




Ibrahim Alabdulmohsin
@ibomohsin.bsky.social
AI research scientist at Google Deepmind, Zürich
So, please check out our work:
abs: arxiv.org/abs/2502.07503
pdf: arxiv.org/pdf/2502.07503
and please reach out for any comments or questions.
abs: arxiv.org/abs/2502.07503
pdf: arxiv.org/pdf/2502.07503
and please reach out for any comments or questions.

Harnessing Language's Fractal Geometry with Recursive Inference Scaling
Recent research in language modeling reveals two scaling effects: the well-known improvement from increased training compute, and a lesser-known boost from applying more sophisticated or computational...
arxiv.org
February 12, 2025 at 8:54 AM
So, please check out our work:
abs: arxiv.org/abs/2502.07503
pdf: arxiv.org/pdf/2502.07503
and please reach out for any comments or questions.
abs: arxiv.org/abs/2502.07503
pdf: arxiv.org/pdf/2502.07503
and please reach out for any comments or questions.
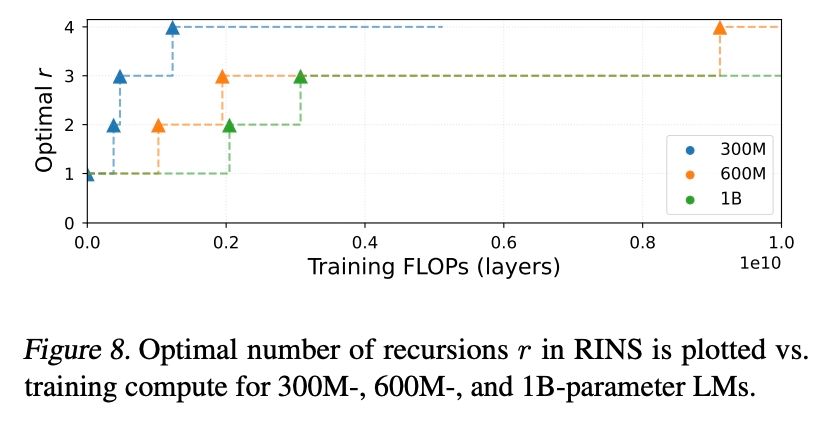
Good, but how many recursion rounds do I need? The optimal number of recursion rounds depends on the model size and training compute budget. Smaller models benefit more from RINS. Also, RINS helps more with long-training durations.
February 12, 2025 at 8:54 AM
Good, but how many recursion rounds do I need? The optimal number of recursion rounds depends on the model size and training compute budget. Smaller models benefit more from RINS. Also, RINS helps more with long-training durations.
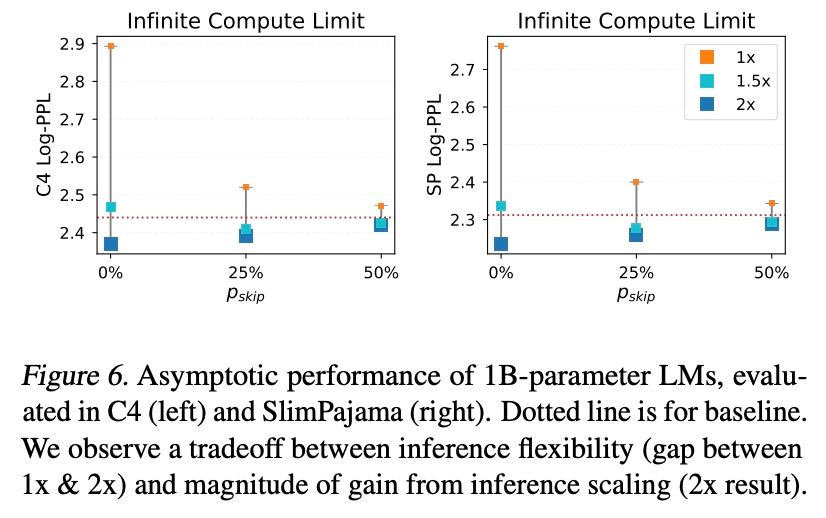
Besides, we also introduce *stochastic* RINS where we select the number of recursion rounds from a binomial distribution. This *improves* performance in SigLIP (despite also *saving* training flops). But in LM, there is a tradeoff between flexibility and maximum performance gain.
February 12, 2025 at 8:54 AM
Besides, we also introduce *stochastic* RINS where we select the number of recursion rounds from a binomial distribution. This *improves* performance in SigLIP (despite also *saving* training flops). But in LM, there is a tradeoff between flexibility and maximum performance gain.
