



Deepak Vijaykeerthy
@deevijaykeerthy.bsky.social
Research & Engineering @IBMResearch
Ex RA at @MSFTResearch
Opinions are my own! Tweets about books & food.
https://research.ibm.com/people/deepak-vijaykeerthy
Ex RA at @MSFTResearch
Opinions are my own! Tweets about books & food.
https://research.ibm.com/people/deepak-vijaykeerthy
Reposted by Deepak Vijaykeerthy

I appreciated this nuanced take on genAI in higher education from @sarahoconnorft.ft.com:
on.ft.com/4iov2gM
on.ft.com/4iov2gM

Students must learn to be more than mindless ‘machine-minders’
Generative AI is a tempting short-cut that can prevent those at university from gaining foundational skills
on.ft.com
March 4, 2025 at 6:19 AM
I appreciated this nuanced take on genAI in higher education from @sarahoconnorft.ft.com:
on.ft.com/4iov2gM
on.ft.com/4iov2gM
Reposted by Deepak Vijaykeerthy

Excited to share our work with friends from MIT/Google on Learned Asynchronous Decoding! LLM responses often contain chunks of tokens that are semantically independent. What if we can train LLMs to identify such chunks and decode them in parallel, thereby speeding up inference? 1/N
February 27, 2025 at 12:38 AM
Excited to share our work with friends from MIT/Google on Learned Asynchronous Decoding! LLM responses often contain chunks of tokens that are semantically independent. What if we can train LLMs to identify such chunks and decode them in parallel, thereby speeding up inference? 1/N
Reposted by Deepak Vijaykeerthy

Scaling Test-Time Compute Without Verification or RL is Suboptimal
They prove that finetuning LLMs with verifier-based (VB) methods based on RL or search is far superior to verifier-free (VF) approaches based on distilling or cloning search traces, given a fixed amount of compute/data budget.
They prove that finetuning LLMs with verifier-based (VB) methods based on RL or search is far superior to verifier-free (VF) approaches based on distilling or cloning search traces, given a fixed amount of compute/data budget.

February 21, 2025 at 1:50 AM
Scaling Test-Time Compute Without Verification or RL is Suboptimal
They prove that finetuning LLMs with verifier-based (VB) methods based on RL or search is far superior to verifier-free (VF) approaches based on distilling or cloning search traces, given a fixed amount of compute/data budget.
They prove that finetuning LLMs with verifier-based (VB) methods based on RL or search is far superior to verifier-free (VF) approaches based on distilling or cloning search traces, given a fixed amount of compute/data budget.
Reposted by Deepak Vijaykeerthy


Reposted by Deepak Vijaykeerthy

There are lots of reflections on the train journey out there. I like this one. filmdaze.net/into-the-gre...

Into the Great Unknown: The Infinite Wisdom of Chihiro’s Train Journey in “Spirited Away”
The climactic journey of ‘Spirited Away’ holds the key to understanding the ethos behind Hayao Miyazaki’s entire filmography.
filmdaze.net
June 15, 2024 at 12:56 PM
There are lots of reflections on the train journey out there. I like this one. filmdaze.net/into-the-gre...
Reposted by Deepak Vijaykeerthy
I remember when AI was just us weirdos who simply want to be left alone to tinker—now it's overrun with polished LinkedIn influencers who won't leave anyone else alone
December 27, 2024 at 12:41 PM
I remember when AI was just us weirdos who simply want to be left alone to tinker—now it's overrun with polished LinkedIn influencers who won't leave anyone else alone
Reposted by Deepak Vijaykeerthy

For the next 12 days, Nicholas Carlini is letting a different LLM make him a new homepage.
Day 1: o1-mini. It makes 43 unique statements about Nicholas. 32 are completely false, 9 have major errors, and 2 are factually correct. Looks nice though.
nicholas.carlini.com/writing/2025...
Day 1: o1-mini. It makes 43 unique statements about Nicholas. 32 are completely false, 9 have major errors, and 2 are factually correct. Looks nice though.
nicholas.carlini.com/writing/2025...

