




Kyle Lo
@kylelo.bsky.social
language model pretraining @ai2.bsky.social, co-lead of data research w/ @soldaini.net, statistics @uw, open science, tabletop, seattle, he/him,🧋 kyleclo.com
why intern at Ai2?
🐟interns own major parts of our model development, sometimes even leading whole projects
🐡we're committed to open science & actively help our interns publish their work
reach out if u wanna build open language models together 🤝
links 👇
🐟interns own major parts of our model development, sometimes even leading whole projects
🐡we're committed to open science & actively help our interns publish their work
reach out if u wanna build open language models together 🤝
links 👇

November 5, 2025 at 11:11 PM
why intern at Ai2?
🐟interns own major parts of our model development, sometimes even leading whole projects
🐡we're committed to open science & actively help our interns publish their work
reach out if u wanna build open language models together 🤝
links 👇
🐟interns own major parts of our model development, sometimes even leading whole projects
🐡we're committed to open science & actively help our interns publish their work
reach out if u wanna build open language models together 🤝
links 👇
woah guess VLMs for OCR the hottest research topic this week😆 since the first olmOCR, we've been..
🔥training our VLM using RLVR with binary unit test rewards🔥
it's incredibly effective & unit test creation easy to scale w synthetic data pipelines
check it out at olmocr.allen.ai
🔥training our VLM using RLVR with binary unit test rewards🔥
it's incredibly effective & unit test creation easy to scale w synthetic data pipelines
check it out at olmocr.allen.ai

October 22, 2025 at 6:02 PM
woah guess VLMs for OCR the hottest research topic this week😆 since the first olmOCR, we've been..
🔥training our VLM using RLVR with binary unit test rewards🔥
it's incredibly effective & unit test creation easy to scale w synthetic data pipelines
check it out at olmocr.allen.ai
🔥training our VLM using RLVR with binary unit test rewards🔥
it's incredibly effective & unit test creation easy to scale w synthetic data pipelines
check it out at olmocr.allen.ai

lol so much love for prepost-postpre training

October 9, 2025 at 5:13 PM
lol so much love for prepost-postpre training
any other fans of pre-pretraining?

October 9, 2025 at 2:53 PM
any other fans of pre-pretraining?
come say hi at posters this morning for OLMo 2 and fluid benchmarking posters 👋 and dont miss @valentinhofmann.bsky.social's talk in morning #colm2025 @ai2.bsky.social vry proud of my gifs
October 9, 2025 at 1:14 PM
come say hi at posters this morning for OLMo 2 and fluid benchmarking posters 👋 and dont miss @valentinhofmann.bsky.social's talk in morning #colm2025 @ai2.bsky.social vry proud of my gifs
@josephc.bsky.social @mariaa.bsky.social and I are at poster #21
findings from large scale survey of 800 researchers on how they use LMs in their research #colm2025
findings from large scale survey of 800 researchers on how they use LMs in their research #colm2025

October 8, 2025 at 8:12 PM
@josephc.bsky.social @mariaa.bsky.social and I are at poster #21
findings from large scale survey of 800 researchers on how they use LMs in their research #colm2025
findings from large scale survey of 800 researchers on how they use LMs in their research #colm2025
flyin to #colm2025 along w bunch of the @ai2.bsky.social team
come chat w me about pretraining horror stories, data & evals, what we're cookin for next olmo, etc
made a 🔥 poster for thursday sess, come say hi
come chat w me about pretraining horror stories, data & evals, what we're cookin for next olmo, etc
made a 🔥 poster for thursday sess, come say hi
October 6, 2025 at 3:20 PM
flyin to #colm2025 along w bunch of the @ai2.bsky.social team
come chat w me about pretraining horror stories, data & evals, what we're cookin for next olmo, etc
made a 🔥 poster for thursday sess, come say hi
come chat w me about pretraining horror stories, data & evals, what we're cookin for next olmo, etc
made a 🔥 poster for thursday sess, come say hi

LM benchmark design requires 3 decisions, how to:
🐟 select test cases
🐠 score LM on each test
🦈 aggregate scores to estimate perf
fluid benchmarking is simple:
🍣 find max informative test cases
🍥 estimate 'ability', not simple avg perf
why care? turn ur grey noisy benchmarks to red ones!
🐟 select test cases
🐠 score LM on each test
🦈 aggregate scores to estimate perf
fluid benchmarking is simple:
🍣 find max informative test cases
🍥 estimate 'ability', not simple avg perf
why care? turn ur grey noisy benchmarks to red ones!

