



Luke Zettlemoyer
@lukezettlemoyer.bsky.social
Professor at UW; Researcher at Meta. LMs, NLP, ML. PNW life.
Reposted by Luke Zettlemoyer

NEW: Luke Zettlemoyer (@lukezettlemoyer.bsky.social) of the University of Washington and Meta AI walks through different approaches to building multimodal foundation models.
Watch the video: youtu.be/vTI4cziw84Q
#NeuroAI2025 #AI #ML #LLMs #NeuroAI
Watch the video: youtu.be/vTI4cziw84Q
#NeuroAI2025 #AI #ML #LLMs #NeuroAI

Mixed-modal Language Modeling with Luke Zettlemoyer
YouTube video by Kempner Institute at Harvard University
youtu.be
June 10, 2025 at 8:43 PM
NEW: Luke Zettlemoyer (@lukezettlemoyer.bsky.social) of the University of Washington and Meta AI walks through different approaches to building multimodal foundation models.
Watch the video: youtu.be/vTI4cziw84Q
#NeuroAI2025 #AI #ML #LLMs #NeuroAI
Watch the video: youtu.be/vTI4cziw84Q
#NeuroAI2025 #AI #ML #LLMs #NeuroAI
Reposted by Luke Zettlemoyer

What if LLMs knew when to stop? 🚧
HALT finetuning teaches LLMs to only generate content they’re confident is correct.
🔍 Insight: Post-training must be adjusted to the model’s capabilities.
⚖️ Tunable trade-off: Higher correctness 🔒 vs. More completeness 📝
🧵
HALT finetuning teaches LLMs to only generate content they’re confident is correct.
🔍 Insight: Post-training must be adjusted to the model’s capabilities.
⚖️ Tunable trade-off: Higher correctness 🔒 vs. More completeness 📝
🧵
June 6, 2025 at 8:22 AM
What if LLMs knew when to stop? 🚧
HALT finetuning teaches LLMs to only generate content they’re confident is correct.
🔍 Insight: Post-training must be adjusted to the model’s capabilities.
⚖️ Tunable trade-off: Higher correctness 🔒 vs. More completeness 📝
🧵
HALT finetuning teaches LLMs to only generate content they’re confident is correct.
🔍 Insight: Post-training must be adjusted to the model’s capabilities.
⚖️ Tunable trade-off: Higher correctness 🔒 vs. More completeness 📝
🧵
Reposted by Luke Zettlemoyer

Excited to continue my research adventure as a postdoc at @uwnlp.bsky.social and Meta! I’ve joined @lukezettlemoyer.bsky.social’s fantastic lab. Together, we plan to rethink how LLMs perceive data to unlock their capabilities to uncharted language and, further, beyond text!


March 31, 2025 at 2:23 PM
Excited to continue my research adventure as a postdoc at @uwnlp.bsky.social and Meta! I’ve joined @lukezettlemoyer.bsky.social’s fantastic lab. Together, we plan to rethink how LLMs perceive data to unlock their capabilities to uncharted language and, further, beyond text!
Reposted by Luke Zettlemoyer

Excited to announce the COLM 2025 keynote speakers: Shirley Ho, Nicholas Carlini, @lukezettlemoyer.bsky.social, and Tom Griffiths!
See you in October in Montreal!
See you in October in Montreal!

March 10, 2025 at 2:34 PM
Excited to announce the COLM 2025 keynote speakers: Shirley Ho, Nicholas Carlini, @lukezettlemoyer.bsky.social, and Tom Griffiths!
See you in October in Montreal!
See you in October in Montreal!
Reposted by Luke Zettlemoyer

Chatbots don't *want* anything and don't *recognize* anything.

