



Haokun Liu
@haokunliu.bsky.social
Ph.D. Student at the University of Chicago | Chicago Human + AI Lab
haokunliu.com
haokunliu.com
Pinned

We're launching a weekly competition where the community decides which research ideas get implemented. Every week, we'll take the top 3 ideas from IdeaHub, run experiments with AI agents, and share everything: code, successes, and failures.
It's completely free and we'll try out ideas for you!
It's completely free and we'll try out ideas for you!
We're launching a weekly competition where the community decides which research ideas get implemented. Every week, we'll take the top 3 ideas from IdeaHub, run experiments with AI agents, and share everything: code, successes, and failures.
It's completely free and we'll try out ideas for you!
It's completely free and we'll try out ideas for you!
November 10, 2025 at 9:32 PM
We're launching a weekly competition where the community decides which research ideas get implemented. Every week, we'll take the top 3 ideas from IdeaHub, run experiments with AI agents, and share everything: code, successes, and failures.
It's completely free and we'll try out ideas for you!
It's completely free and we'll try out ideas for you!
Reposted by Haokun Liu

❓ Does an LLM know thyself? 🪞
Humans pass the mirror test at ~18 months 👶
But what about LLMs? Can they recognize their own writing—or even admit authorship at all?
In our new paper, we put 10 state-of-the-art models to the test. Read on 👇
1/n 🧵
Humans pass the mirror test at ~18 months 👶
But what about LLMs? Can they recognize their own writing—or even admit authorship at all?
In our new paper, we put 10 state-of-the-art models to the test. Read on 👇
1/n 🧵

October 27, 2025 at 5:36 PM
❓ Does an LLM know thyself? 🪞
Humans pass the mirror test at ~18 months 👶
But what about LLMs? Can they recognize their own writing—or even admit authorship at all?
In our new paper, we put 10 state-of-the-art models to the test. Read on 👇
1/n 🧵
Humans pass the mirror test at ~18 months 👶
But what about LLMs? Can they recognize their own writing—or even admit authorship at all?
In our new paper, we put 10 state-of-the-art models to the test. Read on 👇
1/n 🧵
Replacing scientists with AI isn’t just unlikely, it’s a bad design goal.
The better path is collaborative science. Let AI explore the ideas, draft hypotheses, surface evidence, and propose checks. Let humans decide what matters, set standards, and judge what counts as discovery.
The better path is collaborative science. Let AI explore the ideas, draft hypotheses, surface evidence, and propose checks. Let humans decide what matters, set standards, and judge what counts as discovery.
AI can accelerate scientific discovery, but only if we get the scientist–AI interaction right.
The dream of “autonomous AI scientists” is tempting:
machines that generate hypotheses, run experiments, and write papers. But science isn’t just automation.
cichicago.substack.com/p/the-mirage...
🧵
The dream of “autonomous AI scientists” is tempting:
machines that generate hypotheses, run experiments, and write papers. But science isn’t just automation.
cichicago.substack.com/p/the-mirage...
🧵

The Mirage of Autonomous AI Scientists
Science as AI’s killer application cannot succeed without scientist-AI interaction: Introducing Hypogenic.ai.
cichicago.substack.com
October 23, 2025 at 8:29 PM
Replacing scientists with AI isn’t just unlikely, it’s a bad design goal.
The better path is collaborative science. Let AI explore the ideas, draft hypotheses, surface evidence, and propose checks. Let humans decide what matters, set standards, and judge what counts as discovery.
The better path is collaborative science. Let AI explore the ideas, draft hypotheses, surface evidence, and propose checks. Let humans decide what matters, set standards, and judge what counts as discovery.
Reposted by Haokun Liu

