



Fabian Schneider
@fabianschneider.bsky.social
Doctoral researcher. Interested in memory, audition, semantics, predictive coding, spiking networks.
Cool! May I join?
August 1, 2025 at 3:17 PM
Cool! May I join?
Thanks Peter!! :-)
For anyone looking for a brief summary, here's a quick tour of our key findings: bsky.app/profile/fabi...
For anyone looking for a brief summary, here's a quick tour of our key findings: bsky.app/profile/fabi...
🚨 Fresh preprint w/ @helenblank.bsky.social!
How does the brain acquire expectations about a conversational partner, and how are priors integrated w/ sensory inputs?
Current evidence diverges. Is it prediction error? Sharpening?
Spoiler: It's both.👀
🧵1/16
www.biorxiv.org/content/10.1...
How does the brain acquire expectations about a conversational partner, and how are priors integrated w/ sensory inputs?
Current evidence diverges. Is it prediction error? Sharpening?
Spoiler: It's both.👀
🧵1/16
www.biorxiv.org/content/10.1...

August 1, 2025 at 11:32 AM
Thanks Peter!! :-)
For anyone looking for a brief summary, here's a quick tour of our key findings: bsky.app/profile/fabi...
For anyone looking for a brief summary, here's a quick tour of our key findings: bsky.app/profile/fabi...
🧵16/16
More results, details and discussion in the full preprint: www.biorxiv.org/content/10.1...
Huge thanks to Helen Blank, the Predictive Cognition Lab, and colleagues @isnlab.bsky.social.
Happy to discuss here, via email or in person! Make sure to catch us at CCN if you're around. 🥳
More results, details and discussion in the full preprint: www.biorxiv.org/content/10.1...
Huge thanks to Helen Blank, the Predictive Cognition Lab, and colleagues @isnlab.bsky.social.
Happy to discuss here, via email or in person! Make sure to catch us at CCN if you're around. 🥳

Sensory sharpening and semantic prediction errors unify competing models of predictive processing in communication
The human brain makes abundant predictions in speech comprehension that, in real-world conversations, depend on conversational partners. Yet, models diverge on how such predictions are integrated with...
www.biorxiv.org
August 1, 2025 at 11:24 AM
🧵16/16
More results, details and discussion in the full preprint: www.biorxiv.org/content/10.1...
Huge thanks to Helen Blank, the Predictive Cognition Lab, and colleagues @isnlab.bsky.social.
Happy to discuss here, via email or in person! Make sure to catch us at CCN if you're around. 🥳
More results, details and discussion in the full preprint: www.biorxiv.org/content/10.1...
Huge thanks to Helen Blank, the Predictive Cognition Lab, and colleagues @isnlab.bsky.social.
Happy to discuss here, via email or in person! Make sure to catch us at CCN if you're around. 🥳
🧵15/16
3. Prediction errors are not computed indiscriminately and appear to be gated by likelihood, potentially underlying robust updates to world models (where extreme prediction errors might otherwise lead to deleterious model updates).
3. Prediction errors are not computed indiscriminately and appear to be gated by likelihood, potentially underlying robust updates to world models (where extreme prediction errors might otherwise lead to deleterious model updates).
August 1, 2025 at 11:24 AM
🧵15/16
3. Prediction errors are not computed indiscriminately and appear to be gated by likelihood, potentially underlying robust updates to world models (where extreme prediction errors might otherwise lead to deleterious model updates).
3. Prediction errors are not computed indiscriminately and appear to be gated by likelihood, potentially underlying robust updates to world models (where extreme prediction errors might otherwise lead to deleterious model updates).
🧵14/16
2. Priors sharpen representations at the sensory level, and produce high-level prediction errors.
While this contradicts traditional predictive coding, it aligns well with recent views by @clarepress.bsky.social, @peterkok.bsky.social, @danieljamesyon.bsky.social: doi.org/10.1016/j.ti...
2. Priors sharpen representations at the sensory level, and produce high-level prediction errors.
While this contradicts traditional predictive coding, it aligns well with recent views by @clarepress.bsky.social, @peterkok.bsky.social, @danieljamesyon.bsky.social: doi.org/10.1016/j.ti...
Redirecting
doi.org
August 1, 2025 at 11:24 AM
🧵14/16
2. Priors sharpen representations at the sensory level, and produce high-level prediction errors.
While this contradicts traditional predictive coding, it aligns well with recent views by @clarepress.bsky.social, @peterkok.bsky.social, @danieljamesyon.bsky.social: doi.org/10.1016/j.ti...
2. Priors sharpen representations at the sensory level, and produce high-level prediction errors.
While this contradicts traditional predictive coding, it aligns well with recent views by @clarepress.bsky.social, @peterkok.bsky.social, @danieljamesyon.bsky.social: doi.org/10.1016/j.ti...
🧵13/16
So what are the key takeaways?
1. Listeners apply speaker-specific semantic priors in speech comprehension.
This extends previous findings showing speaker-specific adaptations at the phonetic, phonemic and lexical levels.
So what are the key takeaways?
1. Listeners apply speaker-specific semantic priors in speech comprehension.
This extends previous findings showing speaker-specific adaptations at the phonetic, phonemic and lexical levels.
August 1, 2025 at 11:24 AM
🧵13/16
So what are the key takeaways?
1. Listeners apply speaker-specific semantic priors in speech comprehension.
This extends previous findings showing speaker-specific adaptations at the phonetic, phonemic and lexical levels.
So what are the key takeaways?
1. Listeners apply speaker-specific semantic priors in speech comprehension.
This extends previous findings showing speaker-specific adaptations at the phonetic, phonemic and lexical levels.
🧵12/16
In fact, neurally we find a double dissociation between type of prior and congruency: Semantic prediction errors are apparent relative to speaker-invariant priors IFF word is highly unlikely given speaker prior, but emerge relative to speaker-specific priors otherwise!
In fact, neurally we find a double dissociation between type of prior and congruency: Semantic prediction errors are apparent relative to speaker-invariant priors IFF word is highly unlikely given speaker prior, but emerge relative to speaker-specific priors otherwise!

