


Isabel Papadimitriou
@isabelpapad.bsky.social
(jolly good) Fellow at the Kempner Institute @kempnerinstitute.bsky.social, incoming assistant professor at UBC Linguistics (and by courtesy CS, Sept 2025). PhD @stanfordnlp.bsky.social with the lovely @jurafsky.bsky.social
isabelpapad.com
isabelpapad.com
Lastly, we didn’t just go blindly into batchtopk SAEs, we tried other SAEs and a semi-NMF, but they don’t work as well: batchtopk dominates the reconstruction-sparsity tradeoff

September 17, 2025 at 7:12 PM
Lastly, we didn’t just go blindly into batchtopk SAEs, we tried other SAEs and a semi-NMF, but they don’t work as well: batchtopk dominates the reconstruction-sparsity tradeoff
Check out our interactive demo (by the amazing @napoolar), where bridges illustrate our BridgeScore metric: a combination geometrical alignment (cosine) and statistical alignment (coactivation on image-caption pairs): vlm-concept-visualization.com

September 17, 2025 at 7:12 PM
Check out our interactive demo (by the amazing @napoolar), where bridges illustrate our BridgeScore metric: a combination geometrical alignment (cosine) and statistical alignment (coactivation on image-caption pairs): vlm-concept-visualization.com
And they’re stable ~across training data mixtures~! If we train the SAEs with a 5:1 ratio of text to images, we get a lot more text concepts (makes sense!). But if we weight the points by activation scores (bottom), we see basically the same concepts across very different mixtures

September 17, 2025 at 7:12 PM
And they’re stable ~across training data mixtures~! If we train the SAEs with a 5:1 ratio of text to images, we get a lot more text concepts (makes sense!). But if we weight the points by activation scores (bottom), we see basically the same concepts across very different mixtures
But, are the SAEs even stable? It wouldn’t be very enlightening if we were just analyzing a fluke of the SAE seed. Across seeds, we find that frequently-used concepts (the ones that take up 99% of activation weights) are remarkably stable, but the rest are pretty darn unstable.

September 17, 2025 at 7:12 PM
But, are the SAEs even stable? It wouldn’t be very enlightening if we were just analyzing a fluke of the SAE seed. Across seeds, we find that frequently-used concepts (the ones that take up 99% of activation weights) are remarkably stable, but the rest are pretty darn unstable.
How can this be? Because of the projection effect in SAEs! When we impose sparisty, then the inputs that are activated don’t necessarily reflect the whole story of what inputs align with that direction. Here, the batchtopk cutoff (dotted line) hides a multimodal story

September 17, 2025 at 7:12 PM
How can this be? Because of the projection effect in SAEs! When we impose sparisty, then the inputs that are activated don’t necessarily reflect the whole story of what inputs align with that direction. Here, the batchtopk cutoff (dotted line) hides a multimodal story
On first blush, however, the concepts look pretty single-modality: see here their modality scores (how many of the top-activating inputs are images vs text). The classifier results above show us that the actual geometry is often much closer to modality-agnostic.

September 17, 2025 at 7:12 PM
On first blush, however, the concepts look pretty single-modality: see here their modality scores (how many of the top-activating inputs are images vs text). The classifier results above show us that the actual geometry is often much closer to modality-agnostic.
In fact, they often can’t even act as good modality classifiers: if we take the SAE concept direction, and see how well projecting on to that direction separates modality, we see that many of the concepts don’t get great accuracy

September 17, 2025 at 7:12 PM
In fact, they often can’t even act as good modality classifiers: if we take the SAE concept direction, and see how well projecting on to that direction separates modality, we see that many of the concepts don’t get great accuracy
Are there conceptual directions in VLMs that transcend modality? Check out our COLM oral spotlight 🔦 paper! We use SAEs to analyze the multimodality of linear concepts in VLMs
with @chloesu07.bsky.social, @thomasfel.bsky.social, @shamkakade.bsky.social and Stephanie Gil
arxiv.org/abs/2504.11695
with @chloesu07.bsky.social, @thomasfel.bsky.social, @shamkakade.bsky.social and Stephanie Gil
arxiv.org/abs/2504.11695

September 17, 2025 at 7:12 PM
Are there conceptual directions in VLMs that transcend modality? Check out our COLM oral spotlight 🔦 paper! We use SAEs to analyze the multimodality of linear concepts in VLMs
with @chloesu07.bsky.social, @thomasfel.bsky.social, @shamkakade.bsky.social and Stephanie Gil
arxiv.org/abs/2504.11695
with @chloesu07.bsky.social, @thomasfel.bsky.social, @shamkakade.bsky.social and Stephanie Gil
arxiv.org/abs/2504.11695
Our experiments are based on Linguistics Olympiad problems that deal with number systems, like the one here. We created additional hand-standardized versions of each puzzle in order to be able to do all of the operator ablations.