🚀 We’re thrilled to announce the upcoming AI & Scientific Discovery online seminar! We have an amazing lineup of speakers.
This series will dive into how AI is accelerating research, enabling breakthroughs, and shaping the future of research across disciplines.
ai-scientific-discovery.github.io
This series will dive into how AI is accelerating research, enabling breakthroughs, and shaping the future of research across disciplines.
ai-scientific-discovery.github.io
September 25, 2025 at 6:28 PM
🚀 We’re thrilled to announce the upcoming AI & Scientific Discovery online seminar! We have an amazing lineup of speakers.
This series will dive into how AI is accelerating research, enabling breakthroughs, and shaping the future of research across disciplines.
ai-scientific-discovery.github.io
This series will dive into how AI is accelerating research, enabling breakthroughs, and shaping the future of research across disciplines.
ai-scientific-discovery.github.io
Reposted by Haokun Liu
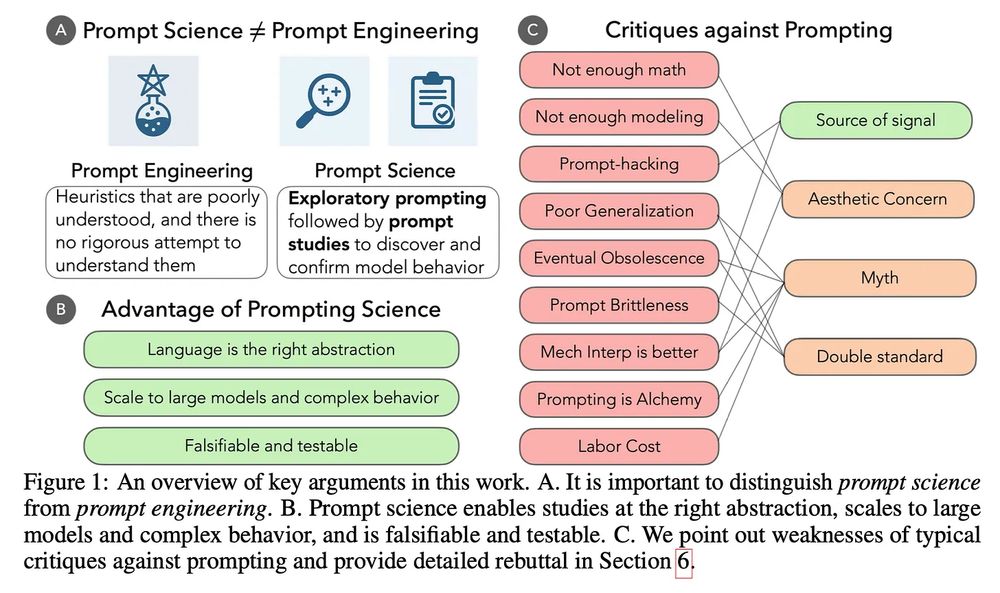
Prompting is our most successful tool for exploring LLMs, but the term evokes eye-rolls and grimaces from scientists. Why? Because prompting as scientific inquiry has become conflated with prompt engineering.
This is holding us back. 🧵and new paper with @ari-holtzman.bsky.social .
This is holding us back. 🧵and new paper with @ari-holtzman.bsky.social .
July 9, 2025 at 8:07 PM
Prompting is our most successful tool for exploring LLMs, but the term evokes eye-rolls and grimaces from scientists. Why? Because prompting as scientific inquiry has become conflated with prompt engineering.
This is holding us back. 🧵and new paper with @ari-holtzman.bsky.social .
This is holding us back. 🧵and new paper with @ari-holtzman.bsky.social .
Reposted by Haokun Liu

