




Sebastian Dziadzio
@dziadzio.bsky.social
ELLIS PhD student in machine learning at IMPRS-IS. Continual learning at scale.
sebastiandziadzio.com
sebastiandziadzio.com
Yeah, mostly because GPT-5 needs to think for 20 seconds to come up with a name for a variable. It's good for bigger, self-contained features, but the bias for "reasoning" in the model router makes it downright unusable for smaller changes.
September 16, 2025 at 11:01 AM
Yeah, mostly because GPT-5 needs to think for 20 seconds to come up with a name for a variable. It's good for bigger, self-contained features, but the bias for "reasoning" in the model router makes it downright unusable for smaller changes.
Done! Sorry for the wait
May 15, 2025 at 1:37 PM
Done! Sorry for the wait

This has been a fun project with a great team: led by @vishaalurao.bsky.social and @confusezius.bsky.social, with core contributions from @bayesiankitten.bsky.social, and supervision by @zeynepakata.bsky.social, Samuel Albanie, and Matthias Bethge.
December 11, 2024 at 6:00 PM
This has been a fun project with a great team: led by @vishaalurao.bsky.social and @confusezius.bsky.social, with core contributions from @bayesiankitten.bsky.social, and supervision by @zeynepakata.bsky.social, Samuel Albanie, and Matthias Bethge.
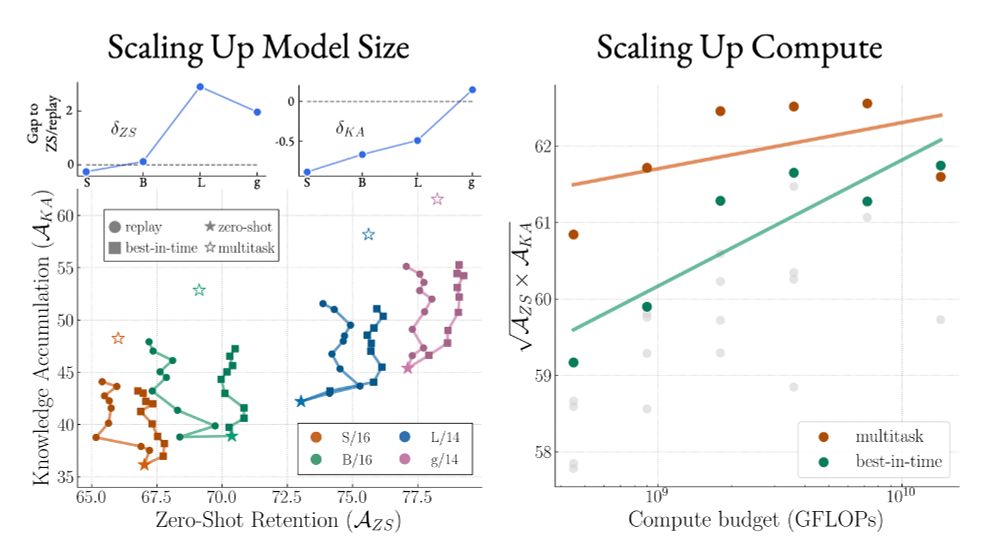
As usual, scaling matters!
🚀 Larger models benefit more from temporal merging than sequential finetuning.
🚀 Larger compute budgets allow temporal merging to match (and surpass!) multitask performance.
🚀 Best-in-TIME scales effectively across longer task sequences (50, 100).
🚀 Larger models benefit more from temporal merging than sequential finetuning.
🚀 Larger compute budgets allow temporal merging to match (and surpass!) multitask performance.
🚀 Best-in-TIME scales effectively across longer task sequences (50, 100).
December 11, 2024 at 6:00 PM
As usual, scaling matters!
🚀 Larger models benefit more from temporal merging than sequential finetuning.
🚀 Larger compute budgets allow temporal merging to match (and surpass!) multitask performance.
🚀 Best-in-TIME scales effectively across longer task sequences (50, 100).
🚀 Larger models benefit more from temporal merging than sequential finetuning.
🚀 Larger compute budgets allow temporal merging to match (and surpass!) multitask performance.
🚀 Best-in-TIME scales effectively across longer task sequences (50, 100).
📌 The choice of merging technique doesn’t matter much.
In the temporal setting, complex merging techniques like TIES or Breadcrumbs offer only marginal gains compared to simpler ones like weight averaging.
In the temporal setting, complex merging techniques like TIES or Breadcrumbs offer only marginal gains compared to simpler ones like weight averaging.

