


@joerocca.bsky.social
Low-alpha lurking/reposting account. Interested in OSS ML, web, XR, EA (esp WAS/WAW), alt proteins, housing, aging, and stuff like that
Pinned

Code/bookmarklet to mute everyone who liked a specific post:
gist.github.com/josephrocca/...
You can paste the code here to turn it into a bookmarklet:
chriszarate.github.io/bookmarkleter/
(With great power comes great responsibility. Personally using it for extremely bad faith tribal brainrot.)
gist.github.com/josephrocca/...
You can paste the code here to turn it into a bookmarklet:
chriszarate.github.io/bookmarkleter/
(With great power comes great responsibility. Personally using it for extremely bad faith tribal brainrot.)
Reposted

I finally joined 🦋! Some of you may recognize me from other sites. Here's a quick intro for new connections:
👋 I work on RL, world models, and generalization in decision-making. I'm perhaps most well known for my work on "TD-MPC2: Scalable, Robust World Models for Continuous Control" www.tdmpc2.com
👋 I work on RL, world models, and generalization in decision-making. I'm perhaps most well known for my work on "TD-MPC2: Scalable, Robust World Models for Continuous Control" www.tdmpc2.com

February 21, 2025 at 9:11 PM
I finally joined 🦋! Some of you may recognize me from other sites. Here's a quick intro for new connections:
👋 I work on RL, world models, and generalization in decision-making. I'm perhaps most well known for my work on "TD-MPC2: Scalable, Robust World Models for Continuous Control" www.tdmpc2.com
👋 I work on RL, world models, and generalization in decision-making. I'm perhaps most well known for my work on "TD-MPC2: Scalable, Robust World Models for Continuous Control" www.tdmpc2.com
Reposted

Small models? Saturating? Where I live we don't know theses words.

April 22, 2025 at 6:09 PM
Small models? Saturating? Where I live we don't know theses words.
Reposted

New Open-source reasoning model (code, dataset, and model)!
Huginn-0125: Pretraining a Depth-Recurrent Model
Train a recurrent-depth model at scale on 4096 AMD GPUs on Frontier.
Huginn-0125: Pretraining a Depth-Recurrent Model
Train a recurrent-depth model at scale on 4096 AMD GPUs on Frontier.

February 10, 2025 at 6:35 PM
New Open-source reasoning model (code, dataset, and model)!
Huginn-0125: Pretraining a Depth-Recurrent Model
Train a recurrent-depth model at scale on 4096 AMD GPUs on Frontier.
Huginn-0125: Pretraining a Depth-Recurrent Model
Train a recurrent-depth model at scale on 4096 AMD GPUs on Frontier.
Reposted
Zyphra beta releases Zonos, a highly expressive TTS model with high fidelity voice cloning.
They release both transformer and SSM-hybrid models under an Apache 2.0 license.
They release both transformer and SSM-hybrid models under an Apache 2.0 license.

February 10, 2025 at 6:44 PM
Zyphra beta releases Zonos, a highly expressive TTS model with high fidelity voice cloning.
They release both transformer and SSM-hybrid models under an Apache 2.0 license.
They release both transformer and SSM-hybrid models under an Apache 2.0 license.
Reposted
Physical Intelligence (π) Open Sourcing π0
They are releasing the code and weights for the π0 as part of our experimental openpi repository.
Blog: www.pi.website/blog/openpi
Repo: github.com/Physical-Int...
They are releasing the code and weights for the π0 as part of our experimental openpi repository.
Blog: www.pi.website/blog/openpi
Repo: github.com/Physical-Int...
February 5, 2025 at 7:22 AM
Physical Intelligence (π) Open Sourcing π0
They are releasing the code and weights for the π0 as part of our experimental openpi repository.
Blog: www.pi.website/blog/openpi
Repo: github.com/Physical-Int...
They are releasing the code and weights for the π0 as part of our experimental openpi repository.
Blog: www.pi.website/blog/openpi
Repo: github.com/Physical-Int...
Reposted

