



Luke Marris
@lukemarris.bsky.social
Research Engineer at Google DeepMind.
Interests in game theory, reinforcement learning, and deep learning.
Website: https://www.lukemarris.info/
Google Scholar: https://scholar.google.com/citations?user=dvTeSX4AAAAJ
Interests in game theory, reinforcement learning, and deep learning.
Website: https://www.lukemarris.info/
Google Scholar: https://scholar.google.com/citations?user=dvTeSX4AAAAJ
[🧵5/N] Does it work? YES! ✅On real data (arena-hard-v0.1), our method provides intuitive rankings robust to redundancy. We added 500 adversarial prompts targeting the top model – Elo rankings tanked, ours stayed stable! (See Fig 3 👇). Scales & gives interpretable insights!

April 17, 2025 at 4:12 PM
[🧵5/N] Does it work? YES! ✅On real data (arena-hard-v0.1), our method provides intuitive rankings robust to redundancy. We added 500 adversarial prompts targeting the top model – Elo rankings tanked, ours stayed stable! (See Fig 3 👇). Scales & gives interpretable insights!
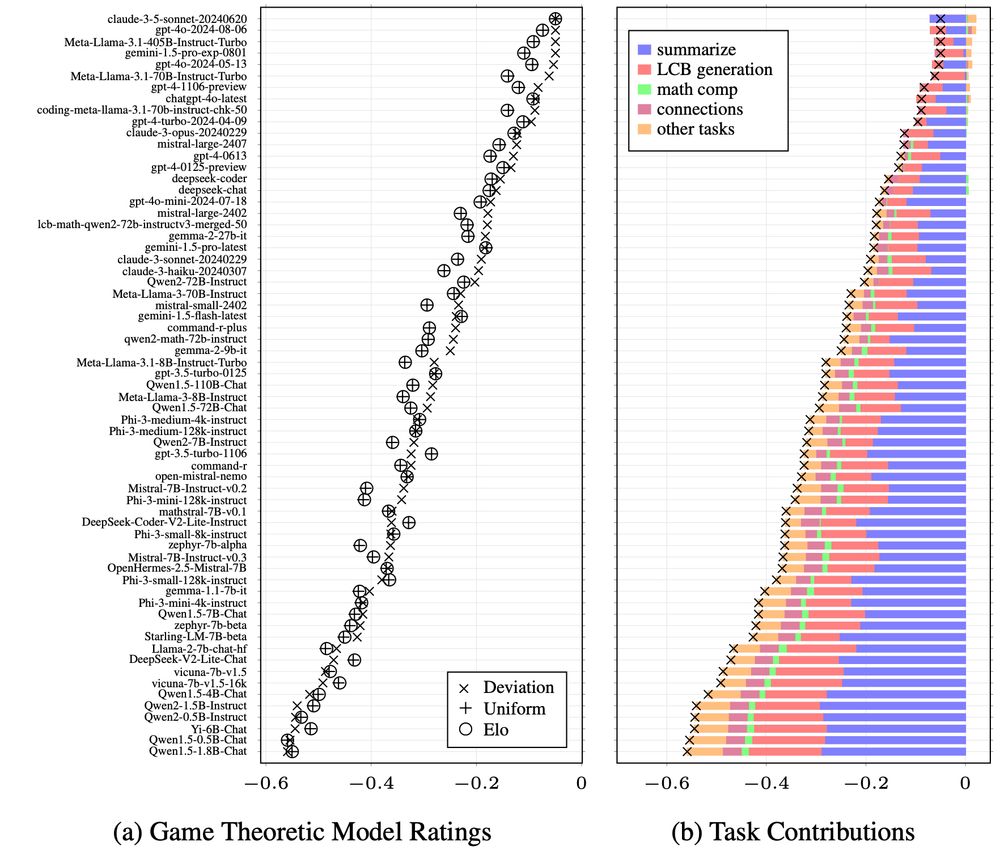
[🧵13/N] It is also possible to plot each task's contribution to the deviation rating, enabling to quickly see the trade-offs between the models. Negative bars mean worse than equilibrium at that task. So Sonnet is relatively weaker at "summarize" and Llama is relatively weaker at "LCB generation".
February 24, 2025 at 2:00 PM
[🧵13/N] It is also possible to plot each task's contribution to the deviation rating, enabling to quickly see the trade-offs between the models. Negative bars mean worse than equilibrium at that task. So Sonnet is relatively weaker at "summarize" and Llama is relatively weaker at "LCB generation".