



Mark Collier
@markcollier.me
Austin Powered. OpenStack co-founder, OpenInfra Foundation COO, ex Rackspace & Yahoo! open source for fun & profit.
Open Source AI early and often
@sparkycollier on twitter and elsewhere
Links: markcollier.me
Open Source AI early and often
@sparkycollier on twitter and elsewhere
Links: markcollier.me
Pinned
Mark Collier
@markcollier.me
· Nov 24
Today is OpenStack's 15th birthday! What an honor to be part of this community from the beginning. I've met so many friends all over the world and have enjoyed seeing others fall in love with open source and make careers and companies out of it, in OpenStack & beyond! To 15 more!
July 19, 2025 at 10:10 PM
Today is OpenStack's 15th birthday! What an honor to be part of this community from the beginning. I've met so many friends all over the world and have enjoyed seeing others fall in love with open source and make careers and companies out of it, in OpenStack & beyond! To 15 more!
Reposted by Mark Collier

You're Probably Breaking the Llama Community License
> If you're distributing or redistributing a LLM model that is under the "Llama 3.3 Community License Agreement", you might be breaking at least one of the terms you've explicitly/implicitly agreed to.
notes.victor.earth/youre-probab...
> If you're distributing or redistributing a LLM model that is under the "Llama 3.3 Community License Agreement", you might be breaking at least one of the terms you've explicitly/implicitly agreed to.
notes.victor.earth/youre-probab...
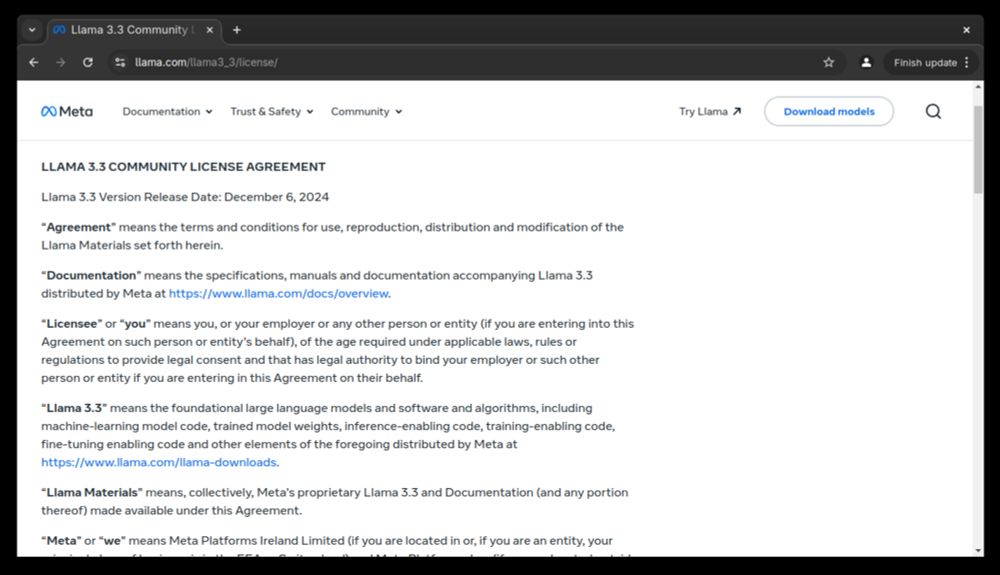
You're Probably Breaking the Llama Community License
You're Probably Breaking the Llama Community License
notes.victor.earth
March 28, 2025 at 12:14 PM
You're Probably Breaking the Llama Community License
> If you're distributing or redistributing a LLM model that is under the "Llama 3.3 Community License Agreement", you might be breaking at least one of the terms you've explicitly/implicitly agreed to.
notes.victor.earth/youre-probab...
> If you're distributing or redistributing a LLM model that is under the "Llama 3.3 Community License Agreement", you might be breaking at least one of the terms you've explicitly/implicitly agreed to.
notes.victor.earth/youre-probab...
Who are some cool open source AI folks in Paris I should meet up with?
March 30, 2025 at 9:31 AM
Who are some cool open source AI folks in Paris I should meet up with?
OpenInfra Summit coming to Paris-Saclay, France Oct 17-19, 2025!
OpenStack, Kata Containers, StarlingX, Zuul + many other open source infrastructure projects will be discussed along with OpenInfra for AI and the mass migration from Vmware to OpenStack
Mark your calendars and practice your French!
OpenStack, Kata Containers, StarlingX, Zuul + many other open source infrastructure projects will be discussed along with OpenInfra for AI and the mass migration from Vmware to OpenStack
Mark your calendars and practice your French!