⭐ The first foundational model available on @LeRobotHF ⭐
Pi0 is the most advanced Vision Language Action model. It takes natural language commands as input and directly output autonomous behavior.
It was trained by @physical_int and ported to pytorch by @m_olbap
👇🧵
Pi0 is the most advanced Vision Language Action model. It takes natural language commands as input and directly output autonomous behavior.
It was trained by @physical_int and ported to pytorch by @m_olbap
👇🧵
February 4, 2025 at 5:07 PM
⭐ The first foundational model available on @LeRobotHF ⭐
Pi0 is the most advanced Vision Language Action model. It takes natural language commands as input and directly output autonomous behavior.
It was trained by @physical_int and ported to pytorch by @m_olbap
👇🧵
Pi0 is the most advanced Vision Language Action model. It takes natural language commands as input and directly output autonomous behavior.
It was trained by @physical_int and ported to pytorch by @m_olbap
👇🧵
Reposted
When it rains, it pours.
Baichuan releases Baichuan-Omni-1.5
Open-source Omni-modal Foundation Model Supporting Text, Image, Video, and Audio Inputs as Well as Text and Audio Outputs.
Both model ( huggingface.co/baichuan-inc... ) and base ( huggingface.co/baichuan-inc... ).
Baichuan releases Baichuan-Omni-1.5
Open-source Omni-modal Foundation Model Supporting Text, Image, Video, and Audio Inputs as Well as Text and Audio Outputs.
Both model ( huggingface.co/baichuan-inc... ) and base ( huggingface.co/baichuan-inc... ).

January 26, 2025 at 9:14 PM
When it rains, it pours.
Baichuan releases Baichuan-Omni-1.5
Open-source Omni-modal Foundation Model Supporting Text, Image, Video, and Audio Inputs as Well as Text and Audio Outputs.
Both model ( huggingface.co/baichuan-inc... ) and base ( huggingface.co/baichuan-inc... ).
Baichuan releases Baichuan-Omni-1.5
Open-source Omni-modal Foundation Model Supporting Text, Image, Video, and Audio Inputs as Well as Text and Audio Outputs.
Both model ( huggingface.co/baichuan-inc... ) and base ( huggingface.co/baichuan-inc... ).
Reposted

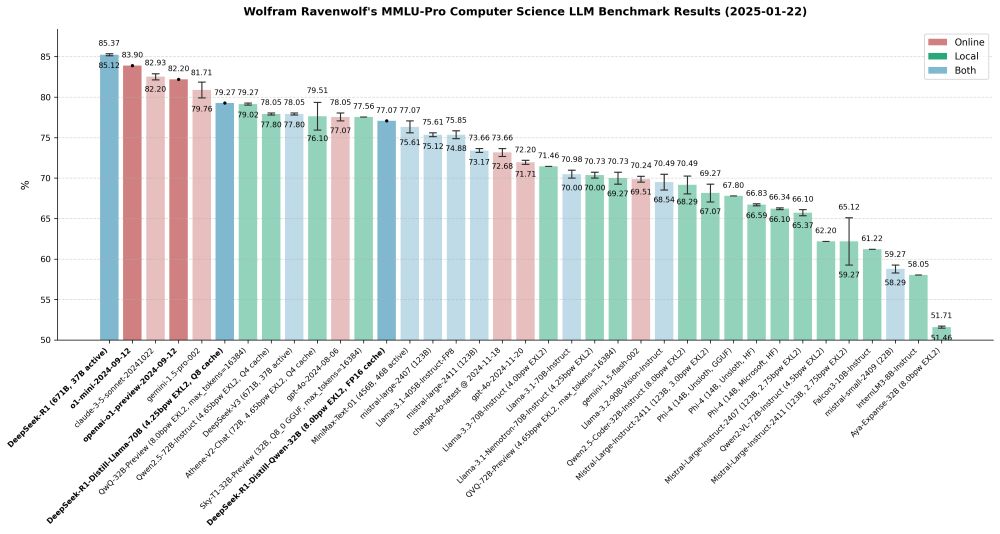
Latest #AI benchmark results: DeepSeek-R1 (including its distilled variants) outperforms OpenAI's o1-mini and preview models. And the Llama 3 distilled version now holds the title of the highest-performing LLM I've tested locally to date. 🚀
January 24, 2025 at 12:22 PM
Latest #AI benchmark results: DeepSeek-R1 (including its distilled variants) outperforms OpenAI's o1-mini and preview models. And the Llama 3 distilled version now holds the title of the highest-performing LLM I've tested locally to date. 🚀
Reposted

