



Jeffrey Bowers
@jeffreybowers.bsky.social
You argued against grandmother cells based on: (a) many neurons always respond to a single input; (b) neurons always respond several inputs. My point is that these findings are consistent with grandmother cells - see article below where we quantify this. Findings also consistent with a threshold.

September 17, 2025 at 3:40 PM
You argued against grandmother cells based on: (a) many neurons always respond to a single input; (b) neurons always respond several inputs. My point is that these findings are consistent with grandmother cells - see article below where we quantify this. Findings also consistent with a threshold.
Another question: how do you reconcile the following claim with the finding that humans identify objects on the basis of line drawings just fine? Indeed, humans identify line drawings the first time they see one, and the cavemen drew line drawings of objects without any training on line drawings.

September 9, 2025 at 8:28 PM
Another question: how do you reconcile the following claim with the finding that humans identify objects on the basis of line drawings just fine? Indeed, humans identify line drawings the first time they see one, and the cavemen drew line drawings of objects without any training on line drawings.
Typically, localist (grandmother) cell coding refers to classifying images into discrete categories (e.g., grandma, grandpa). The relation between coding discrete vs continuous variables is interesting. Here is a passage where I discuss this, from bpb-eu-w2.wpmucdn.com/blogs.bristo...

September 6, 2025 at 8:02 PM
Typically, localist (grandmother) cell coding refers to classifying images into discrete categories (e.g., grandma, grandpa). The relation between coding discrete vs continuous variables is interesting. Here is a passage where I discuss this, from bpb-eu-w2.wpmucdn.com/blogs.bristo...
I debated the author of this paper in an exchange in Psychological Review, and argued their calculations are flawed, see below. My point is not that the evidence is clear, rather, that the dismissal of grandmother cells is unwarranted. And grandmother cells have computational advantages.

September 4, 2025 at 11:22 PM
I debated the author of this paper in an exchange in Psychological Review, and argued their calculations are flawed, see below. My point is not that the evidence is clear, rather, that the dismissal of grandmother cells is unwarranted. And grandmother cells have computational advantages.
Here is a recent PsyArxiv paper where we show that Centaur does not handily outperform domain specific cognitive models because Centaur is not tested in the right way. Its predictions are driven by processes unrelated to human performance. doi.org/10.31234/osf...

July 9, 2025 at 12:50 PM
Here is a recent PsyArxiv paper where we show that Centaur does not handily outperform domain specific cognitive models because Centaur is not tested in the right way. Its predictions are driven by processes unrelated to human performance. doi.org/10.31234/osf...


In a similar way, in the domain of vision, we showed that ANN models of biological vision break down when they are tested on a wide range of psychological experiments. doi.org/10.1017/S014...

June 26, 2025 at 8:29 PM
In a similar way, in the domain of vision, we showed that ANN models of biological vision break down when they are tested on a wide range of psychological experiments. doi.org/10.1017/S014...
Second, Binz et al. report that Centaur did better in predicting performance accuracy on a serial reaction task. However, it does terribly in predicting RTs, and can respond accurately in 1 ms, unlike humans, when asked.

June 26, 2025 at 8:29 PM
Second, Binz et al. report that Centaur did better in predicting performance accuracy on a serial reaction task. However, it does terribly in predicting RTs, and can respond accurately in 1 ms, unlike humans, when asked.
First, Binz et al. report that Centaur did better in predicting performance on a digit span task that measures STM. However, when we manipulated the length of lists, Centaur did not show a human-like STM capacity limit, sometimes repeating 256 digits perfectly.

