



@docxavi.bsky.social
Reposted

Le monde reports that on March 9th a French scientist heading for a conference was denied entry to the US. His computer and cellphone were searched, and messages to friends were found where he expressed his opinion on the Trump admin and their politics wrt to science.
www.lemonde.fr/internationa...
www.lemonde.fr/internationa...
March 19, 2025 at 6:35 PM
Le monde reports that on March 9th a French scientist heading for a conference was denied entry to the US. His computer and cellphone were searched, and messages to friends were found where he expressed his opinion on the Trump admin and their politics wrt to science.
www.lemonde.fr/internationa...
www.lemonde.fr/internationa...
Reposted
Wow, this seems to be extremely easy to code and extremely useful.
Transformers without Normalization
Jiachen Zhu, Xinlei Chen, Kaiming He, Yann LeCun, Zhuang Liu
arxiv.org/abs/2503.10622
Transformers without Normalization
Jiachen Zhu, Xinlei Chen, Kaiming He, Yann LeCun, Zhuang Liu
arxiv.org/abs/2503.10622

March 14, 2025 at 5:42 PM
Wow, this seems to be extremely easy to code and extremely useful.
Transformers without Normalization
Jiachen Zhu, Xinlei Chen, Kaiming He, Yann LeCun, Zhuang Liu
arxiv.org/abs/2503.10622
Transformers without Normalization
Jiachen Zhu, Xinlei Chen, Kaiming He, Yann LeCun, Zhuang Liu
arxiv.org/abs/2503.10622
Reposted

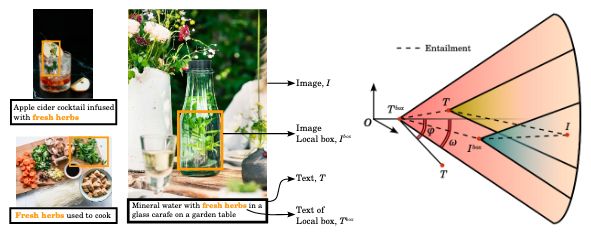
Vision-language models are hierarchical and asymmetrical, hence all models benefit from hyperbolic embeddings.
Our new #ICLR2025 oral paper shows how image-box compositions create cool new hierarchies and powerful vision-language models when used during training!
Link: arxiv.org/abs/2410.06912
Our new #ICLR2025 oral paper shows how image-box compositions create cool new hierarchies and powerful vision-language models when used during training!
Link: arxiv.org/abs/2410.06912
March 4, 2025 at 9:48 AM
Vision-language models are hierarchical and asymmetrical, hence all models benefit from hyperbolic embeddings.
Our new #ICLR2025 oral paper shows how image-box compositions create cool new hierarchies and powerful vision-language models when used during training!
Link: arxiv.org/abs/2410.06912
Our new #ICLR2025 oral paper shows how image-box compositions create cool new hierarchies and powerful vision-language models when used during training!
Link: arxiv.org/abs/2410.06912
Reposted

🚀 Call for Papers – CVPR 3rd Workshop on Multi-Modal Foundation Models (MMFM)
@cvprconference.bsky.social ! 🚀
🔍 Topics: Multi-modal learning, vision-language, audio-visual, and more!
📅 Deadline: March 14, 2025
📝 Submission: cmt3.research.microsoft.com/MMFM2025
🌐 sites.google.com/view/mmfm3rd...
@cvprconference.bsky.social ! 🚀
🔍 Topics: Multi-modal learning, vision-language, audio-visual, and more!
📅 Deadline: March 14, 2025
📝 Submission: cmt3.research.microsoft.com/MMFM2025
🌐 sites.google.com/view/mmfm3rd...
Conference Management Toolkit - Login
Microsoft's Conference Management Toolkit is a hosted academic conference management system. Modern interface, high scalability, extensive features and outstanding support are the signatures of Micros...
cmt3.research.microsoft.com
February 19, 2025 at 2:16 PM
🚀 Call for Papers – CVPR 3rd Workshop on Multi-Modal Foundation Models (MMFM)
@cvprconference.bsky.social ! 🚀
🔍 Topics: Multi-modal learning, vision-language, audio-visual, and more!
📅 Deadline: March 14, 2025
📝 Submission: cmt3.research.microsoft.com/MMFM2025
🌐 sites.google.com/view/mmfm3rd...
@cvprconference.bsky.social ! 🚀
🔍 Topics: Multi-modal learning, vision-language, audio-visual, and more!
📅 Deadline: March 14, 2025
📝 Submission: cmt3.research.microsoft.com/MMFM2025
🌐 sites.google.com/view/mmfm3rd...
Reposted


February 28, 2025 at 6:49 PM
Reposted


February 28, 2025 at 1:54 AM
Reposted

𝗘𝗟𝗜𝗣: 𝗘𝗻𝗵𝗮𝗻𝗰𝗲𝗱 𝗩𝗶𝘀𝘂𝗮𝗹-𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗙𝗼𝘂𝗻𝗱𝗮𝘁𝗶𝗼𝗻 𝗠𝗼𝗱𝗲𝗹𝘀 𝗳𝗼𝗿 𝗜𝗺𝗮𝗴𝗲 𝗥𝗲𝘁𝗿𝗶𝗲𝘃𝗮𝗹
Guanqi Zhan, Yuanpei Liu, Kai Han ... Andrew Zisserman
arxiv.org/abs/2502.15682
Trending on www.scholar-inbox.com
Guanqi Zhan, Yuanpei Liu, Kai Han ... Andrew Zisserman
arxiv.org/abs/2502.15682
Trending on www.scholar-inbox.com




February 25, 2025 at 7:00 AM
𝗘𝗟𝗜𝗣: 𝗘𝗻𝗵𝗮𝗻𝗰𝗲𝗱 𝗩𝗶𝘀𝘂𝗮𝗹-𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗙𝗼𝘂𝗻𝗱𝗮𝘁𝗶𝗼𝗻 𝗠𝗼𝗱𝗲𝗹𝘀 𝗳𝗼𝗿 𝗜𝗺𝗮𝗴𝗲 𝗥𝗲𝘁𝗿𝗶𝗲𝘃𝗮𝗹
Guanqi Zhan, Yuanpei Liu, Kai Han ... Andrew Zisserman
arxiv.org/abs/2502.15682
Trending on www.scholar-inbox.com
Guanqi Zhan, Yuanpei Liu, Kai Han ... Andrew Zisserman
arxiv.org/abs/2502.15682
Trending on www.scholar-inbox.com
Reposted

We created a new channel with daily new vision and graphics papers trending (liked/read) on www.scholar-inbox.com. This is the bsky equivalent of AK on X! Follow now, and never miss a beat again: bsky.app/profile/si-c...

February 21, 2025 at 10:37 AM
We created a new channel with daily new vision and graphics papers trending (liked/read) on www.scholar-inbox.com. This is the bsky equivalent of AK on X! Follow now, and never miss a beat again: bsky.app/profile/si-c...