



Kanishk Gandhi
@gandhikanishk.bsky.social
PhD Student Stanford w/ Noah Goodman, studying reasoning, discovery, and interaction. Trying to build machines that understand people.
StanfordNLP, Stanford AI Lab
StanfordNLP, Stanford AI Lab
8/13 By curating an extended pretraining set to amplify them, we enable Llama to match Qwen's improvement.

March 4, 2025 at 6:15 PM
8/13 By curating an extended pretraining set to amplify them, we enable Llama to match Qwen's improvement.
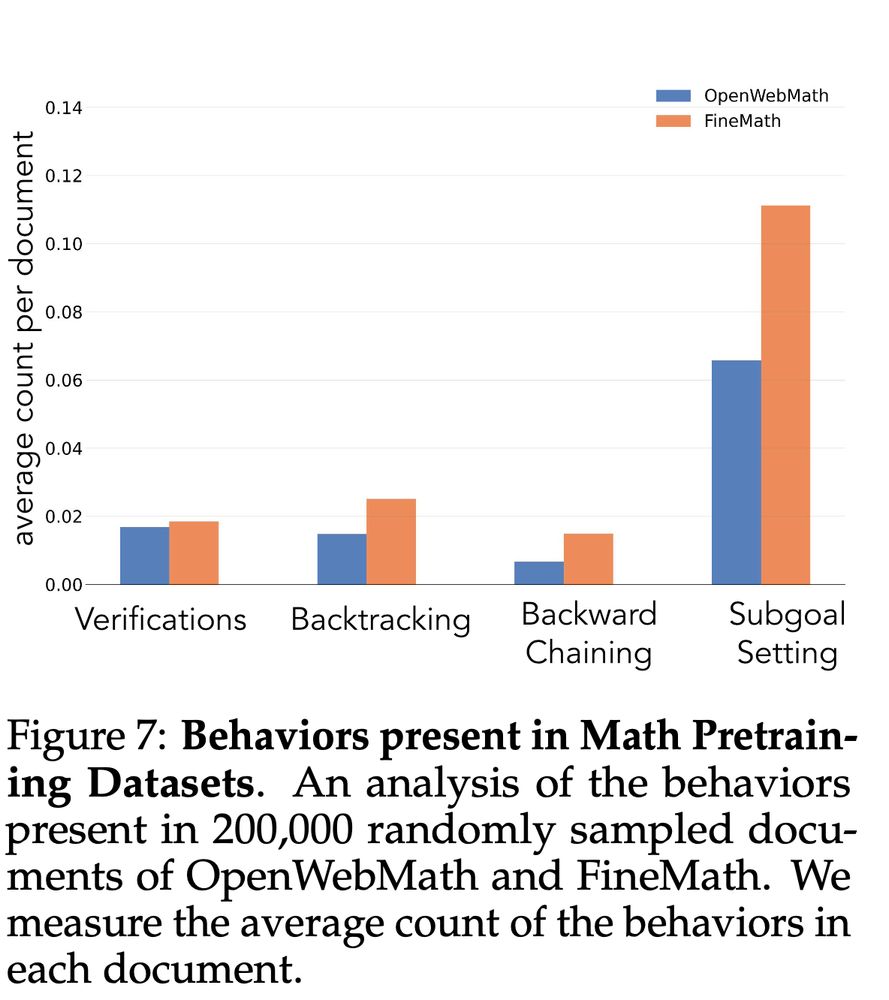
7/13 Can we apply these insights to pretraining? We analyze math pretraining sets like OpenWebMath & FineMath, finding these key behaviors are quite rare.
March 4, 2025 at 6:15 PM
7/13 Can we apply these insights to pretraining? We analyze math pretraining sets like OpenWebMath & FineMath, finding these key behaviors are quite rare.