Chatbots, Like the Rest of Us, Just Want to Be Loved
A study reveals that large language models recognize when they are being studied and change their behavior to seem more likable.
www.wired.com
March 6, 2025 at 9:28 PM
Chatbots don't *want* anything and don't *recognize* anything.
Reposted by Luke Zettlemoyer
LLMs can't take responsibility for their mistakes. When a human journalist puts their name on AI-written text, they take on that responsibility.
Increasingly I see inaccurate and badly written news stories authored by AI, many of which have actual humans listed as authors or editors.
Increasingly I see inaccurate and badly written news stories authored by AI, many of which have actual humans listed as authors or editors.
February 23, 2025 at 11:56 PM
LLMs can't take responsibility for their mistakes. When a human journalist puts their name on AI-written text, they take on that responsibility.
Increasingly I see inaccurate and badly written news stories authored by AI, many of which have actual humans listed as authors or editors.
Increasingly I see inaccurate and badly written news stories authored by AI, many of which have actual humans listed as authors or editors.
Reposted by Luke Zettlemoyer

#AI hallucinations are a problem; #UWAllen Ph.D. student @akariasai.bsky.social may have the answer. She was named a @techreviewjp.bsky.social Innovator Under 35 for her work to make #LLMs more transparent and useful—without making stuff up. #IU35 #AIforGood
news.cs.washington.edu/2025/01/07/w...
news.cs.washington.edu/2025/01/07/w...

‘Working to solve global problems’: Allen School Ph.D. student Akari Asai named one of MIT Technology Review’s Innovators Under 35 Japan - Allen School News
Despite their growing potential and increasing popularity, large language models (LLMs) often produce responses that are factually inaccurate or nonsensical, also known as hallucinations. Allen School...
news.cs.washington.edu
January 8, 2025 at 10:58 PM
#AI hallucinations are a problem; #UWAllen Ph.D. student @akariasai.bsky.social may have the answer. She was named a @techreviewjp.bsky.social Innovator Under 35 for her work to make #LLMs more transparent and useful—without making stuff up. #IU35 #AIforGood
news.cs.washington.edu/2025/01/07/w...
news.cs.washington.edu/2025/01/07/w...
Reposted by Luke Zettlemoyer

My Keynote Talk entitled “Dungeons and DQNs: The Serious Quest for Open Ended Role Playing Game Playing Agents” is now online.
youtu.be/EiurL9eyUNc
In which I might or might not have said “I’m working to take the ‘ick’ out of ‘agentic’”
youtu.be/EiurL9eyUNc
In which I might or might not have said “I’m working to take the ‘ick’ out of ‘agentic’”

Dungeons and DQNs: The Serious Quest for Open Ended Role Playing Game Playing Agents
YouTube video by AIIDE Conference
youtu.be
January 9, 2025 at 1:15 AM
My Keynote Talk entitled “Dungeons and DQNs: The Serious Quest for Open Ended Role Playing Game Playing Agents” is now online.
youtu.be/EiurL9eyUNc
In which I might or might not have said “I’m working to take the ‘ick’ out of ‘agentic’”
youtu.be/EiurL9eyUNc
In which I might or might not have said “I’m working to take the ‘ick’ out of ‘agentic’”
Reposted by Luke Zettlemoyer

kicking off 2025 with our OLMo 2 tech report while payin homage to the sequelest of sequels 🫡
🚗 2 OLMo 2 Furious 🔥 is everythin we learned since OLMo 1, with deep dives into:
🚖 stable pretrain recipe
🚔 lr anneal 🤝 data curricula 🤝 soups
🚘 tulu post-train recipe
🚜 compute infra setup
👇🧵
🚗 2 OLMo 2 Furious 🔥 is everythin we learned since OLMo 1, with deep dives into:
🚖 stable pretrain recipe
🚔 lr anneal 🤝 data curricula 🤝 soups
🚘 tulu post-train recipe
🚜 compute infra setup
👇🧵

