



Kenneth Marino
@kennethmarino.bsky.social
Assistant Prof at University of Utah Fall 2025. NLP+CV+RL. RS at Google DeepMind. PhD from CMU MLD, undergrad Georgia Tech. Sometimes researcher, frequent shitposter.
Super excited that the Computer Use survey I've been working on w/ @anamarasovic.bsky.social for a while now is ready! Originally we were planning on a more traditional survey paper but as more surveys came out we decided on an interactive website survey.

August 29, 2025 at 4:41 PM
Super excited that the Computer Use survey I've been working on w/ @anamarasovic.bsky.social for a while now is ready! Originally we were planning on a more traditional survey paper but as more surveys came out we decided on an interactive website survey.
Reposted by Kenneth Marino

Arriving to #ACL2025 #ACL2025NLP in a few hours!
See you at the welcome reception & catch me at the poster session on 𝐓𝐮𝐞𝐬𝐝𝐚𝐲 (𝐉𝐮𝐥𝐲 𝟐𝟗) 𝐚𝐭 𝟏𝟎:𝟑𝟎𝐚𝐦, where Jesse will present our work introducing new tasks for supporting legal brief writing: arxiv.org/abs/2506.06619
See you at the welcome reception & catch me at the poster session on 𝐓𝐮𝐞𝐬𝐝𝐚𝐲 (𝐉𝐮𝐥𝐲 𝟐𝟗) 𝐚𝐭 𝟏𝟎:𝟑𝟎𝐚𝐦, where Jesse will present our work introducing new tasks for supporting legal brief writing: arxiv.org/abs/2506.06619

July 27, 2025 at 1:35 PM
Arriving to #ACL2025 #ACL2025NLP in a few hours!
See you at the welcome reception & catch me at the poster session on 𝐓𝐮𝐞𝐬𝐝𝐚𝐲 (𝐉𝐮𝐥𝐲 𝟐𝟗) 𝐚𝐭 𝟏𝟎:𝟑𝟎𝐚𝐦, where Jesse will present our work introducing new tasks for supporting legal brief writing: arxiv.org/abs/2506.06619
See you at the welcome reception & catch me at the poster session on 𝐓𝐮𝐞𝐬𝐝𝐚𝐲 (𝐉𝐮𝐥𝐲 𝟐𝟗) 𝐚𝐭 𝟏𝟎:𝟑𝟎𝐚𝐦, where Jesse will present our work introducing new tasks for supporting legal brief writing: arxiv.org/abs/2506.06619
Really excited about this!
As backstory, Jesse Woo started this project when I taught a ML Datasets class at Columbia.
Then we joined up with @anamarasovic.bsky.social and @fatemehc.bsky.social and really kicked it into high gear. Would not have happened without the full team!
As backstory, Jesse Woo started this project when I taught a ML Datasets class at Columbia.
Then we joined up with @anamarasovic.bsky.social and @fatemehc.bsky.social and really kicked it into high gear. Would not have happened without the full team!

1/ 🚨NEW PAPER: "BriefMe: A Legal NLP Benchmark for Assisting with Legal Briefs", accepted to ACL Findings 2025!
We introduce the first benchmark specifically designed to help LLMs assist lawyers in writing legal briefs 🧑⚖️
📄 arxiv.org/abs/2506.06619
🗂️ huggingface.co/datasets/jw4...
We introduce the first benchmark specifically designed to help LLMs assist lawyers in writing legal briefs 🧑⚖️
📄 arxiv.org/abs/2506.06619
🗂️ huggingface.co/datasets/jw4...