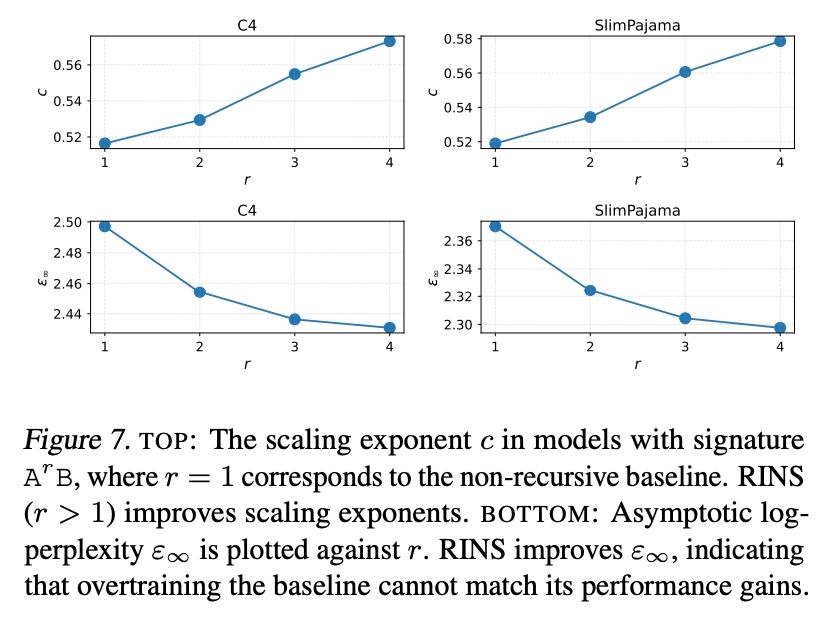
Question: what if we use infinite compute? Will the gap vanish? We did scaling analysis and found that RINS improves both the asymptotic performance limit (so the gap actually increases, not vanishes) and improves convergence speed (scaling exponent).
February 12, 2025 at 8:54 AM
Question: what if we use infinite compute? Will the gap vanish? We did scaling analysis and found that RINS improves both the asymptotic performance limit (so the gap actually increases, not vanishes) and improves convergence speed (scaling exponent).
Our inspiration came from the study of self-similarity in language. If patterns are shared across scales, could scale-invariant decoding serve as a good inductive bias for processing language? It turns out that it does!
February 12, 2025 at 8:54 AM
Our inspiration came from the study of self-similarity in language. If patterns are shared across scales, could scale-invariant decoding serve as a good inductive bias for processing language? It turns out that it does!
To repeat, we train RINS on less data to match the same compute flops, which is why this is a stronger result than “sample efficiency”, and one should not just expect it to work. E.g. it does NOT help in image classification but RINS works in language and multimodal. Why? (3/n)🤔
February 12, 2025 at 8:54 AM
To repeat, we train RINS on less data to match the same compute flops, which is why this is a stronger result than “sample efficiency”, and one should not just expect it to work. E.g. it does NOT help in image classification but RINS works in language and multimodal. Why? (3/n)🤔
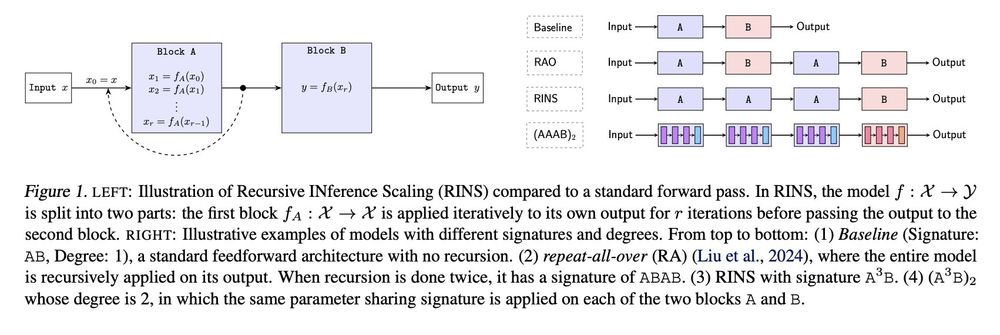
RINS is trivial to implement. After you pick your favorite model & fix your training budget: (1) partition the model into 2 equally-sized blocks, (2) apply recursion on the first and train for the same amount of compute you had planned -> meaning with *fewer* examples! That’s it!
