



Jason Corso
@jasoncorso.bsky.social
Professor at Michigan | Voxel51 Co-Founder and Chief Scientist | Creator, Builder, Writer, Coder, Human
Quit by Annie Duke ...a real life decision making read.

August 8, 2025 at 12:19 PM
Quit by Annie Duke ...a real life decision making read.
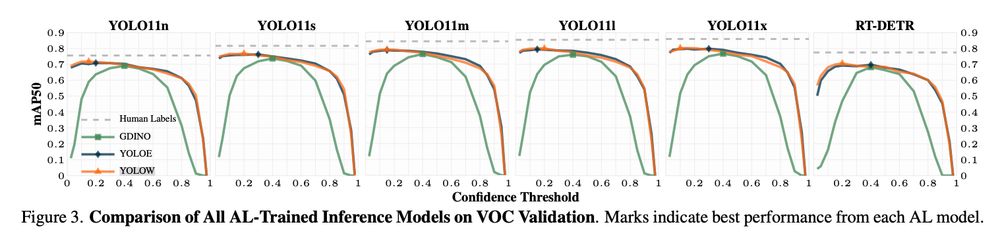
High-confidence labels (0.8–0.9), while appearing cleaner, consistently harmed downstream performance due to reduced recall.
Understanding this balance enables better tuning of auto-labeling pipelines, prioritizing overall model effectiveness over superficial label cleanliness.
Understanding this balance enables better tuning of auto-labeling pipelines, prioritizing overall model effectiveness over superficial label cleanliness.
June 4, 2025 at 4:27 PM
High-confidence labels (0.8–0.9), while appearing cleaner, consistently harmed downstream performance due to reduced recall.
Understanding this balance enables better tuning of auto-labeling pipelines, prioritizing overall model effectiveness over superficial label cleanliness.
Understanding this balance enables better tuning of auto-labeling pipelines, prioritizing overall model effectiveness over superficial label cleanliness.
📊For less-represented classes, models trained from auto labels sometimes performed even better.
The image below compares a human-labeled image (left) with an auto-labeled one (right). Humans are clearly, umm, lazy here :)
The image below compares a human-labeled image (left) with an auto-labeled one (right). Humans are clearly, umm, lazy here :)