We are making som exciting updates to hypogenic this summer: github.com/ChicagoHAI/h... and will post updates here.
GitHub - ChicagoHAI/hypothesis-generation: This is the official repository for HypoGeniC (Hypothesis Generation in Context) and HypoRefine, which are automated, data-driven tools that leverage large l...
This is the official repository for HypoGeniC (Hypothesis Generation in Context) and HypoRefine, which are automated, data-driven tools that leverage large language models to generate hypothesis fo...
github.com
July 9, 2025 at 1:50 PM
We are making som exciting updates to hypogenic this summer: github.com/ChicagoHAI/h... and will post updates here.
Reposted by Haokun Liu
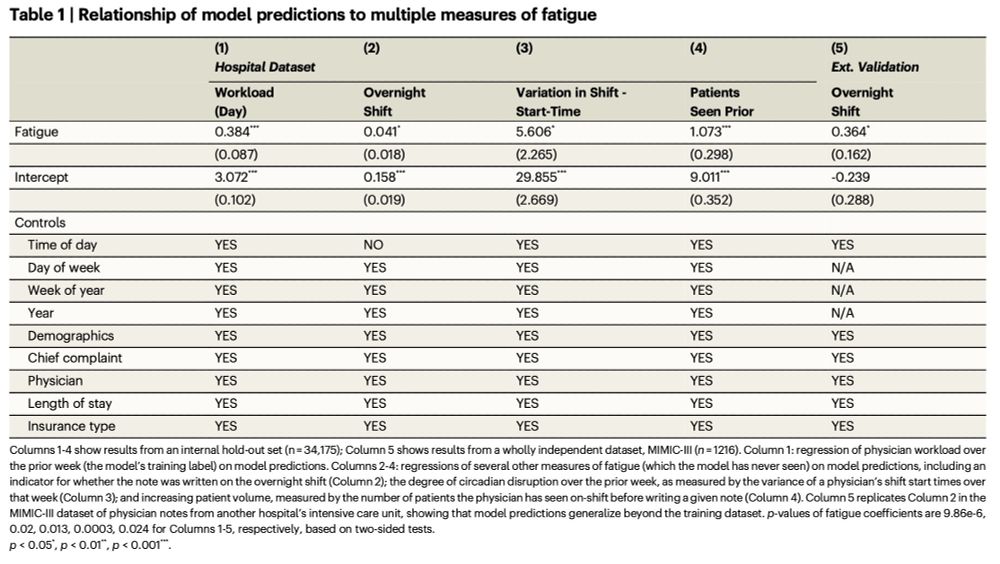
It predicts pretty well—not just shifts in the last week, but also:
1. Who’s working an overnight shift (in our data + external validation in MIMIC)
2. Who’s working on a disruptive circadian schedule
3. How many patients has the doc seen *on the current shift*
1. Who’s working an overnight shift (in our data + external validation in MIMIC)
2. Who’s working on a disruptive circadian schedule
3. How many patients has the doc seen *on the current shift*
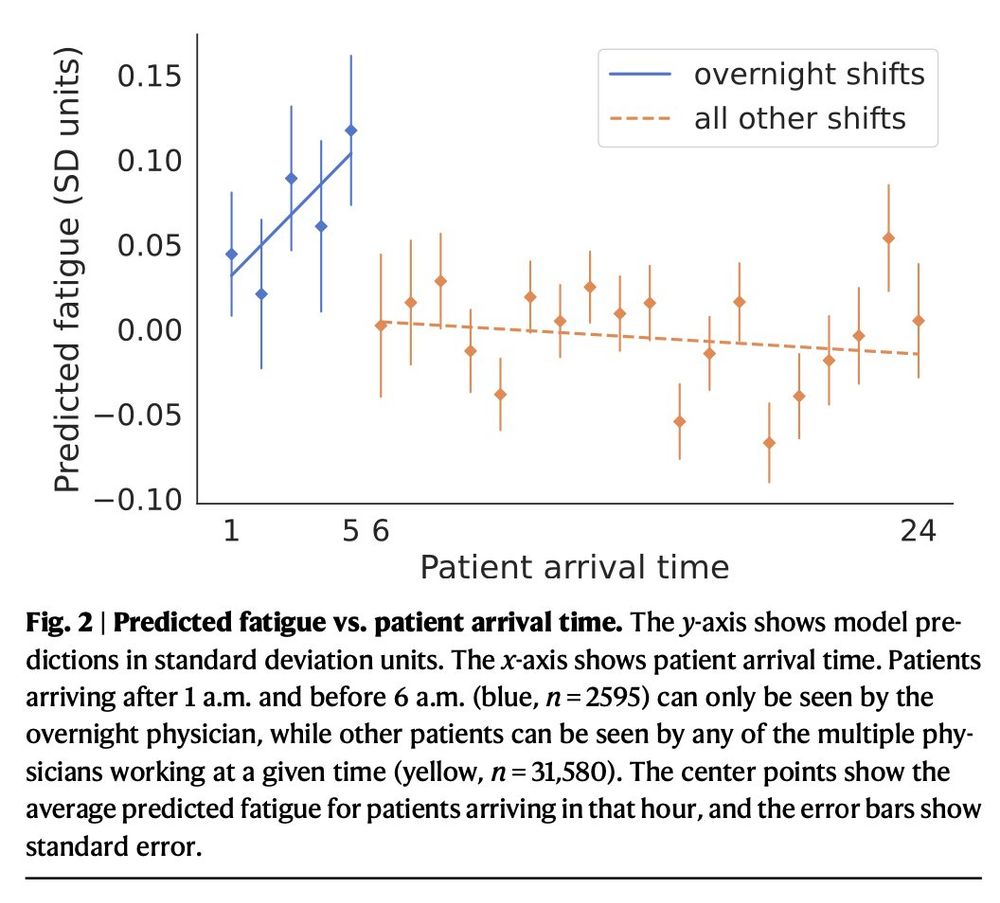
July 2, 2025 at 7:24 PM
It predicts pretty well—not just shifts in the last week, but also:
1. Who’s working an overnight shift (in our data + external validation in MIMIC)
2. Who’s working on a disruptive circadian schedule
3. How many patients has the doc seen *on the current shift*
1. Who’s working an overnight shift (in our data + external validation in MIMIC)
2. Who’s working on a disruptive circadian schedule
3. How many patients has the doc seen *on the current shift*
Reposted by Haokun Liu
🚨 New paper alert 🚨
Ever asked an LLM-as-Marilyn Monroe who the US president was in 2000? 🤔 Should the LLM answer at all? We call these clashes Concept Incongruence. Read on! ⬇️
1/n 🧵
Ever asked an LLM-as-Marilyn Monroe who the US president was in 2000? 🤔 Should the LLM answer at all? We call these clashes Concept Incongruence. Read on! ⬇️
1/n 🧵