August 1, 2025 at 11:24 AM
🧵12/16
In fact, neurally we find a double dissociation between type of prior and congruency: Semantic prediction errors are apparent relative to speaker-invariant priors IFF word is highly unlikely given speaker prior, but emerge relative to speaker-specific priors otherwise!
In fact, neurally we find a double dissociation between type of prior and congruency: Semantic prediction errors are apparent relative to speaker-invariant priors IFF word is highly unlikely given speaker prior, but emerge relative to speaker-specific priors otherwise!
🧵11/16
Interestingly, participants take longer to respond to words incongruent with the speaker, but response times are a function of word probability given the speaker only for congruent words. This may also suggest some kind of gating, incurring a switch cost!
Interestingly, participants take longer to respond to words incongruent with the speaker, but response times are a function of word probability given the speaker only for congruent words. This may also suggest some kind of gating, incurring a switch cost!

August 1, 2025 at 11:24 AM
🧵11/16
Interestingly, participants take longer to respond to words incongruent with the speaker, but response times are a function of word probability given the speaker only for congruent words. This may also suggest some kind of gating, incurring a switch cost!
Interestingly, participants take longer to respond to words incongruent with the speaker, but response times are a function of word probability given the speaker only for congruent words. This may also suggest some kind of gating, incurring a switch cost!
🧵10/16
So is there some process gating which semantic prediction errors are computed?
In real time, we sample particularly congruent and incongruent exemplars of a speaker for each subject. We present unmorphed but degraded words and ask for word identification.
So is there some process gating which semantic prediction errors are computed?
In real time, we sample particularly congruent and incongruent exemplars of a speaker for each subject. We present unmorphed but degraded words and ask for word identification.