TypeScript excitement 😉
Thanks to @searyanc.dev for landing the new --erasableSyntaxOnly tsconfig flag. Heading for TS 5.8 Beta next week 🎉
🔷 Guides users away from TS-only runtime features such as enum & namespace
🔷 Pairs nicely with Node's recent TypeScript support
github.com/microsoft/Ty...
Thanks to @searyanc.dev for landing the new --erasableSyntaxOnly tsconfig flag. Heading for TS 5.8 Beta next week 🎉
🔷 Guides users away from TS-only runtime features such as enum & namespace
🔷 Pairs nicely with Node's recent TypeScript support
github.com/microsoft/Ty...

Tsconfig option to disallow features requiring transformations which are not supported by Node.js' --strip-types · Issue #59601 · microsoft/TypeScript
🔍 Search Terms --strip-types ✅ Viability Checklist This wouldn't be a breaking change in existing TypeScript/JavaScript code This wouldn't change the runtime behavior of existing JavaScript code Th...
github.com
January 24, 2025 at 10:35 AM
TypeScript excitement 😉
Thanks to @searyanc.dev for landing the new --erasableSyntaxOnly tsconfig flag. Heading for TS 5.8 Beta next week 🎉
🔷 Guides users away from TS-only runtime features such as enum & namespace
🔷 Pairs nicely with Node's recent TypeScript support
github.com/microsoft/Ty...
Thanks to @searyanc.dev for landing the new --erasableSyntaxOnly tsconfig flag. Heading for TS 5.8 Beta next week 🎉
🔷 Guides users away from TS-only runtime features such as enum & namespace
🔷 Pairs nicely with Node's recent TypeScript support
github.com/microsoft/Ty...
Reposted
Hugging Face's GRPO to TRL - the training algorithm behind DeepSeek R1
🔋Eliminates the value function from PPO to save boatloads of compute
💰 Samples N completions per prompt to compute average rewards across a group
To use it, run:
pip install git+https://github.com/huggingface/trl.git
🔋Eliminates the value function from PPO to save boatloads of compute
💰 Samples N completions per prompt to compute average rewards across a group
To use it, run:
pip install git+https://github.com/huggingface/trl.git

January 23, 2025 at 3:21 AM
Hugging Face's GRPO to TRL - the training algorithm behind DeepSeek R1
🔋Eliminates the value function from PPO to save boatloads of compute
💰 Samples N completions per prompt to compute average rewards across a group
To use it, run:
pip install git+https://github.com/huggingface/trl.git
🔋Eliminates the value function from PPO to save boatloads of compute
💰 Samples N completions per prompt to compute average rewards across a group
To use it, run:
pip install git+https://github.com/huggingface/trl.git
Reposted
Prime Intellect releases:
- INTELLECT-MATH, a frontier 7B parameter model for math reasoning that shows that the quality of your SFT initialization strongly impacts reinforcement learning.
Blog: www.primeintellect.ai/blog/intelle... Models: huggingface.co/PrimeIntelle...
- INTELLECT-MATH, a frontier 7B parameter model for math reasoning that shows that the quality of your SFT initialization strongly impacts reinforcement learning.
Blog: www.primeintellect.ai/blog/intelle... Models: huggingface.co/PrimeIntelle...