December 26, 2024 at 6:19 AM
For the next 12 days, Nicholas Carlini is letting a different LLM make him a new homepage.
Day 1: o1-mini. It makes 43 unique statements about Nicholas. 32 are completely false, 9 have major errors, and 2 are factually correct. Looks nice though.
nicholas.carlini.com/writing/2025...
Day 1: o1-mini. It makes 43 unique statements about Nicholas. 32 are completely false, 9 have major errors, and 2 are factually correct. Looks nice though.
nicholas.carlini.com/writing/2025...
Reposted by Deepak Vijaykeerthy

🎅 Santa Claus has delivered the ultimate guide to understand OOM error (link in comment)
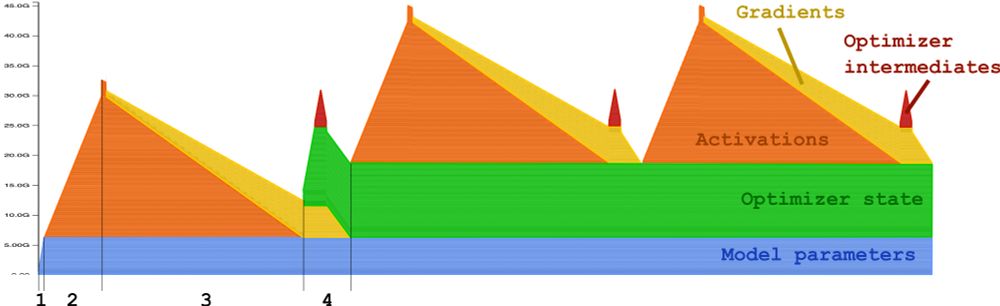
December 24, 2024 at 11:04 AM
🎅 Santa Claus has delivered the ultimate guide to understand OOM error (link in comment)
Reposted by Deepak Vijaykeerthy

The final entry in my #EMNLP2024 fav papers was this paper aclanthology.org/2024.finding... from Thomas L Griffiths' keynote. Used rotational cyphers like ROT-13 and ROT-3 to disentangle forms of reasoning in Chain-of-Thought. Good cypher joke in the keynote! (see p. 24 arxiv.org/abs/2309.13638)

Deciphering the Factors Influencing the Efficacy of Chain-of-Thought: Probability, Memorization, and Noisy Reasoning
Akshara Prabhakar, Thomas L. Griffiths, R. Thomas McCoy. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024.
aclanthology.org
December 20, 2024 at 7:36 PM
The final entry in my #EMNLP2024 fav papers was this paper aclanthology.org/2024.finding... from Thomas L Griffiths' keynote. Used rotational cyphers like ROT-13 and ROT-3 to disentangle forms of reasoning in Chain-of-Thought. Good cypher joke in the keynote! (see p. 24 arxiv.org/abs/2309.13638)
Reposted by Deepak Vijaykeerthy

It turns out OpenAI have a GitHub repository with a 26,000 line YAML OpenAPI schema describing their full API - the same API that's emulated by all sorts of other tools within the LLM ecosystem. Made some notes on that here, plus a YAML exploration tool:
simonwillison.net/2024/Dec/22/...
simonwillison.net/2024/Dec/22/...

openai/openai-openapi
Seeing as the LLM world has semi-standardized on imitating OpenAI's API format for a whole host of different tools, it's useful to note that OpenAI themselves maintain a dedicated repository …
simonwillison.net
December 22, 2024 at 11:00 PM
It turns out OpenAI have a GitHub repository with a 26,000 line YAML OpenAPI schema describing their full API - the same API that's emulated by all sorts of other tools within the LLM ecosystem. Made some notes on that here, plus a YAML exploration tool:
simonwillison.net/2024/Dec/22/...
simonwillison.net/2024/Dec/22/...
Reposted by Deepak Vijaykeerthy

My book is (at last) out, just in time for Christmas!
A blog post to celebrate and present it: francisbach.com/my-book-is-o...
A blog post to celebrate and present it: francisbach.com/my-book-is-o...