January 3, 2025 at 4:02 PM
kicking off 2025 with our OLMo 2 tech report while payin homage to the sequelest of sequels 🫡
🚗 2 OLMo 2 Furious 🔥 is everythin we learned since OLMo 1, with deep dives into:
🚖 stable pretrain recipe
🚔 lr anneal 🤝 data curricula 🤝 soups
🚘 tulu post-train recipe
🚜 compute infra setup
👇🧵
🚗 2 OLMo 2 Furious 🔥 is everythin we learned since OLMo 1, with deep dives into:
🚖 stable pretrain recipe
🚔 lr anneal 🤝 data curricula 🤝 soups
🚘 tulu post-train recipe
🚜 compute infra setup
👇🧵
Reposted by Luke Zettlemoyer

📚 How good are language models at utilising contexts in RAG scenarios?
We release 🧙🏽♀️DRUID to facilitate studies of context usage in real-world scenarios.
arxiv.org/abs/2412.17031
w/ @saravera.bsky.social, H.Yu, @rnv.bsky.social, C.Lioma, M.Maistro, @apepa.bsky.social and @iaugenstein.bsky.social ⭐️
We release 🧙🏽♀️DRUID to facilitate studies of context usage in real-world scenarios.
arxiv.org/abs/2412.17031
w/ @saravera.bsky.social, H.Yu, @rnv.bsky.social, C.Lioma, M.Maistro, @apepa.bsky.social and @iaugenstein.bsky.social ⭐️

A Reality Check on Context Utilisation for Retrieval-Augmented Generation
Retrieval-augmented generation (RAG) helps address the limitations of the parametric knowledge embedded within a language model (LM). However, investigations of how LMs utilise retrieved information o...
arxiv.org
January 2, 2025 at 7:15 AM
📚 How good are language models at utilising contexts in RAG scenarios?
We release 🧙🏽♀️DRUID to facilitate studies of context usage in real-world scenarios.
arxiv.org/abs/2412.17031
w/ @saravera.bsky.social, H.Yu, @rnv.bsky.social, C.Lioma, M.Maistro, @apepa.bsky.social and @iaugenstein.bsky.social ⭐️
We release 🧙🏽♀️DRUID to facilitate studies of context usage in real-world scenarios.
arxiv.org/abs/2412.17031
w/ @saravera.bsky.social, H.Yu, @rnv.bsky.social, C.Lioma, M.Maistro, @apepa.bsky.social and @iaugenstein.bsky.social ⭐️
Reposted by Luke Zettlemoyer

🚀 Introducing the Byte Latent Transformer (BLT) – A LLM architecture that scales better than Llama 3 using patches instead of tokens 🤯
Paper 📄 dl.fbaipublicfiles.com/blt/BLT__Pat...
Code 🛠️ github.com/facebookrese...
Paper 📄 dl.fbaipublicfiles.com/blt/BLT__Pat...
Code 🛠️ github.com/facebookrese...
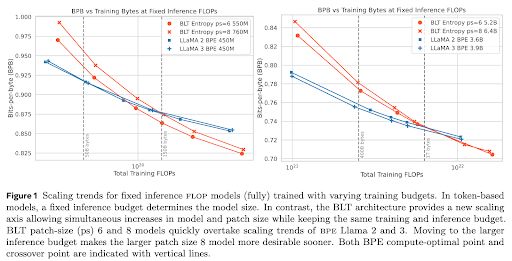
December 13, 2024 at 4:53 PM
🚀 Introducing the Byte Latent Transformer (BLT) – A LLM architecture that scales better than Llama 3 using patches instead of tokens 🤯
Paper 📄 dl.fbaipublicfiles.com/blt/BLT__Pat...
Code 🛠️ github.com/facebookrese...
Paper 📄 dl.fbaipublicfiles.com/blt/BLT__Pat...
Code 🛠️ github.com/facebookrese...
Reposted by Luke Zettlemoyer

