




Kyle Lo
@kylelo.bsky.social
language model pretraining @ai2.bsky.social, co-lead of data research w/ @soldaini.net, statistics @uw, open science, tabletop, seattle, he/him,🧋 kyleclo.com
Pinned
Kyle Lo
@kylelo.bsky.social
· Mar 13

we released olmo 32b today! ☺️
🐟our largest & best fully open model to-date
🐠right up there w similar size weights-only models from big companies on popular benchmarks
🐡but we used way less compute & all our data, ckpts, code, recipe are free & open
made a nice plot of our post-trained results!✌️
🐟our largest & best fully open model to-date
🐠right up there w similar size weights-only models from big companies on popular benchmarks
🐡but we used way less compute & all our data, ckpts, code, recipe are free & open
made a nice plot of our post-trained results!✌️
why intern at Ai2?
🐟interns own major parts of our model development, sometimes even leading whole projects
🐡we're committed to open science & actively help our interns publish their work
reach out if u wanna build open language models together 🤝
links 👇
🐟interns own major parts of our model development, sometimes even leading whole projects
🐡we're committed to open science & actively help our interns publish their work
reach out if u wanna build open language models together 🤝
links 👇

November 5, 2025 at 11:11 PM
why intern at Ai2?
🐟interns own major parts of our model development, sometimes even leading whole projects
🐡we're committed to open science & actively help our interns publish their work
reach out if u wanna build open language models together 🤝
links 👇
🐟interns own major parts of our model development, sometimes even leading whole projects
🐡we're committed to open science & actively help our interns publish their work
reach out if u wanna build open language models together 🤝
links 👇
congrats to our olmo earth team 🌎
small multimodal foundation language models + system for finetuning for important uses like agriculture, wildfire management, conservation & more 🌿
small multimodal foundation language models + system for finetuning for important uses like agriculture, wildfire management, conservation & more 🌿
Introducing OlmoEarth 🌍, state-of-the-art AI foundation models paired with ready-to-use open infrastructure to turn Earth data into clear, up-to-date insights within hours—not years.
November 4, 2025 at 5:57 PM
congrats to our olmo earth team 🌎
small multimodal foundation language models + system for finetuning for important uses like agriculture, wildfire management, conservation & more 🌿
small multimodal foundation language models + system for finetuning for important uses like agriculture, wildfire management, conservation & more 🌿
woah guess VLMs for OCR the hottest research topic this week😆 since the first olmOCR, we've been..
🔥training our VLM using RLVR with binary unit test rewards🔥
it's incredibly effective & unit test creation easy to scale w synthetic data pipelines
check it out at olmocr.allen.ai
🔥training our VLM using RLVR with binary unit test rewards🔥
it's incredibly effective & unit test creation easy to scale w synthetic data pipelines
check it out at olmocr.allen.ai

October 22, 2025 at 6:02 PM
woah guess VLMs for OCR the hottest research topic this week😆 since the first olmOCR, we've been..
🔥training our VLM using RLVR with binary unit test rewards🔥
it's incredibly effective & unit test creation easy to scale w synthetic data pipelines
check it out at olmocr.allen.ai
🔥training our VLM using RLVR with binary unit test rewards🔥
it's incredibly effective & unit test creation easy to scale w synthetic data pipelines
check it out at olmocr.allen.ai

come say hi at posters this morning for OLMo 2 and fluid benchmarking posters 👋 and dont miss @valentinhofmann.bsky.social's talk in morning #colm2025 @ai2.bsky.social vry proud of my gifs
October 9, 2025 at 1:14 PM
come say hi at posters this morning for OLMo 2 and fluid benchmarking posters 👋 and dont miss @valentinhofmann.bsky.social's talk in morning #colm2025 @ai2.bsky.social vry proud of my gifs
@josephc.bsky.social @mariaa.bsky.social and I are at poster #21
findings from large scale survey of 800 researchers on how they use LMs in their research #colm2025
findings from large scale survey of 800 researchers on how they use LMs in their research #colm2025