September 17, 2025 at 6:17 PM
LM benchmark design requires 3 decisions, how to:
🐟 select test cases
🐠 score LM on each test
🦈 aggregate scores to estimate perf
fluid benchmarking is simple:
🍣 find max informative test cases
🍥 estimate 'ability', not simple avg perf
why care? turn ur grey noisy benchmarks to red ones!
🐟 select test cases
🐠 score LM on each test
🦈 aggregate scores to estimate perf
fluid benchmarking is simple:
🍣 find max informative test cases
🍥 estimate 'ability', not simple avg perf
why care? turn ur grey noisy benchmarks to red ones!
looks like the preprint has been updated to include a disclaimer that this was a class project & intentionally provocatively written 😐

August 20, 2025 at 5:30 PM
looks like the preprint has been updated to include a disclaimer that this was a class project & intentionally provocatively written 😐
⚠️ AI-generated content may be inaccurate. Verify important information independently.

August 8, 2025 at 8:33 PM
⚠️ AI-generated content may be inaccurate. Verify important information independently.
only took few days to descend into madness

July 1, 2025 at 8:12 PM
only took few days to descend into madness
back from copenhagen & berkeley travels, now moving into new @ai2.bsky.social office!

June 26, 2025 at 3:45 PM
back from copenhagen & berkeley travels, now moving into new @ai2.bsky.social office!
thx for organizing! great to meet NLP folks & consume fancy bread 🥖🍞🥐

June 21, 2025 at 2:32 PM
thx for organizing! great to meet NLP folks & consume fancy bread 🥖🍞🥐
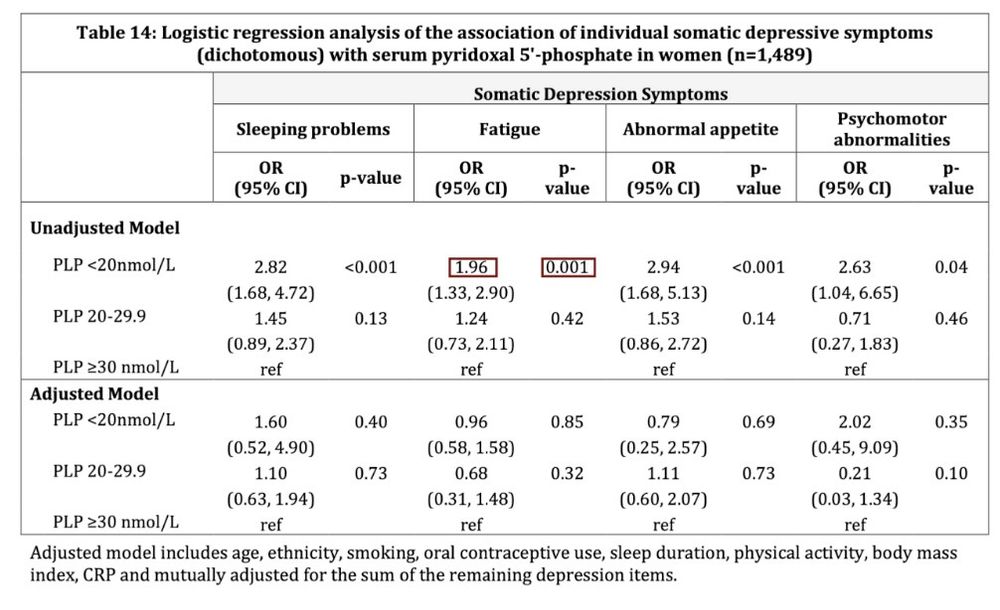
the benchmark works based on thousands of "unit tests"
so instead of fuzzy matching between a model-generated table with a gold reference table,
we define Pass/Fail tests like "the cell to the left of the cell containing 0.001 should contain 1.96"
so instead of fuzzy matching between a model-generated table with a gold reference table,
we define Pass/Fail tests like "the cell to the left of the cell containing 0.001 should contain 1.96"
June 19, 2025 at 1:25 PM
the benchmark works based on thousands of "unit tests"
so instead of fuzzy matching between a model-generated table with a gold reference table,
we define Pass/Fail tests like "the cell to the left of the cell containing 0.001 should contain 1.96"
so instead of fuzzy matching between a model-generated table with a gold reference table,
we define Pass/Fail tests like "the cell to the left of the cell containing 0.001 should contain 1.96"
we won honorable mention for Best Paper at #CVPR2025 🏆 for Molmo & Pixmo, showing the value of high-quality data for VLMs!
recalling when we released same time as Llama 3.2 😆
huge kudos to Matt Deitke, Chris Clark & Ani Kembhavi for their leadership on this project!
@cvprconference.bsky.social
recalling when we released same time as Llama 3.2 😆
huge kudos to Matt Deitke, Chris Clark & Ani Kembhavi for their leadership on this project!
@cvprconference.bsky.social