💫We are thrilled to share that the #OpenInfraSummit Europe has been officially scheduled for October 17-19, 2025, at École Polytechnique near Paris, France!
Read more about the upcoming event and how you can help build the OpenInfra Summit Europe! openinfra.dev/blog/openinf...
Read more about the upcoming event and how you can help build the OpenInfra Summit Europe! openinfra.dev/blog/openinf...

March 25, 2025 at 6:12 PM
OpenInfra Summit coming to Paris-Saclay, France Oct 17-19, 2025!
OpenStack, Kata Containers, StarlingX, Zuul + many other open source infrastructure projects will be discussed along with OpenInfra for AI and the mass migration from Vmware to OpenStack
Mark your calendars and practice your French!
OpenStack, Kata Containers, StarlingX, Zuul + many other open source infrastructure projects will be discussed along with OpenInfra for AI and the mass migration from Vmware to OpenStack
Mark your calendars and practice your French!
Reposted by Mark Collier

“New infrastructure is being designed specifically for AI. GPU support has been part of #OpenStack for years, making it the standard in HPC & AI is the next evolution...users like the Dawn Supercomputer in the UK are already building AI clouds on OpenStack" - @markcollier.me
tfir.io/openinfra-fo...
tfir.io/openinfra-fo...

OpenInfra Foundation To Join the Linux Foundation: A New Era for Open Source and AI - TFiR
As AI, cloud, and open source infrastructure continue to evolve, this move ensures that OpenInfra’s projects are well-positioned to thrive—empowering developers, enterprises, and global economies for ...
tfir.io
March 18, 2025 at 11:20 PM
“New infrastructure is being designed specifically for AI. GPU support has been part of #OpenStack for years, making it the standard in HPC & AI is the next evolution...users like the Dawn Supercomputer in the UK are already building AI clouds on OpenStack" - @markcollier.me
tfir.io/openinfra-fo...
tfir.io/openinfra-fo...
Reposted by Mark Collier

DeepSeek Open Source Optimized Parallelism Strategies, 3 repos [Discussion]
DeepSeek Open Source Optimized Parallelism Strategies, 3 repos
DeepSeek Open Source Optimized Parallelism Strategies, 3 repos
github.com
February 27, 2025 at 5:25 AM
DeepSeek Open Source Optimized Parallelism Strategies, 3 repos [Discussion]
Reposted by Mark Collier

DeepSeek goes beyond “open weights” AI with plans for source code release https://buff.ly/4gT62Nd

DeepSeek goes beyond “open weights” AI with plans for source code release
Chinese AI firm says daily releases will reveal “code that moved our tiny moonshot forward.”…
buff.ly
February 25, 2025 at 3:42 PM
DeepSeek goes beyond “open weights” AI with plans for source code release https://buff.ly/4gT62Nd
Reposted by Mark Collier

Arne talked about that in one of the CERN presentations 😁 indico.cern.ch/event/150867...

Success, Open Source and You: Maximising the impact of your open-source contributions
The CERN Open Source Program Office (OSPO) invites you to a lecture from Dr. Dawn Foster (Director of Data Science, CHAOSS project) on the topic of “Making the most of your open source contributions”....
indico.cern.ch
February 22, 2025 at 4:37 PM
Arne talked about that in one of the CERN presentations 😁 indico.cern.ch/event/150867...
Reposted by Mark Collier

Wallace Shawn Emerges As Frontrunner To Replace Daniel Craig As James Bond

February 20, 2025 at 5:05 PM
Wallace Shawn Emerges As Frontrunner To Replace Daniel Craig As James Bond
Reposted by Mark Collier