February 12, 2025 at 8:54 AM
RINS is trivial to implement. After you pick your favorite model & fix your training budget: (1) partition the model into 2 equally-sized blocks, (2) apply recursion on the first and train for the same amount of compute you had planned -> meaning with *fewer* examples! That’s it!
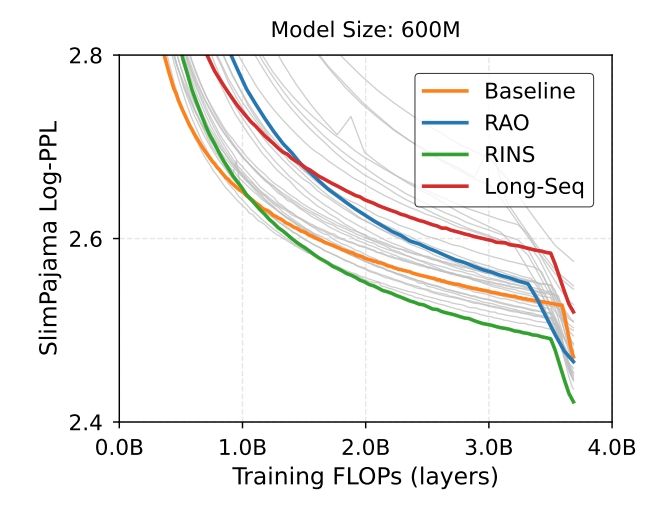
Recursion is trending (e.g. MobileLLM). But recursion adds compute / example so to show that it helps, one must match training flops; otherwise we could’ve just trained the baseline longer. With this, RINS beats +60 other recursive methods. (2/n)
February 12, 2025 at 8:54 AM
Recursion is trending (e.g. MobileLLM). But recursion adds compute / example so to show that it helps, one must match training flops; otherwise we could’ve just trained the baseline longer. With this, RINS beats +60 other recursive methods. (2/n)
Have you wondered why next-token prediction can be such a powerful training objective? Come visit our poster to talk about language and fractals and how to predict downstream performance in LLMs better.
Poster #3105, Fri 13 Dec 4:30-7:30pm
x.com/ibomohsin/st...
See you there!
Poster #3105, Fri 13 Dec 4:30-7:30pm
x.com/ibomohsin/st...
See you there!
x.com
x.com
December 7, 2024 at 6:50 PM
Have you wondered why next-token prediction can be such a powerful training objective? Come visit our poster to talk about language and fractals and how to predict downstream performance in LLMs better.
Poster #3105, Fri 13 Dec 4:30-7:30pm
x.com/ibomohsin/st...
See you there!
Poster #3105, Fri 13 Dec 4:30-7:30pm
x.com/ibomohsin/st...
See you there!
Language interface is truly powerful! In LocCa, we show how simple image-captioning pretraining tasks improve localization without specialized vocabulary, while preserving holistic performance → SoTA on RefCOCO!
Poster #3602, Thu 12 Dec 4:30-7:30pm
arxiv.org/abs/2403.19596
Poster #3602, Thu 12 Dec 4:30-7:30pm
arxiv.org/abs/2403.19596

LocCa: Visual Pretraining with Location-aware Captioners
Image captioning has been shown as an effective pretraining method similar to contrastive pretraining. However, the incorporation of location-aware information into visual pretraining remains an area ...
arxiv.org
December 7, 2024 at 6:50 PM
Language interface is truly powerful! In LocCa, we show how simple image-captioning pretraining tasks improve localization without specialized vocabulary, while preserving holistic performance → SoTA on RefCOCO!
Poster #3602, Thu 12 Dec 4:30-7:30pm
arxiv.org/abs/2403.19596
Poster #3602, Thu 12 Dec 4:30-7:30pm
arxiv.org/abs/2403.19596
1st, we present recipes for evaluating and improving cultural diversity in contrastive models, with practical, actionable insights.
Poster #3810, Wed 11 Dec 11am-2pm (2/4)
x.com/ibomohsin/st...
Poster #3810, Wed 11 Dec 11am-2pm (2/4)
x.com/ibomohsin/st...
x.com
x.com
December 7, 2024 at 6:50 PM
1st, we present recipes for evaluating and improving cultural diversity in contrastive models, with practical, actionable insights.
Poster #3810, Wed 11 Dec 11am-2pm (2/4)
x.com/ibomohsin/st...
Poster #3810, Wed 11 Dec 11am-2pm (2/4)
x.com/ibomohsin/st...