June 18, 2025 at 6:31 PM
Our experiments are based on Linguistics Olympiad problems that deal with number systems, like the one here. We created additional hand-standardized versions of each puzzle in order to be able to do all of the operator ablations.
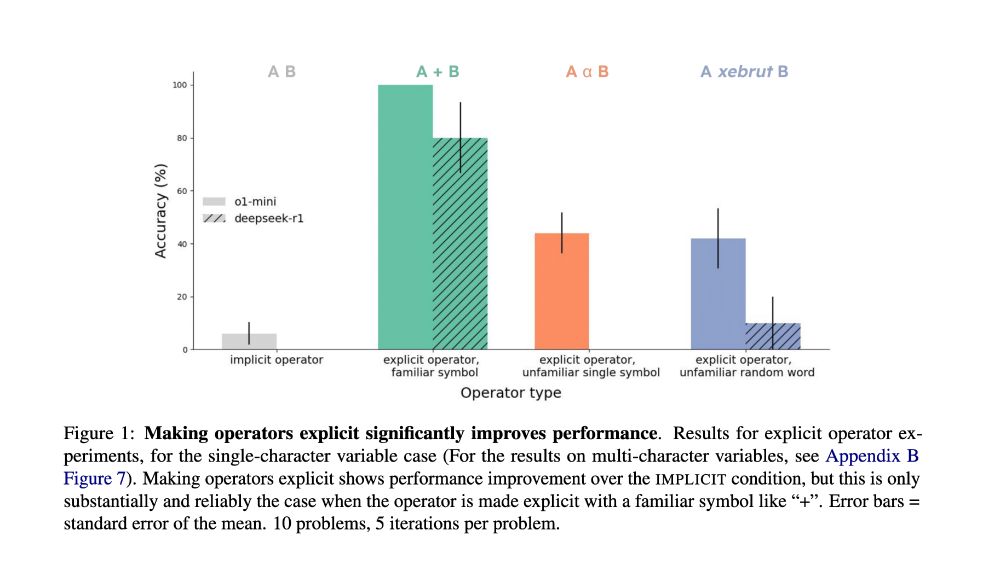
Our main finding: LMs find it hard when *operators* are implicit. We don’t say “5 times 100 plus 20 plus 3”, we say “five hundred and twenty-three”. The Linguistics Olympiad puzzles are pretty simple systems of equations that an LM should solve – but the operators aren’t explicit.
June 18, 2025 at 6:31 PM
Our main finding: LMs find it hard when *operators* are implicit. We don’t say “5 times 100 plus 20 plus 3”, we say “five hundred and twenty-three”. The Linguistics Olympiad puzzles are pretty simple systems of equations that an LM should solve – but the operators aren’t explicit.
Why can’t LMs solve puzzles about the number systems of languages, when they can solve really complex math problems? Our new paper, led by @antararb.bsky.social looks at why this intersection of language and math is difficult, and what this means for LM reasoning! arxiv.org/abs/2506.13886

June 18, 2025 at 6:31 PM
Why can’t LMs solve puzzles about the number systems of languages, when they can solve really complex math problems? Our new paper, led by @antararb.bsky.social looks at why this intersection of language and math is difficult, and what this means for LM reasoning! arxiv.org/abs/2506.13886
Do you want to understand how language models work, and how they can change language science? I'm recruiting PhD students at UBC Linguistics! The research will be fun, and Vancouver is lovely. So much cool NLP happening at UBC across both Ling and CS! linguistics.ubc.ca/graduate/adm...

November 18, 2024 at 7:43 PM
Do you want to understand how language models work, and how they can change language science? I'm recruiting PhD students at UBC Linguistics! The research will be fun, and Vancouver is lovely. So much cool NLP happening at UBC across both Ling and CS! linguistics.ubc.ca/graduate/adm...