June 13, 2025 at 5:46 PM
we won honorable mention for Best Paper at #CVPR2025 🏆 for Molmo & Pixmo, showing the value of high-quality data for VLMs!
recalling when we released same time as Llama 3.2 😆
huge kudos to Matt Deitke, Chris Clark & Ani Kembhavi for their leadership on this project!
@cvprconference.bsky.social
recalling when we released same time as Llama 3.2 😆
huge kudos to Matt Deitke, Chris Clark & Ani Kembhavi for their leadership on this project!
@cvprconference.bsky.social
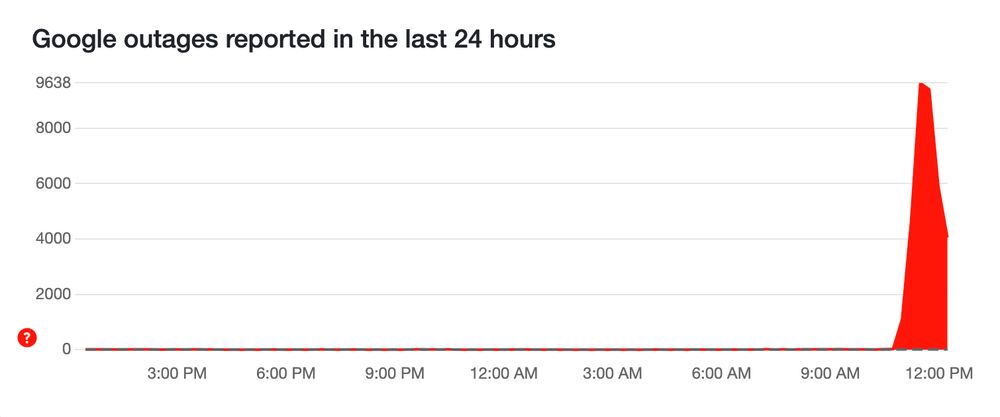
google down, guess ill go smell flowers or sthn 🤷♂️
June 12, 2025 at 7:32 PM
google down, guess ill go smell flowers or sthn 🤷♂️
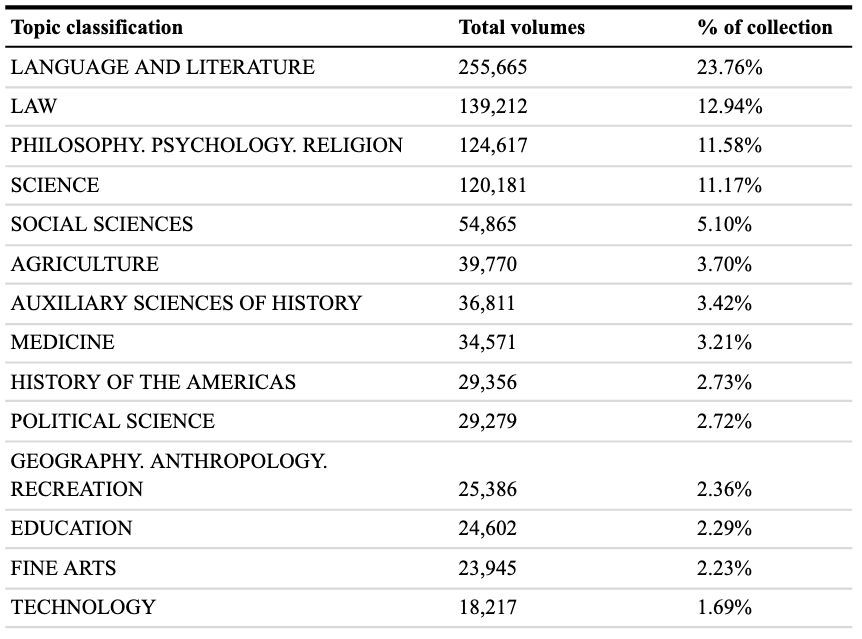
excited to see this release of 1M public domain & CC zero books, digitized and OCR'd! 👏 big win for open data, congrats to the authors!
arxiv.org/abs/2506.08300
arxiv.org/abs/2506.08300
June 12, 2025 at 12:21 AM
excited to see this release of 1M public domain & CC zero books, digitized and OCR'd! 👏 big win for open data, congrats to the authors!
arxiv.org/abs/2506.08300
arxiv.org/abs/2506.08300
looks like same group got an AI generated paper accepted to ACL 😅 www.intology.ai/blog/zochi-acl