June 4, 2025 at 4:27 PM
📊For less-represented classes, models trained from auto labels sometimes performed even better.
The image below compares a human-labeled image (left) with an auto-labeled one (right). Humans are clearly, umm, lazy here :)
The image below compares a human-labeled image (left) with an auto-labeled one (right). Humans are clearly, umm, lazy here :)
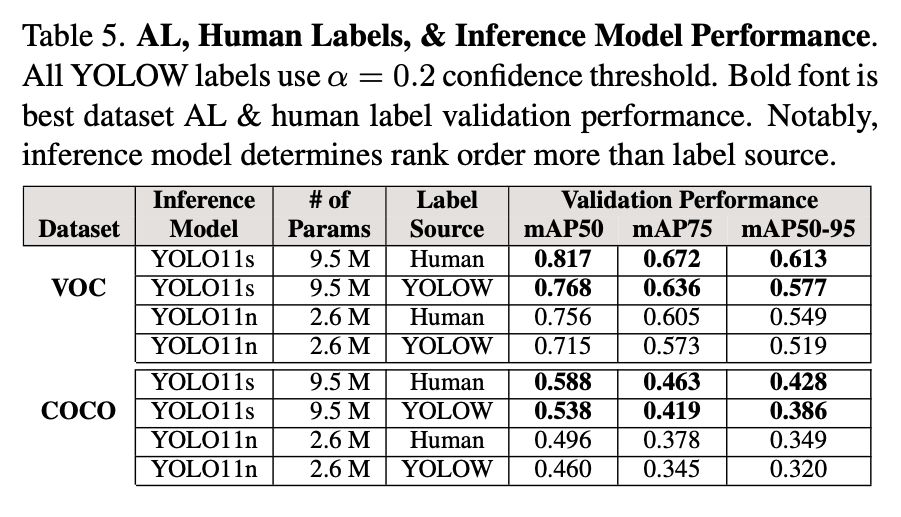
📊 Comparable accuracy to human labels.
The mean average precision (mAP) of inference models trained from auto labels approached those trained from human labels.
On VOC, auto-labeled models achieved mAP50 scores of 0.768, closely matching the 0.817 achieved with human-labeled data.
The mean average precision (mAP) of inference models trained from auto labels approached those trained from human labels.
On VOC, auto-labeled models achieved mAP50 scores of 0.768, closely matching the 0.817 achieved with human-labeled data.
June 4, 2025 at 4:27 PM
📊 Comparable accuracy to human labels.
The mean average precision (mAP) of inference models trained from auto labels approached those trained from human labels.
On VOC, auto-labeled models achieved mAP50 scores of 0.768, closely matching the 0.817 achieved with human-labeled data.
The mean average precision (mAP) of inference models trained from auto labels approached those trained from human labels.
On VOC, auto-labeled models achieved mAP50 scores of 0.768, closely matching the 0.817 achieved with human-labeled data.
The findings:
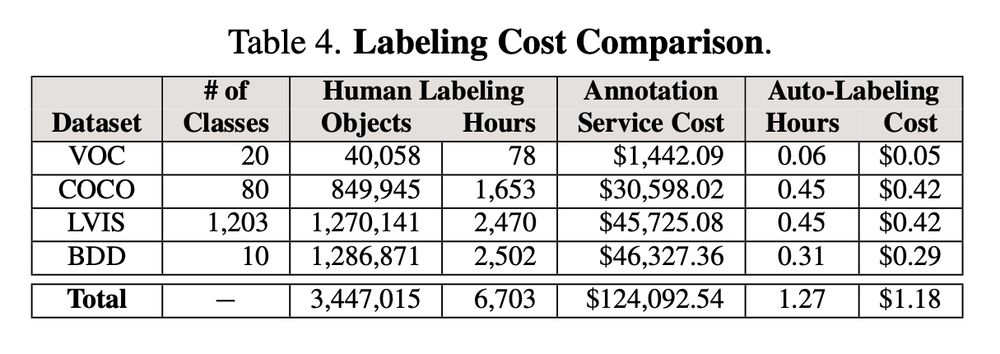
📊 Massive cost and time savings.
Using Verified Auto Labeling costs $1.18 and 1 hour in @NVIDIA L40S GPU time, vs. over $124,092 and 6,703 hours for human annotation.
Read our blog to dive deeper: link.voxel51.com/verified-auto-labeling-tw/
📊 Massive cost and time savings.