May 27, 2025 at 1:59 PM
🚨 New paper alert 🚨
Ever asked an LLM-as-Marilyn Monroe who the US president was in 2000? 🤔 Should the LLM answer at all? We call these clashes Concept Incongruence. Read on! ⬇️
1/n 🧵
Ever asked an LLM-as-Marilyn Monroe who the US president was in 2000? 🤔 Should the LLM answer at all? We call these clashes Concept Incongruence. Read on! ⬇️
1/n 🧵
Reposted by Haokun Liu

1/n 🚀🚀🚀 Thrilled to share our latest work🔥: HypoEval - Hypothesis-Guided Evaluation for Natural Language Generation! 🧠💬📊
There’s a lot of excitement around using LLMs for automated evaluation, but many methods fall short on alignment or explainability — let’s dive in! 🌊
There’s a lot of excitement around using LLMs for automated evaluation, but many methods fall short on alignment or explainability — let’s dive in! 🌊
May 12, 2025 at 7:23 PM
1/n 🚀🚀🚀 Thrilled to share our latest work🔥: HypoEval - Hypothesis-Guided Evaluation for Natural Language Generation! 🧠💬📊
There’s a lot of excitement around using LLMs for automated evaluation, but many methods fall short on alignment or explainability — let’s dive in! 🌊
There’s a lot of excitement around using LLMs for automated evaluation, but many methods fall short on alignment or explainability — let’s dive in! 🌊
Reposted by Haokun Liu