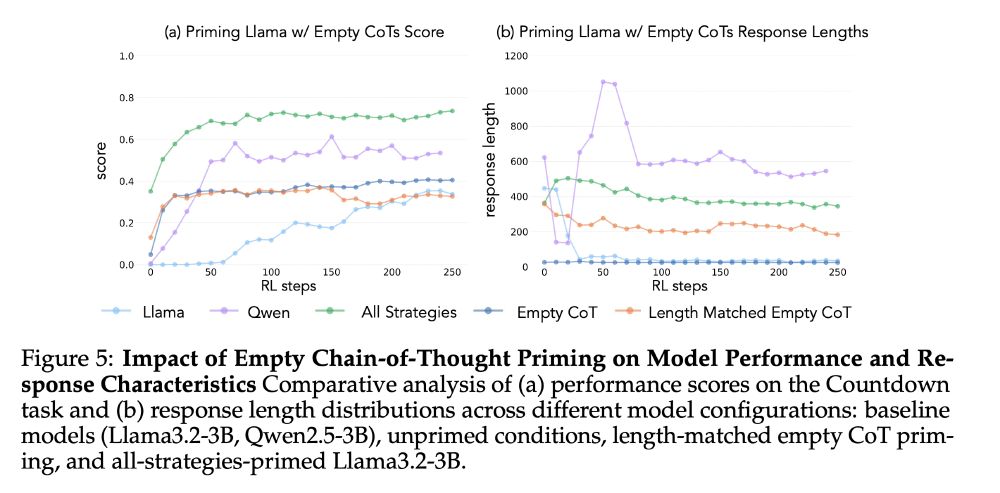
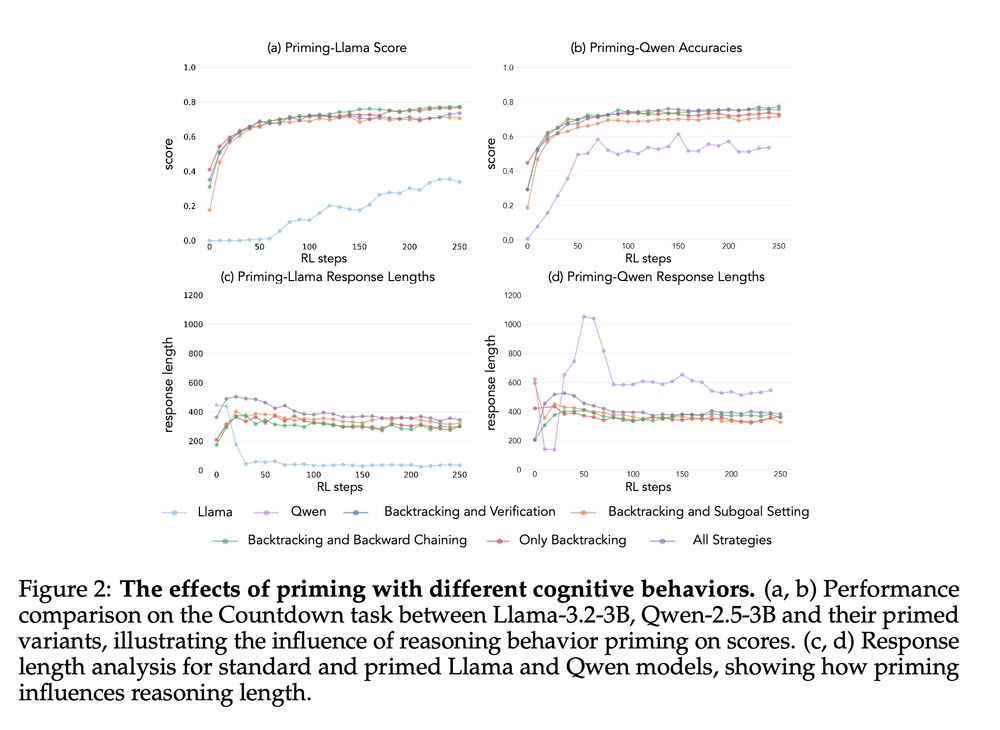
6/13 Empty and length matched empty chain-of-thought priming fails to produce improvement, reverting models to baseline performance. This shows it's the specific cognitive behaviors, not just longer outputs, enabling learning.
March 4, 2025 at 6:15 PM
6/13 Empty and length matched empty chain-of-thought priming fails to produce improvement, reverting models to baseline performance. This shows it's the specific cognitive behaviors, not just longer outputs, enabling learning.