OK! My Google colleague Thang Luong shared some exciting updates about AlphaGeometry2!
AG2 now has surpassed the average gold-medalist in solving Olympiad geometry problems, w/ a solve rate of 84% compared to 54% previously!
Paper: arxiv.org/abs/2502.03544
See full list of authors on link
AG2 now has surpassed the average gold-medalist in solving Olympiad geometry problems, w/ a solve rate of 84% compared to 54% previously!
Paper: arxiv.org/abs/2502.03544
See full list of authors on link

February 8, 2025 at 7:42 PM
OK! My Google colleague Thang Luong shared some exciting updates about AlphaGeometry2!
AG2 now has surpassed the average gold-medalist in solving Olympiad geometry problems, w/ a solve rate of 84% compared to 54% previously!
Paper: arxiv.org/abs/2502.03544
See full list of authors on link
AG2 now has surpassed the average gold-medalist in solving Olympiad geometry problems, w/ a solve rate of 84% compared to 54% previously!
Paper: arxiv.org/abs/2502.03544
See full list of authors on link
Reposted by Mark Collier

📢 Today we're releasing a new highly detailed dataset for video understanding: HD-EPIC
arxiv.org/abs/2502.04144
hd-epic.github.io
What makes the dataset unique is the vast detail contained in the annotations with 263 annotations per minute over 41 hours of video.
arxiv.org/abs/2502.04144
hd-epic.github.io
What makes the dataset unique is the vast detail contained in the annotations with 263 annotations per minute over 41 hours of video.
February 7, 2025 at 12:27 PM
📢 Today we're releasing a new highly detailed dataset for video understanding: HD-EPIC
arxiv.org/abs/2502.04144
hd-epic.github.io
What makes the dataset unique is the vast detail contained in the annotations with 263 annotations per minute over 41 hours of video.
arxiv.org/abs/2502.04144
hd-epic.github.io
What makes the dataset unique is the vast detail contained in the annotations with 263 annotations per minute over 41 hours of video.
Reposted by Mark Collier

Another seed could be a wikipedia style data curation effort.
In parallel, research data-efficient models that can be trained on 100M tokens. This is comparable to both what humans need to develop speech and to wikipedia, proving that it's possible to curate this amount of data as a community.
In parallel, research data-efficient models that can be trained on 100M tokens. This is comparable to both what humans need to develop speech and to wikipedia, proving that it's possible to curate this amount of data as a community.
February 4, 2025 at 3:33 PM
Another seed could be a wikipedia style data curation effort.
In parallel, research data-efficient models that can be trained on 100M tokens. This is comparable to both what humans need to develop speech and to wikipedia, proving that it's possible to curate this amount of data as a community.
In parallel, research data-efficient models that can be trained on 100M tokens. This is comparable to both what humans need to develop speech and to wikipedia, proving that it's possible to curate this amount of data as a community.
First day at FOSDEM and I’m loving it. So much open source and interesting people. Just met a guy who wrote code for F1 to make the cars faster including physics simulation models for designing carbon fiber spoilers and better gear efficiency.
February 1, 2025 at 12:28 PM
First day at FOSDEM and I’m loving it. So much open source and interesting people. Just met a guy who wrote code for F1 to make the cars faster including physics simulation models for designing carbon fiber spoilers and better gear efficiency.
Reposted by Mark Collier

I’d like to learn more about Merriam and Webster. What was that partnership like? I wonder if they ever fought, battled, combatted, wrestled, dueled, or skirmished?
January 25, 2025 at 6:20 AM
I’d like to learn more about Merriam and Webster. What was that partnership like? I wonder if they ever fought, battled, combatted, wrestled, dueled, or skirmished?
Reposted by Mark Collier