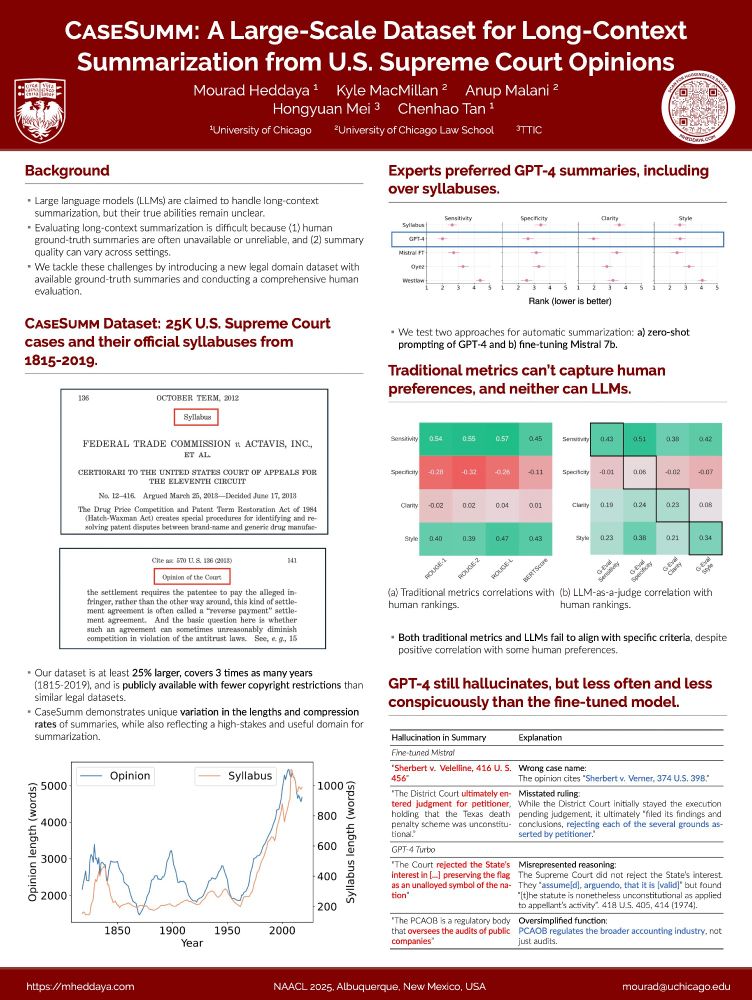
🧑⚖️How well can LLMs summarize complex legal documents? And can we use LLMs to evaluate?
Excited to be in Albuquerque presenting our paper this afternoon at @naaclmeeting 2025!
Excited to be in Albuquerque presenting our paper this afternoon at @naaclmeeting 2025!

May 1, 2025 at 7:25 PM
🧑⚖️How well can LLMs summarize complex legal documents? And can we use LLMs to evaluate?
Excited to be in Albuquerque presenting our paper this afternoon at @naaclmeeting 2025!
Excited to be in Albuquerque presenting our paper this afternoon at @naaclmeeting 2025!
Reposted by Haokun Liu
Although I cannot make #NAACL2025, @chicagohai.bsky.social will be there. Please say hi!
@chachachen.bsky.social GPT ❌ x-rays (Friday 9-10:30)
@mheddaya.bsky.social CaseSumm and LLM 🧑⚖️ (Thursday 2-3:30)
@haokunliu.bsky.social @qiaoyu-rosa.bsky.social hypothesis generation 🔬 (Saturday at 4pm)
@chachachen.bsky.social GPT ❌ x-rays (Friday 9-10:30)
@mheddaya.bsky.social CaseSumm and LLM 🧑⚖️ (Thursday 2-3:30)
@haokunliu.bsky.social @qiaoyu-rosa.bsky.social hypothesis generation 🔬 (Saturday at 4pm)