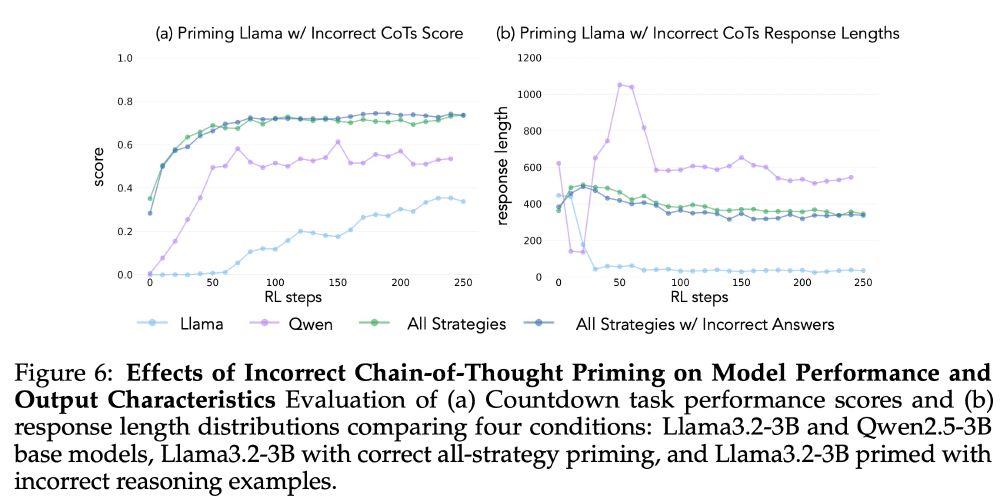
5/13 Crucially, the reasoning patterns matter more than having correct answers. Models primed with incorrect solutions that demonstrate the right cognitive behaviors still show substantial improvement. The behaviors are key.
March 4, 2025 at 6:15 PM
5/13 Crucially, the reasoning patterns matter more than having correct answers. Models primed with incorrect solutions that demonstrate the right cognitive behaviors still show substantial improvement. The behaviors are key.
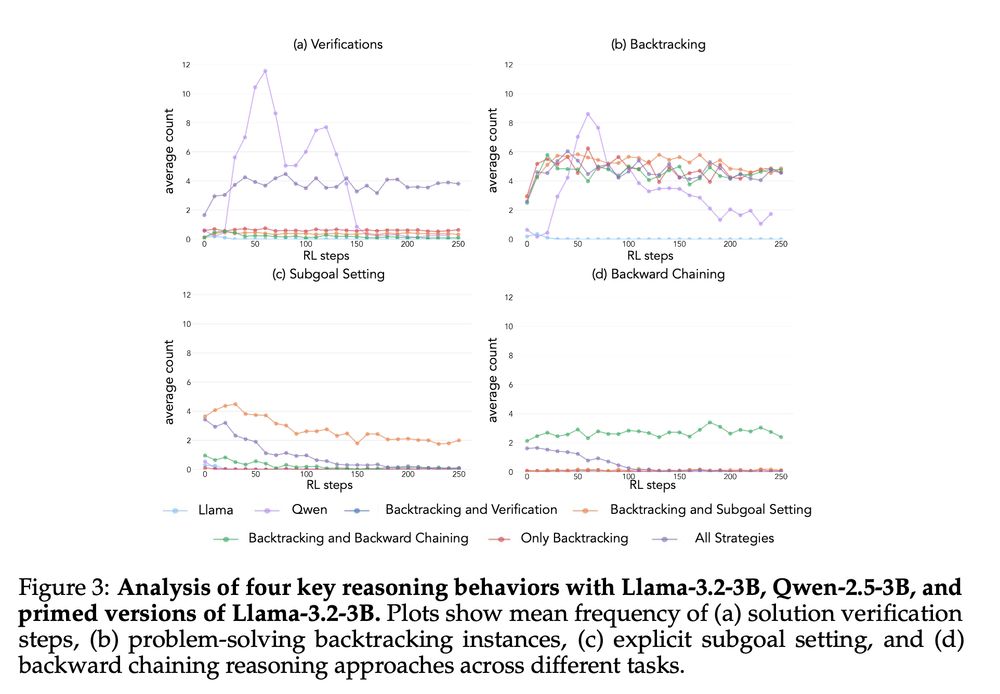
4/13 We curate priming datasets with different behavior combinations and find that models primed with backtracking and verification consistently improve. Interestingly, RL selectively amplifies the most useful behaviors for reaching the goal.
