




Maryam Shanechi
@maryamshanechi.bsky.social
Sawchuk Chair & Prof at USC Viterbi School of Engineering | Founding Director of USC Center for Neurotech | Developing AI/ML methods & neurotech to decode the brain & treat its conditions 🧠🤖💻 https://nseip.usc.edu/
On two public spike-LFP motor cortex datasets during reaching, MRINE:
✅ Improves real-time behavior decoding via multimodal fusion
✅ Outperforms recent multimodal neural models
It also:
✅ Generalizes to a high-dim dataset with Neuropixels spikes and calcium imaging
✅ Improves real-time behavior decoding via multimodal fusion
✅ Outperforms recent multimodal neural models
It also:
✅ Generalizes to a high-dim dataset with Neuropixels spikes and calcium imaging

December 4, 2025 at 4:35 PM
On two public spike-LFP motor cortex datasets during reaching, MRINE:
✅ Improves real-time behavior decoding via multimodal fusion
✅ Outperforms recent multimodal neural models
It also:
✅ Generalizes to a high-dim dataset with Neuropixels spikes and calcium imaging
✅ Improves real-time behavior decoding via multimodal fusion
✅ Outperforms recent multimodal neural models
It also:
✅ Generalizes to a high-dim dataset with Neuropixels spikes and calcium imaging
MRINE tackles these challenges with a multiscale encoder that:
🔸 Models each modality at its own timescale & forward-predicts its dynamics to infer fast latent factors
🔸 Nonlinearly fuses modality-specific factors
🔸 Enables real-time inference via its linear state-space model (SSM) backbone
🔸 Models each modality at its own timescale & forward-predicts its dynamics to infer fast latent factors
🔸 Nonlinearly fuses modality-specific factors
🔸 Enables real-time inference via its linear state-space model (SSM) backbone

December 4, 2025 at 4:35 PM
MRINE tackles these challenges with a multiscale encoder that:
🔸 Models each modality at its own timescale & forward-predicts its dynamics to infer fast latent factors
🔸 Nonlinearly fuses modality-specific factors
🔸 Enables real-time inference via its linear state-space model (SSM) backbone
🔸 Models each modality at its own timescale & forward-predicts its dynamics to infer fast latent factors
🔸 Nonlinearly fuses modality-specific factors
🔸 Enables real-time inference via its linear state-space model (SSM) backbone
Brain activity is recorded through modalities like spikes and LFPs. Fusing them can unlock richer neural representations & improve BCI performance and robustness.
But fusion is hard: modalities differ in timescales & distributions, and BCIs require real-time inference.
But fusion is hard: modalities differ in timescales & distributions, and BCIs require real-time inference.

December 4, 2025 at 4:35 PM
Brain activity is recorded through modalities like spikes and LFPs. Fusing them can unlock richer neural representations & improve BCI performance and robustness.
But fusion is hard: modalities differ in timescales & distributions, and BCIs require real-time inference.
But fusion is hard: modalities differ in timescales & distributions, and BCIs require real-time inference.
Can we achieve nonlinear multimodal neural fusion while also enabling real-time recursive decoding for #BCI?
In our third paper at #NeurIPS2025, we present MRINE, which does exactly that — improving decoding even for modalities w/ distinct timescales & distributions.
👏 Eray Erturk
🧵 Paper Code ⬇️
In our third paper at #NeurIPS2025, we present MRINE, which does exactly that — improving decoding even for modalities w/ distinct timescales & distributions.
👏 Eray Erturk
🧵 Paper Code ⬇️

