



Haokun Liu
@haokunliu.bsky.social
Ph.D. Student at the University of Chicago | Chicago Human + AI Lab
haokunliu.com
haokunliu.com
Big thanks to @chicagohai.bsky.social team and everyone who submitted ideas on IdeaHub. Special shoutout to the open source community building research agents! We're all learning together.
November 10, 2025 at 10:46 PM
Big thanks to @chicagohai.bsky.social team and everyone who submitted ideas on IdeaHub. Special shoutout to the open source community building research agents! We're all learning together.
All 6 generated repositories with detailed code and reports:
- github.com/ChicagoHAI/l...
- github.com/ChicagoHAI/l...
- github.com/ChicagoHAI/i...
- github.com/ChicagoHAI/i...
- github.com/ChicagoHAI/l...
- github.com/ChicagoHAI/l...
- github.com/ChicagoHAI/l...
- github.com/ChicagoHAI/l...
- github.com/ChicagoHAI/i...
- github.com/ChicagoHAI/i...
- github.com/ChicagoHAI/l...
- github.com/ChicagoHAI/l...
November 10, 2025 at 10:45 PM
All 6 generated repositories with detailed code and reports:
- github.com/ChicagoHAI/l...
- github.com/ChicagoHAI/l...
- github.com/ChicagoHAI/i...
- github.com/ChicagoHAI/i...
- github.com/ChicagoHAI/l...
- github.com/ChicagoHAI/l...
- github.com/ChicagoHAI/l...
- github.com/ChicagoHAI/l...
- github.com/ChicagoHAI/i...
- github.com/ChicagoHAI/i...
- github.com/ChicagoHAI/l...
- github.com/ChicagoHAI/l...
Submit your idea, vote on existing ones, or help improve idea-explorer: github.com/ChicagoHAI/i...
Full blog with technical details:
hypogenic.ai/blog/weekly-...
Substack: open.substack.com/pub/cichicag...
Full blog with technical details:
hypogenic.ai/blog/weekly-...
Substack: open.substack.com/pub/cichicag...
Hypogenic AI - Shaping the Future of Science
Reimagining science by augmenting scientist-AI collaboration.
hypogenic.ai
November 10, 2025 at 10:45 PM
Submit your idea, vote on existing ones, or help improve idea-explorer: github.com/ChicagoHAI/i...
Full blog with technical details:
hypogenic.ai/blog/weekly-...
Substack: open.substack.com/pub/cichicag...
Full blog with technical details:
hypogenic.ai/blog/weekly-...
Substack: open.substack.com/pub/cichicag...
So why are we doing this openly?
Because agents clearly can accelerate early-stage exploration. But they need human oversight at every step. Transparent benchmarking beats cherry-picked demos. Community feedback improves agents faster. And honestly, we're all figuring this out together.
Because agents clearly can accelerate early-stage exploration. But they need human oversight at every step. Transparent benchmarking beats cherry-picked demos. Community feedback improves agents faster. And honestly, we're all figuring this out together.
November 10, 2025 at 10:44 PM
So why are we doing this openly?
Because agents clearly can accelerate early-stage exploration. But they need human oversight at every step. Transparent benchmarking beats cherry-picked demos. Community feedback improves agents faster. And honestly, we're all figuring this out together.
Because agents clearly can accelerate early-stage exploration. But they need human oversight at every step. Transparent benchmarking beats cherry-picked demos. Community feedback improves agents faster. And honestly, we're all figuring this out together.
Existing agents like AI-Scientist and AI-Researcher are basically overfitted to ML. There are hard-coded prompts that “requires changing hyperparameters and train on HuggingFace datasets” or specific ML agents. Just changing prompt won’t be enough, as ML assumptions are everywhere in the codebase.
November 10, 2025 at 10:44 PM
Existing agents like AI-Scientist and AI-Researcher are basically overfitted to ML. There are hard-coded prompts that “requires changing hyperparameters and train on HuggingFace datasets” or specific ML agents. Just changing prompt won’t be enough, as ML assumptions are everywhere in the codebase.
The pattern: we can fix specific bugs with better prompts (bias-variance tradeoff). But we can't prompt our way to knowing when to search, recognizing expertise boundaries, or understanding what rigorous methodology looks like.
That's what I call the "meta intelligence" gap.
That's what I call the "meta intelligence" gap.
November 10, 2025 at 10:43 PM
The pattern: we can fix specific bugs with better prompts (bias-variance tradeoff). But we can't prompt our way to knowing when to search, recognizing expertise boundaries, or understanding what rigorous methodology looks like.
That's what I call the "meta intelligence" gap.
That's what I call the "meta intelligence" gap.
What didn’t
Some agents run faked human data, used undersized models even though compute was available, or calling simple answer reweighting as "multi-agent interactions". Resource collection and allocation is a bottleneck, but more importantly, the agents do not know when to search or seek help.