July 1, 2025 at 5:29 PM
Really excited about this!
As backstory, Jesse Woo started this project when I taught a ML Datasets class at Columbia.
Then we joined up with @anamarasovic.bsky.social and @fatemehc.bsky.social and really kicked it into high gear. Would not have happened without the full team!
As backstory, Jesse Woo started this project when I taught a ML Datasets class at Columbia.
Then we joined up with @anamarasovic.bsky.social and @fatemehc.bsky.social and really kicked it into high gear. Would not have happened without the full team!
Reposted by Kenneth Marino

Join us on June 11, 9am to discuss all things fine-grained!
We are looking forward to a series of talks on semantic granularity, covering topics such as machine teaching, interpretability and much more!
Room 104 E
Schedule & details: sites.google.com/view/fgvc12
@cvprconference.bsky.social #CVPR25
We are looking forward to a series of talks on semantic granularity, covering topics such as machine teaching, interpretability and much more!
Room 104 E
Schedule & details: sites.google.com/view/fgvc12
@cvprconference.bsky.social #CVPR25

June 8, 2025 at 11:19 PM
Join us on June 11, 9am to discuss all things fine-grained!
We are looking forward to a series of talks on semantic granularity, covering topics such as machine teaching, interpretability and much more!
Room 104 E
Schedule & details: sites.google.com/view/fgvc12
@cvprconference.bsky.social #CVPR25
We are looking forward to a series of talks on semantic granularity, covering topics such as machine teaching, interpretability and much more!
Room 104 E
Schedule & details: sites.google.com/view/fgvc12
@cvprconference.bsky.social #CVPR25
Reposted by Kenneth Marino
We are so excited to have this amazing line-up of speakers!!
Randall Balestriero, Kai Han, Mia Chiquier, Kenneth Marino (@kennethmarino.bsky.social), Elisa Ricci, Thomas Fel (@thomasfel.bsky.social)
Randall Balestriero, Kai Han, Mia Chiquier, Kenneth Marino (@kennethmarino.bsky.social), Elisa Ricci, Thomas Fel (@thomasfel.bsky.social)
June 8, 2025 at 11:30 PM
We are so excited to have this amazing line-up of speakers!!
Randall Balestriero, Kai Han, Mia Chiquier, Kenneth Marino (@kennethmarino.bsky.social), Elisa Ricci, Thomas Fel (@thomasfel.bsky.social)
Randall Balestriero, Kai Han, Mia Chiquier, Kenneth Marino (@kennethmarino.bsky.social), Elisa Ricci, Thomas Fel (@thomasfel.bsky.social)
We just dropped a new paper on studying LLMs on the “Blicket Test” to ask the question: do language models explore like adults or like children? We also show how to get them to act more like children (i.e. more like scientists). All credit to Anthony and team, this came together super well!

Language model (LM) agents are all the rage now—but they may exhibit cognitive biases when inferring causal relationships!
We evaluate LMs on a cognitive task to find:
- LMs struggle with certain simple causal relationships
- They show biases similar to human adults (but not children)
🧵⬇️
We evaluate LMs on a cognitive task to find:
- LMs struggle with certain simple causal relationships
- They show biases similar to human adults (but not children)
🧵⬇️

May 16, 2025 at 5:18 PM
We just dropped a new paper on studying LLMs on the “Blicket Test” to ask the question: do language models explore like adults or like children? We also show how to get them to act more like children (i.e. more like scientists). All credit to Anthony and team, this came together super well!
Are you tired of your static fixed benchmarks? Feel like your data is in a rut. You want to change something but you just feel stuck? Try ReCogLab!
Really proud of this work and of my fantastic colleagues at Google DeepMind who put in so much hard work.
See you all in Singapore!
Really proud of this work and of my fantastic colleagues at Google DeepMind who put in so much hard work.
See you all in Singapore!

