


Liu, Shuze
@liushuze.bsky.social
PhD student @ Harvard || computational cognitive science, human decision making and reasoning
In a large-action-space contextual bandit experiment, we found that humans exploit the above interplay, enlarging action sets alongside policy complexity to mitigate suboptimality. Under time limits, they remain near-optimal for their chosen action set, indicating spontaneous problem simplification.

August 19, 2025 at 4:03 AM
In a large-action-space contextual bandit experiment, we found that humans exploit the above interplay, enlarging action sets alongside policy complexity to mitigate suboptimality. Under time limits, they remain near-optimal for their chosen action set, indicating spontaneous problem simplification.
Using rate-distortion theory, we assess suboptimalities incurred by smaller action consideration set sizes at various levels of policy state-dependence. We rationalize empirical signatures of human option generation as adaptations to joint limitations on action set size and policy complexity.

August 19, 2025 at 4:01 AM
Using rate-distortion theory, we assess suboptimalities incurred by smaller action consideration set sizes at various levels of policy state-dependence. We rationalize empirical signatures of human option generation as adaptations to joint limitations on action set size and policy complexity.
In real-life decisions, vast action spaces often preclude our exhaustive consideration. Furthermore, cognitive constraints limit the state-dependence of policies that map world states to the actions considered. We build a resource-rational framework unifying both ecologically relevant constraints!

August 19, 2025 at 3:58 AM
In real-life decisions, vast action spaces often preclude our exhaustive consideration. Furthermore, cognitive constraints limit the state-dependence of policies that map world states to the actions considered. We build a resource-rational framework unifying both ecologically relevant constraints!
We found that humans meta-reason their policy complexity according to both time and mental costs, exhibiting consistently supralinear mental cost functions across tasks. This overturns common assumptions, and supports the construct validity of info-theoretic measures as a domain-general mental cost!

July 27, 2025 at 7:41 PM
We found that humans meta-reason their policy complexity according to both time and mental costs, exhibiting consistently supralinear mental cost functions across tasks. This overturns common assumptions, and supports the construct validity of info-theoretic measures as a domain-general mental cost!
To address this literature gap, we designed a series of contextual bandit experiments---addressing speed-accuracy tradeoffs, working memory set size manipulations, and reward magnitudes---to stress-test the mutual information formulation of mental costs and look for consistent relationships.

July 27, 2025 at 7:36 PM
To address this literature gap, we designed a series of contextual bandit experiments---addressing speed-accuracy tradeoffs, working memory set size manipulations, and reward magnitudes---to stress-test the mutual information formulation of mental costs and look for consistent relationships.
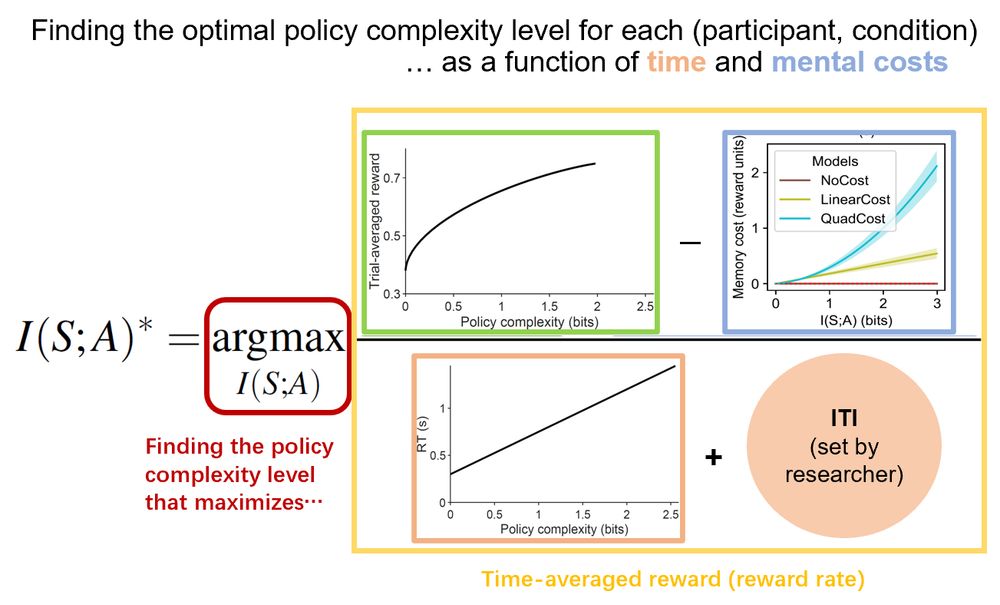
While rational inattention & policy compression have formulated mental costs via mutual information, there remains disagreement on whether it induces a capacity limit or a linear cost. Time costs further confound the picture, as they also incentivize low policy complexity to reduce decision time.
July 27, 2025 at 7:34 PM
While rational inattention & policy compression have formulated mental costs via mutual information, there remains disagreement on whether it induces a capacity limit or a linear cost. Time costs further confound the picture, as they also incentivize low policy complexity to reduce decision time.
We found that key model choices drastically affect fits and better explain the human central tendency:
1) Human priors are non-Gaussian;
2) Sensory noise is heteroskedastic, dipping centrally and plateauing peripherally;
3) Both model averaging (optimal) and probability matching fit behavior well.
1) Human priors are non-Gaussian;
2) Sensory noise is heteroskedastic, dipping centrally and plateauing peripherally;
3) Both model averaging (optimal) and probability matching fit behavior well.

