io/hutchinson/

November 21, 2024 at 8:48 AM
New blog post: the Hutchinson trace estimator, or how to evaluate divergence/Jacobian trace cheaply. Fundamental for Continuous Normalizing Flows
mathurinm.github.io/hutchinson/
mathurinm.github.io/hutchinson/
Time to unearth posts from the previous network!
1°: Two equivalent views on PCA: maximize the variance of the projected data, or minimize the reconstruction error
1°: Two equivalent views on PCA: maximize the variance of the projected data, or minimize the reconstruction error
November 20, 2024 at 4:27 PM
Time to unearth posts from the previous network!
1°: Two equivalent views on PCA: maximize the variance of the projected data, or minimize the reconstruction error
1°: Two equivalent views on PCA: maximize the variance of the projected data, or minimize the reconstruction error