October 8, 2025 at 8:12 PM
@josephc.bsky.social @mariaa.bsky.social and I are at poster #21
findings from large scale survey of 800 researchers on how they use LMs in their research #colm2025
findings from large scale survey of 800 researchers on how they use LMs in their research #colm2025
flyin to #colm2025 along w bunch of the @ai2.bsky.social team
come chat w me about pretraining horror stories, data & evals, what we're cookin for next olmo, etc
made a 🔥 poster for thursday sess, come say hi
come chat w me about pretraining horror stories, data & evals, what we're cookin for next olmo, etc
made a 🔥 poster for thursday sess, come say hi
October 6, 2025 at 3:20 PM
flyin to #colm2025 along w bunch of the @ai2.bsky.social team
come chat w me about pretraining horror stories, data & evals, what we're cookin for next olmo, etc
made a 🔥 poster for thursday sess, come say hi
come chat w me about pretraining horror stories, data & evals, what we're cookin for next olmo, etc
made a 🔥 poster for thursday sess, come say hi

not my project but I rlly like it
working w cancer research center to analyze clinical data, but private data cant leave the center.
so the team developed a tool that generates code for remote execution by the cancer center, developed on synthetic data, and now tested for realsies 🤩
working w cancer research center to analyze clinical data, but private data cant leave the center.
so the team developed a tool that generates code for remote execution by the cancer center, developed on synthetic data, and now tested for realsies 🤩
October 2, 2025 at 5:19 PM
not my project but I rlly like it
working w cancer research center to analyze clinical data, but private data cant leave the center.
so the team developed a tool that generates code for remote execution by the cancer center, developed on synthetic data, and now tested for realsies 🤩
working w cancer research center to analyze clinical data, but private data cant leave the center.
so the team developed a tool that generates code for remote execution by the cancer center, developed on synthetic data, and now tested for realsies 🤩
had to explain to first time submitter why AC recommended accept ended up as reject 😮💨 been publishing long enough that i get why such things happen but can be rough
September 19, 2025 at 12:07 AM
had to explain to first time submitter why AC recommended accept ended up as reject 😮💨 been publishing long enough that i get why such things happen but can be rough
LM benchmark design requires 3 decisions, how to:
🐟 select test cases
🐠 score LM on each test
🦈 aggregate scores to estimate perf
fluid benchmarking is simple:
🍣 find max informative test cases
🍥 estimate 'ability', not simple avg perf
why care? turn ur grey noisy benchmarks to red ones!
🐟 select test cases
🐠 score LM on each test
🦈 aggregate scores to estimate perf
fluid benchmarking is simple:
🍣 find max informative test cases
🍥 estimate 'ability', not simple avg perf
why care? turn ur grey noisy benchmarks to red ones!

September 17, 2025 at 6:17 PM
LM benchmark design requires 3 decisions, how to:
🐟 select test cases
🐠 score LM on each test
🦈 aggregate scores to estimate perf
fluid benchmarking is simple:
🍣 find max informative test cases
🍥 estimate 'ability', not simple avg perf
why care? turn ur grey noisy benchmarks to red ones!
🐟 select test cases
🐠 score LM on each test
🦈 aggregate scores to estimate perf
fluid benchmarking is simple:
🍣 find max informative test cases
🍥 estimate 'ability', not simple avg perf
why care? turn ur grey noisy benchmarks to red ones!
scathing takedown of recent K2 Think model
"evaluates on data it was trained on, relies on an external model and additional samples for its claimed performance gains, and artificially reduces the scores of compared models"
www.sri.inf.ethz.ch/blog/k2think
"evaluates on data it was trained on, relies on an external model and additional samples for its claimed performance gains, and artificially reduces the scores of compared models"
www.sri.inf.ethz.ch/blog/k2think