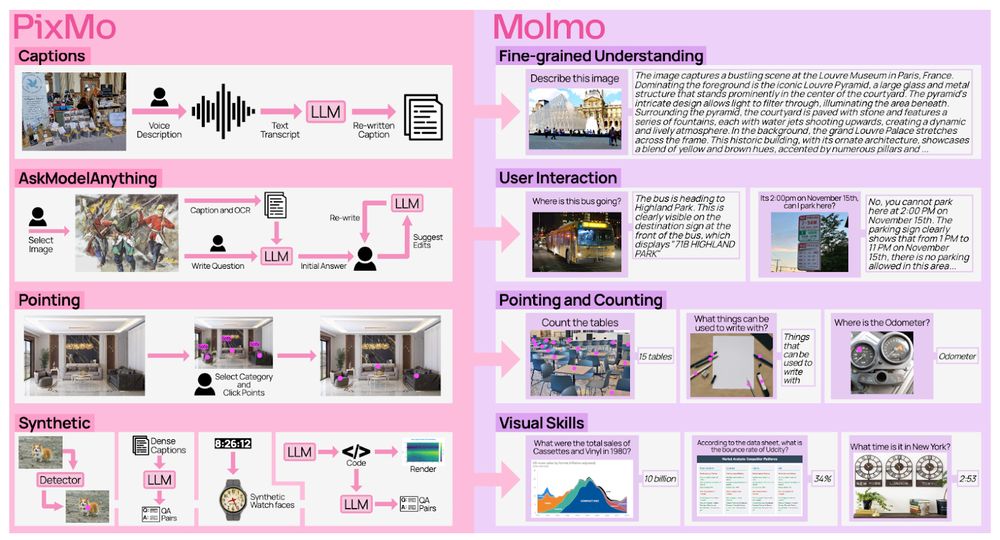
Remember Molmo? The full recipe is finally out!
Training code, data, and everything you need to reproduce our models. Oh, and we have updated our tech report too!
Links in thread 👇
Training code, data, and everything you need to reproduce our models. Oh, and we have updated our tech report too!
Links in thread 👇
December 9, 2024 at 6:34 PM
Remember Molmo? The full recipe is finally out!
Training code, data, and everything you need to reproduce our models. Oh, and we have updated our tech report too!
Links in thread 👇
Training code, data, and everything you need to reproduce our models. Oh, and we have updated our tech report too!
Links in thread 👇
Reposted by Luke Zettlemoyer

Check out my new piece on AI terms of use restrictions w/ Mark Lemley ( @marklemley.bsky.social ).
There's been a recent stir about terms of use restrictions on AI outputs & models. We dig into the legal analysis, questioning their enforceability.
Link: papers.ssrn.com/sol3/papers....
There's been a recent stir about terms of use restrictions on AI outputs & models. We dig into the legal analysis, questioning their enforceability.
Link: papers.ssrn.com/sol3/papers....

December 10, 2024 at 12:39 AM
Check out my new piece on AI terms of use restrictions w/ Mark Lemley ( @marklemley.bsky.social ).
There's been a recent stir about terms of use restrictions on AI outputs & models. We dig into the legal analysis, questioning their enforceability.
Link: papers.ssrn.com/sol3/papers....
There's been a recent stir about terms of use restrictions on AI outputs & models. We dig into the legal analysis, questioning their enforceability.
Link: papers.ssrn.com/sol3/papers....
Reposted by Luke Zettlemoyer

I’m on the academic job market this year! I’m completing my @uwcse.bsky.social @uwnlp.bsky.social Ph.D. (2025), focusing on overcoming LLM limitations like hallucinations, by building new LMs.
My Ph.D. work focuses on Retrieval-Augmented LMs to create more reliable AI systems 🧵
My Ph.D. work focuses on Retrieval-Augmented LMs to create more reliable AI systems 🧵