Some agents run faked human data, used undersized models even though compute was available, or calling simple answer reweighting as "multi-agent interactions". Resource collection and allocation is a bottleneck, but more importantly, the agents do not know when to search or seek help.
November 10, 2025 at 10:43 PM
What didn’t
Some agents run faked human data, used undersized models even though compute was available, or calling simple answer reweighting as "multi-agent interactions". Resource collection and allocation is a bottleneck, but more importantly, the agents do not know when to search or seek help.
Some agents run faked human data, used undersized models even though compute was available, or calling simple answer reweighting as "multi-agent interactions". Resource collection and allocation is a bottleneck, but more importantly, the agents do not know when to search or seek help.
What worked
Agents can actually design and run small experiments: sometimes to seed bigger studies, sometimes as sanity checks, and sometimes to straight-up refute the original hypothesis. That kind of evidence is way more useful than “LLM-as-a-judge says the idea is good.”
Agents can actually design and run small experiments: sometimes to seed bigger studies, sometimes as sanity checks, and sometimes to straight-up refute the original hypothesis. That kind of evidence is way more useful than “LLM-as-a-judge says the idea is good.”
November 10, 2025 at 10:40 PM
What worked
Agents can actually design and run small experiments: sometimes to seed bigger studies, sometimes as sanity checks, and sometimes to straight-up refute the original hypothesis. That kind of evidence is way more useful than “LLM-as-a-judge says the idea is good.”
Agents can actually design and run small experiments: sometimes to seed bigger studies, sometimes as sanity checks, and sometimes to straight-up refute the original hypothesis. That kind of evidence is way more useful than “LLM-as-a-judge says the idea is good.”
There's a lot of hype on AI agents for science. But what can they actually do? We tested our idea-explorer on ideas from IdeaHub:
Do LLMs have different types of beliefs?
Can formal rules make AI agents honest about their uncertainty?
Can LLMs temporarily ignore their training to follow new rules?
Do LLMs have different types of beliefs?
Can formal rules make AI agents honest about their uncertainty?
Can LLMs temporarily ignore their training to follow new rules?
November 10, 2025 at 10:35 PM
There's a lot of hype on AI agents for science. But what can they actually do? We tested our idea-explorer on ideas from IdeaHub:
Do LLMs have different types of beliefs?
Can formal rules make AI agents honest about their uncertainty?