August 1, 2025 at 11:24 AM
🧵10/16
So is there some process gating which semantic prediction errors are computed?
In real time, we sample particularly congruent and incongruent exemplars of a speaker for each subject. We present unmorphed but degraded words and ask for word identification.
So is there some process gating which semantic prediction errors are computed?
In real time, we sample particularly congruent and incongruent exemplars of a speaker for each subject. We present unmorphed but degraded words and ask for word identification.
🧵9/16
Conversely, here we find that only speaker-specific semantic surprisal improves encoding performance. Explained variance clusters across all sensors between 150-630ms, consistent with prediction errors at higher levels of the processing hierarchy such as semantics!
Conversely, here we find that only speaker-specific semantic surprisal improves encoding performance. Explained variance clusters across all sensors between 150-630ms, consistent with prediction errors at higher levels of the processing hierarchy such as semantics!
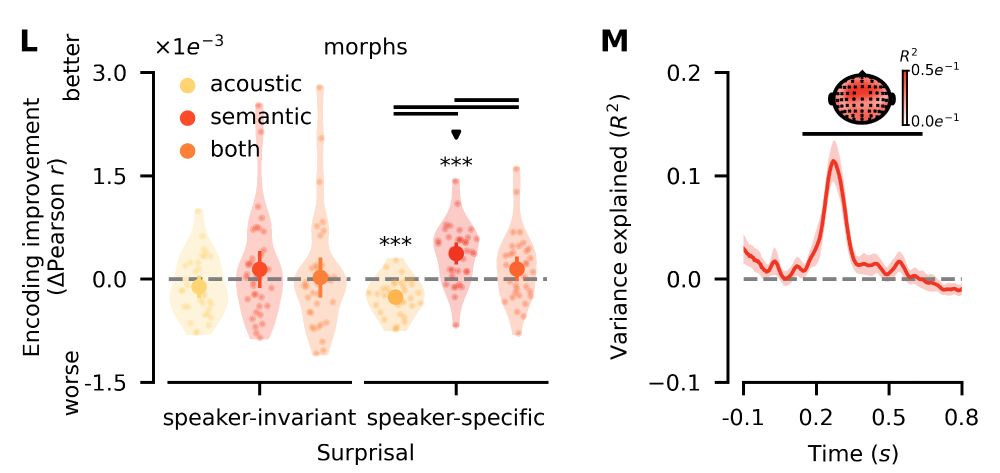
August 1, 2025 at 11:24 AM
🧵9/16
Conversely, here we find that only speaker-specific semantic surprisal improves encoding performance. Explained variance clusters across all sensors between 150-630ms, consistent with prediction errors at higher levels of the processing hierarchy such as semantics!
Conversely, here we find that only speaker-specific semantic surprisal improves encoding performance. Explained variance clusters across all sensors between 150-630ms, consistent with prediction errors at higher levels of the processing hierarchy such as semantics!
🧵8/16
What about high-level representations? Let's zoom out to the broadband EEG response.
To test for information theoretic measures, we encode single-trial responses from acoustic/semantic surprisal, controlling for general linguistic confounds (in part through LLMs).
What about high-level representations? Let's zoom out to the broadband EEG response.
To test for information theoretic measures, we encode single-trial responses from acoustic/semantic surprisal, controlling for general linguistic confounds (in part through LLMs).

August 1, 2025 at 11:24 AM
🧵8/16
What about high-level representations? Let's zoom out to the broadband EEG response.
To test for information theoretic measures, we encode single-trial responses from acoustic/semantic surprisal, controlling for general linguistic confounds (in part through LLMs).
What about high-level representations? Let's zoom out to the broadband EEG response.
To test for information theoretic measures, we encode single-trial responses from acoustic/semantic surprisal, controlling for general linguistic confounds (in part through LLMs).
🧵7/16
How are they altered? Our RSMs naturally represent expected information. Due to their geometry, a sign flip inverts the pattern to represent unexpected information.
Coefficients show clear evidence of sharpening at the sensory level, pulling reps. towards predictions!
How are they altered? Our RSMs naturally represent expected information. Due to their geometry, a sign flip inverts the pattern to represent unexpected information.
Coefficients show clear evidence of sharpening at the sensory level, pulling reps. towards predictions!

August 1, 2025 at 11:24 AM
🧵7/16
How are they altered? Our RSMs naturally represent expected information. Due to their geometry, a sign flip inverts the pattern to represent unexpected information.
Coefficients show clear evidence of sharpening at the sensory level, pulling reps. towards predictions!
How are they altered? Our RSMs naturally represent expected information. Due to their geometry, a sign flip inverts the pattern to represent unexpected information.
Coefficients show clear evidence of sharpening at the sensory level, pulling reps. towards predictions!
🧵6/16
We find that similarity structure of sensory representations is best explained by combining speaker-invariant and -specific acoustic predictions. Critically, purely semantic predictions do not help.
Semantic predictions alter sensory representations at the acoustic level!
We find that similarity structure of sensory representations is best explained by combining speaker-invariant and -specific acoustic predictions. Critically, purely semantic predictions do not help.
Semantic predictions alter sensory representations at the acoustic level!