December 4, 2025 at 4:35 PM
Can we achieve nonlinear multimodal neural fusion while also enabling real-time recursive decoding for #BCI?
In our third paper at #NeurIPS2025, we present MRINE, which does exactly that — improving decoding even for modalities w/ distinct timescales & distributions.
👏 Eray Erturk
🧵 Paper Code ⬇️
In our third paper at #NeurIPS2025, we present MRINE, which does exactly that — improving decoding even for modalities w/ distinct timescales & distributions.
👏 Eray Erturk
🧵 Paper Code ⬇️
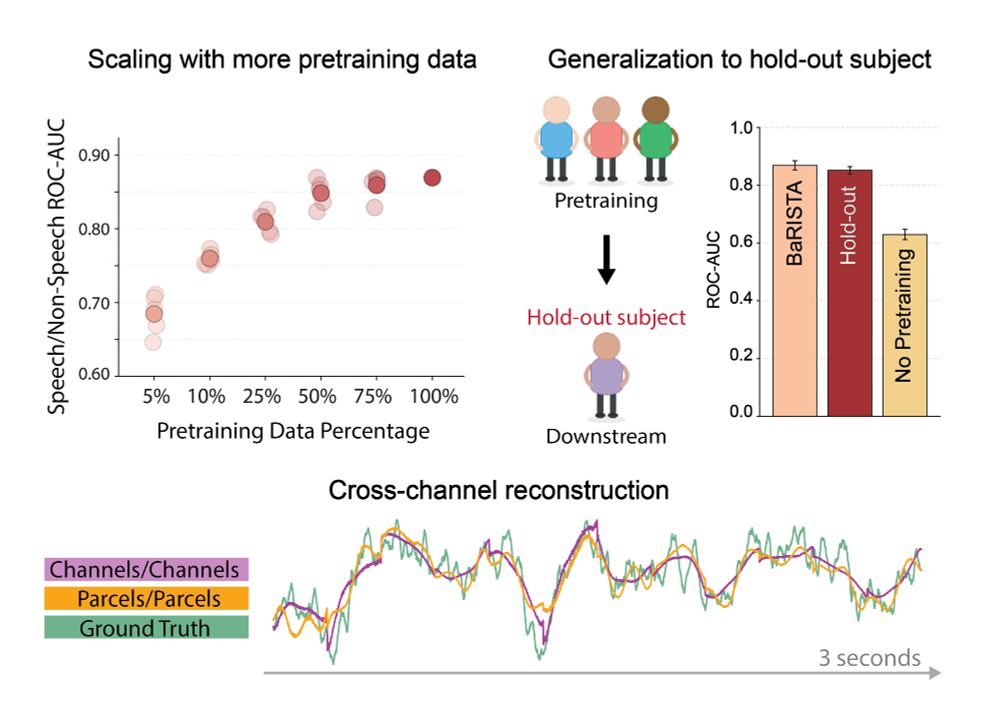
We also show that BaRISTA:
✅ Scales with increased pretraining data
✅ Generalizes to held-out subjects
✅ Can use spatial scales larger than channel level without sacrificing channel reconstruction performance
✅ Scales with increased pretraining data
✅ Generalizes to held-out subjects
✅ Can use spatial scales larger than channel level without sacrificing channel reconstruction performance
December 2, 2025 at 8:20 PM
We also show that BaRISTA:
✅ Scales with increased pretraining data
✅ Generalizes to held-out subjects
✅ Can use spatial scales larger than channel level without sacrificing channel reconstruction performance
✅ Scales with increased pretraining data
✅ Generalizes to held-out subjects
✅ Can use spatial scales larger than channel level without sacrificing channel reconstruction performance
On a public iEEG dataset (Brain Treebank):
✅ BaRISTA shows that spatial encoding at scales larger than individual channels improves downstream decoding of auditory or visual features
✅ BaRISTA outperforms state-of-the-art iEEG models given its flexible spatial encoding
✅ BaRISTA shows that spatial encoding at scales larger than individual channels improves downstream decoding of auditory or visual features
✅ BaRISTA outperforms state-of-the-art iEEG models given its flexible spatial encoding