Can LLMs temporarily ignore their training to follow new rules?
Do LLMs have different types of beliefs?
Can formal rules make AI agents honest about their uncertainty?
Can LLMs temporarily ignore their training to follow new rules?
Here's how it works:
→ Submit your research idea or upvote existing ones (tag: "Weekly Competition")
→ Each Monday we select top 3 from previous week
→ We run experiments using research agents
→ Share repos + findings back on IdeaHub
Vote here: hypogenic.ai/ideahub
→ Submit your research idea or upvote existing ones (tag: "Weekly Competition")
→ Each Monday we select top 3 from previous week
→ We run experiments using research agents
→ Share repos + findings back on IdeaHub
Vote here: hypogenic.ai/ideahub
Hypogenic AI - Shaping the Future of Science
Reimagining science by augmenting scientist-AI collaboration.
hypogenic.ai
November 10, 2025 at 9:33 PM
Here's how it works:
→ Submit your research idea or upvote existing ones (tag: "Weekly Competition")
→ Each Monday we select top 3 from previous week
→ We run experiments using research agents
→ Share repos + findings back on IdeaHub
Vote here: hypogenic.ai/ideahub
→ Submit your research idea or upvote existing ones (tag: "Weekly Competition")
→ Each Monday we select top 3 from previous week
→ We run experiments using research agents
→ Share repos + findings back on IdeaHub
Vote here: hypogenic.ai/ideahub
Reposted by Haokun Liu

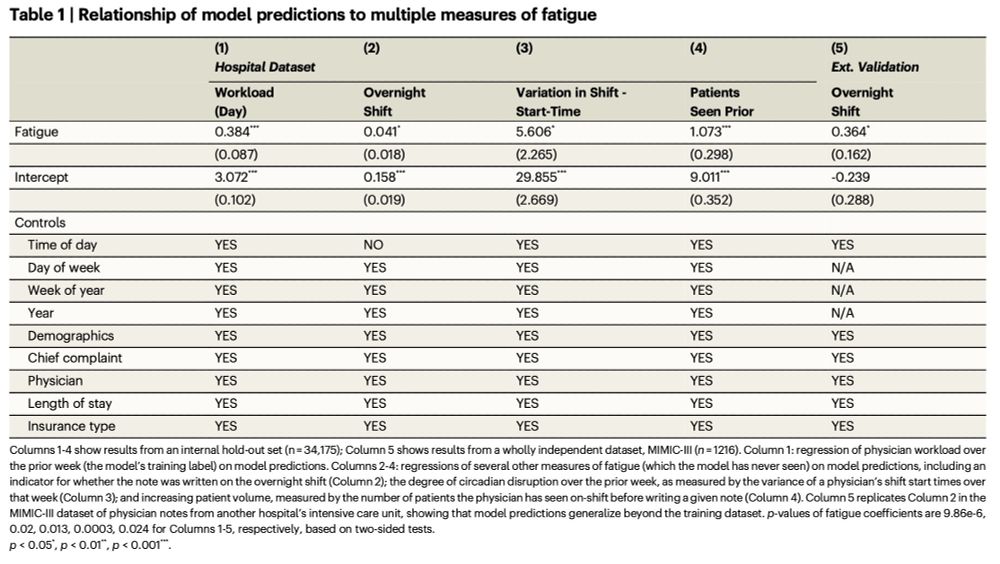
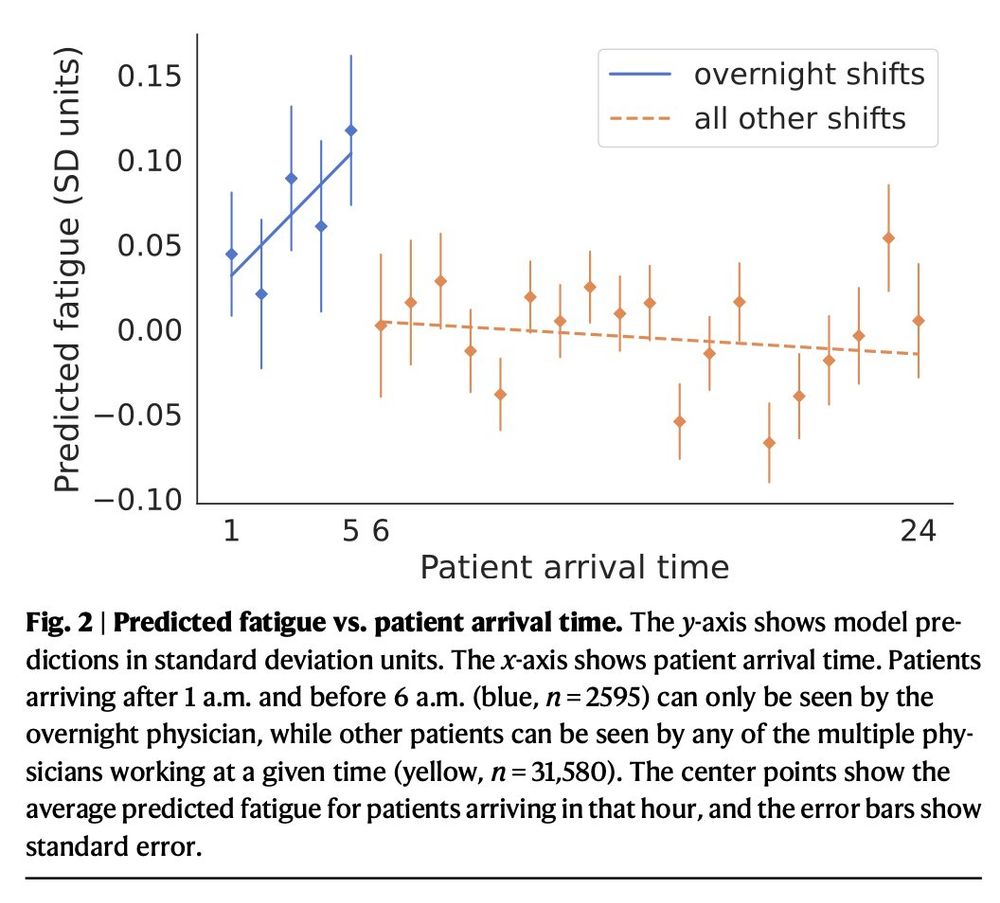
It predicts pretty well—not just shifts in the last week, but also:
1. Who’s working an overnight shift (in our data + external validation in MIMIC)
2. Who’s working on a disruptive circadian schedule
3. How many patients has the doc seen *on the current shift*
1. Who’s working an overnight shift (in our data + external validation in MIMIC)
2. Who’s working on a disruptive circadian schedule
3. How many patients has the doc seen *on the current shift*
July 2, 2025 at 7:24 PM
It predicts pretty well—not just shifts in the last week, but also:
1. Who’s working an overnight shift (in our data + external validation in MIMIC)
2. Who’s working on a disruptive circadian schedule
3. How many patients has the doc seen *on the current shift*
1. Who’s working an overnight shift (in our data + external validation in MIMIC)
2. Who’s working on a disruptive circadian schedule
3. How many patients has the doc seen *on the current shift*
13/ Lastly, great thanks to my wonderful collaborators Sicong Huang, Jingyu Hu, @qiaoyu-rosa.bsky.social , and my advisor @chenhaotan.bsky.social !
April 28, 2025 at 7:40 PM
13/ Lastly, great thanks to my wonderful collaborators Sicong Huang, Jingyu Hu, @qiaoyu-rosa.bsky.social , and my advisor @chenhaotan.bsky.social !