April 30, 2025 at 8:19 PM
Although I cannot make #NAACL2025, @chicagohai.bsky.social will be there. Please say hi!
@chachachen.bsky.social GPT ❌ x-rays (Friday 9-10:30)
@mheddaya.bsky.social CaseSumm and LLM 🧑⚖️ (Thursday 2-3:30)
@haokunliu.bsky.social @qiaoyu-rosa.bsky.social hypothesis generation 🔬 (Saturday at 4pm)
@chachachen.bsky.social GPT ❌ x-rays (Friday 9-10:30)
@mheddaya.bsky.social CaseSumm and LLM 🧑⚖️ (Thursday 2-3:30)
@haokunliu.bsky.social @qiaoyu-rosa.bsky.social hypothesis generation 🔬 (Saturday at 4pm)
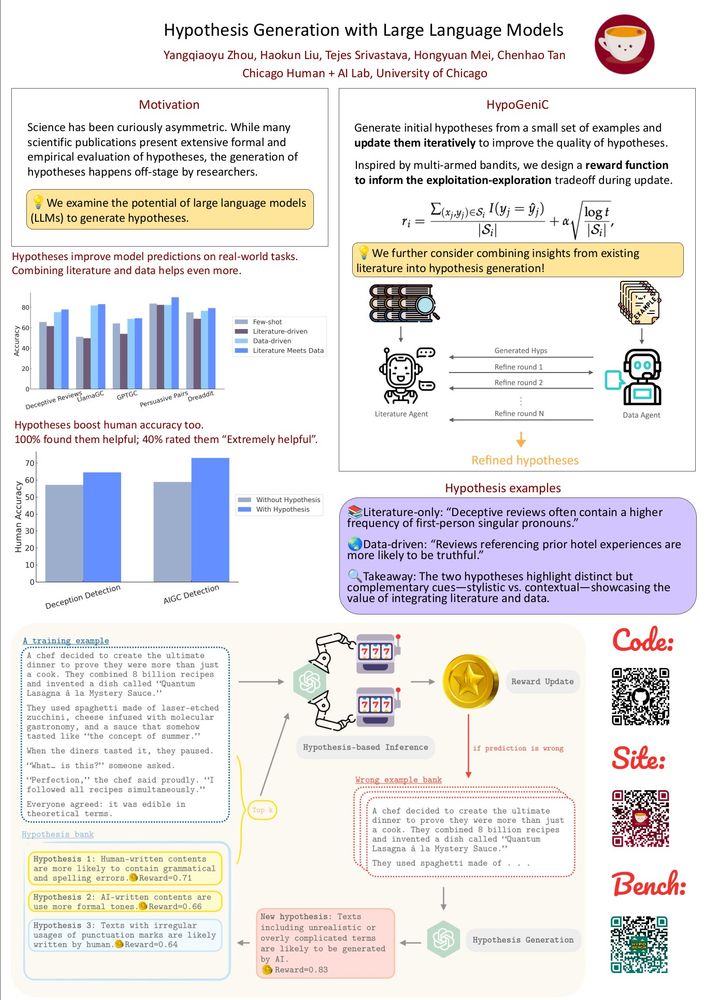
🚀🚀🚀Excited to share our latest work: HypoBench, a systematic benchmark for evaluating LLM-based hypothesis generation methods!
There is much excitement about leveraging LLMs for scientific hypothesis generation, but principled evaluations are missing - let’s dive into HypoBench together.
There is much excitement about leveraging LLMs for scientific hypothesis generation, but principled evaluations are missing - let’s dive into HypoBench together.

April 28, 2025 at 7:35 PM
🚀🚀🚀Excited to share our latest work: HypoBench, a systematic benchmark for evaluating LLM-based hypothesis generation methods!
There is much excitement about leveraging LLMs for scientific hypothesis generation, but principled evaluations are missing - let’s dive into HypoBench together.
There is much excitement about leveraging LLMs for scientific hypothesis generation, but principled evaluations are missing - let’s dive into HypoBench together.
Reposted by Haokun Liu
Encourage your students to submit posters and register! Limited free housing is provided for student participants only, on a first-come (i.e., request)-first-serve basis.
We are also actively looking for sponsors. Reach out if you are interested!
Please repost! Help spread the words!
We are also actively looking for sponsors. Reach out if you are interested!
Please repost! Help spread the words!
The Midwest Machine Learning Symposium will happen in Chicago on June 23-4 on the University of Chicago campus (midwest-ml.org/2025/). We have an amazing lineup of speakers:@profsanjeevarora.bsky.social from Princeton, Heng Ji from UIUC, Tuomas Sandholm from CMU, @ravenben.bsky.social from UChicago.