December 2, 2025 at 8:20 PM
On a public iEEG dataset (Brain Treebank):
✅ BaRISTA shows that spatial encoding at scales larger than individual channels improves downstream decoding of auditory or visual features
✅ BaRISTA outperforms state-of-the-art iEEG models given its flexible spatial encoding
✅ BaRISTA shows that spatial encoding at scales larger than individual channels improves downstream decoding of auditory or visual features
✅ BaRISTA outperforms state-of-the-art iEEG models given its flexible spatial encoding
At what scale should spatial information be encoded toward future foundation models of intracranial brain activity?
In our second paper at #NeurIPS2025, we present BaRISTA ☕ — a self-supervised multi-subject model that enables flexible spatial encoding & boosts downstream decoding.
🧵 Paper Code ⬇️
In our second paper at #NeurIPS2025, we present BaRISTA ☕ — a self-supervised multi-subject model that enables flexible spatial encoding & boosts downstream decoding.
🧵 Paper Code ⬇️

December 2, 2025 at 8:20 PM
At what scale should spatial information be encoded toward future foundation models of intracranial brain activity?
In our second paper at #NeurIPS2025, we present BaRISTA ☕ — a self-supervised multi-subject model that enables flexible spatial encoding & boosts downstream decoding.
🧵 Paper Code ⬇️
In our second paper at #NeurIPS2025, we present BaRISTA ☕ — a self-supervised multi-subject model that enables flexible spatial encoding & boosts downstream decoding.
🧵 Paper Code ⬇️
Our framework achieves:
✅ Substantial decoding performance improvement over several LFP-only baselines
✅ Consistent improvements in unsupervised, supervised & multi-session distillation setups
✅ Generalization to unseen sessions without additional distillation
✅ Spike-aligned LFP latent structure
✅ Substantial decoding performance improvement over several LFP-only baselines
✅ Consistent improvements in unsupervised, supervised & multi-session distillation setups
✅ Generalization to unseen sessions without additional distillation
✅ Spike-aligned LFP latent structure

November 25, 2025 at 8:15 PM
Our framework achieves:
✅ Substantial decoding performance improvement over several LFP-only baselines
✅ Consistent improvements in unsupervised, supervised & multi-session distillation setups
✅ Generalization to unseen sessions without additional distillation
✅ Spike-aligned LFP latent structure
✅ Substantial decoding performance improvement over several LFP-only baselines
✅ Consistent improvements in unsupervised, supervised & multi-session distillation setups
✅ Generalization to unseen sessions without additional distillation
✅ Spike-aligned LFP latent structure
Our framework:
1️⃣ Pretrains a multi-session spike model
2️⃣ Fine-tunes the multi-session spike model on new spike signals
3️⃣ Trains the Distilled LFP model via cross-modal representation alignment
🔥 This produces spike-informed LFP models with significantly improved decoding.
1️⃣ Pretrains a multi-session spike model
2️⃣ Fine-tunes the multi-session spike model on new spike signals
3️⃣ Trains the Distilled LFP model via cross-modal representation alignment
🔥 This produces spike-informed LFP models with significantly improved decoding.

November 25, 2025 at 8:15 PM
Our framework:
1️⃣ Pretrains a multi-session spike model
2️⃣ Fine-tunes the multi-session spike model on new spike signals
3️⃣ Trains the Distilled LFP model via cross-modal representation alignment
🔥 This produces spike-informed LFP models with significantly improved decoding.
1️⃣ Pretrains a multi-session spike model
2️⃣ Fine-tunes the multi-session spike model on new spike signals
3️⃣ Trains the Distilled LFP model via cross-modal representation alignment
🔥 This produces spike-informed LFP models with significantly improved decoding.
🎉 New in #NeurIPS2025, we present “Cross-Modal Representational Knowledge Distillation for Enhanced Spike-Informed LFP Modeling”.
We show that high-fidelity spike transformer models can teach LFP models to substantially enhance LFP decoding. #BCI
👏 Eray Erturk
🧵 Paper, Code ⬇️
We show that high-fidelity spike transformer models can teach LFP models to substantially enhance LFP decoding. #BCI
👏 Eray Erturk
🧵 Paper, Code ⬇️