March 4, 2025 at 6:15 PM
4/13 We curate priming datasets with different behavior combinations and find that models primed with backtracking and verification consistently improve. Interestingly, RL selectively amplifies the most useful behaviors for reaching the goal.
3/13 Can we change a model's initial properties to enable improvement? Yes! After "priming" Llama, by finetuning on examples demonstrating these behaviors, it starts improving from RL just like Qwen. The priming jumpstarts the learning process.
March 4, 2025 at 6:15 PM
3/13 Can we change a model's initial properties to enable improvement? Yes! After "priming" Llama, by finetuning on examples demonstrating these behaviors, it starts improving from RL just like Qwen. The priming jumpstarts the learning process.
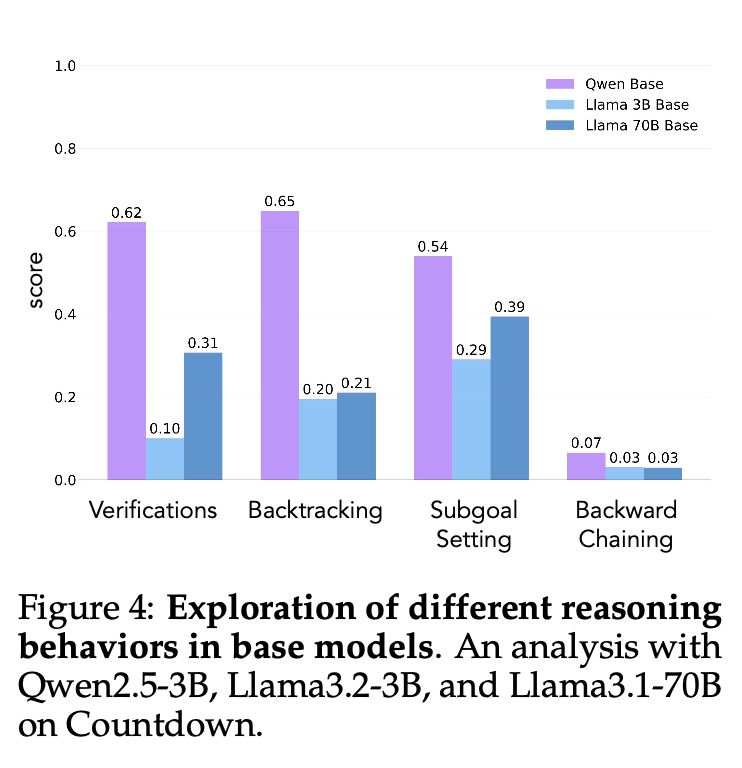
2/13 We identify 4 key cognitive behaviors that enable successful learning: Verification (checking work), Backtracking (trying new approaches), Subgoal Setting (breaking problems down) & Backward Chaining (working backwards from a goal). Qwen naturally exhibits these, while Llama mostly lacks them.
March 4, 2025 at 6:15 PM
2/13 We identify 4 key cognitive behaviors that enable successful learning: Verification (checking work), Backtracking (trying new approaches), Subgoal Setting (breaking problems down) & Backward Chaining (working backwards from a goal). Qwen naturally exhibits these, while Llama mostly lacks them.
1/13 New Paper!! We try to understand why some LMs self-improve their reasoning while others hit a wall. The key? Cognitive behaviors! Read our paper on how the right cognitive behaviors can make all the difference in a model's ability to improve with RL! 🧵

March 4, 2025 at 6:15 PM
1/13 New Paper!! We try to understand why some LMs self-improve their reasoning while others hit a wall. The key? Cognitive behaviors! Read our paper on how the right cognitive behaviors can make all the difference in a model's ability to improve with RL! 🧵