August 1, 2025 at 11:24 AM
🧵6/16
We find that similarity structure of sensory representations is best explained by combining speaker-invariant and -specific acoustic predictions. Critically, purely semantic predictions do not help.
Semantic predictions alter sensory representations at the acoustic level!
We find that similarity structure of sensory representations is best explained by combining speaker-invariant and -specific acoustic predictions. Critically, purely semantic predictions do not help.
Semantic predictions alter sensory representations at the acoustic level!
🧵5/16
We compute similarity between reconstructions for both speakers and original words from morph creation. We encode observed sensory RSMs from speaker-invariant and -specific acoustic and semantic predictions, controlling for raw acoustics and general linguistic predictions.
We compute similarity between reconstructions for both speakers and original words from morph creation. We encode observed sensory RSMs from speaker-invariant and -specific acoustic and semantic predictions, controlling for raw acoustics and general linguistic predictions.

August 1, 2025 at 11:24 AM
🧵5/16
We compute similarity between reconstructions for both speakers and original words from morph creation. We encode observed sensory RSMs from speaker-invariant and -specific acoustic and semantic predictions, controlling for raw acoustics and general linguistic predictions.
We compute similarity between reconstructions for both speakers and original words from morph creation. We encode observed sensory RSMs from speaker-invariant and -specific acoustic and semantic predictions, controlling for raw acoustics and general linguistic predictions.
🧵4/16
Let's zoom in on the sensory level: We train stimulus reconstruction models to decode auditory spectrograms from EEG recordings.
If predictions shape neural representations at the sensory level, we should find reconstructed representational content shifted by speakers.
Let's zoom in on the sensory level: We train stimulus reconstruction models to decode auditory spectrograms from EEG recordings.
If predictions shape neural representations at the sensory level, we should find reconstructed representational content shifted by speakers.

August 1, 2025 at 11:24 AM
🧵4/16
Let's zoom in on the sensory level: We train stimulus reconstruction models to decode auditory spectrograms from EEG recordings.
If predictions shape neural representations at the sensory level, we should find reconstructed representational content shifted by speakers.
Let's zoom in on the sensory level: We train stimulus reconstruction models to decode auditory spectrograms from EEG recordings.
If predictions shape neural representations at the sensory level, we should find reconstructed representational content shifted by speakers.
🧵3/16
Indeed, participants report hearing words as a function of semantic probability given the speaker, scaling with exposure.
But how? Predictive coding invokes prediction errors, but Bayesian inference requires sharpening. Does the brain represent un-/expected information?
Indeed, participants report hearing words as a function of semantic probability given the speaker, scaling with exposure.
But how? Predictive coding invokes prediction errors, but Bayesian inference requires sharpening. Does the brain represent un-/expected information?

August 1, 2025 at 11:24 AM
🧵3/16
Indeed, participants report hearing words as a function of semantic probability given the speaker, scaling with exposure.
But how? Predictive coding invokes prediction errors, but Bayesian inference requires sharpening. Does the brain represent un-/expected information?
Indeed, participants report hearing words as a function of semantic probability given the speaker, scaling with exposure.
But how? Predictive coding invokes prediction errors, but Bayesian inference requires sharpening. Does the brain represent un-/expected information?
🧵2/16
We played morphed audio files (e.g., sea/tea) and had participants report which of the two words they had heard. Critically, the same morphs were played in different speaker contexts, with speaker-specific feedback reinforcing robust speaker-specific semantic expectations.
We played morphed audio files (e.g., sea/tea) and had participants report which of the two words they had heard. Critically, the same morphs were played in different speaker contexts, with speaker-specific feedback reinforcing robust speaker-specific semantic expectations.

August 1, 2025 at 11:24 AM
🧵2/16
We played morphed audio files (e.g., sea/tea) and had participants report which of the two words they had heard. Critically, the same morphs were played in different speaker contexts, with speaker-specific feedback reinforcing robust speaker-specific semantic expectations.
We played morphed audio files (e.g., sea/tea) and had participants report which of the two words they had heard. Critically, the same morphs were played in different speaker contexts, with speaker-specific feedback reinforcing robust speaker-specific semantic expectations.