November 25, 2025 at 8:15 PM
🎉 New in #NeurIPS2025, we present “Cross-Modal Representational Knowledge Distillation for Enhanced Spike-Informed LFP Modeling”.
We show that high-fidelity spike transformer models can teach LFP models to substantially enhance LFP decoding. #BCI
👏 Eray Erturk
🧵 Paper, Code ⬇️
We show that high-fidelity spike transformer models can teach LFP models to substantially enhance LFP decoding. #BCI
👏 Eray Erturk
🧵 Paper, Code ⬇️
Also on public data (🙏to Churchland, Andersen, and Shapiro labs)
✅ Self-attention improves neural-behavior predictions by learning long-range patterns while convolutions learn local ones
✅ Two-stage learning improves behavior prediction by disentangling behaviorally relevant dynamics
✅ Self-attention improves neural-behavior predictions by learning long-range patterns while convolutions learn local ones
✅ Two-stage learning improves behavior prediction by disentangling behaviorally relevant dynamics

July 14, 2025 at 5:46 PM
Also on public data (🙏to Churchland, Andersen, and Shapiro labs)
✅ Self-attention improves neural-behavior predictions by learning long-range patterns while convolutions learn local ones
✅ Two-stage learning improves behavior prediction by disentangling behaviorally relevant dynamics
✅ Self-attention improves neural-behavior predictions by learning long-range patterns while convolutions learn local ones
✅ Two-stage learning improves behavior prediction by disentangling behaviorally relevant dynamics
SBIND:
✅ Operates directly on raw images & avoids preprocessing.
✅ Combines self-attention and convolutional layers to model both global and local patterns.
✅ Uses two-stage learning of convolutional RNNs (ConvRNNs) to disentangle behaviorally relevant and other neural dynamics.
✅ Operates directly on raw images & avoids preprocessing.
✅ Combines self-attention and convolutional layers to model both global and local patterns.
✅ Uses two-stage learning of convolutional RNNs (ConvRNNs) to disentangle behaviorally relevant and other neural dynamics.

July 14, 2025 at 5:46 PM
SBIND:
✅ Operates directly on raw images & avoids preprocessing.
✅ Combines self-attention and convolutional layers to model both global and local patterns.
✅ Uses two-stage learning of convolutional RNNs (ConvRNNs) to disentangle behaviorally relevant and other neural dynamics.
✅ Operates directly on raw images & avoids preprocessing.
✅ Combines self-attention and convolutional layers to model both global and local patterns.
✅ Uses two-stage learning of convolutional RNNs (ConvRNNs) to disentangle behaviorally relevant and other neural dynamics.
🎉 New in #ICML2025, we develop SBIND for modeling neural imaging modalities and disentangling their behaviorally relevant dynamics.
SBIND learns local and global spatiotemporal patterns in raw widefield calcium and functional ultrasound neural images.
👏M Hoseini
🧵Paper, Code⬇️
SBIND learns local and global spatiotemporal patterns in raw widefield calcium and functional ultrasound neural images.
👏M Hoseini
🧵Paper, Code⬇️

July 14, 2025 at 5:46 PM
🎉 New in #ICML2025, we develop SBIND for modeling neural imaging modalities and disentangling their behaviorally relevant dynamics.
SBIND learns local and global spatiotemporal patterns in raw widefield calcium and functional ultrasound neural images.
👏M Hoseini
🧵Paper, Code⬇️
SBIND learns local and global spatiotemporal patterns in raw widefield calcium and functional ultrasound neural images.
👏M Hoseini
🧵Paper, Code⬇️
On public motor cortex data during reaching from the Sabes lab, BRAID outperformed several baselines in neural-behavioral predictions by capturing nonlinearity, modeling sensory task instructions as input, and disentangling intrinsic behaviorally relevant neural dynamics.