January 22, 2025 at 3:20 AM
Prime Intellect releases:
- INTELLECT-MATH, a frontier 7B parameter model for math reasoning that shows that the quality of your SFT initialization strongly impacts reinforcement learning.
Blog: www.primeintellect.ai/blog/intelle... Models: huggingface.co/PrimeIntelle...
- INTELLECT-MATH, a frontier 7B parameter model for math reasoning that shows that the quality of your SFT initialization strongly impacts reinforcement learning.
Blog: www.primeintellect.ai/blog/intelle... Models: huggingface.co/PrimeIntelle...
Reposted

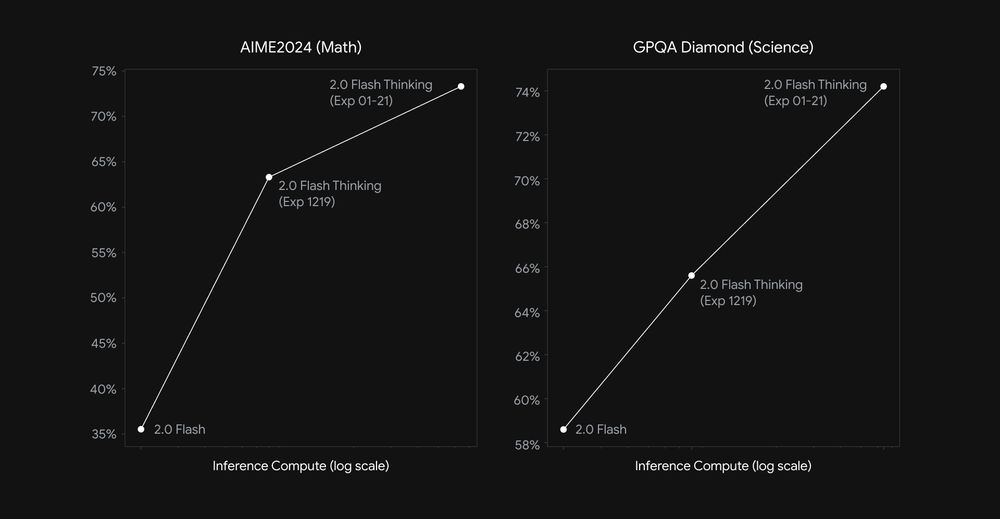
We’ve been thrilled by the positive reception to Gemini 2.0 Flash Thinking we discussed in December.
Today we’re sharing an experimental update w/improved performance on math, science, and multimodal reasoning benchmarks 📈:
• AIME: 73.3%
• GPQA: 74.2%
• MMMU: 75.4%
Today we’re sharing an experimental update w/improved performance on math, science, and multimodal reasoning benchmarks 📈:
• AIME: 73.3%
• GPQA: 74.2%
• MMMU: 75.4%
January 22, 2025 at 12:31 AM
We’ve been thrilled by the positive reception to Gemini 2.0 Flash Thinking we discussed in December.
Today we’re sharing an experimental update w/improved performance on math, science, and multimodal reasoning benchmarks 📈:
• AIME: 73.3%
• GPQA: 74.2%
• MMMU: 75.4%
Today we’re sharing an experimental update w/improved performance on math, science, and multimodal reasoning benchmarks 📈:
• AIME: 73.3%
• GPQA: 74.2%
• MMMU: 75.4%
Reposted
SambaNova's EvaByte
The open-weight tokenizer-free language model. Their 6.5B byte-level LM—-EvaByte matches modern tokenizer-based LMs with 5x less data & 2x faster decoding!
The open-weight tokenizer-free language model. Their 6.5B byte-level LM—-EvaByte matches modern tokenizer-based LMs with 5x less data & 2x faster decoding!

January 22, 2025 at 2:45 AM
SambaNova's EvaByte
The open-weight tokenizer-free language model. Their 6.5B byte-level LM—-EvaByte matches modern tokenizer-based LMs with 5x less data & 2x faster decoding!
The open-weight tokenizer-free language model. Their 6.5B byte-level LM—-EvaByte matches modern tokenizer-based LMs with 5x less data & 2x faster decoding!
Reposted
ByteDance's UI-TARS, which can operate on your local personal device.
Project: github.com/bytedance/UI...
Desktop: github.com/bytedance/UI...
Browser: github.com/web-infra-de...
Models : huggingface.co/bytedance-re...
Paper: arxiv.org/abs/2501.12326
Project: github.com/bytedance/UI...
Desktop: github.com/bytedance/UI...
Browser: github.com/web-infra-de...
Models : huggingface.co/bytedance-re...
Paper: arxiv.org/abs/2501.12326