Using Verified Auto Labeling costs $1.18 and 1 hour in @NVIDIA L40S GPU time, vs. over $124,092 and 6,703 hours for human annotation.
Read our blog to dive deeper: link.voxel51.com/verified-auto-labeling-tw/
June 4, 2025 at 4:27 PM
The findings:
📊 Massive cost and time savings.
Using Verified Auto Labeling costs $1.18 and 1 hour in @NVIDIA L40S GPU time, vs. over $124,092 and 6,703 hours for human annotation.
Read our blog to dive deeper: link.voxel51.com/verified-auto-labeling-tw/
📊 Massive cost and time savings.
Using Verified Auto Labeling costs $1.18 and 1 hour in @NVIDIA L40S GPU time, vs. over $124,092 and 6,703 hours for human annotation.
Read our blog to dive deeper: link.voxel51.com/verified-auto-labeling-tw/
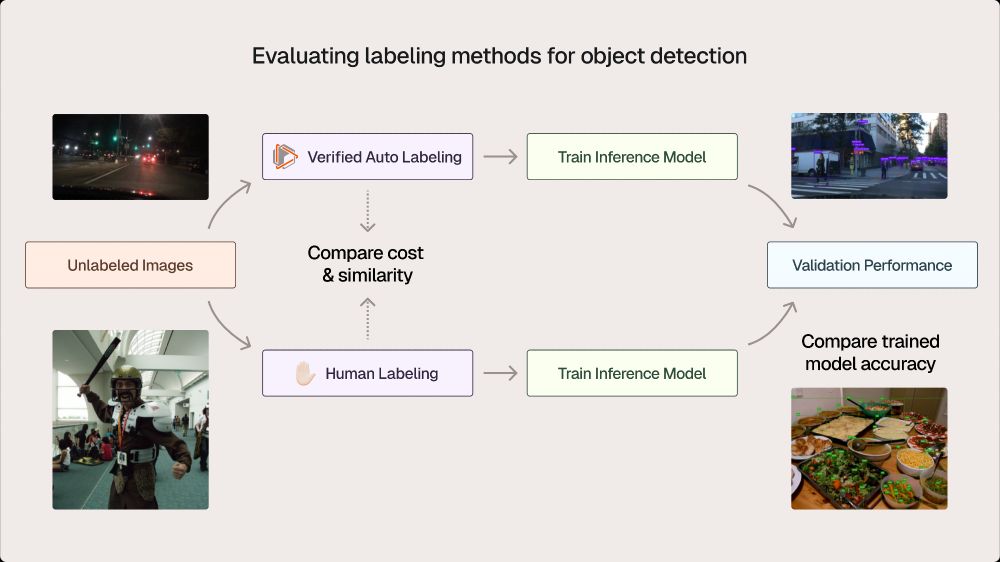
🛠 What we did:
- Used off-the-shelf foundation models to label several benchmark datasets
- Evaluated these labels relative to the human-annotated ground truth
- Used off-the-shelf foundation models to label several benchmark datasets
- Evaluated these labels relative to the human-annotated ground truth
June 4, 2025 at 4:27 PM
🛠 What we did:
- Used off-the-shelf foundation models to label several benchmark datasets
- Evaluated these labels relative to the human-annotated ground truth
- Used off-the-shelf foundation models to label several benchmark datasets
- Evaluated these labels relative to the human-annotated ground truth
Exciting CVML result from the @voxel51.bsky.social ML team: zero-shot object detectors are 100,000x cheaper yet rival humans
The zeitgeist claims zero-shot labeling is here but no one measured it. We did. 95%+ performance of human labels 100,000x cheaper & 5,000x faster
arxiv.org/abs/2506.02359
The zeitgeist claims zero-shot labeling is here but no one measured it. We did. 95%+ performance of human labels 100,000x cheaper & 5,000x faster
arxiv.org/abs/2506.02359