April 21, 2025 at 7:40 PM
On public motor cortex data during reaching from the Sabes lab, BRAID outperformed several baselines in neural-behavioral predictions by capturing nonlinearity, modeling sensory task instructions as input, and disentangling intrinsic behaviorally relevant neural dynamics.
In nonlinear simulations, BRAID accurately disentangled intrinsic neural-behavioral dynamics from input dynamics. In terms of learning the intrinsic dynamics and decoding behavior, BRAID outperformed prior neural-behavioral models, which either don’t include input or are linear.

April 21, 2025 at 7:40 PM
In nonlinear simulations, BRAID accurately disentangled intrinsic neural-behavioral dynamics from input dynamics. In terms of learning the intrinsic dynamics and decoding behavior, BRAID outperformed prior neural-behavioral models, which either don’t include input or are linear.
BRAID
✅ Disentangles intrinsic behaviorally relevant neural dynamics from input, neural-specific & behavior-specific dynamics
✅ Captures nonlinearity
It is a multi-stage RNN: each stage learns a subtype of dynamics & combines a predictor network w/ a generative network to learn intrinsic dynamics.
✅ Disentangles intrinsic behaviorally relevant neural dynamics from input, neural-specific & behavior-specific dynamics
✅ Captures nonlinearity
It is a multi-stage RNN: each stage learns a subtype of dynamics & combines a predictor network w/ a generative network to learn intrinsic dynamics.

April 21, 2025 at 7:40 PM
BRAID
✅ Disentangles intrinsic behaviorally relevant neural dynamics from input, neural-specific & behavior-specific dynamics
✅ Captures nonlinearity
It is a multi-stage RNN: each stage learns a subtype of dynamics & combines a predictor network w/ a generative network to learn intrinsic dynamics.
✅ Disentangles intrinsic behaviorally relevant neural dynamics from input, neural-specific & behavior-specific dynamics
✅ Captures nonlinearity
It is a multi-stage RNN: each stage learns a subtype of dynamics & combines a predictor network w/ a generative network to learn intrinsic dynamics.
🎉 New in #ICLR2025, we present BRAID for input-driven nonlinear dynamical modeling of neural-behavioral data.
BRAID disentangles the intrinsic dynamics shared between modalities from input dynamics and modality-specific dynamics.
👏 Parsa Vahidi & Omid Sani
@iclr-conf.bsky.social
🧵, Paper & Code ⬇️
BRAID disentangles the intrinsic dynamics shared between modalities from input dynamics and modality-specific dynamics.
👏 Parsa Vahidi & Omid Sani
@iclr-conf.bsky.social
🧵, Paper & Code ⬇️

April 21, 2025 at 7:40 PM
🎉 New in #ICLR2025, we present BRAID for input-driven nonlinear dynamical modeling of neural-behavioral data.
BRAID disentangles the intrinsic dynamics shared between modalities from input dynamics and modality-specific dynamics.
👏 Parsa Vahidi & Omid Sani
@iclr-conf.bsky.social
🧵, Paper & Code ⬇️
BRAID disentangles the intrinsic dynamics shared between modalities from input dynamics and modality-specific dynamics.
👏 Parsa Vahidi & Omid Sani
@iclr-conf.bsky.social
🧵, Paper & Code ⬇️
On public neural data from the mice head direction circuit from Buzsáki lab, PGPCA outperforms baselines across all state dimensions. Also, interestingly, the geometric coordinate outperforms the Euclidean one, showing that the noise around the manifold also follows the same geometry.