January 22, 2025 at 6:55 AM
ByteDance's UI-TARS, which can operate on your local personal device.
Project: github.com/bytedance/UI...
Desktop: github.com/bytedance/UI...
Browser: github.com/web-infra-de...
Models : huggingface.co/bytedance-re...
Paper: arxiv.org/abs/2501.12326
Project: github.com/bytedance/UI...
Desktop: github.com/bytedance/UI...
Browser: github.com/web-infra-de...
Models : huggingface.co/bytedance-re...
Paper: arxiv.org/abs/2501.12326
Reposted

Introducing Kokoro.js, a new JavaScript library for running Kokoro TTS, an 82 million parameter text-to-speech model, 100% locally in the browser w/ WASM. Powered by 🤗 Transformers.js. WebGPU support coming soon!
👉 npm i kokoro-js 👈
Link to demo (+ sample code) in 🧵
👉 npm i kokoro-js 👈
Link to demo (+ sample code) in 🧵
January 16, 2025 at 3:05 PM
Introducing Kokoro.js, a new JavaScript library for running Kokoro TTS, an 82 million parameter text-to-speech model, 100% locally in the browser w/ WASM. Powered by 🤗 Transformers.js. WebGPU support coming soon!
👉 npm i kokoro-js 👈
Link to demo (+ sample code) in 🧵
👉 npm i kokoro-js 👈
Link to demo (+ sample code) in 🧵
Reposted
DeepSeek-R1 is coming soon.
DeepSeek-R1 (Preview) Results. The model performs in the vicinity of o1-Medium providing SOTA reasoning performance on LiveCodeBench.
DeepSeek-R1 (Preview) Results. The model performs in the vicinity of o1-Medium providing SOTA reasoning performance on LiveCodeBench.

January 17, 2025 at 7:31 PM
DeepSeek-R1 is coming soon.
DeepSeek-R1 (Preview) Results. The model performs in the vicinity of o1-Medium providing SOTA reasoning performance on LiveCodeBench.
DeepSeek-R1 (Preview) Results. The model performs in the vicinity of o1-Medium providing SOTA reasoning performance on LiveCodeBench.
Reposted

New sharing step on our journey towards easy-to-use fully-open models.

Meet Helium-1 preview, our 2B multi-lingual LLM, targeting edge and mobile devices, released under a CC-BY license. Start building with it today!
huggingface.co/kyutai/heliu...
huggingface.co/kyutai/heliu...

kyutai/helium-1-preview-2b · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
January 16, 2025 at 10:44 AM
New sharing step on our journey towards easy-to-use fully-open models.
Reposted

📢 Paper + code release 📃💻
After 2 years of work, I'm excited to announce our newest paper, MatterGen, has been published in Nature!
www.nature.com/articles/s41...
We are also releasing all the training data, model weights, model code, and evaluation code on GitHub!
github.com/microsoft/ma...
After 2 years of work, I'm excited to announce our newest paper, MatterGen, has been published in Nature!
www.nature.com/articles/s41...
We are also releasing all the training data, model weights, model code, and evaluation code on GitHub!
github.com/microsoft/ma...
January 16, 2025 at 10:15 AM
📢 Paper + code release 📃💻
After 2 years of work, I'm excited to announce our newest paper, MatterGen, has been published in Nature!
www.nature.com/articles/s41...
We are also releasing all the training data, model weights, model code, and evaluation code on GitHub!
github.com/microsoft/ma...
After 2 years of work, I'm excited to announce our newest paper, MatterGen, has been published in Nature!
www.nature.com/articles/s41...
We are also releasing all the training data, model weights, model code, and evaluation code on GitHub!
github.com/microsoft/ma...
Reposted
TinyBVH has been updated to 1.2.5 on main. New:
TLAS/BLAS construction and traversal, for single and double precision BVHs, and including a brand new GPU demo: See the attached real-time footage, captured at 1280x720 on an NVIDIA 2070 laptop GPU.
#RTXoff
github.com/jbikker/tiny...
TLAS/BLAS construction and traversal, for single and double precision BVHs, and including a brand new GPU demo: See the attached real-time footage, captured at 1280x720 on an NVIDIA 2070 laptop GPU.
#RTXoff
github.com/jbikker/tiny...
January 16, 2025 at 1:27 PM
TinyBVH has been updated to 1.2.5 on main. New:
TLAS/BLAS construction and traversal, for single and double precision BVHs, and including a brand new GPU demo: See the attached real-time footage, captured at 1280x720 on an NVIDIA 2070 laptop GPU.
#RTXoff
github.com/jbikker/tiny...
TLAS/BLAS construction and traversal, for single and double precision BVHs, and including a brand new GPU demo: See the attached real-time footage, captured at 1280x720 on an NVIDIA 2070 laptop GPU.
#RTXoff
github.com/jbikker/tiny...
Reposted
InternLM v3
- Performance surpasses models like Llama3.1-8B and Qwen2.5-7B
- Capable of deep reasoning with system prompts
- Trained only on 4T high-quality tokens
huggingface.co/collections/...
- Performance surpasses models like Llama3.1-8B and Qwen2.5-7B
- Capable of deep reasoning with system prompts
- Trained only on 4T high-quality tokens
huggingface.co/collections/...