December 21, 2024 at 3:23 PM
My book is (at last) out, just in time for Christmas!
A blog post to celebrate and present it: francisbach.com/my-book-is-o...
A blog post to celebrate and present it: francisbach.com/my-book-is-o...
Reposted by Deepak Vijaykeerthy

The magic thing that humans do is a pretty good job at solving tasks under high uncertainty about the problem specification. We also frequently are capable of doing this collaboratively. I still do not see evidence that models can do any part of this.
December 21, 2024 at 1:08 AM
The magic thing that humans do is a pretty good job at solving tasks under high uncertainty about the problem specification. We also frequently are capable of doing this collaboratively. I still do not see evidence that models can do any part of this.
Reposted by Deepak Vijaykeerthy

We’ve had a wonderful edition of the Table Representation Learning workshop @NeurIPS 2024! Thanks to all for bringing such great energy and contributions!
This was the 3rd edition and it's so great to see the interest in ML for tables, as well as the diversity and quality of TRL research rising 🚀.
This was the 3rd edition and it's so great to see the interest in ML for tables, as well as the diversity and quality of TRL research rising 🚀.


December 18, 2024 at 7:18 PM
We’ve had a wonderful edition of the Table Representation Learning workshop @NeurIPS 2024! Thanks to all for bringing such great energy and contributions!
This was the 3rd edition and it's so great to see the interest in ML for tables, as well as the diversity and quality of TRL research rising 🚀.
This was the 3rd edition and it's so great to see the interest in ML for tables, as well as the diversity and quality of TRL research rising 🚀.
Reposted by Deepak Vijaykeerthy

Many LLM uncertainty estimators perform similarly, but does that mean they do the same? No! We find that they use different cues, and combining them gives even better performance. 🧵1/5
📄 openreview.net/forum?id=QKR...
NeurIPS: Sunday, East Exhibition Hall A, Safe Gen AI workshop
📄 openreview.net/forum?id=QKR...
NeurIPS: Sunday, East Exhibition Hall A, Safe Gen AI workshop
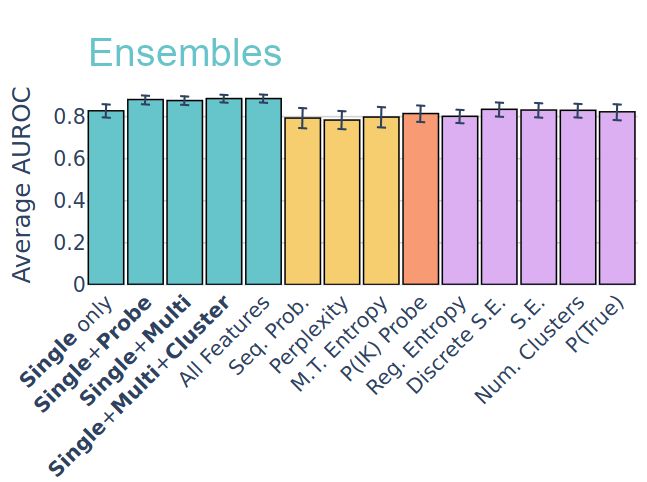
December 13, 2024 at 12:37 PM
Many LLM uncertainty estimators perform similarly, but does that mean they do the same? No! We find that they use different cues, and combining them gives even better performance. 🧵1/5
📄 openreview.net/forum?id=QKR...
NeurIPS: Sunday, East Exhibition Hall A, Safe Gen AI workshop
📄 openreview.net/forum?id=QKR...
NeurIPS: Sunday, East Exhibition Hall A, Safe Gen AI workshop
Reposted by Deepak Vijaykeerthy

Today at #NeurIPS2024 "System2" workshop, don't miss Celine Lee's "Sampling Language from Latent System2 Reasoning" which explores latent code with classic and neural interpreters for synthetic data generation.
December 15, 2024 at 12:25 PM
Today at #NeurIPS2024 "System2" workshop, don't miss Celine Lee's "Sampling Language from Latent System2 Reasoning" which explores latent code with classic and neural interpreters for synthetic data generation.
Reposted by Deepak Vijaykeerthy

Just gave a talk on "Grounding LLMs in Code Execution" at the NeurIPS Hacker-Cup AI Competition, here are the slides docs.google.com/presentation...