April 17, 2025 at 6:55 PM
On public neural data from the mice head direction circuit from Buzsáki lab, PGPCA outperforms baselines across all state dimensions. Also, interestingly, the geometric coordinate outperforms the Euclidean one, showing that the noise around the manifold also follows the same geometry.
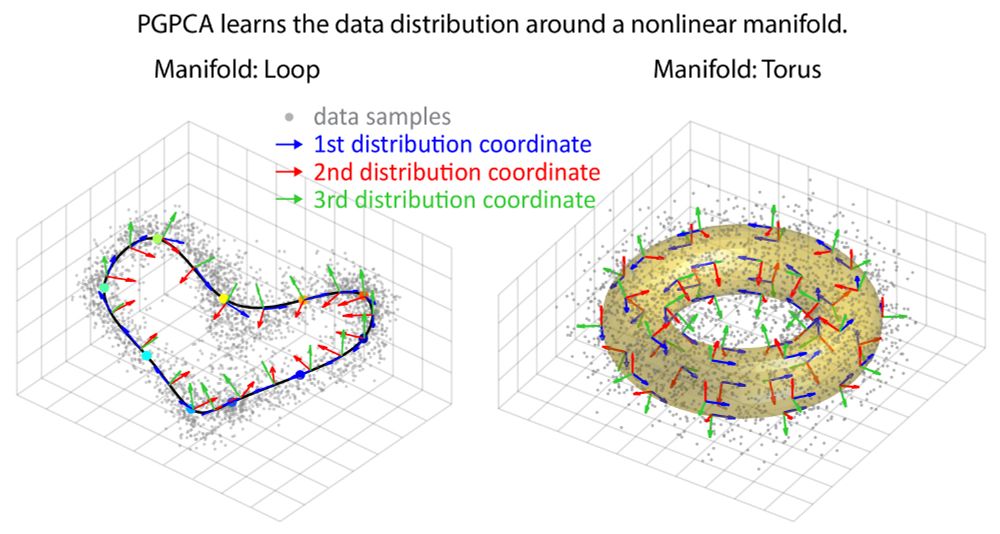
In simulations, PGPCA recovers the true data distribution and distinguishes between different coordinates (geometric vs. Euclidean) regardless of the manifold state distribution p(z). Also, PGPCA outperforms Probabilistic PCA (PPCA) in modeling data around a nonlinear manifold.

April 17, 2025 at 6:55 PM
In simulations, PGPCA recovers the true data distribution and distinguishes between different coordinates (geometric vs. Euclidean) regardless of the manifold state distribution p(z). Also, PGPCA outperforms Probabilistic PCA (PPCA) in modeling data around a nonlinear manifold.
PGPCA decomposes the data distribution p(y) into a state distribution on a nonlinear manifold p(z) plus a deviation from the manifold captured by the distribution coordinate K(z). K(z) can be Euclidean or geometric, as we derive. A new algorithm learns the model parameters.