Debunking the Claims of K2-Think
K2-Think is a recently released LLM that claims performance on par with GPT-OSS 120B and DeepSeek v3.1, despite having fewer parameters. As we discuss below, the reported gains are overstated, relying...
www.sri.inf.ethz.ch
September 12, 2025 at 8:57 PM
scathing takedown of recent K2 Think model
"evaluates on data it was trained on, relies on an external model and additional samples for its claimed performance gains, and artificially reduces the scores of compared models"
www.sri.inf.ethz.ch/blog/k2think
"evaluates on data it was trained on, relies on an external model and additional samples for its claimed performance gains, and artificially reduces the scores of compared models"
www.sri.inf.ethz.ch/blog/k2think
Reposted by Kyle Lo

COLM is coming up! Very excited. I'm starting to figure out two things:
1. A small invite-only dinner for Interconnects AI (Ai2 event news later).
2. Various research chats and catchups.
Fill out the form below or email me if you're interested :) 🍁🇨🇦
Interest form: buff.ly/9nWBxZ9
1. A small invite-only dinner for Interconnects AI (Ai2 event news later).
2. Various research chats and catchups.
Fill out the form below or email me if you're interested :) 🍁🇨🇦
Interest form: buff.ly/9nWBxZ9

September 4, 2025 at 8:13 PM
COLM is coming up! Very excited. I'm starting to figure out two things:
1. A small invite-only dinner for Interconnects AI (Ai2 event news later).
2. Various research chats and catchups.
Fill out the form below or email me if you're interested :) 🍁🇨🇦
Interest form: buff.ly/9nWBxZ9
1. A small invite-only dinner for Interconnects AI (Ai2 event news later).
2. Various research chats and catchups.
Fill out the form below or email me if you're interested :) 🍁🇨🇦
Interest form: buff.ly/9nWBxZ9
Reposted by Kyle Lo

🎙️ Say hello to OLMoASR—our fully open, from-scratch speech-to-text (STT) model. Trained on a curated audio-text set, it boosts zero-shot ASR and now powers STT in the Ai2 Playground. 👇
August 28, 2025 at 4:13 PM
🎙️ Say hello to OLMoASR—our fully open, from-scratch speech-to-text (STT) model. Trained on a curated audio-text set, it boosts zero-shot ASR and now powers STT in the Ai2 Playground. 👇
"Out of 13,048 reviewers..only 69 were deemed highly irresponsible..and enforcement was applied solely in those cases...These reviewers were contacted multiple times...as well as being personally contacted by the area chairs and senior area chairs, but still failed to fulfill them."
🫡🫡🫡
🫡🫡🫡

This year, EMNLP ended up desk rejecting ~100 papers. For more insight into the process, and potential future changes, please see this blog post from the PCs: 2025.emnlp.org/desk-rejecti...
@christos-c.bsky.social @carolynrose.bsky.social @tanmoy-chak.bsky.social @violetpeng.bsky.social
@christos-c.bsky.social @carolynrose.bsky.social @tanmoy-chak.bsky.social @violetpeng.bsky.social
New Desk Rejection Practice for EMNLP 2025
For some time there has been substantial concern within the community regarding many aspects of reviewing, from poor quality, to too few reviewers in the pool, to poor quality reviews, to reviewers no...
2025.emnlp.org
August 20, 2025 at 5:08 PM
"Out of 13,048 reviewers..only 69 were deemed highly irresponsible..and enforcement was applied solely in those cases...These reviewers were contacted multiple times...as well as being personally contacted by the area chairs and senior area chairs, but still failed to fulfill them."
🫡🫡🫡
🫡🫡🫡
my favorite figure from work by @davidheineman.com
if you're frustrated by LM evals, not knowing if results are real or noise, it's useful to decompose sources of variance:
🐠is there enough meaningful spread (signal) among compared models
🐟do scores vary between intermediate checkpoints (noise)
if you're frustrated by LM evals, not knowing if results are real or noise, it's useful to decompose sources of variance:
🐠is there enough meaningful spread (signal) among compared models
🐟do scores vary between intermediate checkpoints (noise)

(2/6) Consider these training curves: 150M, 300M and 1B param models on 25 pretraining corpora. Many benchmarks can separate models, but are too noisy, and vice versa! 😧
We want – ⭐ low noise and high signal ⭐ – *both* low variance during training and a high spread of scores.
We want – ⭐ low noise and high signal ⭐ – *both* low variance during training and a high spread of scores.