Want to procedurally generate large-scale relational reasoning experiments in natural language, to study human psychology 🧠 or eval LLMs 🤖?
We have a tool for you! Our latest #ICLR work on long-context/relational reasoning evaluation for LLMs ReCogLab!
github.com/google-deepm...
Thread ⬇️
We have a tool for you! Our latest #ICLR work on long-context/relational reasoning evaluation for LLMs ReCogLab!
github.com/google-deepm...
Thread ⬇️
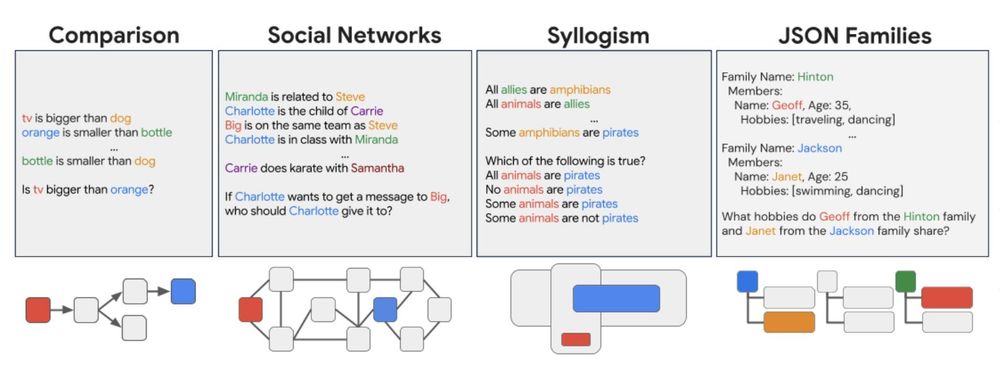
March 18, 2025 at 5:06 PM
Are you tired of your static fixed benchmarks? Feel like your data is in a rut. You want to change something but you just feel stuck? Try ReCogLab!
Really proud of this work and of my fantastic colleagues at Google DeepMind who put in so much hard work.
See you all in Singapore!
Really proud of this work and of my fantastic colleagues at Google DeepMind who put in so much hard work.
See you all in Singapore!
People who actually believe in the promise of AI should be the most upset about the over-claiming, over-hyping and overt secrecy and unwillingness to expose your work to scrutiny that has come to characterize much of the “feel the AGI” crowd.
January 20, 2025 at 8:39 PM
People who actually believe in the promise of AI should be the most upset about the over-claiming, over-hyping and overt secrecy and unwillingness to expose your work to scrutiny that has come to characterize much of the “feel the AGI” crowd.
This is why open source and publishing is important. Maybe OpenAI didn’t do anything sus with held out splits. But if code and models are never released and the experiments and methods are not published or described in sufficient detail, we can’t reproduce it or scrutinize any of these decisions.

This is just a reminder that training on test data is all you need to achieve SOTA perf
OpenAI had access to all of FrontierMath data from the beginning, but they verbally agreed that data would not be used in model training. Although there was a legal agreement not to disclose the partnership
OpenAI had access to all of FrontierMath data from the beginning, but they verbally agreed that data would not be used in model training. Although there was a legal agreement not to disclose the partnership
January 19, 2025 at 5:34 PM
This is why open source and publishing is important. Maybe OpenAI didn’t do anything sus with held out splits. But if code and models are never released and the experiments and methods are not published or described in sufficient detail, we can’t reproduce it or scrutinize any of these decisions.
Just read a fantastic web agent paper. Game changer!
* Treats it as an RL problem
* Trains rather than just prompting
* Beats closed models
* Releases code and model so other people can build off of their work
Many great ideas in this paper too, definitely read
arxiv.org/pdf/2411.02337
* Treats it as an RL problem
* Trains rather than just prompting
* Beats closed models
* Releases code and model so other people can build off of their work
Many great ideas in this paper too, definitely read
arxiv.org/pdf/2411.02337
arxiv.org
January 17, 2025 at 4:23 PM
Just read a fantastic web agent paper. Game changer!
* Treats it as an RL problem
* Trains rather than just prompting
* Beats closed models
* Releases code and model so other people can build off of their work
Many great ideas in this paper too, definitely read
arxiv.org/pdf/2411.02337
* Treats it as an RL problem
* Trains rather than just prompting
* Beats closed models
* Releases code and model so other people can build off of their work
Many great ideas in this paper too, definitely read
arxiv.org/pdf/2411.02337
Fun fact: Faculty do check the papers you put in your CV and notice when you try to make a workshop paper look like a full conference paper with deceptive wording.
January 7, 2025 at 1:36 AM
Fun fact: Faculty do check the papers you put in your CV and notice when you try to make a workshop paper look like a full conference paper with deceptive wording.
Reposted by Kenneth Marino

Felix Hill was such an incredible mentor — and occasional cold water swimming partner — to me. He's a huge part of why I joined DeepMind and how I've come to approach research. Even a month later, it's still hard to believe he's gone.