[NeurIPS HackerCup 2024] Grounding LLMs in Code Execution
Grounding LLMs in Code Execution Gabriel Synnaeve, Meta, FAIR
docs.google.com
December 14, 2024 at 7:11 PM
Just gave a talk on "Grounding LLMs in Code Execution" at the NeurIPS Hacker-Cup AI Competition, here are the slides docs.google.com/presentation...
Reposted by Deepak Vijaykeerthy

New preprint! ✨
Interested in LLM-as-a-Judge?
Want to get the best judge for ranking your system?
our new work is just for you:
"JuStRank: Benchmarking LLM Judges for System Ranking"
🕺💃
arxiv.org/abs/2412.09569
Interested in LLM-as-a-Judge?
Want to get the best judge for ranking your system?
our new work is just for you:
"JuStRank: Benchmarking LLM Judges for System Ranking"
🕺💃
arxiv.org/abs/2412.09569

JuStRank: Benchmarking LLM Judges for System Ranking
Given the rapid progress of generative AI, there is a pressing need to systematically compare and choose between the numerous models and configurations available. The scale and versatility of such eva...
arxiv.org
December 13, 2024 at 10:16 AM
New preprint! ✨
Interested in LLM-as-a-Judge?
Want to get the best judge for ranking your system?
our new work is just for you:
"JuStRank: Benchmarking LLM Judges for System Ranking"
🕺💃
arxiv.org/abs/2412.09569
Interested in LLM-as-a-Judge?
Want to get the best judge for ranking your system?
our new work is just for you:
"JuStRank: Benchmarking LLM Judges for System Ranking"
🕺💃
arxiv.org/abs/2412.09569
Reposted by Deepak Vijaykeerthy

Nice article explaining unwanted bias in hiring stemming from the use of artificial intelligence with extensive quotations from @kyrawilson.bsky.social and Moninder Singh. www.ibm.com/think/news/a...

How AI can help the recruitment process—without hurting it | IBM
AI agents for recruiters are time-savers—but experts caution that developers need to make sure they're unbiased. Find out what data scientists and engineers are doing to mitigate bias in AI-driven rec...
www.ibm.com
December 11, 2024 at 5:51 PM
Nice article explaining unwanted bias in hiring stemming from the use of artificial intelligence with extensive quotations from @kyrawilson.bsky.social and Moninder Singh. www.ibm.com/think/news/a...
Reposted by Deepak Vijaykeerthy

Want to predict the task performance of LMs before pretraining them?
We develop task scaling laws and model ladders, which predict the accuracy on individual tasks by OLMo 2 7B & 13B models within 2 points of absolute error. The cost is 1% of the compute used to pretrain them.
We develop task scaling laws and model ladders, which predict the accuracy on individual tasks by OLMo 2 7B & 13B models within 2 points of absolute error. The cost is 1% of the compute used to pretrain them.
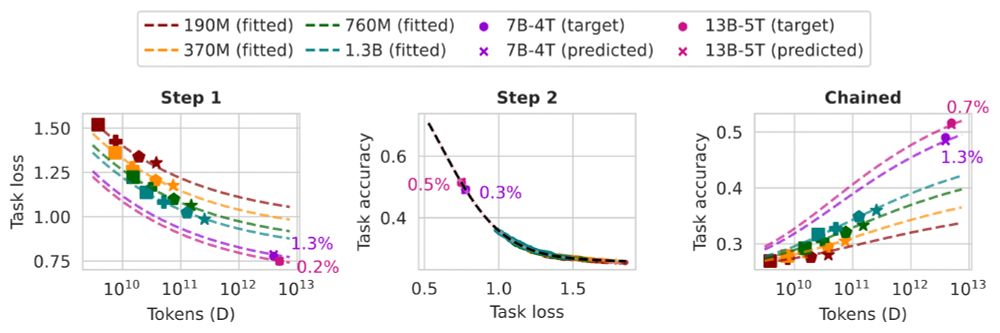
December 9, 2024 at 5:07 PM
Want to predict the task performance of LMs before pretraining them?
We develop task scaling laws and model ladders, which predict the accuracy on individual tasks by OLMo 2 7B & 13B models within 2 points of absolute error. The cost is 1% of the compute used to pretrain them.
We develop task scaling laws and model ladders, which predict the accuracy on individual tasks by OLMo 2 7B & 13B models within 2 points of absolute error. The cost is 1% of the compute used to pretrain them.
Reposted by Deepak Vijaykeerthy

Today we'll be presenting the Tutorial on Retrieval-Enhanced Machine Learning (REML). Come by to learn about the emerging design patterns in this space and see how to use retrieval beyond RAG.
In collaboration w/ the amazing @841io.bsky.social @teknology.bsky.social Alireza Salemi and Hamed Zamani.
In collaboration w/ the amazing @841io.bsky.social @teknology.bsky.social Alireza Salemi and Hamed Zamani.