I used the DeepSeek R1 reasoning model to prepare for a new course proposal. These screenshots show with and without the "DeepThink" option turned on--strikingly different. R1 does a lot more synthesis and offers clearer suggestions. It also accepts pdf files, o1 doesn't. Crazy this is open source.
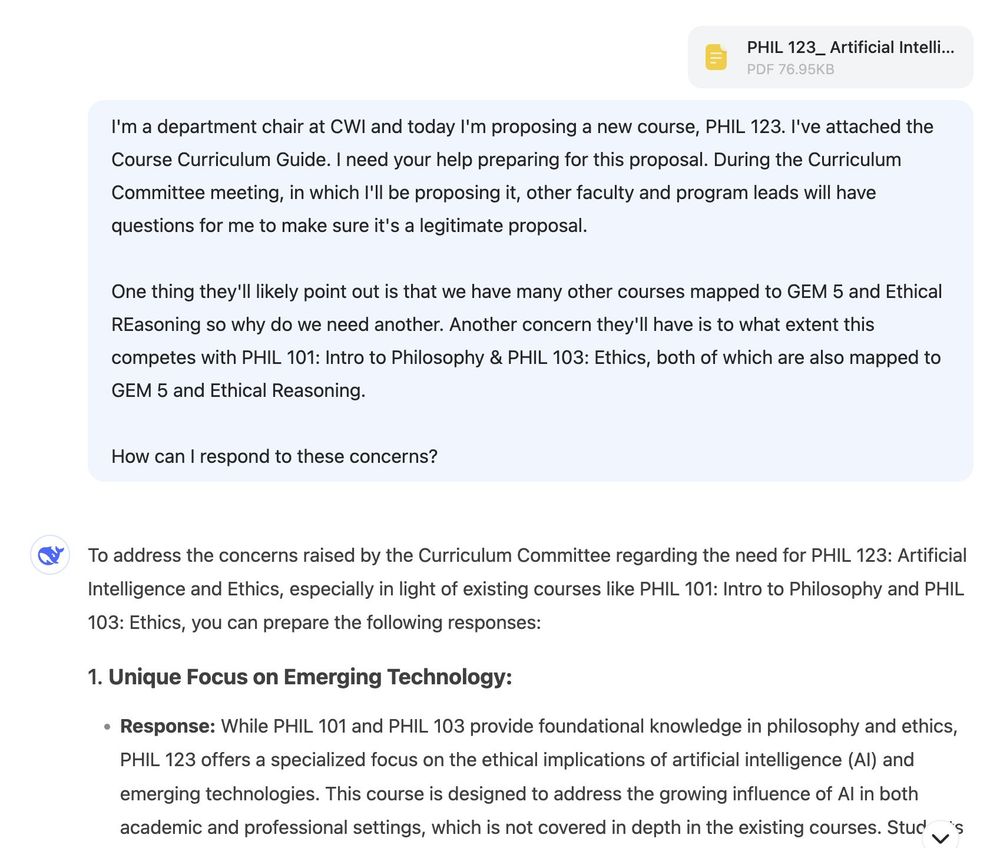
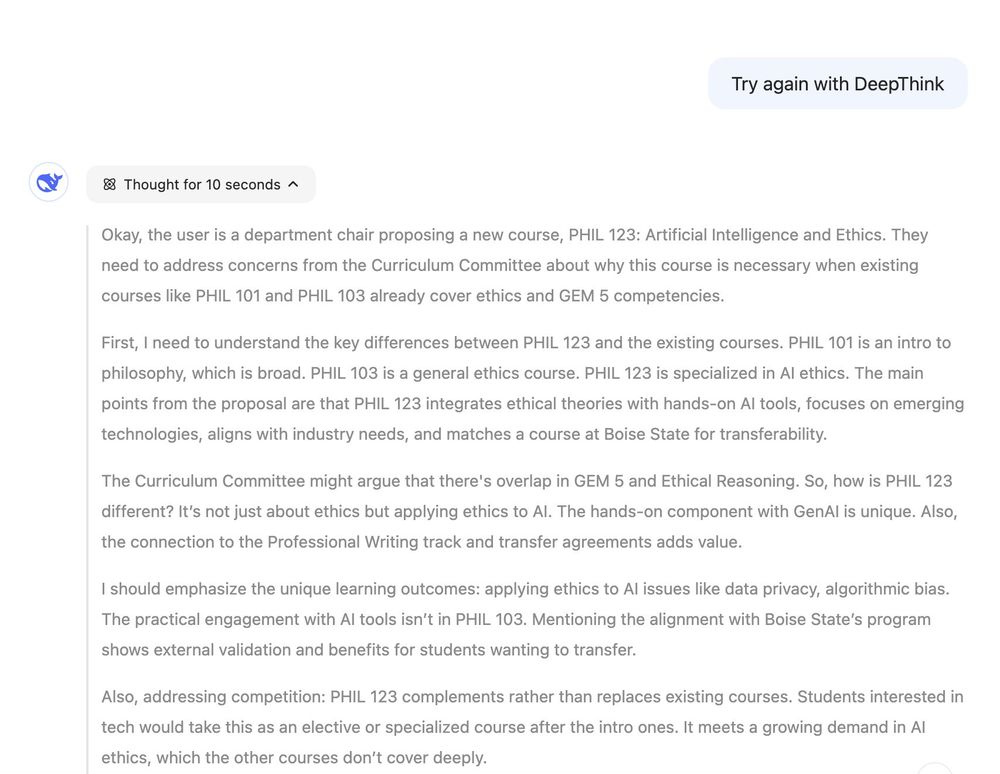