December 11, 2024 at 6:00 PM
📌 The choice of merging technique doesn’t matter much.
In the temporal setting, complex merging techniques like TIES or Breadcrumbs offer only marginal gains compared to simpler ones like weight averaging.
In the temporal setting, complex merging techniques like TIES or Breadcrumbs offer only marginal gains compared to simpler ones like weight averaging.
📌 Initialization and deployment choices are crucial.
One strategy stands out—using exponential moving average for both initialization and deployment strikes the best balance between knowledge accumulation and zero-shot retention. We call this approach ✨Best-in-TIME✨
One strategy stands out—using exponential moving average for both initialization and deployment strikes the best balance between knowledge accumulation and zero-shot retention. We call this approach ✨Best-in-TIME✨

December 11, 2024 at 6:00 PM
📌 Initialization and deployment choices are crucial.
One strategy stands out—using exponential moving average for both initialization and deployment strikes the best balance between knowledge accumulation and zero-shot retention. We call this approach ✨Best-in-TIME✨
One strategy stands out—using exponential moving average for both initialization and deployment strikes the best balance between knowledge accumulation and zero-shot retention. We call this approach ✨Best-in-TIME✨
📌 Accounting for time is essential.
Standard merging struggles with the temporal dynamics. Replay and weighting schemes, which factor in the sequential nature of the problem, help (but only to a point).
Standard merging struggles with the temporal dynamics. Replay and weighting schemes, which factor in the sequential nature of the problem, help (but only to a point).

December 11, 2024 at 6:00 PM
📌 Accounting for time is essential.
Standard merging struggles with the temporal dynamics. Replay and weighting schemes, which factor in the sequential nature of the problem, help (but only to a point).
Standard merging struggles with the temporal dynamics. Replay and weighting schemes, which factor in the sequential nature of the problem, help (but only to a point).
Key insights:
📌 Accounting for time is essential.
📌 Initialization and deployment choices are crucial.
📌 The choice of merging technique doesn’t matter much.
📌 Accounting for time is essential.
📌 Initialization and deployment choices are crucial.
📌 The choice of merging technique doesn’t matter much.
December 11, 2024 at 6:00 PM
Key insights:
📌 Accounting for time is essential.
📌 Initialization and deployment choices are crucial.
📌 The choice of merging technique doesn’t matter much.
📌 Accounting for time is essential.
📌 Initialization and deployment choices are crucial.
📌 The choice of merging technique doesn’t matter much.
The world keeps changing, and so should our models.
Enter TIME (Temporal Integration of Model Expertise), a unifying approach that considers:
1️⃣ Initialization
2️⃣ Deployment
3️⃣ Merging Techniques
We study these three axes on the large FoMo-in-Flux benchmark.
Enter TIME (Temporal Integration of Model Expertise), a unifying approach that considers:
1️⃣ Initialization
2️⃣ Deployment
3️⃣ Merging Techniques
We study these three axes on the large FoMo-in-Flux benchmark.

December 11, 2024 at 6:00 PM
The world keeps changing, and so should our models.
Enter TIME (Temporal Integration of Model Expertise), a unifying approach that considers:
1️⃣ Initialization
2️⃣ Deployment
3️⃣ Merging Techniques
We study these three axes on the large FoMo-in-Flux benchmark.
Enter TIME (Temporal Integration of Model Expertise), a unifying approach that considers:
1️⃣ Initialization
2️⃣ Deployment
3️⃣ Merging Techniques
We study these three axes on the large FoMo-in-Flux benchmark.
I keep forgetting about the concert, yesterday I was like 'wow people in Vancouver sure love sequins and cowboy boots'.
December 9, 2024 at 2:18 AM
I keep forgetting about the concert, yesterday I was like 'wow people in Vancouver sure love sequins and cowboy boots'.
Whenever my "papers" tab group got lost in a chrome crash I felt nothing but relief.
The firehose is relentless, so over time my strategy became to skim in the moment if interesting and save to zotero, otherwise close the tab. There is only the present. Important stuff will come back.
The firehose is relentless, so over time my strategy became to skim in the moment if interesting and save to zotero, otherwise close the tab. There is only the present. Important stuff will come back.
November 30, 2024 at 1:19 PM
Whenever my "papers" tab group got lost in a chrome crash I felt nothing but relief.
The firehose is relentless, so over time my strategy became to skim in the moment if interesting and save to zotero, otherwise close the tab. There is only the present. Important stuff will come back.
The firehose is relentless, so over time my strategy became to skim in the moment if interesting and save to zotero, otherwise close the tab. There is only the present. Important stuff will come back.
Yeah, I think we consistently underestimate how much stuff is out there on the Internet. You might think your question or image prompt is niche and original, but if you consider the distribution of Internet-scale datasets, you'd have to work very hard to even reach the tail.
November 30, 2024 at 12:59 PM
Yeah, I think we consistently underestimate how much stuff is out there on the Internet. You might think your question or image prompt is niche and original, but if you consider the distribution of Internet-scale datasets, you'd have to work very hard to even reach the tail.
If someone said "the algorithm" with no additional context, I'd think of the latter, but "an algorithm" for me is still the former. Interesting how the default meaning is shifting.
November 30, 2024 at 12:42 PM
If someone said "the algorithm" with no additional context, I'd think of the latter, but "an algorithm" for me is still the former. Interesting how the default meaning is shifting.
Have you read Fables for Robots? I think it was only published in English as part of Mortal Engines. If you liked Cyberiad, you'll like this one too!
November 29, 2024 at 10:27 AM
Have you read Fables for Robots? I think it was only published in English as part of Mortal Engines. If you liked Cyberiad, you'll like this one too!