December 9, 2024 at 1:41 AM
Today we'll be presenting the Tutorial on Retrieval-Enhanced Machine Learning (REML). Come by to learn about the emerging design patterns in this space and see how to use retrieval beyond RAG.
In collaboration w/ the amazing @841io.bsky.social @teknology.bsky.social Alireza Salemi and Hamed Zamani.
In collaboration w/ the amazing @841io.bsky.social @teknology.bsky.social Alireza Salemi and Hamed Zamani.
Reposted by Deepak Vijaykeerthy
In the middle of the AI buzz in Zürich... I really enjoyed my visit to ETH to talk about Table Representation Learning and Data Systems, and meet the excellent Systems Group!
Thanks to Ana and Gustavo for hosting me so wonderfully! 🙏
🖇️ www.madelonhulsebos.com/assets/eth_c...
Bottom line:
Thanks to Ana and Gustavo for hosting me so wonderfully! 🙏
🖇️ www.madelonhulsebos.com/assets/eth_c...
Bottom line:

December 8, 2024 at 10:52 AM
In the middle of the AI buzz in Zürich... I really enjoyed my visit to ETH to talk about Table Representation Learning and Data Systems, and meet the excellent Systems Group!
Thanks to Ana and Gustavo for hosting me so wonderfully! 🙏
🖇️ www.madelonhulsebos.com/assets/eth_c...
Bottom line:
Thanks to Ana and Gustavo for hosting me so wonderfully! 🙏
🖇️ www.madelonhulsebos.com/assets/eth_c...
Bottom line:
Reposted by Deepak Vijaykeerthy

1/ Did they fool you into thinking that variational inference is just "the lesser way" of doing Bayesian inference? Please let me argue otherwise.
lacerbi.github.io/blog/2024/vi...
Or just come to play with the interactive variational inference widget that took me way too long to code up.
lacerbi.github.io/blog/2024/vi...
Or just come to play with the interactive variational inference widget that took me way too long to code up.

December 5, 2024 at 12:36 PM
1/ Did they fool you into thinking that variational inference is just "the lesser way" of doing Bayesian inference? Please let me argue otherwise.
lacerbi.github.io/blog/2024/vi...
Or just come to play with the interactive variational inference widget that took me way too long to code up.
lacerbi.github.io/blog/2024/vi...
Or just come to play with the interactive variational inference widget that took me way too long to code up.
Reposted by Deepak Vijaykeerthy

Our big_vision codebase is really good! And it's *the* reference for ViT, SigLIP, PaliGemma, JetFormer, ... including fine-tuning them.
However, it's criminally undocumented. I tried using it outside Google to fine-tune PaliGemma and SigLIP on GPUs, and wrote a tutorial: lb.eyer.be/a/bv_tuto.html
However, it's criminally undocumented. I tried using it outside Google to fine-tune PaliGemma and SigLIP on GPUs, and wrote a tutorial: lb.eyer.be/a/bv_tuto.html

December 3, 2024 at 12:18 AM
Our big_vision codebase is really good! And it's *the* reference for ViT, SigLIP, PaliGemma, JetFormer, ... including fine-tuning them.
However, it's criminally undocumented. I tried using it outside Google to fine-tune PaliGemma and SigLIP on GPUs, and wrote a tutorial: lb.eyer.be/a/bv_tuto.html
However, it's criminally undocumented. I tried using it outside Google to fine-tune PaliGemma and SigLIP on GPUs, and wrote a tutorial: lb.eyer.be/a/bv_tuto.html
Reposted by Deepak Vijaykeerthy

How do LLMs learn to reason from data? Are they ~retrieving the answers from parametric knowledge🦜? In our new preprint, we look at the pretraining data and find evidence against this:
Procedural knowledge in pretraining drives LLM reasoning ⚙️🔢
🧵⬇️
Procedural knowledge in pretraining drives LLM reasoning ⚙️🔢
🧵⬇️
November 20, 2024 at 4:35 PM
How do LLMs learn to reason from data? Are they ~retrieving the answers from parametric knowledge🦜? In our new preprint, we look at the pretraining data and find evidence against this:
Procedural knowledge in pretraining drives LLM reasoning ⚙️🔢
🧵⬇️
Procedural knowledge in pretraining drives LLM reasoning ⚙️🔢
🧵⬇️