January 2, 2025 at 7:01 PM
Felix Hill was such an incredible mentor — and occasional cold water swimming partner — to me. He's a huge part of why I joined DeepMind and how I've come to approach research. Even a month later, it's still hard to believe he's gone.
Reposted by Kenneth Marino

Researcher: "We let the data speak for itself."
Earlier that day:
Earlier that day:

January 2, 2025 at 3:31 PM
Researcher: "We let the data speak for itself."
Earlier that day:
Earlier that day:
Reposted by Kenneth Marino

the reviewer’s insightful suggestions have made our paper more accessible

January 3, 2025 at 9:44 PM
the reviewer’s insightful suggestions have made our paper more accessible
Reposted by Kenneth Marino

Computer Vision: Fact & Fiction is now available on YouTube 🙌🏼 I made a playlist for it with the seven chapters. Enjoy this time capsule from two decades ago!
December 19, 2024 at 4:50 PM
Computer Vision: Fact & Fiction is now available on YouTube 🙌🏼 I made a playlist for it with the seven chapters. Enjoy this time capsule from two decades ago!
There’s still time to apply to work with me at Utah. If you’re interested in the intersection of language with perception and action and/or web agents, definitely apply!
www.cs.utah.edu/graduate/pro...
Deadline Dec 15
www.cs.utah.edu/graduate/pro...
Deadline Dec 15
Application – Kahlert School of Computing
www.cs.utah.edu
December 14, 2024 at 1:52 AM
There’s still time to apply to work with me at Utah. If you’re interested in the intersection of language with perception and action and/or web agents, definitely apply!
www.cs.utah.edu/graduate/pro...
Deadline Dec 15
www.cs.utah.edu/graduate/pro...
Deadline Dec 15
We’ll be at our poster soon if you’re interested in multimodal agents and continual learning.
Can’t take a lot of credit, was only an advisor on the project. Gabriel Sarch (PhD candidate at CMU) did a great job on this project; you should come talk to him!
Link to paper: arxiv.org/pdf/2406.14596
Can’t take a lot of credit, was only an advisor on the project. Gabriel Sarch (PhD candidate at CMU) did a great job on this project; you should come talk to him!
Link to paper: arxiv.org/pdf/2406.14596

December 12, 2024 at 5:49 PM
We’ll be at our poster soon if you’re interested in multimodal agents and continual learning.
Can’t take a lot of credit, was only an advisor on the project. Gabriel Sarch (PhD candidate at CMU) did a great job on this project; you should come talk to him!
Link to paper: arxiv.org/pdf/2406.14596
Can’t take a lot of credit, was only an advisor on the project. Gabriel Sarch (PhD candidate at CMU) did a great job on this project; you should come talk to him!
Link to paper: arxiv.org/pdf/2406.14596
I’m at Neurips this week if you want to chat about multimodal agents (including web agents and robotics), datasets, knowledge-VQA, etc.
Also, I’m hiring PhD students this fall at Utah; there’s still time to apply: www.cs.utah.edu/graduate/pro...
Happy to chat if you’re at the conference!
Also, I’m hiring PhD students this fall at Utah; there’s still time to apply: www.cs.utah.edu/graduate/pro...
Happy to chat if you’re at the conference!
Application – Kahlert School of Computing
www.cs.utah.edu
December 9, 2024 at 1:38 AM
I’m at Neurips this week if you want to chat about multimodal agents (including web agents and robotics), datasets, knowledge-VQA, etc.
Also, I’m hiring PhD students this fall at Utah; there’s still time to apply: www.cs.utah.edu/graduate/pro...
Happy to chat if you’re at the conference!
Also, I’m hiring PhD students this fall at Utah; there’s still time to apply: www.cs.utah.edu/graduate/pro...
Happy to chat if you’re at the conference!
Reposted by Kenneth Marino

For those of you attending #NeurIPS2024 in person: I'm from Vancouver and I made an extensive list of restaurants, bars, bookstores, etc., that I used to frequent when I still lived there. Enjoy!
dippedrusk.com/posts/2024-0...
dippedrusk.com/posts/2024-0...