December 4, 2024 at 1:26 PM
I’m on the academic job market this year! I’m completing my @uwcse.bsky.social @uwnlp.bsky.social Ph.D. (2025), focusing on overcoming LLM limitations like hallucinations, by building new LMs.
My Ph.D. work focuses on Retrieval-Augmented LMs to create more reliable AI systems 🧵
My Ph.D. work focuses on Retrieval-Augmented LMs to create more reliable AI systems 🧵
Reposted by Luke Zettlemoyer

I'm on the academic job market!
I develop autonomous systems for: programming, research-level question answering, finding sec vulnerabilities & other useful+challenging tasks.
I do this by building frontier-pushing benchmarks and agents that do well on them.
See you at NeurIPS!
I develop autonomous systems for: programming, research-level question answering, finding sec vulnerabilities & other useful+challenging tasks.
I do this by building frontier-pushing benchmarks and agents that do well on them.
See you at NeurIPS!

December 4, 2024 at 4:52 PM
I'm on the academic job market!
I develop autonomous systems for: programming, research-level question answering, finding sec vulnerabilities & other useful+challenging tasks.
I do this by building frontier-pushing benchmarks and agents that do well on them.
See you at NeurIPS!
I develop autonomous systems for: programming, research-level question answering, finding sec vulnerabilities & other useful+challenging tasks.
I do this by building frontier-pushing benchmarks and agents that do well on them.
See you at NeurIPS!
Reposted by Luke Zettlemoyer

I'm excited about scaling up robot learning! We’ve been scaling up data gen with RL in realistic sims generated from crowdsourced videos. Enables data collection far more cheaply than real world teleop. Importantly, data becomes *cheaper* with more environments and transfers to real robots! 🧵 (1/N)
December 5, 2024 at 2:13 AM
I'm excited about scaling up robot learning! We’ve been scaling up data gen with RL in realistic sims generated from crowdsourced videos. Enables data collection far more cheaply than real world teleop. Importantly, data becomes *cheaper* with more environments and transfers to real robots! 🧵 (1/N)
Reposted by Luke Zettlemoyer

We just updated the OLMo repo at github.com/allenai/OLMo!
There are now several training configs that together reproduce the training runs that lead to the final OLMo 2 models.
In particular, all the training data is available, tokenized and shuffled exactly as we trained on it!
There are now several training configs that together reproduce the training runs that lead to the final OLMo 2 models.
In particular, all the training data is available, tokenized and shuffled exactly as we trained on it!
GitHub - allenai/OLMo: Modeling, training, eval, and inference code for OLMo
Modeling, training, eval, and inference code for OLMo - allenai/OLMo
github.com
December 2, 2024 at 8:13 PM
We just updated the OLMo repo at github.com/allenai/OLMo!
There are now several training configs that together reproduce the training runs that lead to the final OLMo 2 models.
In particular, all the training data is available, tokenized and shuffled exactly as we trained on it!
There are now several training configs that together reproduce the training runs that lead to the final OLMo 2 models.
In particular, all the training data is available, tokenized and shuffled exactly as we trained on it!
Reposted by Luke Zettlemoyer

Hi everyone, I am excited to share our large-scale survey study with 800+ researchers, which reveals researchers’ usage and perceptions of LLMs as research tools, and how the usage and perceptions differ based on demographics.
See results in comments!
🔗 Arxiv link: arxiv.org/abs/2411.05025
See results in comments!
🔗 Arxiv link: arxiv.org/abs/2411.05025

LLMs as Research Tools: A Large Scale Survey of Researchers' Usage and Perceptions
The rise of large language models (LLMs) has led many researchers to consider their usage for scientific work. Some have found benefits using LLMs to augment or automate aspects of their research pipe...
arxiv.org
December 2, 2024 at 7:45 PM
Hi everyone, I am excited to share our large-scale survey study with 800+ researchers, which reveals researchers’ usage and perceptions of LLMs as research tools, and how the usage and perceptions differ based on demographics.
See results in comments!
🔗 Arxiv link: arxiv.org/abs/2411.05025
See results in comments!
🔗 Arxiv link: arxiv.org/abs/2411.05025
Reposted by Luke Zettlemoyer