August 19, 2025 at 6:09 PM
my favorite figure from work by @davidheineman.com
if you're frustrated by LM evals, not knowing if results are real or noise, it's useful to decompose sources of variance:
🐠is there enough meaningful spread (signal) among compared models
🐟do scores vary between intermediate checkpoints (noise)
if you're frustrated by LM evals, not knowing if results are real or noise, it's useful to decompose sources of variance:
🐠is there enough meaningful spread (signal) among compared models
🐟do scores vary between intermediate checkpoints (noise)
very nice work by @datologyai.com folks on synth data for pretraining
very nice results over nemotron synth, which we've generally been impressed by
rephrasing the web (arxiv.org/abs/2401.16380) seems very powerful & good demonstration of how to push it further
very nice results over nemotron synth, which we've generally been impressed by
rephrasing the web (arxiv.org/abs/2401.16380) seems very powerful & good demonstration of how to push it further
August 18, 2025 at 11:49 PM
very nice work by @datologyai.com folks on synth data for pretraining
very nice results over nemotron synth, which we've generally been impressed by
rephrasing the web (arxiv.org/abs/2401.16380) seems very powerful & good demonstration of how to push it further
very nice results over nemotron synth, which we've generally been impressed by
rephrasing the web (arxiv.org/abs/2401.16380) seems very powerful & good demonstration of how to push it further
Reposted by Kyle Lo
We’re releasing early pre-training checkpoints for OLMo-2-1B to help study how LLM capabilities emerge. They’re fine-grained snapshots intended for analysis, reproduction, and comparison. 🧵

August 18, 2025 at 7:02 PM
We’re releasing early pre-training checkpoints for OLMo-2-1B to help study how LLM capabilities emerge. They’re fine-grained snapshots intended for analysis, reproduction, and comparison. 🧵
huge thx to the NSF & NVIDIA for supporting our work on fully open AI model science & development 🤩
With fresh support of $75M from NSF and $77M from NVIDIA, we’re set to scale our open model ecosystem, bolster the infrastructure behind it, and fast‑track reproducible AI research to unlock the next wave of scientific discovery. 💡

August 14, 2025 at 3:43 PM
huge thx to the NSF & NVIDIA for supporting our work on fully open AI model science & development 🤩
⚠️ AI-generated content may be inaccurate. Verify important information independently.

August 8, 2025 at 8:33 PM
⚠️ AI-generated content may be inaccurate. Verify important information independently.
Reposted by Kyle Lo

GPT-5 lands first place on NoCha, our long-context book understanding benchmark.
That said, this is a tiny improvement (~1%) over o1-preview, which was released almost one year ago. Have long-context models hit a wall?
Accuracy of human readers is >97%... Long way to go!
That said, this is a tiny improvement (~1%) over o1-preview, which was released almost one year ago. Have long-context models hit a wall?
Accuracy of human readers is >97%... Long way to go!
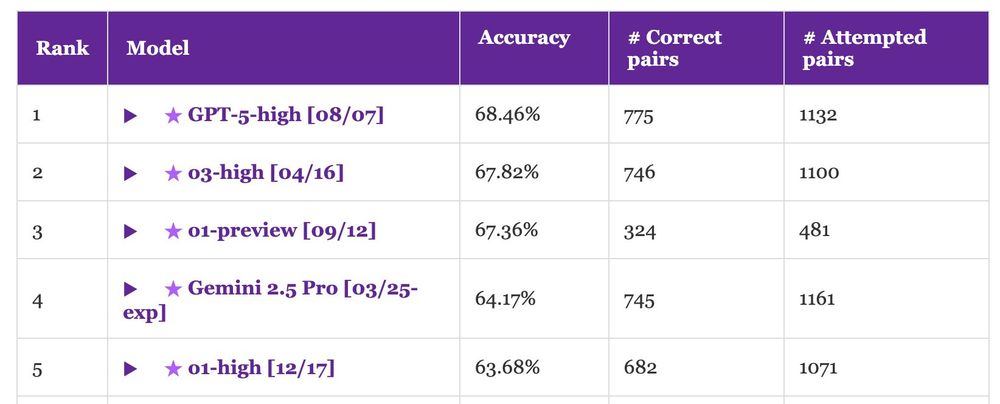
August 8, 2025 at 2:13 AM
GPT-5 lands first place on NoCha, our long-context book understanding benchmark.
That said, this is a tiny improvement (~1%) over o1-preview, which was released almost one year ago. Have long-context models hit a wall?
Accuracy of human readers is >97%... Long way to go!
That said, this is a tiny improvement (~1%) over o1-preview, which was released almost one year ago. Have long-context models hit a wall?
Accuracy of human readers is >97%... Long way to go!
uniting the internet w chart crimes lol