April 21, 2025 at 3:12 PM
Encourage your students to submit posters and register! Limited free housing is provided for student participants only, on a first-come (i.e., request)-first-serve basis.
We are also actively looking for sponsors. Reach out if you are interested!
Please repost! Help spread the words!
We are also actively looking for sponsors. Reach out if you are interested!
Please repost! Help spread the words!
Reposted by Haokun Liu

1/n
You may know that large language models (LLMs) can be biased in their decision-making, but ever wondered how those biases are encoded internally and whether we can surgically remove them?
You may know that large language models (LLMs) can be biased in their decision-making, but ever wondered how those biases are encoded internally and whether we can surgically remove them?
April 14, 2025 at 7:55 PM
1/n
You may know that large language models (LLMs) can be biased in their decision-making, but ever wondered how those biases are encoded internally and whether we can surgically remove them?
You may know that large language models (LLMs) can be biased in their decision-making, but ever wondered how those biases are encoded internally and whether we can surgically remove them?
Reposted by Haokun Liu

New preprint!
Metaphors shape how people understand politics, but measuring them (& their real-world effects) is hard.
We develop a new method to measure metaphor & use it to study dehumanizing metaphor in 400K immigration tweets Link: bit.ly/4i3PGm3
#NLP #NLProc #polisky #polcom #compsocialsci
🐦🐦
Metaphors shape how people understand politics, but measuring them (& their real-world effects) is hard.
We develop a new method to measure metaphor & use it to study dehumanizing metaphor in 400K immigration tweets Link: bit.ly/4i3PGm3
#NLP #NLProc #polisky #polcom #compsocialsci
🐦🐦

February 20, 2025 at 7:59 PM
New preprint!
Metaphors shape how people understand politics, but measuring them (& their real-world effects) is hard.
We develop a new method to measure metaphor & use it to study dehumanizing metaphor in 400K immigration tweets Link: bit.ly/4i3PGm3
#NLP #NLProc #polisky #polcom #compsocialsci
🐦🐦
Metaphors shape how people understand politics, but measuring them (& their real-world effects) is hard.
We develop a new method to measure metaphor & use it to study dehumanizing metaphor in 400K immigration tweets Link: bit.ly/4i3PGm3
#NLP #NLProc #polisky #polcom #compsocialsci
🐦🐦
Reposted by Haokun Liu
Spent a great day at Boulder meeting new students and old colleagues. I used to take this view every day.
Here are the slides for my talk titled "Alignment Beyond Human Preferences: Use Human Goals to Guide AI towards Complementary AI": chenhaot.com/talks/alignm...
Here are the slides for my talk titled "Alignment Beyond Human Preferences: Use Human Goals to Guide AI towards Complementary AI": chenhaot.com/talks/alignm...



January 24, 2025 at 3:01 PM
Spent a great day at Boulder meeting new students and old colleagues. I used to take this view every day.
Here are the slides for my talk titled "Alignment Beyond Human Preferences: Use Human Goals to Guide AI towards Complementary AI": chenhaot.com/talks/alignm...
Here are the slides for my talk titled "Alignment Beyond Human Preferences: Use Human Goals to Guide AI towards Complementary AI": chenhaot.com/talks/alignm...
💡Check out our project website for our latest paper! Learn about a new approach to hypothesis generation:
👉 chicagohai.github.io/hypogenic-de...
👉 chicagohai.github.io/hypogenic-de...