June 11, 2025 at 3:54 PM
We found that key model choices drastically affect fits and better explain the human central tendency:
1) Human priors are non-Gaussian;
2) Sensory noise is heteroskedastic, dipping centrally and plateauing peripherally;
3) Both model averaging (optimal) and probability matching fit behavior well.
1) Human priors are non-Gaussian;
2) Sensory noise is heteroskedastic, dipping centrally and plateauing peripherally;
3) Both model averaging (optimal) and probability matching fit behavior well.
We explore modeling choices in Bayesian cue integration—priors, sensory noise functions, and causal inference strategies—using a data-driven, semiparametric approach. With promising candidates identified, we enumerate them in a combinatorial model space and test them via model comparison.

June 11, 2025 at 3:48 PM
We explore modeling choices in Bayesian cue integration—priors, sensory noise functions, and causal inference strategies—using a data-driven, semiparametric approach. With promising candidates identified, we enumerate them in a combinatorial model space and test them via model comparison.
@weijima.bsky.social, @lacerbi.bsky.social, Trevor, and I have a new preprint on Bayesian models of multisensory perception!
We systematically inspect the underexplored degrees of freedom in Bayesian models, squeezing out their best capability in capturing human behavior.
osf.io/preprints/ps...
We systematically inspect the underexplored degrees of freedom in Bayesian models, squeezing out their best capability in capturing human behavior.
osf.io/preprints/ps...

June 11, 2025 at 3:43 PM
@weijima.bsky.social, @lacerbi.bsky.social, Trevor, and I have a new preprint on Bayesian models of multisensory perception!
We systematically inspect the underexplored degrees of freedom in Bayesian models, squeezing out their best capability in capturing human behavior.
osf.io/preprints/ps...
We systematically inspect the underexplored degrees of freedom in Bayesian models, squeezing out their best capability in capturing human behavior.
osf.io/preprints/ps...
Across three experiments, humans adaptively adjusted policy complexity in the predicted directions (though with a leftward bias, which we model via memory costs in our CogSci paper). LBA modeling revealed that policy-compression-style perseveration had manifested strongly in participant behavior.

April 12, 2025 at 7:04 PM
Across three experiments, humans adaptively adjusted policy complexity in the predicted directions (though with a leftward bias, which we model via memory costs in our CogSci paper). LBA modeling revealed that policy-compression-style perseveration had manifested strongly in participant behavior.
Given policy complexity-RT relations, we can derive policy complexity levels that maximize reward over time. This generates predictions across various task manipulations, including ITIs, reward regularities, and set sizes (reward magnitudes forthcoming in CogSci 2025), which we test in this paper.


April 12, 2025 at 7:04 PM
Given policy complexity-RT relations, we can derive policy complexity levels that maximize reward over time. This generates predictions across various task manipulations, including ITIs, reward regularities, and set sizes (reward magnitudes forthcoming in CogSci 2025), which we test in this paper.
Policy compression applies rate-distortion theory to action selection, specifying the attainable reward at every policy state-dependence/complexity level. It prescribes a linear relationship b/w policy complexity and RTs, and rationalizes action perserveration as optimal usage of limited resources.

April 12, 2025 at 7:03 PM
Policy compression applies rate-distortion theory to action selection, specifying the attainable reward at every policy state-dependence/complexity level. It prescribes a linear relationship b/w policy complexity and RTs, and rationalizes action perserveration as optimal usage of limited resources.
Across three experiments spanning asset selection and switching scenarios, varying time horizons, and different statistical properties of asset trajectories, we show that the Bayesian probabilistic forecasting model consistently outperforms myopic heuristics inspired by existing frameworks. (5/6)

March 23, 2025 at 1:02 AM
Across three experiments spanning asset selection and switching scenarios, varying time horizons, and different statistical properties of asset trajectories, we show that the Bayesian probabilistic forecasting model consistently outperforms myopic heuristics inspired by existing frameworks. (5/6)
Here we develop a normative model: humans use Bayesian function learning to extrapolate asset performance trajectories, making decisions based on forecasted outcomes at a task-specific time horizon. Prior knowledge informs these inferences, enabling comparisons between current and new options. (4/6)

March 23, 2025 at 1:02 AM
Here we develop a normative model: humans use Bayesian function learning to extrapolate asset performance trajectories, making decisions based on forecasted outcomes at a task-specific time horizon. Prior knowledge informs these inferences, enabling comparisons between current and new options. (4/6)