May 29, 2025 at 12:18 AM
looks like same group got an AI generated paper accepted to ACL 😅 www.intology.ai/blog/zochi-acl
hilarious deep research UX w/ the agent trace
it's like "i found relevant content in <journal|conf|arxiv> paper" but the links provided all go to the publisher homepage instead of the actual paper lolol whyy 🤦♂️
it's like "i found relevant content in <journal|conf|arxiv> paper" but the links provided all go to the publisher homepage instead of the actual paper lolol whyy 🤦♂️

May 23, 2025 at 7:03 AM
hilarious deep research UX w/ the agent trace
it's like "i found relevant content in <journal|conf|arxiv> paper" but the links provided all go to the publisher homepage instead of the actual paper lolol whyy 🤦♂️
it's like "i found relevant content in <journal|conf|arxiv> paper" but the links provided all go to the publisher homepage instead of the actual paper lolol whyy 🤦♂️
nice article thx for sharing! enjoyed fig about surveying bad baselines

May 23, 2025 at 6:12 AM
nice article thx for sharing! enjoyed fig about surveying bad baselines

unfortunately not 😮💨 it's disabled for me too; i am wondering if the call was incorrect - the real for making sure all openreview profiles exist was actually the abstract deadline, not full submission deadline. ill try emailing PCs

May 14, 2025 at 11:36 PM
unfortunately not 😮💨 it's disabled for me too; i am wondering if the call was incorrect - the real for making sure all openreview profiles exist was actually the abstract deadline, not full submission deadline. ill try emailing PCs
@neuripsconf.bsky.social
it seems the call for papers neurips.cc/Conferences/... says author list should be finalized by May 15th, but on OpenReview itself, author list needs to be finalized by May 11th
can pls clarify, thx! 🙏
it seems the call for papers neurips.cc/Conferences/... says author list should be finalized by May 15th, but on OpenReview itself, author list needs to be finalized by May 11th
can pls clarify, thx! 🙏


May 12, 2025 at 5:08 AM
@neuripsconf.bsky.social
it seems the call for papers neurips.cc/Conferences/... says author list should be finalized by May 15th, but on OpenReview itself, author list needs to be finalized by May 11th
can pls clarify, thx! 🙏
it seems the call for papers neurips.cc/Conferences/... says author list should be finalized by May 15th, but on OpenReview itself, author list needs to be finalized by May 11th
can pls clarify, thx! 🙏