January 15, 2025 at 8:24 AM
InternLM v3
- Performance surpasses models like Llama3.1-8B and Qwen2.5-7B
- Capable of deep reasoning with system prompts
- Trained only on 4T high-quality tokens
huggingface.co/collections/...
- Performance surpasses models like Llama3.1-8B and Qwen2.5-7B
- Capable of deep reasoning with system prompts
- Trained only on 4T high-quality tokens
huggingface.co/collections/...
Reposted
Google's Titans: a new architecture with attention and a meta in-context memory that learns how to memorize at test time as presented by one of the author - @alibehrouz.bsky.social

January 13, 2025 at 7:53 PM
Google's Titans: a new architecture with attention and a meta in-context memory that learns how to memorize at test time as presented by one of the author - @alibehrouz.bsky.social
Reposted

ViTPose -- best open-source pose estimation model just landed to @hf.co transformers 🕺🏻💃🏻
🔖 Model collection: huggingface.co/collections/...
🔖 Notebook on how to use: colab.research.google.com/drive/1e8fcb...
🔖 Try it here: huggingface.co/spaces/hysts...
🔖 Model collection: huggingface.co/collections/...
🔖 Notebook on how to use: colab.research.google.com/drive/1e8fcb...
🔖 Try it here: huggingface.co/spaces/hysts...
January 9, 2025 at 2:27 PM
ViTPose -- best open-source pose estimation model just landed to @hf.co transformers 🕺🏻💃🏻
🔖 Model collection: huggingface.co/collections/...
🔖 Notebook on how to use: colab.research.google.com/drive/1e8fcb...
🔖 Try it here: huggingface.co/spaces/hysts...
🔖 Model collection: huggingface.co/collections/...
🔖 Notebook on how to use: colab.research.google.com/drive/1e8fcb...
🔖 Try it here: huggingface.co/spaces/hysts...
Reposted

Deno is committed to web standards - that's why we co-founded WinterCG two years ago. Today marks the next step in that journey: WinterCG moves to Ecma International as technical comittee 55 (TC55).
Goodbye WinterCG, welcome WinterTC!
deno.com/blog/wintertc
Goodbye WinterCG, welcome WinterTC!
deno.com/blog/wintertc

Goodbye WinterCG, welcome WinterTC
WinterCG, the Web Interoperable Runtimes Community Group is moving to ECMA as TC55 to be able to publish standards.
deno.com
January 10, 2025 at 2:06 PM
Deno is committed to web standards - that's why we co-founded WinterCG two years ago. Today marks the next step in that journey: WinterCG moves to Ecma International as technical comittee 55 (TC55).
Goodbye WinterCG, welcome WinterTC!
deno.com/blog/wintertc
Goodbye WinterCG, welcome WinterTC!
deno.com/blog/wintertc