How do LLMs learn to reason from data? Are they ~retrieving the answers from parametric knowledge🦜? In our new preprint, we look at the pretraining data and find evidence against this:
Procedural knowledge in pretraining drives LLM reasoning ⚙️🔢
🧵⬇️
Procedural knowledge in pretraining drives LLM reasoning ⚙️🔢
🧵⬇️
November 20, 2024 at 4:35 PM
How do LLMs learn to reason from data? Are they ~retrieving the answers from parametric knowledge🦜? In our new preprint, we look at the pretraining data and find evidence against this:
Procedural knowledge in pretraining drives LLM reasoning ⚙️🔢
🧵⬇️
Procedural knowledge in pretraining drives LLM reasoning ⚙️🔢
🧵⬇️
Reposted by Luke Zettlemoyer

We should make sure that only really big companies can afford to pay really big copyright holders to access the data needed to do stuff with AI, and keep everyone else out.
Wouldn’t that be just super?
Wouldn’t that be just super?
November 28, 2024 at 5:04 AM
We should make sure that only really big companies can afford to pay really big copyright holders to access the data needed to do stuff with AI, and keep everyone else out.
Wouldn’t that be just super?
Wouldn’t that be just super?
Reposted by Luke Zettlemoyer

I am seeking multiple PhD students passionate about Generative Intelligence and its applications in empowering AI agents to interact with the physical world to join us at UPenn CIS for the 2024-2025 academic cycle. You can find more information at www.cis.upenn.edu/graduate/pro...
Doctoral Program
Doctoral Program
www.cis.upenn.edu
November 27, 2024 at 1:18 AM
I am seeking multiple PhD students passionate about Generative Intelligence and its applications in empowering AI agents to interact with the physical world to join us at UPenn CIS for the 2024-2025 academic cycle. You can find more information at www.cis.upenn.edu/graduate/pro...
Reposted by Luke Zettlemoyer

OLMo 2 is out 🥳 7B and 13B trained on 5T tokens, and meticulousy instruction tuned using Tulu 3 recipe.
Simply the best fully open models yet.
Really proud of the work & the amazing team at
@ai2.bsky.social
Simply the best fully open models yet.
Really proud of the work & the amazing team at
@ai2.bsky.social
November 26, 2024 at 9:12 PM
OLMo 2 is out 🥳 7B and 13B trained on 5T tokens, and meticulousy instruction tuned using Tulu 3 recipe.
Simply the best fully open models yet.
Really proud of the work & the amazing team at
@ai2.bsky.social
Simply the best fully open models yet.
Really proud of the work & the amazing team at
@ai2.bsky.social
Reposted by Luke Zettlemoyer
Excited to share OLMo 2!
🐟 7B and 13B weights, trained up to 4-5T tokens, fully open data, code, etc
🐠 better architecture and recipe for training stability
🐡 staged training, with new data mix Dolmino🍕 added during annealing
🦈 state-of-the-art OLMo 2 Instruct models
#nlp #mlsky
links below👇
🐟 7B and 13B weights, trained up to 4-5T tokens, fully open data, code, etc
🐠 better architecture and recipe for training stability
🐡 staged training, with new data mix Dolmino🍕 added during annealing
🦈 state-of-the-art OLMo 2 Instruct models
#nlp #mlsky
links below👇

November 26, 2024 at 8:59 PM
Reposted by Luke Zettlemoyer

very interesting work and it reminds me a bit of this paper. Tokenizers and ROPE must die. after samplers, i am on to those next ...
arxiv.org/abs/2407.036...
arxiv.org/abs/2407.036...
November 25, 2024 at 2:20 AM
very interesting work and it reminds me a bit of this paper. Tokenizers and ROPE must die. after samplers, i am on to those next ...
arxiv.org/abs/2407.036...
arxiv.org/abs/2407.036...