August 8, 2025 at 2:03 AM
uniting the internet w chart crimes lol
thx to all the feedback from OSS community!
our olmOCR lead Jake Poznanski shipped a new model fixing lotta issues + some more optimization for better throughput
have fun converting PDFs!
our olmOCR lead Jake Poznanski shipped a new model fixing lotta issues + some more optimization for better throughput
have fun converting PDFs!
📝 olmOCR v0.2.1 has arrived with new models! Our open‑source OCR engine now reads tougher docs with greater precision—and it’s still 100 % open. 👇

August 1, 2025 at 6:40 PM
thx to all the feedback from OSS community!
our olmOCR lead Jake Poznanski shipped a new model fixing lotta issues + some more optimization for better throughput
have fun converting PDFs!
our olmOCR lead Jake Poznanski shipped a new model fixing lotta issues + some more optimization for better throughput
have fun converting PDFs!
olmoTrace for connecting model generations to training data won Best Paper for System Demonstrations at #ACL2025!

Today we're unveiling OLMoTrace, a tool that enables everyone to understand the outputs of LLMs by connecting to their training data.
We do this on unprecedented scale and in real time: finding matching text between model outputs and 4 trillion training tokens within seconds. ✨
We do this on unprecedented scale and in real time: finding matching text between model outputs and 4 trillion training tokens within seconds. ✨
For years it’s been an open question — how much is a language model learning and synthesizing information, and how much is it just memorizing and reciting?
Introducing OLMoTrace, a new feature in the Ai2 Playground that begins to shed some light. 🔦
Introducing OLMoTrace, a new feature in the Ai2 Playground that begins to shed some light. 🔦
July 31, 2025 at 8:33 PM
olmoTrace for connecting model generations to training data won Best Paper for System Demonstrations at #ACL2025!
Reposted by Kyle Lo

People at #ACL2025, come drop by our poster today & chat with me about how context matters for reliable language model evaluations!
Jul 30, 11:00-12:30 at Hall 4X, board 424.
Jul 30, 11:00-12:30 at Hall 4X, board 424.
Excited to share ✨ Contextualized Evaluations ✨!
Benchmarks like Chatbot Arena contain underspecified queries, which can lead to arbitrary eval judgments. What happens if we provide evaluators with context (e.g who's the user, what's their intent) when judging LM outputs? 🧵↓
Benchmarks like Chatbot Arena contain underspecified queries, which can lead to arbitrary eval judgments. What happens if we provide evaluators with context (e.g who's the user, what's their intent) when judging LM outputs? 🧵↓

July 30, 2025 at 6:05 AM
People at #ACL2025, come drop by our poster today & chat with me about how context matters for reliable language model evaluations!
Jul 30, 11:00-12:30 at Hall 4X, board 424.
Jul 30, 11:00-12:30 at Hall 4X, board 424.