June 4, 2025 at 4:27 PM
Exciting CVML result from the @voxel51.bsky.social ML team: zero-shot object detectors are 100,000x cheaper yet rival humans
The zeitgeist claims zero-shot labeling is here but no one measured it. We did. 95%+ performance of human labels 100,000x cheaper & 5,000x faster
arxiv.org/abs/2506.02359
The zeitgeist claims zero-shot labeling is here but no one measured it. We did. 95%+ performance of human labels 100,000x cheaper & 5,000x faster
arxiv.org/abs/2506.02359
Selective Transparency and The Battle for Open Source
What a great way to start a new week other than a new contributed article in VentureBeat!!! Focus: the battle for open source AI through the serious risk that selective transparency poses.
venturebeat.com/ai/the-open-...
What a great way to start a new week other than a new contributed article in VentureBeat!!! Focus: the battle for open source AI through the serious risk that selective transparency poses.
venturebeat.com/ai/the-open-...

March 24, 2025 at 1:17 PM
Selective Transparency and The Battle for Open Source
What a great way to start a new week other than a new contributed article in VentureBeat!!! Focus: the battle for open source AI through the serious risk that selective transparency poses.
venturebeat.com/ai/the-open-...
What a great way to start a new week other than a new contributed article in VentureBeat!!! Focus: the battle for open source AI through the serious risk that selective transparency poses.
venturebeat.com/ai/the-open-...
Out with the ^$&*%*, in with Open Large Models! Like a breath of fresh are, there are two key reasons to get rid of your OpenAI subscription today, like I just did.

March 22, 2025 at 4:42 PM
Out with the ^$&*%*, in with Open Large Models! Like a breath of fresh are, there are two key reasons to get rid of your OpenAI subscription today, like I just did.
The academic research funding diaspora in the US is going to suck... Why is everyone so quiet?!

March 11, 2025 at 6:47 PM
The academic research funding diaspora in the US is going to suck... Why is everyone so quiet?!
Super impressed by NVIDIA's strategery to drive impact on multiple layers of the AI compute world. IMO Focused, smaller, specialized models are going to see more practical value and ROI before the large ones that currently dominate the conversation.

March 5, 2025 at 4:03 PM
Super impressed by NVIDIA's strategery to drive impact on multiple layers of the AI compute world. IMO Focused, smaller, specialized models are going to see more practical value and ROI before the large ones that currently dominate the conversation.
In overleaf, you can "check" the stop on first error setting in the pdf viewer to help force you to look at the logs!

March 4, 2025 at 4:19 PM
In overleaf, you can "check" the stop on first error setting in the pdf viewer to help force you to look at the logs!
🤠 🔥 🤠 Shout out to the amazing and growing team at Voxel51 as we begin our 2025 offsite retreat in Austin! 🤠 🔥 🤠
Making Visual AI a Reality. Every day. Grew to 50 team members, dozens of F500 custs, 3M open source installs...
Stay tuned for a wild 2025 from @voxel51.bsky.social
Making Visual AI a Reality. Every day. Grew to 50 team members, dozens of F500 custs, 3M open source installs...
Stay tuned for a wild 2025 from @voxel51.bsky.social

February 12, 2025 at 2:46 PM
🤠 🔥 🤠 Shout out to the amazing and growing team at Voxel51 as we begin our 2025 offsite retreat in Austin! 🤠 🔥 🤠
Making Visual AI a Reality. Every day. Grew to 50 team members, dozens of F500 custs, 3M open source installs...
Stay tuned for a wild 2025 from @voxel51.bsky.social
Making Visual AI a Reality. Every day. Grew to 50 team members, dozens of F500 custs, 3M open source installs...
Stay tuned for a wild 2025 from @voxel51.bsky.social
Adapt LLM Vocabularies for New Capabilities
**New Paper Alert** VITRO: Vocabulary Inversion for Time-series Representation Optimization. To appear at ICASSP 2025. w/ Filipos Bellos and Nam Nguyen.
👉 Project Page w/ code: fil-mp.github.io/project_page/
👉 Paper Link: arxiv.org/abs/2412.17921
**New Paper Alert** VITRO: Vocabulary Inversion for Time-series Representation Optimization. To appear at ICASSP 2025. w/ Filipos Bellos and Nam Nguyen.
👉 Project Page w/ code: fil-mp.github.io/project_page/
👉 Paper Link: arxiv.org/abs/2412.17921