April 17, 2025 at 6:55 PM
PGPCA decomposes the data distribution p(y) into a state distribution on a nonlinear manifold p(z) plus a deviation from the manifold captured by the distribution coordinate K(z). K(z) can be Euclidean or geometric, as we derive. A new algorithm learns the model parameters.
New in our #ICLR2025 spotlight ✨, we introduce PGPCA, a Probabilistic Geometric method that enables modeling and dimensionality reduction for data distributed around nonlinear manifolds. We also show PGPCA’s application to brain data.
👏 Han-Lin Hsieh
@iclr-conf.bsky.social
Paper, Code, 🧵⬇️
👏 Han-Lin Hsieh
@iclr-conf.bsky.social
Paper, Code, 🧵⬇️
April 17, 2025 at 6:55 PM
New in our #ICLR2025 spotlight ✨, we introduce PGPCA, a Probabilistic Geometric method that enables modeling and dimensionality reduction for data distributed around nonlinear manifolds. We also show PGPCA’s application to brain data.
👏 Han-Lin Hsieh
@iclr-conf.bsky.social
Paper, Code, 🧵⬇️
👏 Han-Lin Hsieh
@iclr-conf.bsky.social
Paper, Code, 🧵⬇️
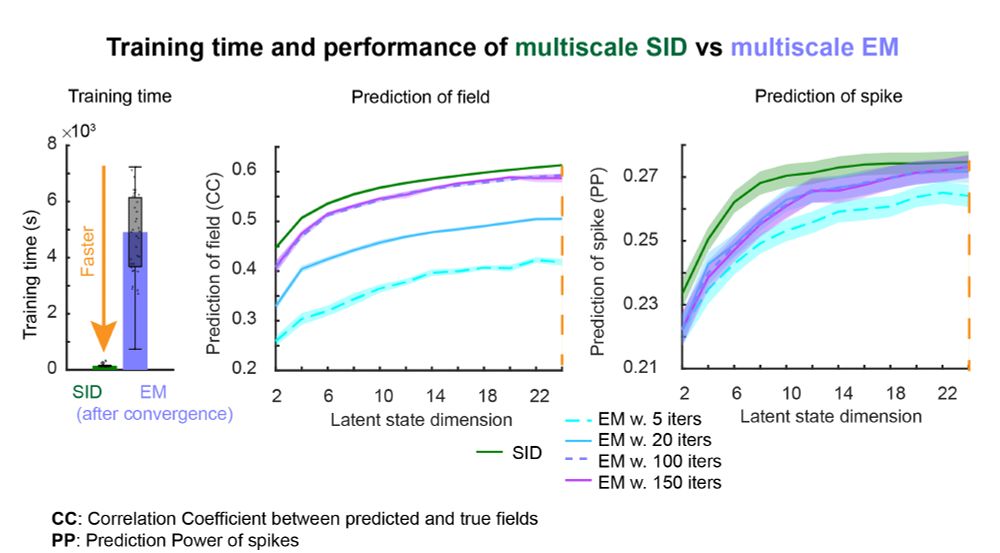
Also, compared to multiscale EM, multiscale SID has a much lower training time, coupled with a better accuracy in dynamical mode identification and a better or similar accuracy in predicting neural activity and behavior.
December 18, 2024 at 7:17 PM
Also, compared to multiscale EM, multiscale SID has a much lower training time, coupled with a better accuracy in dynamical mode identification and a better or similar accuracy in predicting neural activity and behavior.
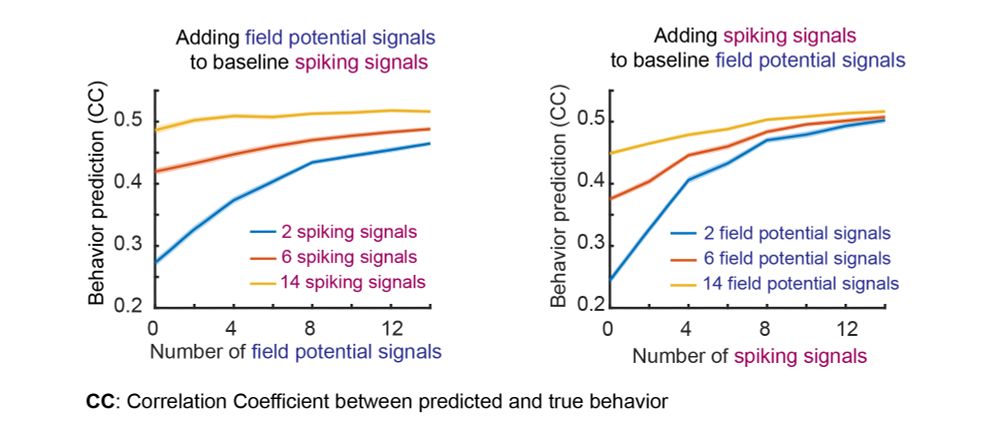
Using neural data recorded during arm movements, we show that multiscale SID can fuse information across spiking & field potential neural modalities. This results in improved learning of dynamical modes & better behavior (movement) prediction compared to using a single modality.
December 18, 2024 at 7:17 PM