Vagrant's Vancouver | Vagrant Gautam
A non-comprehensive list of places to go and things to do in the Greater Vancouver Area as curated by yours truly over 6 years. Might be outdated so please double-check!
dippedrusk.com
November 29, 2024 at 8:49 PM
For those of you attending #NeurIPS2024 in person: I'm from Vancouver and I made an extensive list of restaurants, bars, bookstores, etc., that I used to frequent when I still lived there. Enjoy!
dippedrusk.com/posts/2024-0...
dippedrusk.com/posts/2024-0...
FYI, there’s a fake Google DeepMind account on here with about 3k followers right now. Please don’t follow or engage with it.
November 26, 2024 at 2:38 AM
FYI, there’s a fake Google DeepMind account on here with about 3k followers right now. Please don’t follow or engage with it.
Reposted by Kenneth Marino

ahhh i feel right at home on bsky now that the seasonal "review system is broken!!11!1!" laments are going full swing. thanks everyone for making the transition go so smoothly <3
November 24, 2024 at 1:02 PM
ahhh i feel right at home on bsky now that the seasonal "review system is broken!!11!1!" laments are going full swing. thanks everyone for making the transition go so smoothly <3
Okay, hot take time:
I don’t like the ICLR continuous back and forth format.
I find it exhausting as both an author and a reviewer.
And the end result is often that reviewers don’t engage very much anyway so we might as well design it as a single response and then discussion.
I don’t like the ICLR continuous back and forth format.
I find it exhausting as both an author and a reviewer.
And the end result is often that reviewers don’t engage very much anyway so we might as well design it as a single response and then discussion.
November 24, 2024 at 2:47 AM
Okay, hot take time:
I don’t like the ICLR continuous back and forth format.
I find it exhausting as both an author and a reviewer.
And the end result is often that reviewers don’t engage very much anyway so we might as well design it as a single response and then discussion.
I don’t like the ICLR continuous back and forth format.
I find it exhausting as both an author and a reviewer.
And the end result is often that reviewers don’t engage very much anyway so we might as well design it as a single response and then discussion.
I think my favorite part of Bluesky is that I can choose followers and feeds to *just* be about research. Twitter floods your feed with politics. Threads fills it with random celebrities. I can open Bluesky and just see research.
November 21, 2024 at 3:32 PM
I think my favorite part of Bluesky is that I can choose followers and feeds to *just* be about research. Twitter floods your feed with politics. Threads fills it with random celebrities. I can open Bluesky and just see research.

Daily paper #4:
Arboretum: A Large Multimodal Dataset Enabling AI for Biodiversity
arxiv.org/pdf/2406.17720
Truly enormous dataset of animals/plants/fungi. Over 130M images, 300k species.
Truly staggering scale and number of classes. A whole new scale of challenge for fine grain recognition.
Arboretum: A Large Multimodal Dataset Enabling AI for Biodiversity
arxiv.org/pdf/2406.17720
Truly enormous dataset of animals/plants/fungi. Over 130M images, 300k species.
Truly staggering scale and number of classes. A whole new scale of challenge for fine grain recognition.
arxiv.org
November 19, 2024 at 2:17 PM
Daily paper #4:
Arboretum: A Large Multimodal Dataset Enabling AI for Biodiversity
arxiv.org/pdf/2406.17720
Truly enormous dataset of animals/plants/fungi. Over 130M images, 300k species.
Truly staggering scale and number of classes. A whole new scale of challenge for fine grain recognition.
Arboretum: A Large Multimodal Dataset Enabling AI for Biodiversity
arxiv.org/pdf/2406.17720
Truly enormous dataset of animals/plants/fungi. Over 130M images, 300k species.
Truly staggering scale and number of classes. A whole new scale of challenge for fine grain recognition.