February 6, 2025 at 3:42 PM
Adapt LLM Vocabularies for New Capabilities
**New Paper Alert** VITRO: Vocabulary Inversion for Time-series Representation Optimization. To appear at ICASSP 2025. w/ Filipos Bellos and Nam Nguyen.
👉 Project Page w/ code: fil-mp.github.io/project_page/
👉 Paper Link: arxiv.org/abs/2412.17921
**New Paper Alert** VITRO: Vocabulary Inversion for Time-series Representation Optimization. To appear at ICASSP 2025. w/ Filipos Bellos and Nam Nguyen.
👉 Project Page w/ code: fil-mp.github.io/project_page/
👉 Paper Link: arxiv.org/abs/2412.17921
Have y'all seen TransPixar yet? Transparency-specific tokens in the Diffusion Transformer leads to some of the most compelling and practical video gen work I've see to date. So impressed by this. wileewang.github.io/TransPixar/
January 9, 2025 at 3:27 PM
Have y'all seen TransPixar yet? Transparency-specific tokens in the Diffusion Transformer leads to some of the most compelling and practical video gen work I've see to date. So impressed by this. wileewang.github.io/TransPixar/
🥒 ⛔ 🥒 Mistake Detection for Human-AI Teams with VLMs
New Paper Alert!
Explainable Procedural Mistake Detection
With coauthors Shane Storks, Itamar Bar-Yossef, Yayuan Li, Zheyuan Zhang and Joyce Chai
Full Paper: arxiv.org/abs/2412.11927
New Paper Alert!
Explainable Procedural Mistake Detection
With coauthors Shane Storks, Itamar Bar-Yossef, Yayuan Li, Zheyuan Zhang and Joyce Chai
Full Paper: arxiv.org/abs/2412.11927

December 19, 2024 at 3:12 PM
🥒 ⛔ 🥒 Mistake Detection for Human-AI Teams with VLMs
New Paper Alert!
Explainable Procedural Mistake Detection
With coauthors Shane Storks, Itamar Bar-Yossef, Yayuan Li, Zheyuan Zhang and Joyce Chai
Full Paper: arxiv.org/abs/2412.11927
New Paper Alert!
Explainable Procedural Mistake Detection
With coauthors Shane Storks, Itamar Bar-Yossef, Yayuan Li, Zheyuan Zhang and Joyce Chai
Full Paper: arxiv.org/abs/2412.11927
⚠️ 📈 ⚠️ Annotation mistakes got you down? ⚠️ 📈 ⚠️
State of the art mislabel detection to fix the glass ceiling, save MLE time, and save money! Try it on your problem!
👉 Paper Link: arxiv.org/abs/2412.02596
👉 GitHub Repo: github.com/voxel51/reco...
State of the art mislabel detection to fix the glass ceiling, save MLE time, and save money! Try it on your problem!
👉 Paper Link: arxiv.org/abs/2412.02596
👉 GitHub Repo: github.com/voxel51/reco...

December 18, 2024 at 3:10 PM
⚠️ 📈 ⚠️ Annotation mistakes got you down? ⚠️ 📈 ⚠️
State of the art mislabel detection to fix the glass ceiling, save MLE time, and save money! Try it on your problem!
👉 Paper Link: arxiv.org/abs/2412.02596
👉 GitHub Repo: github.com/voxel51/reco...
State of the art mislabel detection to fix the glass ceiling, save MLE time, and save money! Try it on your problem!
👉 Paper Link: arxiv.org/abs/2412.02596
👉 GitHub Repo: github.com/voxel51/reco...
🎥🖐🎥🖐 New Video GenAI with Better Rendering of Hands -> Instructional Video Generation
New Paper Alert!
👉 Project Page: excitedbutter.github.io/project_page/
👉 Paper Link: arxiv.org/abs/2412.04189
👉 GitHub Repo: github.com/ExcitedButte...
New Paper Alert!
👉 Project Page: excitedbutter.github.io/project_page/
👉 Paper Link: arxiv.org/abs/2412.04189
👉 GitHub Repo: github.com/ExcitedButte...
December 17, 2024 at 4:09 PM
🎥🖐🎥🖐 New Video GenAI with Better Rendering of Hands -> Instructional Video Generation
New Paper Alert!
👉 Project Page: excitedbutter.github.io/project_page/
👉 Paper Link: arxiv.org/abs/2412.04189
👉 GitHub Repo: github.com/ExcitedButte...
New Paper Alert!
👉 Project Page: excitedbutter.github.io/project_page/
👉 Paper Link: arxiv.org/abs/2412.04189
👉 GitHub Repo: github.com/ExcitedButte...
💧 📉 💧 Are you wasting money & time: does your data have a leak? 💧 📉 💧
New open source AI feature alert! Leaky splits can be the bane of ML models, giving a false sense of confidence, and a nasty surprise in production.
Blog medium.com/voxel51/on-l...
Code github.com/voxel51/fift...
New open source AI feature alert! Leaky splits can be the bane of ML models, giving a false sense of confidence, and a nasty surprise in production.
Blog medium.com/voxel51/on-l...
Code github.com/voxel51/fift...