November 22, 2024 at 2:29 PM
💡Check out our project website for our latest paper! Learn about a new approach to hypothesis generation:
👉 chicagohai.github.io/hypogenic-de...
👉 chicagohai.github.io/hypogenic-de...
Check out this podcast for our paper: youtu.be/q7Vrvpc1cPQ?si…
(Powered by NotebookLM)
(Powered by NotebookLM)
November 16, 2024 at 12:13 AM
Check out this podcast for our paper: youtu.be/q7Vrvpc1cPQ?si…
(Powered by NotebookLM)
(Powered by NotebookLM)
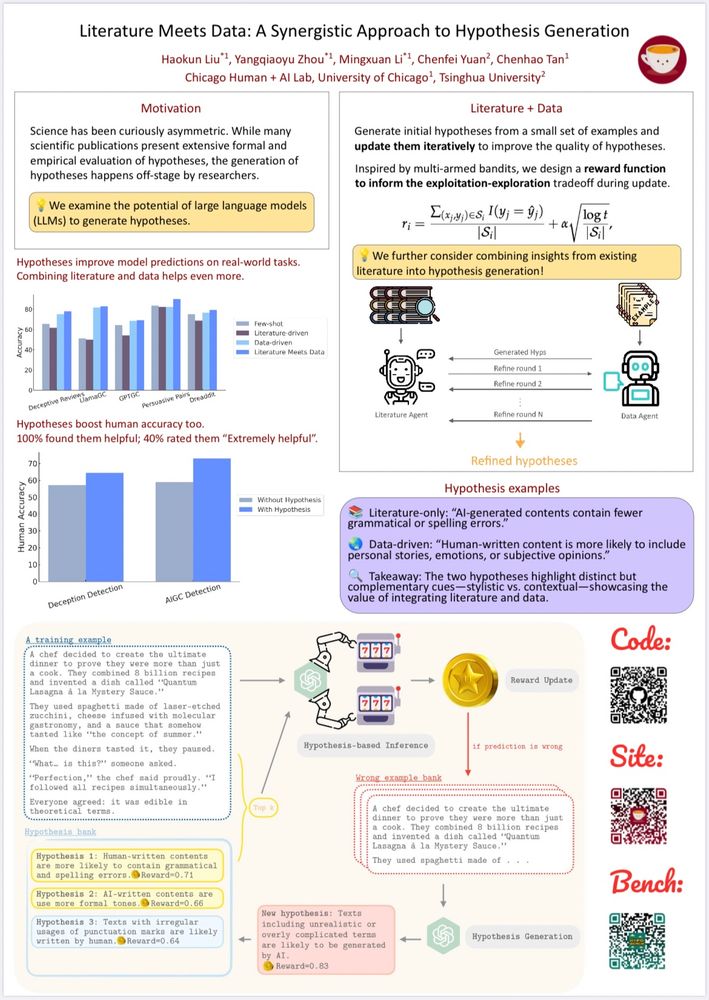
1/ 🚀 New Paper Alert!
Excited to share: Literature Meets Data: A Synergistic Approach to Hypothesis Generation 📚📊!
We propose a novel framework combining literature insights & observational data with LLMs for hypothesis generation. Here’s how and why it matters.
Excited to share: Literature Meets Data: A Synergistic Approach to Hypothesis Generation 📚📊!
We propose a novel framework combining literature insights & observational data with LLMs for hypothesis generation. Here’s how and why it matters.
November 14, 2024 at 8:30 PM
1/ 🚀 New Paper Alert!
Excited to share: Literature Meets Data: A Synergistic Approach to Hypothesis Generation 📚📊!
We propose a novel framework combining literature insights & observational data with LLMs for hypothesis generation. Here’s how and why it matters.
Excited to share: Literature Meets Data: A Synergistic Approach to Hypothesis Generation 📚📊!
We propose a novel framework combining literature insights & observational data with LLMs for hypothesis generation. Here’s how and why it matters.