June 26, 2025 at 8:29 PM
First, Binz et al. report that Centaur did better in predicting performance on a digit span task that measures STM. However, when we manipulated the length of lists, Centaur did not show a human-like STM capacity limit, sometimes repeating 256 digits perfectly.
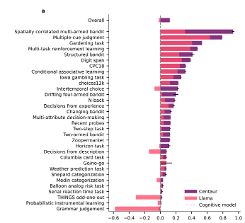
Binz et al. (in press, Nature) developed an LLM called Centaur that better predicts human responses in 159 of 160 behavioural experiments compared to existing cognitive models. See: arxiv.org/abs/2410.20268
June 26, 2025 at 8:29 PM
Binz et al. (in press, Nature) developed an LLM called Centaur that better predicts human responses in 159 of 160 behavioural experiments compared to existing cognitive models. See: arxiv.org/abs/2410.20268
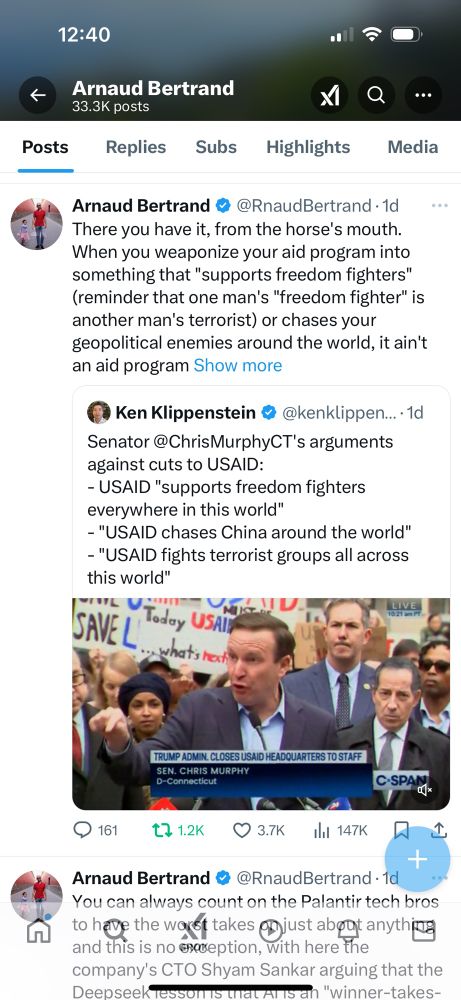
But more of a taster. Irony is most republicans happy about defunding as they actually think USAID is about aid.
February 5, 2025 at 12:42 PM
But more of a taster. Irony is most republicans happy about defunding as they actually think USAID is about aid.
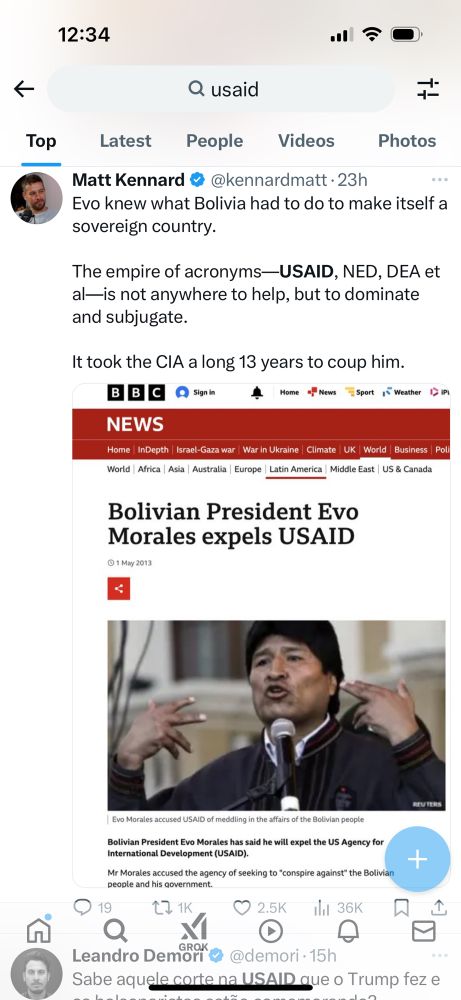
Trump is a disaster. But so was Biden. Genocide is as bad as it gets. And democrats lost supporting it. Regarding USAID, it was largely a tool of imperial power. Not hard to find out how it worked - but not as the letters suggest.
February 5, 2025 at 12:38 PM
Trump is a disaster. But so was Biden. Genocide is as bad as it gets. And democrats lost supporting it. Regarding USAID, it was largely a tool of imperial power. Not hard to find out how it worked - but not as the letters suggest.
I literally said shame all around.
February 5, 2025 at 12:10 PM
I literally said shame all around.