December 12, 2024 at 5:24 PM
💧 📉 💧 Are you wasting money & time: does your data have a leak? 💧 📉 💧
New open source AI feature alert! Leaky splits can be the bane of ML models, giving a false sense of confidence, and a nasty surprise in production.
Blog medium.com/voxel51/on-l...
Code github.com/voxel51/fift...
New open source AI feature alert! Leaky splits can be the bane of ML models, giving a false sense of confidence, and a nasty surprise in production.
Blog medium.com/voxel51/on-l...
Code github.com/voxel51/fift...
👽 📈 👽 New Paper Alert! 👽 📈 👽
Class-wise Autoencoders Measure Classification Difficulty and Detect Label Mistakes
Understanding how hard a machine learning problem is has been quite elusive. Not any more.
Paper Link: arxiv.org/abs/2412.02596
GitHub Repo: github.com/voxel51/reco...
Class-wise Autoencoders Measure Classification Difficulty and Detect Label Mistakes
Understanding how hard a machine learning problem is has been quite elusive. Not any more.
Paper Link: arxiv.org/abs/2412.02596
GitHub Repo: github.com/voxel51/reco...

December 10, 2024 at 3:54 PM
👽 📈 👽 New Paper Alert! 👽 📈 👽
Class-wise Autoencoders Measure Classification Difficulty and Detect Label Mistakes
Understanding how hard a machine learning problem is has been quite elusive. Not any more.
Paper Link: arxiv.org/abs/2412.02596
GitHub Repo: github.com/voxel51/reco...
Class-wise Autoencoders Measure Classification Difficulty and Detect Label Mistakes
Understanding how hard a machine learning problem is has been quite elusive. Not any more.
Paper Link: arxiv.org/abs/2412.02596
GitHub Repo: github.com/voxel51/reco...
First hand shrinkflation. This bacon Gouda sandwich (next to a tall coffee) is embarrassingly smaller than I last recall. What the….

December 9, 2024 at 5:49 PM
First hand shrinkflation. This bacon Gouda sandwich (next to a tall coffee) is embarrassingly smaller than I last recall. What the….
New paper alert!
Zero-Shot Coreset Selection: Efficient Pruning for Unlabeled Data
Training models requires massive amounts of labeled data. ZCore shows you that you need less labeled data to train good models.
Paper Link: arxiv.org/abs/2411.15349
GitHub Repo: github.com/voxel51/zcore
Zero-Shot Coreset Selection: Efficient Pruning for Unlabeled Data
Training models requires massive amounts of labeled data. ZCore shows you that you need less labeled data to train good models.
Paper Link: arxiv.org/abs/2411.15349
GitHub Repo: github.com/voxel51/zcore

December 9, 2024 at 4:59 PM
New paper alert!
Zero-Shot Coreset Selection: Efficient Pruning for Unlabeled Data
Training models requires massive amounts of labeled data. ZCore shows you that you need less labeled data to train good models.
Paper Link: arxiv.org/abs/2411.15349
GitHub Repo: github.com/voxel51/zcore
Zero-Shot Coreset Selection: Efficient Pruning for Unlabeled Data
Training models requires massive amounts of labeled data. ZCore shows you that you need less labeled data to train good models.
Paper Link: arxiv.org/abs/2411.15349
GitHub Repo: github.com/voxel51/zcore