Using neural data recorded during arm movements, we show that multiscale SID can fuse information across spiking & field potential neural modalities. This results in improved learning of dynamical modes & better behavior (movement) prediction compared to using a single modality.
We develop multiscale SID, a computationally efficient learning method that extends subspace identification (SID) to multimodal time-series. We also introduce a constrained optimization to learn valid noise statistics, which enables multimodal statistical inference. Inference can be done causally.
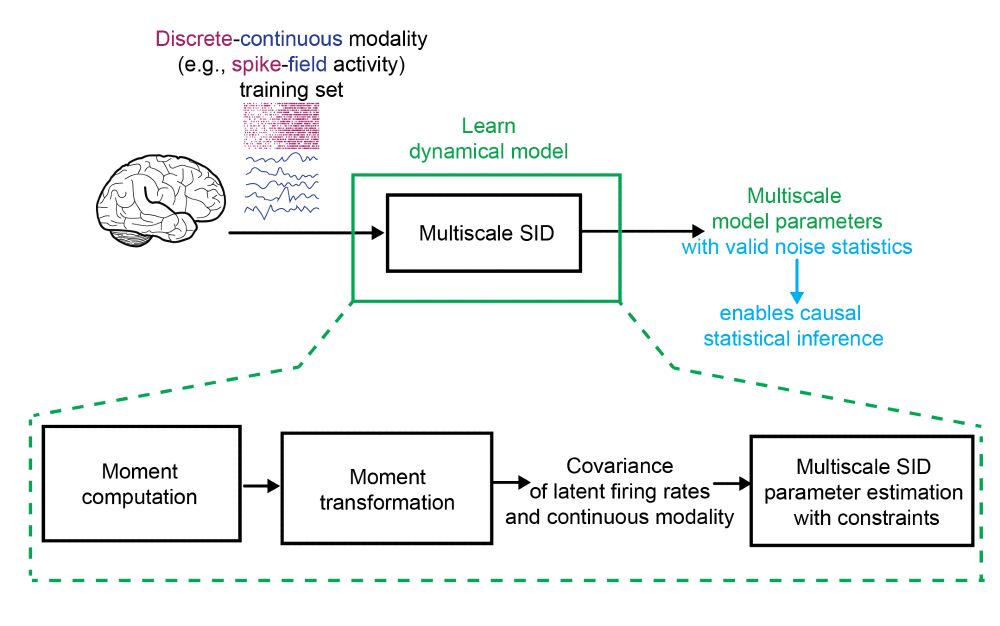
December 18, 2024 at 7:17 PM
We develop multiscale SID, a computationally efficient learning method that extends subspace identification (SID) to multimodal time-series. We also introduce a constrained optimization to learn valid noise statistics, which enables multimodal statistical inference. Inference can be done causally.
Can we efficiently learn models of collective dynamics in multimodal discrete-continuous time-series, e.g., spike-LFP?
We develop a multimodal subspace identification method to do so & enable causal multimodal decoding!
👏P Ahmadipour!
📜J Neural Eng Paper: iopscience.iop.org/article/10.1...
Code+🧵⬇️
We develop a multimodal subspace identification method to do so & enable causal multimodal decoding!
👏P Ahmadipour!
📜J Neural Eng Paper: iopscience.iop.org/article/10.1...
Code+🧵⬇️

December 18, 2024 at 7:17 PM
Can we efficiently learn models of collective dynamics in multimodal discrete-continuous time-series, e.g., spike-LFP?
We develop a multimodal subspace identification method to do so & enable causal multimodal decoding!
👏P Ahmadipour!
📜J Neural Eng Paper: iopscience.iop.org/article/10.1...
Code+🧵⬇️
We develop a multimodal subspace identification method to do so & enable causal multimodal decoding!
👏P Ahmadipour!
📜J Neural Eng Paper: iopscience.iop.org/article/10.1...
Code+🧵⬇️