January 22, 2025 at 4:40 PM
I used the DeepSeek R1 reasoning model to prepare for a new course proposal. These screenshots show with and without the "DeepThink" option turned on--strikingly different. R1 does a lot more synthesis and offers clearer suggestions. It also accepts pdf files, o1 doesn't. Crazy this is open source.
it really tied the room together
January 20, 2025 at 5:04 AM
it really tied the room together
Major @openinfra.org 2024 highlights: surging @OpenStack.org adoption driven by AI infrastructure & digital sovereignty; successful migrations from VMware; two on-time releases enhancing AI/ML workload support; + upcoming OpenStack 15th anniversary celebration!
www.openstack.org/blog/opensta...
www.openstack.org/blog/opensta...
OpenStack 2024 Community Progress & Highlights | OpenStack Blog | Open Infrastructure Foundation
www.openstack.org
January 15, 2025 at 4:18 PM
Major @openinfra.org 2024 highlights: surging @OpenStack.org adoption driven by AI infrastructure & digital sovereignty; successful migrations from VMware; two on-time releases enhancing AI/ML workload support; + upcoming OpenStack 15th anniversary celebration!
www.openstack.org/blog/opensta...
www.openstack.org/blog/opensta...
Reposted by Mark Collier

I was interviewed at CES this morning. We mentioned that consumers will decide whether they want to be on a platform that is “unfiltered free speech “ or “ moderated”. I mentioned that I loved @bsky.app , and spontaneously people started clapping 🔥.
January 9, 2025 at 12:16 AM
I was interviewed at CES this morning. We mentioned that consumers will decide whether they want to be on a platform that is “unfiltered free speech “ or “ moderated”. I mentioned that I loved @bsky.app , and spontaneously people started clapping 🔥.
Reposted by Mark Collier
Does anyone have a contact for Ann ? Would love to discuss with her the possibility of partnering with her to publish her cartoons exclusively on @bluesky

Jeff Bezos never wanted this cartoon to become public.
He killed it, and as a result, pulitzer prize editorial cartoonist Ann Telnaes quit.
Make sure everyone sees this cartoon.
He killed it, and as a result, pulitzer prize editorial cartoonist Ann Telnaes quit.
Make sure everyone sees this cartoon.

January 5, 2025 at 1:51 PM
Does anyone have a contact for Ann ? Would love to discuss with her the possibility of partnering with her to publish her cartoons exclusively on @bluesky
Reposted by Mark Collier

Like scarves wrapped around the neck of Johnny Depp, so are the days of our lives.
January 2, 2025 at 3:11 PM
Like scarves wrapped around the neck of Johnny Depp, so are the days of our lives.
While a low-temperature universe theoretically provides an ideal environment for reducing noise, the lack of available energy ironically makes reliable computation—and potentially intelligent life—unsustainable in the long run.
So don't even worry about it.
So don't even worry about it.
January 1, 2025 at 10:45 PM
While a low-temperature universe theoretically provides an ideal environment for reducing noise, the lack of available energy ironically makes reliable computation—and potentially intelligent life—unsustainable in the long run.
So don't even worry about it.
So don't even worry about it.